








 本文介绍了KNN算法的原理和欧几里得距离的计算方法,并通过C语言实现了一个简单的鸢尾花分类器。通过遍历不同的K值,计算预测正确的概率,展示了KNN算法在鸢尾花数据集上的应用。
本文介绍了KNN算法的原理和欧几里得距离的计算方法,并通过C语言实现了一个简单的鸢尾花分类器。通过遍历不同的K值,计算预测正确的概率,展示了KNN算法在鸢尾花数据集上的应用。
KNN算法介绍
KNN的全称是K Nearest Neighbors,意思是K个最近的邻居,从这个名字我们就能看出一些KNN算法的蛛丝马迹了。K个最近邻居,毫无疑问,K的取值肯定是至关重要的。那么最近的邻居又是怎么回事呢?其实啊,KNN的原理就是当预测一个新的值x的时候,根据它距离最近的K个点是什么类别来判断x属于哪个类别。听起来有点绕,还是看看图吧。
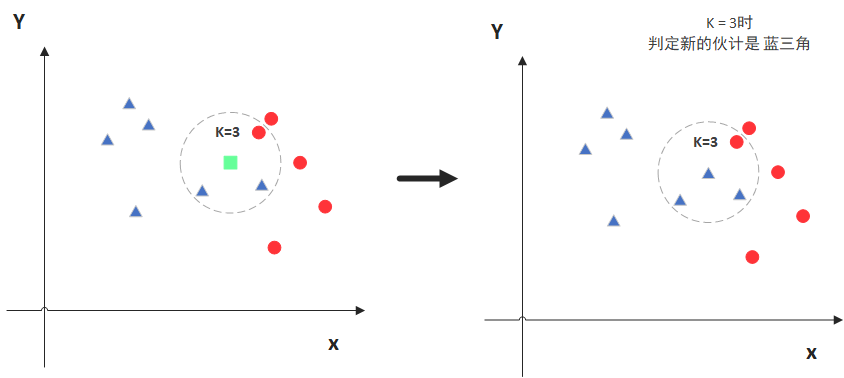
图中绿色的点就是我们要预测的那个点,假设K=3。那么KNN算法就会找到与它距离最近的三个点(这里用圆圈把它圈起来了),看看哪种类别多一些,比如这个例子中是蓝色三角形多一些,新来的绿色点就归类到蓝三角了。
欧几里得距离介绍
定义
欧几里得距离( Euclidean distance)也称欧式距离,它是一个通常采用的距离定义,它是在m维空间中两个点之间的真实距离。
公式
二
维
:
d
=
(
x
2
−
x
1
)
2
+
(
y
2
−
y
1
)
2
二维:d=\sqrt{(x_2-x_1)^2+(y_2-y_1)^2}
二维:d=(x2−x1)2+(y2−y1)2
n
维
:
d
(
x
,
y
)
=
∑
i
=
1
n
(
x
i
−
y
i
)
2
n维:d(x,y)=\sqrt{\sum_{i=1}^{n}(x_i-y_i)^2}
n维:d(x,y)=i=1∑n(xi−yi)2
我们用到n维的
实现思路
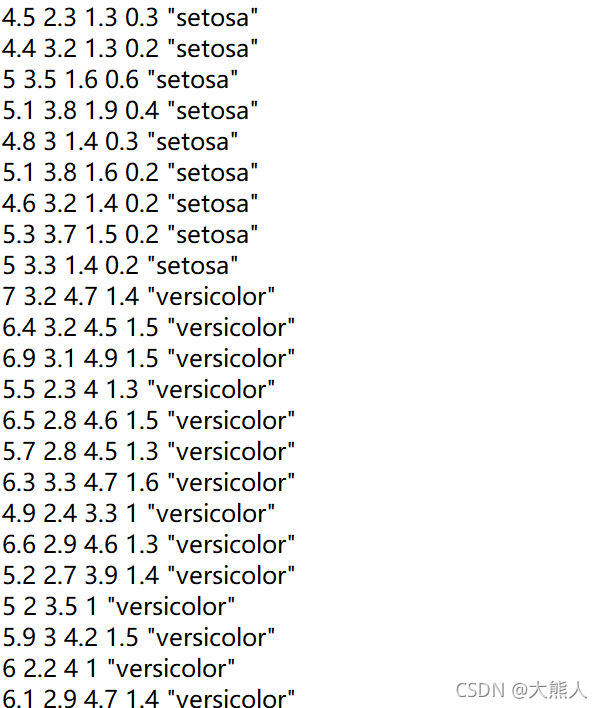
数据集
特征值的类别数:即花萼长度、花萼宽度、花瓣长度、花瓣宽度。
三种鸢尾花:setosa、versicolor、virginica。
(部分)
实现步骤
① 读取数据,打乱数据(或者随机读取数据),并把每种花分别设置A、B、C标签。
② 分割数据(共150组,分55组为测试集,95组为训练集)。
③遍历
K
(
1
≤
K
≤
15
,
K
%
2
≠
0
)
K(1\leq K \leq 15,K\%2\neq0)
K(1≤K≤15,K%2=0)值。
④ 计算测试集数据对所有训练数据的距离(用欧几里得距离),将计算好的距离与训练集标签绑定在一块进行保存。
⑤ 对保存好的 (距离,训练集标签) 从小到大排序,取前
K
K
K个(即距离最近的邻居数),统计其训练集标签 出现的频数。
⑥ 将频数最高的训练集标签保存到预测标签结果集中,判断预测标签与原有测试集标签是否相等,相等即为预测正确,统计数量。
⑦ 计算概率(预测标签正确的总数量 / 测试集总数),打印结果。
⑧ 重复③④⑤⑥⑦,直到遍历完所有
K
K
K值。
!!!完整的代码以及数据文件我会全部打包分享在文章结尾!!!
源码(C语言)
头文件:
/**
* @file KNN.h
* @author 大熊人 (daxiongren@foxmail.com)
* @brief 头文件
* @version 1.0
* @date 2021-11-28
* @copyright Copyright (c) 2021
*/
#ifndef __KNN_H
#define __KNN_H
#define TOTAL 150 // 总数据的数量
#define TEST_SIZE 55 // 测试数据的数量
#define TRAIN_SIZE 95 // 训练数据的数量
#define N 4 // 特征数据的数量(维数)
#define KN 15 // K的最大取值
/* 距离结构体 */
typedef struct {
double value; // 距离数据
char label; // 用于绑定训练集标签
} Distance;
/* 鸢尾花结构体 */
typedef struct {
double value[N]; // 每种花的4个特征数据
char type[20]; // 存放花的种类
char label; // 用于设置标签 为了方便检测
} Iris;
/* 函数接口声明 */
void labelABC(char *type, char *label);
void makeRand(Iris iris[], int n);
void openDataFile(char *path);
void printData();
void loadData();
double EuclideanDistance(double d1[], double d2[], int n);
char compareLabel(int a, int b, int c);
char countLabel(int *count, int k, char forecastLabel);
int cmp(const void *d1, const void *d2);
void printResult(int k, int count);
#endif
======================================================================================================
源文件:
/**
* @file KNN.cpp
* @author 大熊人 (daxiongren@foxmail.com)
* @brief 用KNN算法简单实现对鸢尾花分类
* @version 1.0
* @date 2021-11-28
* @copyright Copyright (c) 2021
*/
#include "KNN.h"
#include <math.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <time.h>
Iris testSet[TEST_SIZE]; // 测试集结构体数组
Iris forecastSet[TEST_SIZE]; // 保存预测的标签
Iris trainSet[TRAIN_SIZE]; // 训练集结构体数组
Iris temp[TOTAL]; // 临时存放数据结构体数组
Distance distance[TRAIN_SIZE]; // 存放距离结构体数组
/**
* @brief 把不同种类的花分别转化成 A B C 标签
* @param type[IN] 花的种类
* @param label[OUT] 转化的标签
*/
void labelABC(char *type, char *label) {
if (strcmp(type, "\"setosa\"") == 0) *label = 'A';
if (strcmp(type, "\"versicolor\"") == 0) *label = 'B';
if (strcmp(type, "\"virginica\"") == 0) *label = 'C';
}
/**
* @brief 利用伪随机数进行数据打乱
* @param iris
* @param n
*/
void makeRand(Iris iris[], int n) {
Iris t;
int i, n1, n2;
srand((unsigned int)time(NULL)); //获取随机数的种子,百度查下用法
for (i = 0; i < n; i++) {
n1 = (rand() % n); //产生n以内的随机数 n是数组元素个数
n2 = (rand() % n);
/* 若两随机数不相等 则下标为这两随机数的数组进行交换 */
if (n1 != n2) {
t = iris[n1];
iris[n1] = iris[n2];
iris[n2] = t;
}
}
}
/**
* @brief 打开数据文件
* @param path 数据文件的路径
*/
void openDataFile(char *path) {
int i, j;
// 用于先存放150个数据后再打乱
FILE *fp = NULL;
fp = fopen(path, "r");
for (i = 0; i < TOTAL; i++) {
for (j = 0; j < N; j++) {
fscanf(fp, "%lf ", &temp[i].value[j]);
}
fscanf(fp, "%s", temp[i].type);
/* 把不同种类的花分别转化成 A B C 标签 */
labelABC(temp[i].type, &temp[i].label);
}
makeRand(temp, TOTAL); //打乱所有数据
fclose(fp);
fp = NULL;
}
/**
* @brief 把分割后的数据都打印出来 便于观察是否已经打乱
*/
void printData() {
int i, j;
printf("\n设置标签 -> 打乱 -> 按%d/%d分割\n", TEST_SIZE, TRAIN_SIZE);
printf("数据如下:\n\n");
printf("%d组测试集:\n", TEST_SIZE);
for (i = 0; i < TEST_SIZE; i++) {
for (j = 0; j < N; j++) {
printf("%.2lf ", testSet[i].value[j]);
}
printf("%c\n", testSet[i].label);
}
printf("\n\n%d组训练集:\n", TRAIN_SIZE);
for (i = 0; i < TRAIN_SIZE; i++) {
for (j = 0; j < N; j++) {
printf("%.2lf ", trainSet[i].value[j]);
}
printf("%c\n", trainSet[i].label);
}
}
/**
* @brief 加载数据 分割:测试TEST_SIZE组 训练TRAIN_SIZE组
*/
void loadData() {
int i, j, n = 0, m = 0;
for (i = 0; i < TOTAL; i++) {
/* 先将TEST_SIZE个数据存入测试集 */
if (i < TEST_SIZE) {
for (j = 0; j < N; j++) {
testSet[n].value[j] = temp[i].value[j]; //存入花的四个特征数据
}
testSet[n].label = temp[i].label; //存入花的标签
n++;
} else { /* 剩下的数据存入训练集 */
for (j = 0; j < N; j++) {
trainSet[m].value[j] = temp[i].value[j]; //存入花的四个特征数据
}
trainSet[m].label = temp[i].label; //存入花的标签
m++;
}
}
}
/**
* @brief 计算欧几里得距离
* @param d1
* @param d2
* @param n 维数
* @return double
*/
double EuclideanDistance(double d1[], double d2[], int n) {
double result = 0.0;
int i;
/* 欧几里得距离 */
for (i = 0; i < n; i++) {
result += pow(d1[i] - d2[i], 2.0);
}
result = sqrt(result);
return result; //返回距离
}
/**
* @brief 比较三个标签出现的频数
* @param a
* @param b
* @param c
* @return char 返回出现的频数最多的标签
*/
char compareLabel(int a, int b, int c) {
if (a > b && a > c) {
return 'A';
}
if (b > a && b > c) {
return 'B';
}
if (c > a && c > b) {
return 'C';
}
return 0;
}
/**
* @brief 统计与测试集距离最邻近的k个标签出现的频数
* @param count[OUT] 用于统计
* @param k[IN] 当前K值
* @param forecastLabel[IN] 训练集的预测标签
* @return 返回频数最高的标签
*/
char countLabel(int *count, int k, char forecastLabel) {
int i;
int sumA = 0, sumB = 0, sumC = 0; //分别统计距离最邻近的三类标签出现的频数
for (i = 0; i < k; i++) {
switch (distance[i].label) {
case 'A':
sumA++;
break;
case 'B':
sumB++;
break;
case 'C':
sumC++;
break;
}
}
/* 检测出现频数最高的标签与测试集的预测标签是否相等 */
char maxLabel = compareLabel(sumA, sumB, sumC);
if (maxLabel == forecastLabel) {
(*count)++; //统计符合的数量
}
return maxLabel;
}
/* 快速排序qsort函数的cmp回调函数 */
int cmp(const void *d1, const void *d2) {
Distance D1 = *(Distance *)d1;
Distance D2 = *(Distance *)d2;
return D1.value > D2.value ? 1 : -1;
}
/**
* @brief 打印结果
* @param k K值
* @param count 预测正确的总数量
*/
void printResult(int k, int count) {
int i;
printf("对比结果:\n");
/* 打印每个K值对应的概率 */
printf("K = %d P = %.2lf%%\n", k, (100.0 * count) / TEST_SIZE);
printf("原有标签:");
printf("[%c", testSet[0].label);
for (i = 1; i < TEST_SIZE; i++) printf(",%c", testSet[i].label);
printf("]\n");
printf("预测标签:");
printf("[%c", forecastSet[0].label);
for (i = 1; i < TEST_SIZE; i++) printf(",%c", forecastSet[i].label);
printf("]\n\n");
}
int main() {
int i, j;
int k; // k值
int count = 0; //用于统计预测正确的标签数量
/* openDataFile("你的数据文件路径")
* 如果放在代码文件路径下那就直接写文件名(建议写绝对路径) */
openDataFile("./iris.txt"); // 打开数据文件 -> 打乱数据
loadData(); // 加载打乱后的数据并分割
printData(); // 打印数据
printf("\n\n测试集:%d组 训练集:%d组\n\n", TEST_SIZE, TRAIN_SIZE);
for (k = 1; k <= KN; k += 2) { // k值:1--KN(取奇数) KN = 15(宏定义)
for (i = 0; i < TEST_SIZE; i++) { // 遍历测试集
for (j = 0; j < TRAIN_SIZE; j++) { // 遍历训练集
/* 把计算欧几里得距离依次存入distance结构体数组的value中 */
distance[j].value =
EuclideanDistance(testSet[i].value, trainSet[j].value, N);
/* 将训练集标签与计算好的距离绑定在一块 */
distance[j].label = trainSet[j].label;
}
/* 用qsort函数从小到大排序(距离,训练集标签) */
qsort(distance, TRAIN_SIZE, sizeof(distance[0]), cmp);
/* 统计与测试集标签距离最邻近的k个标签出现的频数
* 并返回频数最后高标签 即预测的标签 */
forecastSet[i].label = countLabel(&count, k, testSet[i].label);
}
/* 打印结果 */
printResult(k, count);
count = 0; // 重置
}
getchar();
return 0;
}
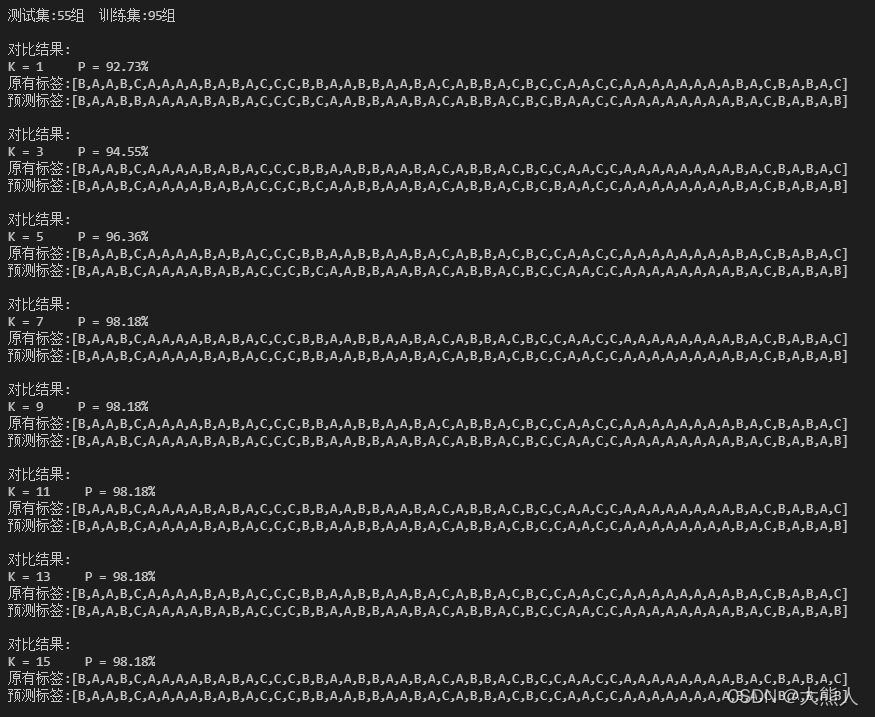
运行结果
(部分)
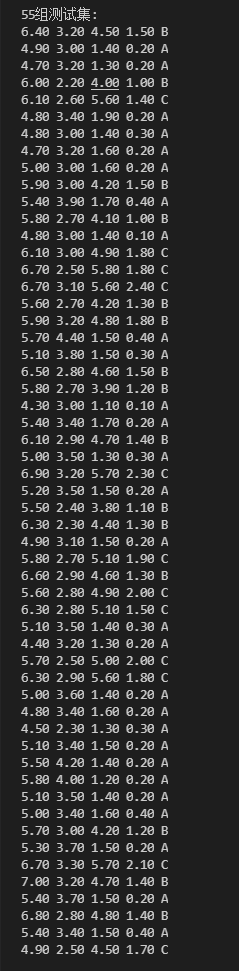 | 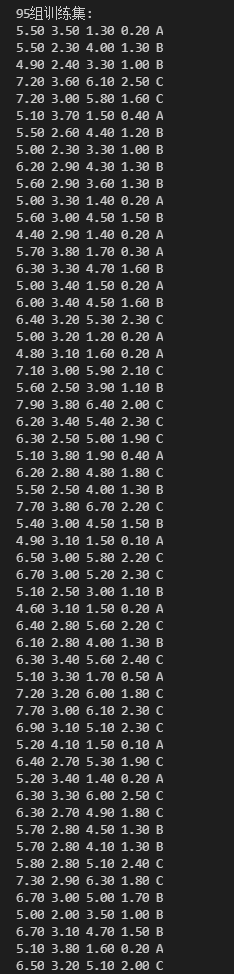 |
|---|
对于每一个
K
(
1
≤
K
≤
15
,
K
%
2
≠
0
)
K(1\leq K \leq 15,K\%2\neq0)
K(1≤K≤15,K%2=0)值,预测正确的概率:
源码下载
github地址:https://github.com/daxiongren/IrisClassification-KNNAlgorithm
百度网盘:https://pan.baidu.com/s/10dU6l52M_vjNpBIbIj6Fvw
提取码: rh2d
结尾
本人能力有限,如有错误之处望大家海涵并不吝指正!


















 463
463

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











