







 本文展示了一个Python脚本,利用requests库和正则表达式从doupoxs.com抓取斗破苍穹小说的前10页内容,并将文字信息保存到本地TXT文件。脚本首先设置User-Agent,然后打开TXT文件追加内容,通过get_info函数处理每个页面,查找并写入<p>标签内的文本。
本文展示了一个Python脚本,利用requests库和正则表达式从doupoxs.com抓取斗破苍穹小说的前10页内容,并将文字信息保存到本地TXT文件。脚本首先设置User-Agent,然后打开TXT文件追加内容,通过get_info函数处理每个页面,查找并写入<p>标签内的文本。
利用requests库和正则表达式方法,爬取斗破苍穹小说网斗破苍穹小说全文免费在线阅读(天蚕土豆) - 斗破小说网 (doupoxs.com)
中该小说的信息,并将爬取的数据存储到本地文件中。
需要爬取的信息为全文的文字信息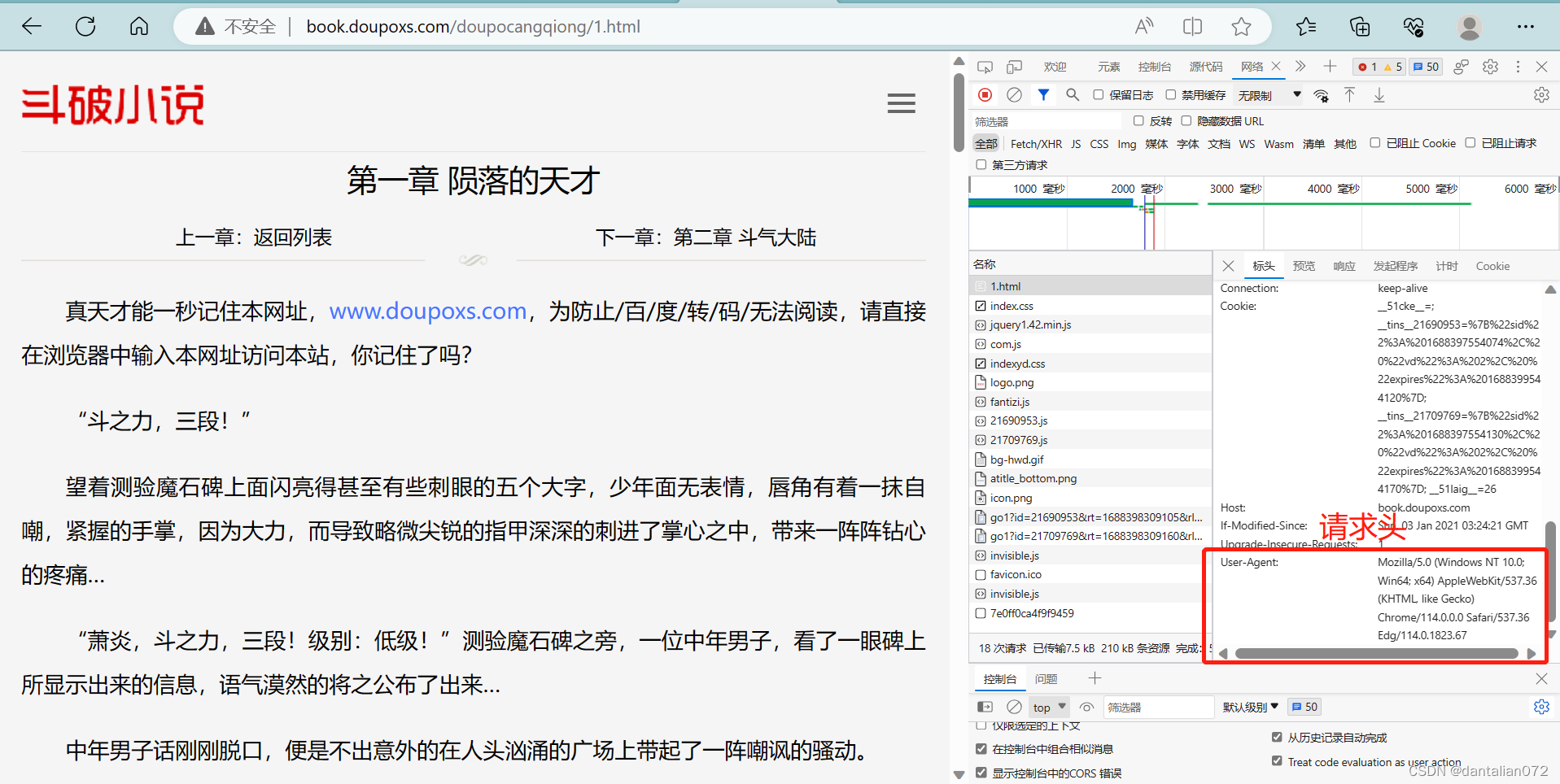
我为了运行方便,只爬取了1-10页的信息,可自由选择需要爬取的信息
import requests
import re
import time
headers = {
'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36 Edg/114.0.1823.67'
}
#新建TXT文件,追加的方式
f = open('D:\hxy学习\python\doupo.txt','a+')
#定义获取信息的函数
def get_info(url) :
resp = requests.get(url,headers=headers) 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









