







论文来源:AAAI 2024
论文地址:https://ojs.aaai.org/index.php/AAAI/article/view/29844
Abstract
LLM通过利用能够逐步思考的思维链在NLP任务中取得了很好的性能,但是为LLM扩展多模态能力时计算成本高,且需要大量的硬件资源。为了解决上述问题,本文提出了KAM-CoT框架,集成了CoT推理、知识图谱和多种模态,以全面理解多模态任务。
KAM-CoT采用两阶段式训练过程,连接知识图谱以生成有效的推理和答案,通过在推理过程中整合来自KG的外部知识,使模型获得更很层次的上下文理解,以缓解幻觉,并提高答案的质量。
这种知识增强的CoT推理能够使模型处理需要外部上下文的问题,提供更高质量的答案。
Introduction
对于CoT推理,KGs可以补充逐步推理过程,通过整合来自KGs的信息,LM可以更连贯地进行推理吗,并利用实体和属性之间的上下文关系。
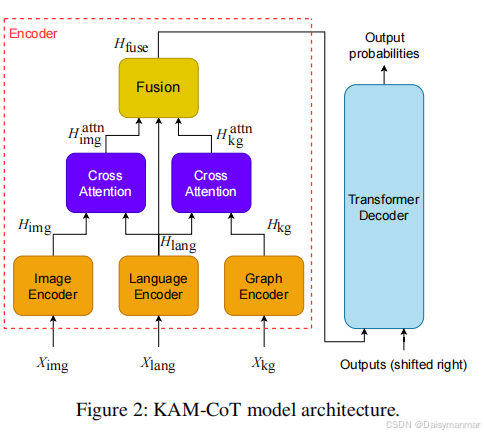
本文利用KGs来增加多种模态以帮助模型充分挖掘CoT能力来解决复杂问题。LAM-CoT包括一个LM获取文本上下文,一个视觉编码器来编码视觉特征和一个图神经网络(GNN)以基于KGs进行推理。推理过程包括两个阶段,第一阶段生成合理的推理,第二阶段将生成的推理作为额外的输入并提供答案。KAM-CoT将文本、视觉和图特征拼接在一起,是模型能够连贯地思考和推理。
主要贡献:
1. 图提取,基于给定的上下文从ConceptNet中提取三元组;
2. 融合KG,将文本和图像模态与KG融合;
3. KAM-CoT,分阶段联合处理视觉、文本和KG,并逐步推理以生成合理的推理和答案。
Method
论文的核心思想与论文《Multimodal Chain-of-Thought Reasoning in Language Models》类似,第一步是训练模型生成推理,第二步是将第一步生成的推理作为额外的输入,使模型生成正确的答案,不同点在于MM-CoT只处理图像和文本模态,本文对该方法进行了扩展,将KG作为一种额外的模态,从而将生成过程建立在事实知识的基础上。
为了获得用于推理生成的文本输入,论文只是简单的将不同的文本部分进行拼接,,对于答案选择预测, 则增加推理
。
然后为每个样本提取一个子图,通过训练模型
来生成推理
:
与上述过程类似,为了生成正确的答案,训练模型
最后,通过计算生成文本的概率类获得推理或答案:
整过的推理过程如下:

编码不同模态的输入
文本编码:使用基于Transformer的语言编码器对进行编码,获得
。
图像编码:使用基于Transformer的图像编码器对进行编码,获得
。
子图选择:
对于每个样本,从ConceptNet中选择一个子图。具体来说,将ConceptNet中的关系划分为17中不同的类型,这些可以可以是正向的或反向的,总共34中可能得边类型,三元组被转换为句子,并存储为响应的句子模式,用于从问题、上下文和答案选择中提取结点。
为了获取初始化节点嵌入,使用与文本编码相同的预训练检查点对语言编码器进行训练(确保语言和结点嵌入在相同的嵌入空间),并在该节点的跨度内取嵌入的平均值。
图编码:利用图神经网络获取子图编码
模态间的交互
使用交叉注意力来实现文本、图像和子图表示之间的交互,如图2所示,第一个注意力模块实现语言和图像嵌入之间的交互,另一个注意力模块实现语言和结点之间的交互。
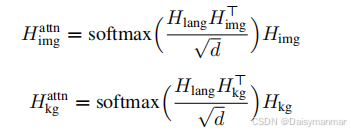
特征融合
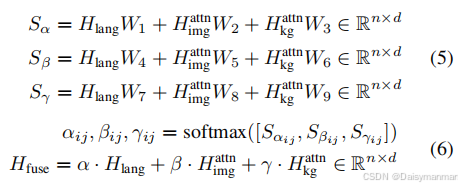
解码
使用一个Transformer解码器获得自回归生成的文本:
![]()
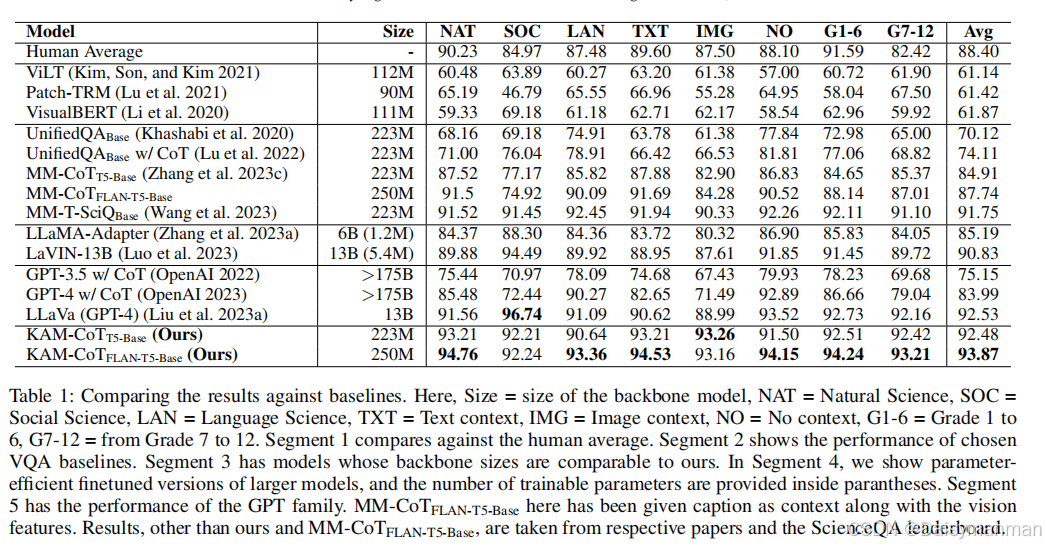
实验



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









