






一,SQL环境
1,PostgreSQL安装搭建
为了提高安全性,需要修改PostgreSQL的设置文件:如何在 Windows 10 中安装 PostgreSQL 和连接设置 | 程序员忆初 (developerastrid.com)
2,创建数据库
CREATE DATABASE 表名(表名只能用小写字母)
二,数据库及SQL
1,数据库和SQL
1-1,DBMS的种类(按数据的保存格式分类)
(1),层次数据库(HDB);
(2),关系数据库(RDB);
(3),面向对象数据库(OODB);
(4),XML数据库(XMLDB);
(5),键值存储系统(KVS);
1-2,数据库的结构
一般为客户端/服务器类型(CS类型)
1-3,SQL概要
SQL种类(根据操作目的分类)
(1)DDL(数据定义语言):包括CREATE——创建数据库和表等对象、DROP——删除数据库和表等对象、ALTER——修改数据库和表等对象结构
(2)DML(数据操纵语言):包括SELECT——查询表中的数据、INSERT——向表中插入新数据、UPDATE——更新表中的数据、DELETE——删除表中的数据
(3)DCL(数据控制语言):COMMIT——确认对数据库的数据进行的变更、ROLLBACK——取消对数据库中的数据进行的变更、CRANT——赋予用户操作权限、REVOKE——取消用户的操作权限
SQL server、PostgreSQL:BEGIN TRANSACTION
MYSQL:START TRANSACTION
Oracle、DB2:不需要该语句
基本书写规则
(1)SQL语句要以;结尾
(2)SQL语句不区分大小写——关键字大写、表名的首字母大写、其余(列名等)小写
(3)常数书写方式按正常书写
(4)字符串书写需要用‘’括起来
(5)单词之间需要用半角空格或换行符进行分隔
(6)表名命名规则:半角英文字母、半角数字、下划线(_)
1-4,表的创建
CREATE TABLE 表名
(
<列名1><数据类型><该列所需约束>,
<列名2><数据类型><该列所需约束>,
<列名3><数据类型><该列所需约束>,
);
PS:数据类型的指定
数据类型:
INTEGER(整数型,不能存储小数);
CHAR(字符串),CHAR(8),可存储8个字符,即定长字符串;
VARCHAR(字符串),可变长字符串;
DATE(日期型);
约束:NOT NULL和NULL
主键约束:PRIMARY KEY (列名)——创建表语句之后
1-5,表的删除和更新
(1)表的删除:DROP TABLE <表名>;
(2)添加列
常规:ALTER TABLE <表名> ADD COLUMN<列的定义>;
Oracle和SQL Server :ALTER TABLE <表名> ADD <列的定义>;
(3)删除列
常规:ALTER TABLE <表名> DROP COLUMN<列名>;
Oracle:ALTER TABLE <表名> DROP <列名>;
(4)开始运行
BEGIN TRANSACTION——SQL server、PostgreSQL
START TRANSACTION——MySQL
Oracle和DB2中无需使用该字段
(5)修改表
Oracle和PostgreSQL:ALTER TABLE <表名> RENAME TO <新表名>;
DB2:RENAME TABLE <表名> RENAME TO <新表名>;
SQL server:sp_rename ‘表名’,‘新表名’;
MySQL:RENAME TABLE <表名> RENAME to <新表名>;
三,查询基础
1,语句基础
注释:/*和*/之间做注释或者在#之后做注释
查询:SELECT <列名> FROM <表名>;——查询所有列用 *
设置列别名:SELECT <列名> AS <列别名> FROM <表名>;
查询去重:SELECT DISTINCT<列名> FROM <表名>;
条件查询:WHERE子句
2,运算符
2-1,算术运算符
加减乘除
四则运算中包含NULL的计算结果一定等于NULL
2-2,比较运算符
不等于:包括!=和<>
不能对NULL使用比加运算符
2-3,逻辑运算符
AND:并集
OR:或者
AND运算符优先于OR运算符;若需要优先运算OR运算符可以使用括号
四,聚合与排序
1,表聚合查询
COUNT:计算表中的行数(用*统计所得结果包括NULL,用列名统计不包括NULL)
SUM:计算表中的数值列中数据的合计值
AVG:计算表中的数值列中数据的平均值
MAX:计算表中的数值列中数据的最大值
MIN:计算表中的数值列中数据的最小值
2,表分组
GROUP BY
1-1,使用聚合函数后,SELECT 子句中只能存在以下三种元素(常数;聚合函数;GROUP BY子句中指定的列名,即聚合键)
1-2,GROUP BY子句中写了列的别名(GROUP BY子句执行顺序在SELECT 子句之前,所以不能识别SELECT子句中定义的别名)
1-3,GROUP BY子句的结果是按随机排序的
1-4,WHERE子句中使用聚合函数会发生错误(只有SELECT子句、HAVING子句和ORDER BY子句中能够使用聚合函数)
3,聚合结果指定条件
WHERE子句用来指定数据行的条件;HAVING子句用来指定分组的条件
HAVING子句必须写在GROUP BY子句之后,其执行顺序也在GROUP BY子句之后
使用聚合函数后,HAVING子句中只能存在以下三种元素(常数;聚合函数;GROUP BY子句中指定的列名,即聚合键)
4,查询结果进行排序
ORDER BY子句对查询结果进行排序;
ORDER BY子句可以指定多个排序键;
排序键中包含NULL时,会在开头或末尾进行汇总;
ORDER BY子句中可以使用SELECT子句中定义的别名;
ORDER BY子句中可以使用SELECT子句中未出现的列或者聚合函数;
升序字段:ORDER BY <列名> ASC
降序字段:RDER BY <列名> DESC
书写顺序:SELECT子句——FROM子句——WHERE子句——GROUP BY子句——HAVING子句——ORDER BY子句
五,数据更新
1,数据的插入
1-1,使用INSERT可以向表中插入数据或数据行(原则上INSERT语句每次执行一行数据的插入)
插入一行:INSERT INTO<表名>(列1,列2,列3....)VALUES(值1,值2,值3...);
插入多行:INSERT INTO<表名>VALUES(值1,值2,值3...)(值1,值2,值3...);
1-2,将列名和值用逗号隔开,分别括在()中,这种形式称为清单
1-3,对表中所有列进行INSERT操作时可以省略表名后的列清单
INSERT INTO<表名>VALUES(值1,值2,值3...);
1-4,插入NULL时需要在VALUES子句的清单中写入NULL
1-5,可以为表中的列设定默认值(初始值),默认值可以通过在CREATE TABLE语句中为列设置DEFAULT约束来设定
CREATE TABLE<表名>(列名,列值类型,FEFAULT 0)
1-6,插入默认值可以通过两种方式实现,即在INSERT语句的VALUES子句中指定DEFAULT关键字或省略列清单
方法1:INSERT INTO<表名>(列1,列2,列3....)VALUES(值1,DEFAULT ,值3...)——赋值为默认值;
方法2:同时省略语句中列清单和值清单中的对应列,则该对应列将被自动赋值为默认值
如果没有插入值也没有默认值则为NULL
1-7,使用INSERT ...SELECT可以从其他表中复制数据
INSERT INTO <copy表>(列1,列2,列3等)SELECT (列1,列2,列3等) FROM <原表>
复制其他表中数据时也可以使用WHERE\GROUP BY\
2,数据的删除
DELETE FROM <表名>——删除表数据,表结构不会被删除
DELETE FROM <表名> WHERE <条件>——删除指定条件的数据
特例:Oracle、SQL server、PostgreSQL、MySql和DB2数据库产品中有删除或舍弃整个表数据的语句——TRUNCATE<表名>
3,数据的更新
更新当前列所有数据:UPDATE <表名> SET <列名>=<表达式>;
更新当前列特定数据:UPDATE <表名> SET <列名>=<表达式> WHERE <条件>;
更新当前列所有数据为NULL:UPDATE <表名> SET <列名>=NULL;
更新多列数据:UPDATE <表名> SET <列名>=<表达式>,<列名>=<表达式>;
4,事务
事务:同一个处理单元中执行的一系列更新处理的集合
创建事务:
(1),SQL server、PostgreSQL——BEGIN TRANSACTION
(2),MySql——START TRANSACTION
(3),Oracle、DB2——无
语句顺序:事务开始语句(BEGIN TRANSACTION)——数据操纵语句(SELECT等)或数据定义语句(CREATE等)——事务结束语句(COMMIT或ROLLBACK等数据控制语句)
提交事务:COMMIT
取消处理:ROLLBACK
DBMS的四种特性(所有DBMS都遵循的ACID特性):
(1),原子性——事务结束时,包含的更新处理要么全部执行,要么全部不执行
(2),一致性——事务中包含的处理要满足数据库提前设置的约束,如主键约束或NOT NULL约束
(3),隔离性——不同事务之间互不干扰,保证了事务之间不会互相嵌套及影响
(4),持久性——事务结束后(无论提交或回滚)结束后,都能够保证该时间点的的数据状态不会被保存的特性。即使由于系统故障导致数据丢失,数据库也可以通过手段恢复
六,复杂查询
1,视图
视图和表的效果是相同的;区别在于表保存的是数据,而视图保存的是SELECT语句
视图的优点:1,由于视图无需保存数据,因此可以节省存储设备的容量;提高多次书写SELECT语句的效率
尽量避免在视图的基础上创建视图,虽然可以这么操作
定义视图时可以使用任何SELECT语句(ORDER BY语句除外)——因为视图和表一样,数据行是无顺序的(PostgreSQL数据库中可以使用ORDER BY语句)
1-1,创建视图
CREATE VIEW 视图名称(<视图列名1>,<视图列名2>) AS <SELECT语句>;
1-2,使用视图
SELECT <视图列名1>,<视图列名2> FROM 视图名称
1-3,视图限制——视图更新
如果视图满足以下条件,则视图可以更新(通过汇总得到的视图无法更新)
(1),SELECT子句中未使用DISTINCT
(2),FROM子句中只有一张表
(3),未使用GROUP BY子句
(4),未使用HAVING子句
INSERT INTO 视图名 VALUES(数据1,数据2,...)
1-4,删除视图
DROP VIEW 视图名(<视图列名1>,<视图列名2>,<视图列名2>);
2,子查询——相当于一次性视图
1-1,常规子查询
SELECT column_name column_name
FROM
(SELECT column_name,column_name
FROM table1, table2
[WHERE子句])
AS temp_table_name
WHERE condition在Oracle中as关键字不能用于指定表的别名,在Oracle中指定表的别名时只需在原有表名和表的别名之间用空格分隔即可
1-2,标量子查询
每次查询必须而且只能返回1行1列的结果(能够使用常数或者列名的地方都可以使用,无论SELECT子句、GROUP BY子句、HAVING子句、ORDER BY子句)
SELECT
product_id,
product_name,
sale_price
FROM
Product
WHERE
sale_price > (
SELECT
AVG(sale_price)
FROM
Product
);子查询绝对不能返回多行结果:如果子查询返回了多行结果,那么它就不是一个普通的子查询,因此不能用在比较运算等需要单一输入值的运算符当中,也不能用在SELECT等子句中
3,关联子查询
即WHERE子句:HWERE A.a=B.a
SELECT * FROM article
WHERE uid
IN
(
SELECT uid FROM user
WHERE article.uid = user.uid
) MySQL中表子查询与关联子查询的基础学习教程 - html中文网
七,函数/谓词/Case表达式
1,各种函数
1-1,算术函数
绝对值(ABS,absolute value): SELECT ABS(列名) FROM 表名
求余(MOD,modulo):SELECT n,p,MOD(n,p) AS mod_c FROM 表名
四舍五入(ROUND,对象数值,保留结果的小数位数):SELECT n,p,ROUND(n,p) AS mod_c FROM 表名——n保留p位小数
1-2,字符串函数
(1)字符串
INSERT INTO 表名(str1,str2,str3)VALUES('字段1','字段2','字段3');
(2)字符串拼接,用||连接
SELECT str1||str2 AS new_str FROM 表名;
SQLserver 和MySql中无法使用,SQLserver中使用+号连接,MySql中使用CONCAT连接
SELECT CONCAT(str1,str2 )AS new_str FROM 表名;
(3),字符串长度,用LENGTH
SELECT LENGTH(str1) FROM 表名;
SQLserver中使用 LEN(str1)函数
(4),小写转换(LOWER)
(5),大写转换(UPPER)
(6),替换函数(REPLACE)
REPLACE (对象字符串,替换前的字符串,替换后的字符串)
SELECT str1,str2,str3 REPLACE(str1,str2,str3) AS rep_str FROM 表名
(7),字符串截取函数(SUBSTRING)——PostgreSQL 和MySQL可用
SELECT SUBSTRING(str1 FROM 3 FOR 2) AS new_str FROM 表名;——截取出字符串中第3和第4位的字符
SQL server:SUBSTRING(对象字符串,截取的起始位置,截取的字符数);
Oracle和DB2:SUBSTR(对象字符串,截取的起始位置,截取的字符数);
1-3,日期函数
当前日期(CURRENT_DATE):SELECT CURRENT_DATE
当前时间(CURRENT_TIME):SELECT CURRENT_DATE
截取日期元素(EXTRACT):EXTRACT(日期元素 FROM 日期)——EXTRACT(year FROM date)——MySQL
截取日期元素(DATEPART):DATEPART(日期元素 FROM 日期)——SQL server
1-4,转换函数
(1),类型转换(CAST)
CAST(转换前的值 AS 想要转换的数据类型)——SELECT CAST('2022-09-09' AS DATE) AS date FROM 表名
(2),将NULL转换为其他值(COALESCE)
2,谓词
1-1,LIKE
1-2,BETWEEN AND
1-3,IS NULL,IS NOT NULL
1-4,IN,OR
1-5,EXISIT
3,CASE表达式
CASE——不能省略
WHEN <求职表达式> THEN<表达式>——满足表达式,则XXX
WHEN <求职表达式> THEN<表达式>——满足表达式,则XXX
ELSE <表达式>——否则,则XXX
END——不能省略
(1),搜索case
CASE WHEN sex = '1' THEN '男' WHEN sex = '2' THEN '女' ELSE '其他' END
(2),简单case
CASE sex WHEN '1' THEN '男' WHEN '2' THEN '女' ELSE '其他' END
(3),Oracle扩展——DECODE函数
DECODE(列名,
条件,满足条件后的结果,
条件,满足条件后的结果,
)
(4),MySQL扩展——IF函数
IF(条件,满足条件后的结果,不满足条件后的结果)
八,集合运算
1,表的加减法
1-1,表的加法
(1)UNION(并集)
SELECT a FROM 表1 UNION SELECT b FROM 表2;——会自动去重
SELECT a FROM 表1 UNION ALL SELECT b FROM 表2;——不会自动去重
注意:(1),作为运算对象的记录的列数必须相同,否则会无法计算;(2),作为运算对象的记录中列的类型必须一致,否则无法计算;(3),可以使用任何SELECT语句,但ORDER BY子句只能在最后使用1次;
(2)INTERSECT(交集)
SELECT a FROM 表1 INTERSECT SELECT b FROM 表2;
1-2,表的减法——EXCEPT(差集)
SELECT a FROM 表1 EXCEPT SELECT b FROM 表2;
Oracle中表的减法使用MINUS运算符:SELECT a FROM 表1 EXCEPT SELECT b FROM 表2;
MySQL不支持减法运算符EXCEPT
2,联结(JOIN)
1-1,内联结(INNER JOIN)——只联结共有数据行
INNER JOIN ...ON...
SELECT A.a,B.b FROM A INNER JOIN B ON A.a=B.b;
1-2,外联结(OUTER JOIN)——联结单表所有行
RIGHT/LEFT OUTER JOIN...ON...——左联结左表为主表;右联接右表为主表。最终的结果呈现主表的全部数据
SELECT A.a,B.b FROM A RIGHT/LEFT OUTER JOIN B ON A.a=B.b;
1-3,交叉联结(CROSS JOIN)——笛卡尔积
SELECT A.a,B.b FROM A CROSS JOIN B;
交叉联结无法使用ON子句,最终呈现的结果时两张表中行数的乘积
1-4,过时语法——可通用
SELECT A.a,B.b FROM A,B WHERE A.a=B.b AND a=x;
无法迅速判断内联结或外联结;无法快速判断联结条件或限制条件;
1-5,关系除法
目前无DMBS使用语法
九,SQL高级处理
1,窗口函数
1-1,窗口函数(OLAP函数)
对数据库数据进行实时分析处理的函数
MySQL不支持窗口函数;Oracle和SQLserver中窗口函数称为分析函数
1-2,窗口函数的分类
(1),能够作为窗口函数的聚合函数(SUM\AVG\COUNT\MAX\MIN)
(2),RANK\DENSE_RANK\ROW_NUMBER等专用窗口函数
<窗口函数> OVER ([PARTITION BY<列清单>] ORDER BY BY<排序用列清单>)
PARTITION BY能够设定排序的对象范围——通过PARTITION BY分组后的记录集合称为窗口,窗口意指一个范围;
ORDER BY能够指定按照哪一列、何种顺序进行排序(可使用ASC或DESC进行排序);
当不指定PARTITIN BY时意指将整个表作为一个大窗口使用;
RANK排序:第一位、第二位、第二位、第四位——如果存在相同位次的记录,则会跳过之后的位次;
DENSE_RANK排序:第一位、第二位、第二位、第三位——即使存在相同位次的记录,也不会跳过之后的位次;
ROW_NUMBER排序:第一位、第二位、第三位、第四位——赋予唯一的连续位次
1-3,窗口函数的适用范围
窗口函数只能在SELECT子句中使用,不能在WHERE子句或者GROUP BY子句中使用
SELECT <列名> RANK(列名) OVER (ORDER BY 列名) FROM 表名;
1-4,作为窗口函数使用的聚合函数(以自身记录作为基准进行统计)
SELECT <列名> SUM(列名) OVER (ORDER BY 列名) FROM 表名;
移动平均:SELECT <列名> SUM(列名) OVER (ORDER BY 列名 ROW 2 PRECEDING) FROM 表名;——最近3行的数据统计
ROW——行;PRECEDING——之前;FOLLOWING——之后
ROW 2 PRECEDING——以自身为基准的之前2行,即最近3行
ROW 1 PRECEDING AND 1 FOLLOWDING——以自身为基准的上下两行,总计3行
注意:SELECT 子句+窗口函数+FROM语句+ORDER BY子句(可以通过后缀ORDER BY子句对结果进行排序)
2,GROUPING运算符
仅使用GROUP BY子句和聚合函数无法同时得到小计和合计,若想同时得到,必须使用GROUPING运算符
SELECT '合计' AS product_type,SUM(sale_price) FROM Product UNION ALL SELECT product_type,SUM(sale_price) FROM Product GROUP BY product_type;
1-1,GROUPING运算符
(1),ROLLUP——一次性计算不同聚合键组合的结果(包括GROUP BY()和GROUP BY(product_type))
Oracle、SQLserver、DB2、PostgreSQL:SELECT product_type,SUM(sale_price) AS sum_price FROM Product GROUP BY ROLLUP(product_type);
MySQL:SELECT product_type,SUM(sale_price) AS sum_price FROM Product GROUP BY product_type with ROLLUP;

上述使用ROLLUP所得到的结果中,衣服那一块有多个NULL值,但是产生的原因有所不同,sum_price为4000的记录,因为其注册时间是null;sum_price为5000的小计记录,是超级分组的记录。
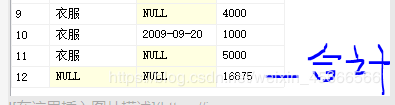
使用GROUPING函数可以避免混淆,该函数在其参数列的值为超级分组记录所产生的Null时返回1,其他情况返回0。
SELECT GROUPING(product_type) AS product_type,
GROUPING(regist_date) AS regist_date, SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);使用GROUPING函数在超级分组记录的键值中插入字符串。
当GROUPING函数的返回值为1时,指定“合计”或者“小计”等字符串,其他情况返回通常列的值。
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY ROLLUP(product_type, regist_date);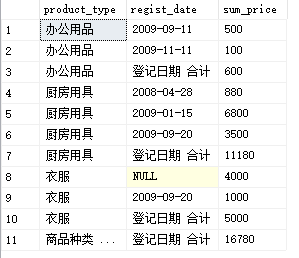
(2),CUBE(包括GROUP BY(),GROUP BY(product_type)和GROUP BY(regist_date))
CUBE的语法和ROLLUP语法相同,只需要将ROLLUP替换为CUBE即可
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_price
FROM Product
GROUP BY CUBE(product_type, regist_date);与ROLLUP的结果相比,CUBE的结果中多出了几行把日期作为聚合键所得到的汇总结果记录。

CUBE可以理解为将使用聚合键进行切割的模块堆积成一个立方体,可以指定2个轴甚至更多轴
(3),GROUPING SETS
GROUPING SETS可以用于从ROLLUP或CUBE的结果中取出部分记录
SELECT CASE WHEN GROUPING(product_type) = 1
THEN '商品种类 合计'
ELSE product_type END AS product_type,
CASE WHEN GROUPING(regist_date) = 1
THEN '登记日期 合计'
ELSE CAST(regist_date AS VARCHAR(16)) END AS regist_date,
SUM(sale_price) AS sum_tanka
FROM Product
GROUP BY GROUPING SETS (product_type, regist_date);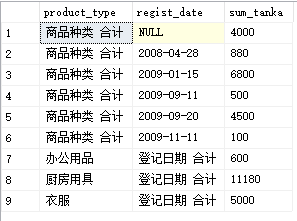
十,连接数据库
1,数据库世界和应用程序世界的连接
驱动:数据和应用层之间的连接工具称之为驱动
现在广泛使用的驱动标准主要有ODBC(open DataBase Connecticity)和JDBC(JAVA DataBase Connecticity)。
2,JAVA基础知识
3,通过JAVA连接PostgreSQL















 4074
4074











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









