










🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:SpiritSight Agent: Advanced GUI Agent with One Look
论文链接:https://arxiv.org/pdf/2503.03196
开源代码:https://huggingface.co/SenseLLM/SpiritSight-Agent-8B
导读
随着现代数字设备的发展,图形用户界面(Graphical User Interface,GUI)自动化一直是人们追求的目标。得益于大语言模型(Large Language Models,LLMs)的最新进展,人们构建了GUI智能体来协助用户与图形界面进行交互,这些智能体能够根据对环境的观察和用户的指令自动做出行动决策。
简介
图形用户界面(Graphical User Interface,GUI)代理在辅助人机交互、自动完成人类用户在数字设备上的导航方面展现出了惊人的能力。理想的GUI代理应具备高精度、低延迟以及对不同GUI平台的兼容性。近期基于视觉的方法通过利用先进的视觉语言模型(Vision Language Models,VLMs)展现出了潜力。虽然这些基于视觉的GUI代理总体上满足了兼容性和低延迟的要求,但由于它们在元素定位方面存在局限性,往往精度较低。为解决这一问题,我们提出了SpiritSight,这是一种基于视觉的端到端GUI代理,在各种GUI平台的GUI导航任务中表现出色。首先,我们使用可扩展的方法创建了一个名为GUI-Lasagne的多层次、大规模、高质量的GUI数据集,赋予了SpiritSight强大的GUI理解和定位能力。其次,我们引入了通用块解析(Universal Block Parsing,UBP)方法来解决动态高分辨率视觉输入中的歧义问题,进一步增强了SpiritSight定位GUI对象的能力。通过这些努力,SpiritSight代理在各种GUI基准测试中优于其他先进方法,证明了其在GUI导航任务中的卓越能力和兼容性。
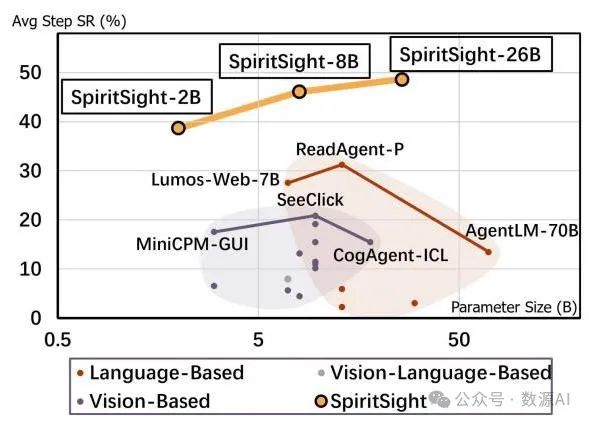
图2. 我们三种规模(2B、8B、26B)的SpiritSight代理与各种先前方法在多模态Mind2Web基准测试中的平均步骤成功率比较。
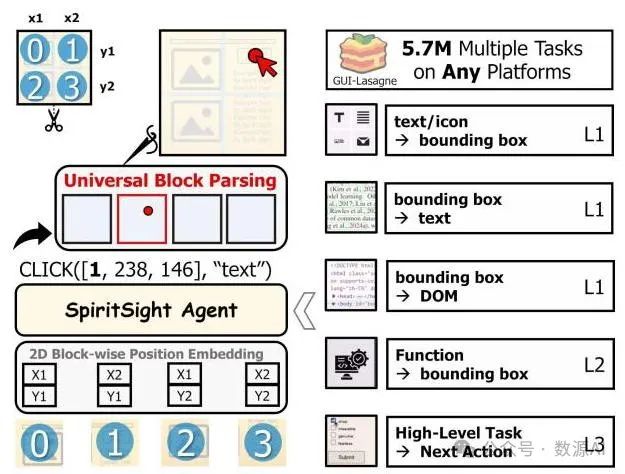
图3. 我们的SpiritSight代理概述。我们开发了一个大规模、多层次、高质量的预训练数据集,使SpiritSight具备三个层次的全面GUI知识。此外,我们引入了通用块解析(Universal Block Parsing,UBP)方法来增强SpiritSight的基础能力。
数据收集
在本节中,我们提出了一种经济高效的数据收集策略,旨在构建一个多层次、大规模且高质量的图形用户界面(GUI)数据集,名为GUI-Lasagne,如图4所示。该数据集有助于使我们的模型在图形用户界面理解、定位和导航方面具备强大的能力。GUI-Lasagne的统计信息如表6所示。
1. 视觉 - 文本对齐
视觉 - 文本对齐是指图形用户界面(GUI)智能体感知GUI视觉外观的基础能力,具体而言,即识别或定位文本/图标元素的能力。我们直接从GUI源数据中收集视觉 - 文本数据。在网页场景中,我们从CommonCrawl [16]和网站排名数据源获取网站URL。然后,我们使用Playwright 开发了一个数据收集工具,从收集到的URL中收集真实世界的网页数据。借助这个工具,我们收集了张网页截图及其DOM数据,这些数据在分辨率和语言方面都具有多样性。此外,我们开发了一个名为InternVL - 图标(InternVL - Icon)的图标识别模型作为图标标注工具,通过从阿里巴巴图标库(Alibaba Icon Library )构建个图标 - 说明文字对的数据集,并使用该数据集对InternVL1.5 - 26B进行微调。然后,我们使用InternVL - 图标为网页上的所有图标生成说明文字进行标注。至于移动场景,我们从AitW [46](一个移动平台上的大规模GUI数据集)收集数据。更多收集细节请参见附录E.1。
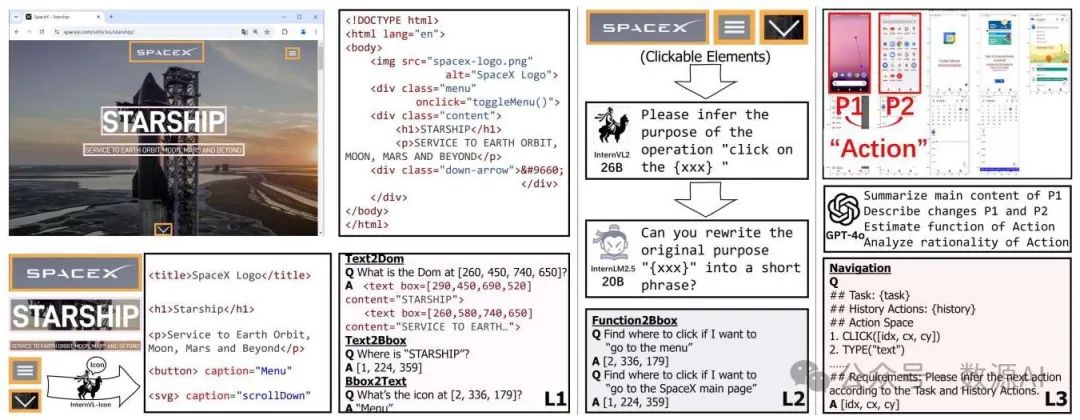
图4. 我们的GUILasagne数据集的收集流程。左、中、右部分分别展示了一级、二级和三级数据的构建。
受李(Lee)等人 [27] 和程(Cheng)等人 [11] 的启发,我们基于收集到的图形用户界面(GUI)源数据构建了三个任务:文本到边界框(text2bbox)、边界框到文本(bbox2text)和边界框到文档对象模型(bbox2dom)。文本到边界框任务促使模型根据给定的文本或图标说明来定位元素。为避免歧义,我们为在屏幕截图中多次出现的元素提供额外的上下文信息。在这三个任务中,文本到边界框任务的数据最为丰富,以帮助模型培养强大的定位能力。边界框到文本任务是文本到边界框任务的逆任务,用于训练模型识别文本和图标。边界框到文档对象模型任务要求模型生成与给定边界框相对应的文档对象模型(DOM)树,如附录 D.4 所示。此任务不仅有助于模型学习识别文本/图标元素,还能帮助其理解图形用户界面布局。为充分利用模型的上下文长度,我们在文本到边界框和边界框到文本任务的每个训练样本中打包多个数据对,并为边界框到文档对象模型任务选择包含尽可能多元素的框。总体而言,我们分别为网页和移动场景构建了总共 190 万个和 110 万个训练样本。这些数据显著增强了我们的 SpiritSight 智能体的图形用户界面基础能力,尤其是图形用户界面定位能力。有关样本构建的更多详细信息,请参阅附录 F。
2. 视觉 - 功能对齐
视觉 - 功能对齐是指模型根据元素功能定位该元素的能力。这类数据无法直接从原始图形用户界面(GUI)数据中获取。受翻译任务中用于数据集收集的回译方法 [48] 的启发,我们利用 InternVL 的图像理解能力来收集功能定位数据。具体而言,我们将每个屏幕截图划分为一个 网格,并以文本形式描述目标元素的大致位置(例如,图像的左上角)。此外,我们在屏幕截图中围绕目标元素放置一个边界框,以指定其精确位置。我们向 InternVL2 - 26B 提供屏幕截图、元素的文本内容或图标说明以及位置描述,以促使其生成元素的功能。此外,我们利用 InternLM2.5 - 20B 来提高生成的功能描述的质量和多样性。根据人工判断,这些功能描述的接受率约为 ,我们认为这足以构建功能定位预训练数据。有关数据收集和验证的更多详细信息,请参阅附录 E. 2。
基于上述策略,我们收集了网络场景中所有交互元素的功能到边界框(function2bbox)对。在移动场景中,我们从图形用户界面(GUI)导航数据集中构建功能定位数据,这将在3.3节中描述。我们使用与文本到边界框(text2bbox)和边界框到文本(bbox2text)任务相同的打包方法进行高效训练,最终获得个训练样本。
3. 可视化图形用户界面导航
我们利用公开可用的AitW [46]数据集来构建我们的图形用户界面(GUI)导航训练数据。AitW是一个大规模的移动导航数据集,其中每张截图都标注了相应的目标、当前步骤等信息。然而,正如AitZ [72]和AMEX [5]中所指出的,AitW数据集包含一些标注错误的样本。我们选择使用GPT - 4o对其进行清理,并采用思维链(Chain - of - Thought,CoT)[60]方法使判断更加准确。具体来说,我们向GPT - 4o提供任务描述、当前动作标注以及当前步骤和下一步骤的截图。然后指示GPT - 4o先总结两张截图并找出它们之间的差异,接着根据这些差异描述当前步骤,最后评估当前动作标注的合理性。有关数据清理和质量验证的更多详细信息,请参阅附录E. 3。
我们过滤掉了GPT - 4o识别为不合理的步骤,最终得到了一个包含个思维链(Chain of Thought,CoT)风格的图形用户界面(GUI)导航训练样本的数据集。利用收集到的CoT风格数据,如3.2节所述,我们可以通过将收集到的步骤描述视为相应元素的函数,为移动场景构建额外的函数接地数据。
4. 其他训练数据
为了增强模型对GUI内容的理解,我们进一步收集了一些公开数据集作为补充,包括文档/网页/移动视觉问答(VQA)数据集[7, 8, 20, 40]、图像描述数据集[12, 54]和移动接地数据集[12, 33],最终得到了个用于模型训练的问答对。
通用块解析
1. 问题陈述
我们使用InternVL2 [9]作为SpiritSight的基础模型,该模型采用动态高分辨率训练方法,在很大程度上保留了输入图像的细节。该方法首先从预定义的一组宽高比中为每个输入图像匹配最佳宽高比,然后将每个图像进行调整大小并分割成像素的块。
然而,这种方法可能会在定位图形用户界面(GUI)元素时引入歧义。图5a展示了一个典型的例子,其中两个截图的宽高比分别为1:2和2:1。根据动态高分辨率策略,这些截图被分割成两个块,一个是垂直分割,另一个是水平分割。假设每个样本中的目标元素在裁剪后的第二个块(块 - 1)内处于相同的相对位置。然后将裁剪后的截图输入到InternVL中,期望模型从这两个相同的输入中预测出不同的位置。我们将这种情况称为定位歧义问题。
通常,一个点在全局坐标系中表示为
其中 和 分别表示原始图像中该点的水平和垂直坐标值。假设对图像进行了缩放并将其划分为 个块。我们可以将对应块中的点 表示为 :
其中 和 (在我们的实验中均设置为 448)分别表示每个块的宽度和高度。 和 表示包含 的块的水平和垂直索引, 和 表示 在该块内的坐标。这些块在输入模型之前被展平为一个序列,因此我们有
其中 表示该块在序列中的索引,满足:
该模型经过训练以逼近映射 ,这本质上是一个多值函数。例如,当输入 为 时, 的可能值包括当 时为 ,或者当 为 2 时为 ,如图 5a 所示。
2. 方法
这种模糊性主要源于扁平化操作,如公式(5)所示,该操作会导致块之间的空间关系丢失。一种解决方案是输入额外的缩略图,但这可能会带来额外的计算和内存开销。我们提出分两步解决这种位置模糊性问题。首先,我们引入二维逐块位置嵌入(2D - BPE)[67],通过为每个块添加两个位置嵌入来捕捉空间信息。其次,我们引入通用块解析(UBP)方法,该方法用特定块的坐标表示取代全局坐标表示。具体而言,我们用公式(4)表示一个点。在这种情况下,对模型进行训练以逼近一个单射映射 ,从而解决模糊性问题。在模型推理过程中,该点的全局坐标可以在后期处理中按如下方式计算:
总体而言,我们的通用块解析(UBP)方法确保了模型输入和输出之间位置信息的清晰映射,从而提高了模型的定位能力。
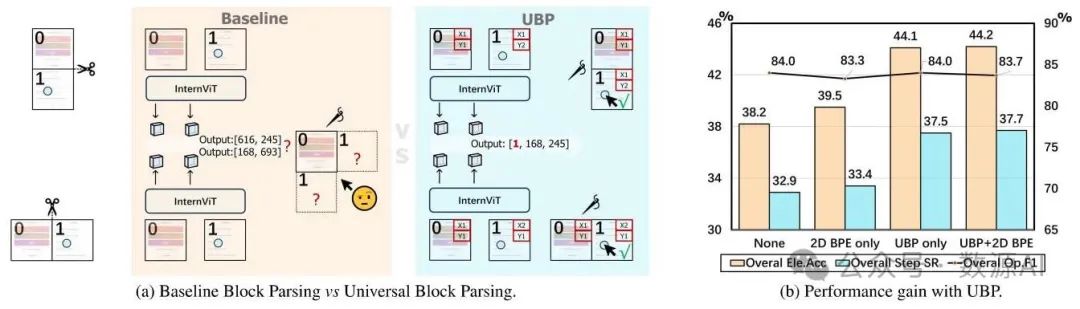
图5. (a) 基线块解析与我们提出的通用块解析(UBP)的比较。(b) 基线块解析和我们提出的通用块解析(UBP)方法在多模态Mind2Web基准测试上的结果。通用块解析(UBP)提高了我们模型的性能。通用块解析(UBP)和二维字节对编码(2D - BPE)的结合取得了最佳结果。
实验与结果
1. 基于高级视觉的图形用户界面代理
在本节中,我们在多模态思维到网页(Multimodal - Mind2Web)[13]这一经典且高质量的图形用户界面(GUI)导航基准测试上,比较了SpiritSight与其他先进方法在各种输入模式和测试配置下的性能。结果如表1所示。使用前50个候选元素作为输入的方法表现最佳。这很明显,因为候选元素的辅助可以显著减少决策空间。然而,这类方法在实际应用中并非特别可行。
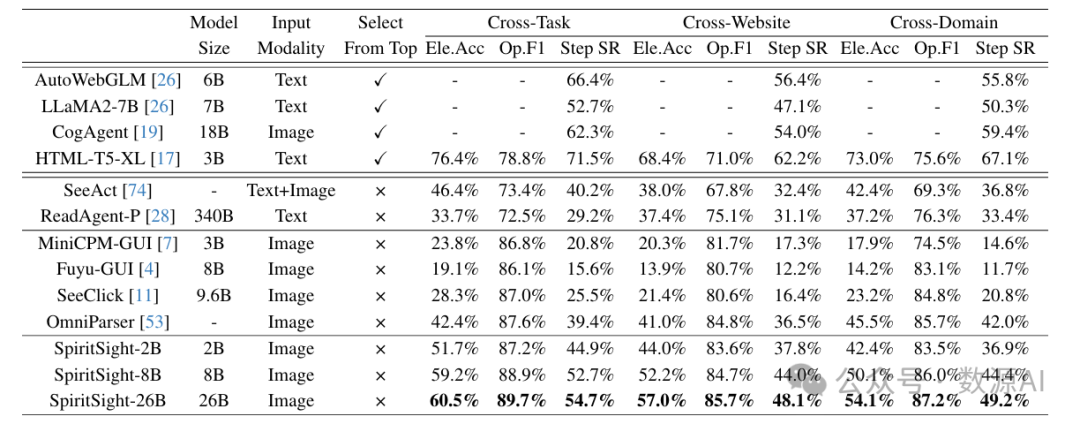
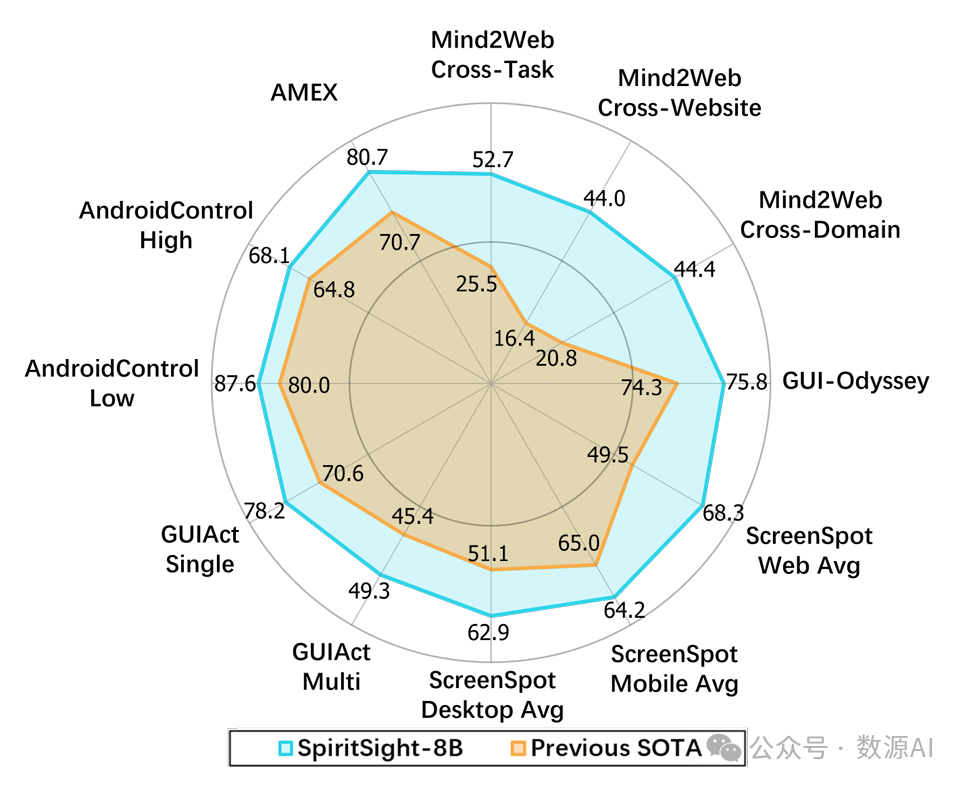
结果表明,SpiritSight显著优于所有不依赖任何候选元素的方法,包括基于视觉的方法、基于语言的方法,甚至基于视觉 - 语言的方法。这证明了SpiritSight在网页GUI导航任务中具有强大的能力。值得注意的是,与其他基于视觉的方法相比,SpiritSight在元素准确率(Ele.Acc)指标上取得了显著优势,这可归因于专门构建的视觉定位训练数据和所提出的统一边界框预测(UBP)方法。
2. 强大的跨平台兼容性
我们在跨多个平台的其他图形用户界面(GUI)导航基准测试中对SpiritSight进行了评估,并将其与表2所示的最先进(SOTA)GUI智能体进行了比较。SpiritSight在这些基准测试中表现最佳,显示了其在多个平台上的强大能力。Odyssey智能体(OdysseyAgent)使用额外的历史截图图像作为输入,但SpiritSight仍取得了相当的结果。
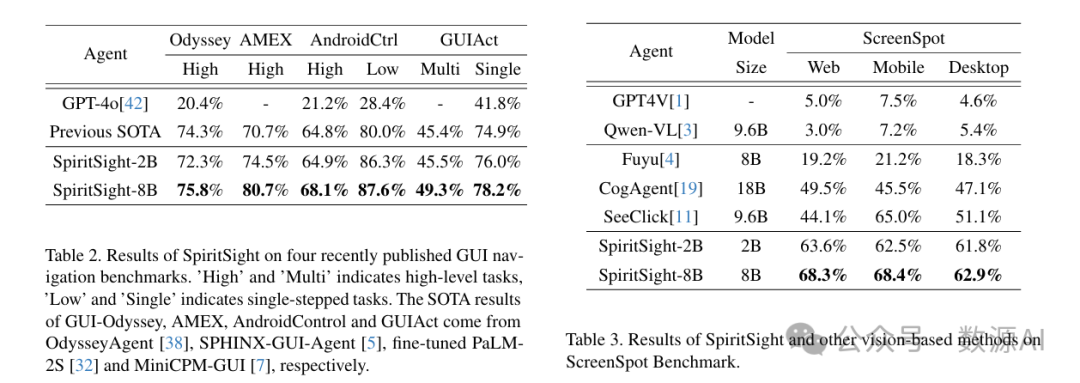
我们还在功能定位基准测试ScreenSpot上对SpiritSight进行了评估。如表3所示,SpiritSight在所有三个平台上均表现出色,展示了其跨平台能力和强大的定位能力。值得注意的是,SpiritSight模型是专门为GUI导航任务训练的,并未特意收集与ScreenSpot对齐的训练数据。SpiritSight在ScreenSpot基准测试中的性能仍有进一步提升的空间。我们在自定义构建的测试数据集上进一步评估了SpiritSight的基础能力,即视觉定位能力。更多细节请参见附录D.4。
3. 识别与定位作为GUI导航的先验条件
为了验证GUI-Lasagne数据三个层级的重要性,我们在预训练阶段逐步从训练集中移除了第三层级、第二层级和第一层级的数据,并在多模态Mind2Web上评估了SpiritSight-8B模型。结果如图6a中的蓝色线所示。可以看出,每个层级的数据都有助于提高步骤成功率(Step SR)。虽然与其他两个层级相比,第一层级数据中的任务与网页导航任务差异最大,但它们为预训练模型提供了有效的初始化。尽管第三层级的数据是从移动场景构建的,但它也有助于基于网页的图形用户界面(GUI)导航任务。这表明联合学习策略有助于SpiritSight在有限资源的情况下,在不同的GUI环境中培养强大的导航能力。
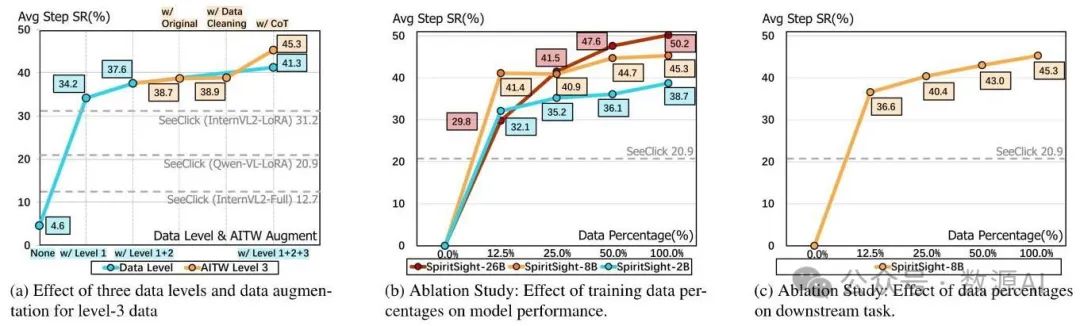
图6. 图形用户界面千层面(GUILasagne)数据集的消融研究以及多模态思维到网页(Multimodal-Mind2Web)基准测试中的缩放效应。
我们还进行了消融实验,以评估数据清洗和思维链(Chain of Thought,CoT)构建策略在三级数据上的有效性,如图6a中的橙色线所示。可以观察到,以思维链的方式进行训练能有效提升模型的图形用户界面(GUI)导航能力,而数据清洗策略的影响相对较小。这可能是因为在大模型的预训练阶段,对错误样本的容忍度相对较高。“使用思维链”和“使用一级+二级+三级数据”的结果差异是由于微调阶段的实现方式不同。更多细节请参见附录D.2。
为了评估我们的GUI-Lasagne数据集的有效性,我们在SeeClick训练数据[11]上使用全参数训练和低秩自适应(LoRA,Low-Rank Adaptation)训练对InternVL - 2(80亿参数)进行训练,分别得到SeeClick(InternVL - 全参数)和SeeClick(InternVL - LoRA)模型。然后,我们在多模态Mind2Web基准测试上对这两个模型进行微调并评估。结果如图6a中的虚线所示,我们还展示了原始SeeClick模型的结果。SeeClick(InternVL - LoRA)的表现优于原始SeeClick模型,这可能归因于InternVL采用的动态高分辨率方法保留了输入图像的细节。SeeClick(InternVL - 全参数)的表现最差,因为SeeClick训练数据的规模不足以使模型在全参数训练期间收敛。仅在GUI-Lasagne一级数据上训练的SpiritSight智能体的表现优于在SeeClick数据上训练的所有三个模型,这证明了GUI-Lasagne数据集的有效性。
4. 统一双向位置编码(UBP)带来的更好定位能力
为了验证统一双向位置编码(UBP)在定位任务上的有效性,我们使用低秩自适应(LoRA)以提高资源利用效率,分别在4种不同设置(以原始设置为基线、二维字节对编码(2D - BPE)、统一双向位置编码(UBP)以及二维字节对编码(2D - BPE)与统一双向位置编码(UBP)结合)下对InternVL进行微调。然后,我们在多模态Mind2Web基准测试上对这些模型进行评估,如图5b所示。可以看出,与基线相比,统一双向位置编码(UBP)在元素准确率(Ele.Acc)方面显示出显著优势,而操作F1分数(Op.F1)的结果在这4种设置下变化不大。这表明统一双向位置编码(UBP)主要通过增强定位能力来提高图形用户界面(GUI)代理的性能。最后,统一双向位置编码(UBP)和二维字节对编码(2D - BPE)的结合取得了最佳结果。这表明统一双向位置编码(UBP)与二维字节对编码(2D - BPE)兼容,从而带来更好的性能。
5. 数据集和模型规模的缩放效应
我们使用多模态思维到网页(Multimodal-Mind2Web)基准测试,探究了预训练数据集和模型大小对灵视(SpiritSight)的影响。结果如图6b所示。灵视-2B(SpiritSight-2B)仅使用八分之一的预训练数据集,就超越了SeeClick [11]。这一出色表现得益于图形用户界面千层面(GUI-Lasagne)数据的高质量和以基础为重点的特性。随着数据集规模的增大,性能也随之提升,这表明收集大规模数据的重要性。灵视-2B在使用较少量的预训练数据时就达到了饱和,而灵视-26B(SpiritSight-26B)似乎还有进一步提升的潜力,这与大语言模型(LLMs)和视觉语言模型(VLMs)的缩放定律相符。
我们还评估了SpiritSight迁移到下游图形用户界面(GUI)代理任务的能力。我们在多模态Mind2Web训练数据的不同比例子集上对SpiritSight-Base(80亿参数)进行微调,并将结果展示在图6c中。值得注意的是,SpiritSight仅使用比例的微调数据就实现了的步骤成功率(Step SR),这表明它在GUI导航任务中具有很强的迁移能力。
6. 对其他语言的有效迁移
探索GUI代理的跨语言能力对于其在非英语环境中的应用非常有益。我们将GUIAct(网页多语言)数据集的训练集和测试集分别划分为英语和中文部分。然后,我们在两组数据上对SpiritSight-Base(80亿参数)进行微调:整个训练集(英语和中文)和仅英语的训练集。结果如表4所示。
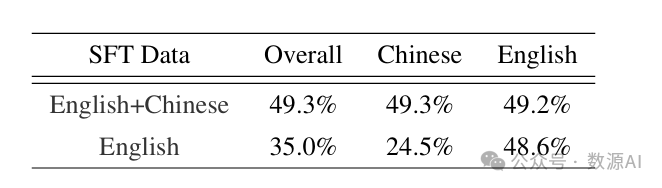
在中英配置下,尽管预训练数据集中中文样本数量少于英文样本,但灵视(SpiritSight)在英文和中文测试集上均取得了相当的效果。在仅英文配置下,灵视在中文测试集上的步骤成功率(Step SR)达到了24.5%,达到了中英配置性能的一半。灵视在中文方面的零样本学习能力源于预训练阶段包含的少量但有效的基础中文数据。
该实验为将图形用户界面(GUI)智能体应用于非英语环境提供了一种范例:通过收集(1)来自目标语言环境的免费网页和移动图形用户界面信息(一级和二级数据),以及(2)少量低成本的高质量图形用户界面导航数据(三级数据)。采用这种语言迁移策略,在非英语环境中只需极少的额外成本,就能实现与英语环境相同的功能。

结论
在本文中,我们提出了一种先进的基于视觉的端到端GUI代理SpiritSight,它在多个GUI平台上具有很高的泛化能力。我们构建了一个高效的多层次、大规模、高质量的GUI预训练数据集,使SpiritSight具备强大的GUI感知、定位和理解能力。此外,我们引入了一种UBP方法来解决模型训练期间动态高分辨率输入中的歧义问题,进一步增强了SpiritSight定位GUI对象的能力。因此,SpiritSight在众多GUI导航基准测试中表现出色,显示出在实际应用中进行实际部署的巨大潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









