







需要的包:
python
chrome driver (put in the python path)
selenium==2.48.0
requests
Auto_health_report.py
from selenium import webdriver
import time
# Load the login webpage
browser = webdriver.Chrome()
# executable_path='C:\Program Files\Mozilla Firefox\firefox.exe' #放弃火狐浏览器,换成自己常用的Chrome
browser.get('https://weixine.ustc.edu.cn/2020/login')
link_indentity = browser.find_element_by_link_text('统一身份认证登录')
link_indentity.click()
# Fill in the blanks
username_elememt = browser.find_element_by_id('username')
username_elememt.send_keys('【输入自己的学号】')
password_element = browser.find_element_by_id('password')
password_element.send_keys('【输入自己的密码】')
link_login = browser.find_element_by_id('login')
link_login.click()
# Submit the daily health report
# information_report_element = browser.find_element_by_link_text('user-info-btn')
# information_report_element.click()
# time.sleep(3)
confirm_element = browser.find_element_by_id('report-submit-btn-a24')
confirm_element.click()
time.sleep(1)
browser.quit()
auto.bat
@echo off
start cmd /k "python Auto_health_report.py && taskkill /f /t /im cmd.exe"
- cmd里输入python,现在会自动弹出Microsoft store,在里面安装。
- 关于selenium 包,有说法2.48.0的版本最稳定(未验证)。
- 可能出现问题:
selenium.common.exceptions.WebDriverException: Message: 'chromedriver' executable
是Chrome驱动的问题,参考这个,下载Chrome对应版本的驱动,将chromedriver.exe复制到python所在目录下,比如前面Microsoft store里安装的python就是在C:\Users\xxx\AppData\Local\Microsoft\WindowsApps\python.exe。(也可以用where python查)。
4.find_element_by_id的ID怎么查?参考这个
按F12,选择elements,再把鼠标移动到要查找的button的位置,就可以看到ID了

再举个栗子
from selenium import webdriver
import time
# Load the login webpage
browser = webdriver.Chrome()
# executable_path='C:\Program Files\Mozilla Firefox\firefox.exe'
browser.get('https://weixine.ustc.edu.cn/2020/login')
link_indentity = browser.find_element_by_link_text('统一身份认证登录')
link_indentity.click()
# Fill in the blanks
username_elememt = browser.find_element_by_id('username')
username_elememt.send_keys('【输入自己的学号】')
password_element = browser.find_element_by_id('password')
password_element.send_keys('【输入自己的密码】')
link_login = browser.find_element_by_id('login')
link_login.click()
confirm_element = browser.find_element_by_id('menu')
confirm_element.click()
time.sleep(1)
confirm_element = browser.find_element_by_link_text('申报记录')
confirm_element.click()
time.sleep(1)
browser.quit()

获取文本框信息
name=browser.find_element_by_xpath('/html/body/div[2]/div[1]/ul[2]/li/span').text
print(name)
with open('name.txt', 'wb') as f:
f.write(name.encode('utf-8'))
注意:这里不要写成
/html/body/div[2]/div[1]/ul[2]/li/span/text()

下载图片
需要requests包:
pip install requests
url = browser.find_element_by_css_selector('#WU_FILE_0>img').get_attribute('src')
url2 = browser.find_element_by_css_selector('#fileListAkm>#WU_FILE_1>img').get_attribute('src')
url3 = browser.find_element_by_css_selector('#fileListHs>#WU_FILE_1>img').get_attribute('src')
browser.quit()
r = requests.get(url)
with open(name+'XingChengMa.png', 'wb') as f:
f.write(r.content)
r = requests.get(url2)
with open(name+'AnKangMa.png', 'wb') as f:
f.write(r.content)
r = requests.get(url3)
with open(name+'HeSuanBaoGao.png', 'wb') as f:
f.write(r.content)

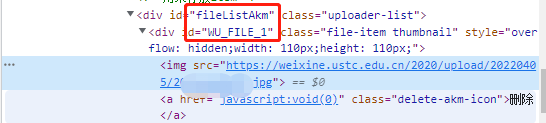
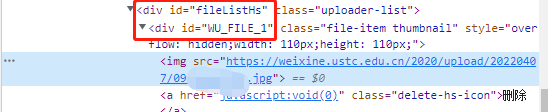
这里有重名的:“WU_FILE_1”, 所以写了2层
‘#fileListAkm>#WU_FILE_1>img’
‘#fileListHs>#WU_FILE_1>img’














 2634
2634











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









