






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:EasyControl: Adding Efficient and Flexible Control for Diffusion Transformer
论文链接:https://arxiv.org/pdf/2503.07027
开源代码:https://github.com/Xiaojiu-z/EasyControl

导读
近年来,基于扩散模型的图像生成系统经历了显著的架构演变。技术发展轨迹已逐渐从早期基于UNet的架构转向基于Transformer的DiT(扩散Transformer)模型。在基于UNet的时代,如SD 1.5/XL等预训练模型建立了一个繁荣的生态系统,催生了一系列即插即用的条件生成扩展模块,如ControlNet、IP-Adapter等。这些模块通过冻结预训练参数并引入额外的适配器或编码器架构,实现了预训练模型的灵活扩展,从而推动了文本到图像生成技术的广泛应用。
简介
基于Unet的扩散模型(如ControlNet和IP-Adapter)近期取得了进展,引入了有效的空间和主体控制机制。然而,DiT(扩散变压器,Diffusion Transformer)架构在高效灵活控制方面仍面临挑战。为解决这一问题,我们提出了EasyControl,这是一个旨在将条件引导的扩散变压器统一起来的新颖框架,具有高效性和灵活性。我们的框架基于三项关键创新。首先,我们引入了轻量级条件注入低秩自适应(LoRA)模块。该模块独立处理条件信号,是一种即插即用的解决方案。它避免修改基础模型的权重,确保与定制模型兼容,并能灵活注入各种条件。值得注意的是,即使仅在单条件数据上进行训练,该模块也支持和谐且稳健的零样本多条件泛化。其次,我们提出了位置感知训练范式。这种方法将输入条件标准化为固定分辨率,允许生成具有任意宽高比和灵活分辨率的图像。同时,它优化了计算效率,使框架在实际应用中更具实用性。第三,我们开发了一种结合键值缓存(KV Cache)技术的因果注意力机制,适用于条件生成任务。这一创新显著降低了图像合成的延迟,提高了框架的整体效率。通过大量实验,我们证明了Easy-Control在各种应用场景中都取得了卓越的性能。这些创新共同使我们的框架高效、灵活,适用于广泛的任务。
方法与模型
在本节中,我们将介绍Easy - Control的技术细节,该方法的整体框架如图2所示。EasyControl基于FLUX. 1开发。它包含几个关键组件:条件注入低秩自适应(LoRA)模块(第3.1节)、Easy - Control中的因果注意力机制(第3.2节)、位置感知训练范式(第3.3节)以及推理用的键值缓存(KV Cache)(第3.4节)。关于扩散变压器(DiT)的预备知识详见补充材料(第A节)。
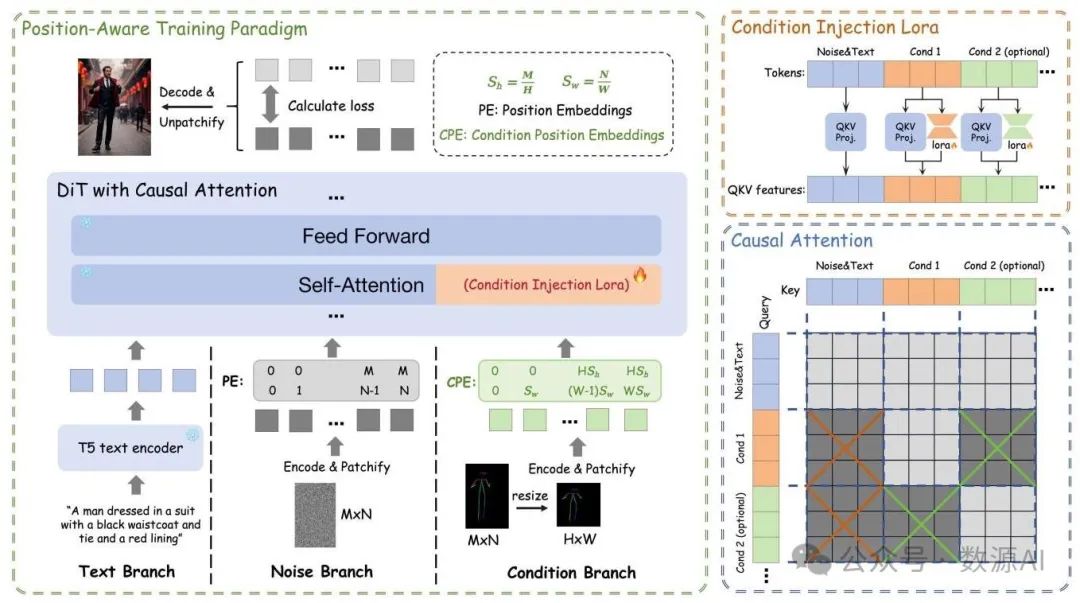
图2. EasyControl框架示意图。条件信号通过新引入的条件分支注入到扩散变压器(Diffusion Transformer,DiT)中,该分支与轻量级、即插即用的条件注入低秩自适应(Condition Injection LoRA)模块一起对条件令牌进行编码。在训练过程中,每个单独的条件都进行单独训练,其中条件图像被调整为较低分辨率,并使用我们提出的位置感知训练范式进行训练。这种方法能够实现高效且灵活的分辨率训练。该框架采用了因果注意力机制,这使得能够实现键值(Key-Value,KV)缓存,从而显著提高推理效率。此外,我们的设计便于无缝集成多个条件注入低秩自适应模块,实现稳健且协调的多条件生成。
1. 条件注入低秩自适应(LoRA)模块
为了在保留预训练模型泛化能力的同时有效整合条件信号,我们通过引入一个额外的条件分支来扩展FLUX架构。与引入单独控制模块的传统方法不同,我们的方法将条件信息无缝集成到现有架构中,同时避免了冗余参数和计算开销。
在基于变压器(Transformer)的架构中,输入特征表示首先被投影为查询(Q)、键(K)和值(V)特征,然后再由自注意力机制进行处理。给定对应去噪(文本、噪声)和条件分支的输入表示 ,标准的QKV变换定义如下:
其中 是所有分支共享的投影矩阵。虽然这种设计允许进行高效的参数共享,但它并未明确优化条件信号的表示。为解决这一局限性,我们引入了 LoRA(低秩自适应,Low-Rank Adaptation),在保持其他分支不变的同时自适应地增强条件表示:
因此,条件分支更新后的 QKV 特征为:
其中 ( )是对 LoRA 变换进行参数化的低秩矩阵。值得注意的是,文本和噪声分支保持不变:
通过仅对条件分支应用基于 LoRA 的自适应方法,我们确保条件信号能有效地注入到模型中,而不会破坏预训练的文本和噪声表示。这种有针对性的自适应方法使模型能够在保持其原始特征空间完整性的同时灵活地整合条件信息,从而实现更可控、高保真的图像生成。
2. EasyControl 中的因果注意力
因果注意力(Causal Attention)是一种单向注意力机制,旨在通过允许序列模型中的每个位置仅关注先前位置及其自身来限制信息流,从而确保时间因果性。这是通过在Softmax操作之前对注意力对数应用一个值为0和的掩码来实现的,数学表达式如下:
其中确保因果约束,QKV是来自噪声、文本和条件分支的拼接特征。为了提高推理效率并有效整合多个条件信号,我们设计了两种专门的因果注意力机制:因果条件注意力(Causal Conditional Attention)和因果相互注意力(Causal Mutual Attention)。这些机制通过不同的掩码策略来控制信息流,以平衡条件聚合和隔离。
2.1. 因果条件注意力
该机制遵循两条规则:(1)每个条件分支内的条件内计算;(2)在训练期间,使用注意力掩码防止条件标记查询去噪(文本和噪声)标记。形式上,我们将单条件训练中的输入序列定义为:
其中 表示噪声和文本标记, 表示条件标记,我们定义了一个注意力掩码 来调节注意力流。具体来说,该掩码的公式如下:
其中 表示总序列长度。
这种设计阻止了从条件分支到去噪(噪声和文本)分支的单向注意力,同时允许去噪分支标记自由聚合条件信号。通过严格隔离从条件到去噪的查询,该设计在推理过程中为每个分支实现了解耦的键值缓存(KV Cache)状态,从而减少了冗余计算并显著提高了图像生成效率。
2.2. 因果相互注意力
我们的模型仅在单条件输入上进行训练,每个条件标记(condition token)都会学习与去噪标记(denoising token)的优化交互。在多条件推理过程中,虽然所有条件都能与去噪标记正常交互,但由于未对跨条件标记交互进行训练,会出现条件间干扰(见图5)。这种机制能有效整合多个条件信号,同时避免推理过程中的干扰。形式上,我们将多条件推理中的输入序列定义为:
其中 表示噪声和文本标记, 表示对应第 个条件的标记,我们定义一个注意力掩码 来调节注意力流。具体而言,该掩码的公式为:
其中 表示总序列长度。这种结构化掩码确保了在图像标记聚合所有条件信息的同时,不同的条件保持独立,防止相互干扰。
3. 位置感知训练范式
为了提高条件图像生成中的计算效率和分辨率灵活性,我们提出了一种位置感知训练范式。该范式基于一种简单的方法:将高分辨率控制信号从其原始维度 下采样到较低的目标分辨率 。在我们的实验中,我们设置为 。然后,调整大小后的图像通过变分自编码器(VAE)编码器编码到潜在空间,接着进行分块操作以提取条件标记。这些标记与原始扩散变压器(DiT)模型中的噪声标记和文本标记相结合,并通过迭代去噪进行处理。
虽然这种简单的降尺度方法在处理主体条件(例如人脸图像)时效果良好,但它无法在空间条件(例如Canny边缘图)下保持空间对齐,从而限制了模型在任意分辨率下生成图像的能力。为了解决这个问题,我们引入了两种针对性的策略:(1)用于空间条件的位置感知插值(Position-Aware Interpolation,PAI),它在调整大小时保持像素级对齐;(2)用于主体条件的位置编码偏移策略(详见补充材料B节),它在高度维度上对位置编码应用固定位移。
3.1. 位置感知插值
为了保持条件标记和噪声标记之间的空间一致性,我们引入了位置感知插值(Position-Aware Interpolation,PAI)策略,该策略在条件信号的调整大小过程中对位置编码进行插值。这确保了模型能够准确捕捉控制条件和生成图像像素之间的空间关系。
给定原始条件图像的尺寸 (M,N) 和调整后的尺寸 (H,W),缩放因子计算如下:
其中 和 分别表示高度和宽度方向的缩放因子。
对于调整大小后的条件图像中的给定块(i,j),其在原始图像中对应的位置 映射如下:
其中 和 。这种映射将调整大小后的图像中的任何块与其在原始图像中的对应位置对齐。
原始图像中位置编码的序列表示为:
而调整大小后的图像的插值序列为:
这确保了调整大小后的图像中保留了空间关系。
3.2. 损失函数
我们的损失函数采用了流匹配损失(flow-matching loss)。其数学表达式如下:
其中 表示时刻 的图像特征,为输入条件; 表示速度场; 指原始图像特征; 是预测的噪声。
4. 通过键值缓存(KV Cache)实现高效推理
通过利用因果注意力机制,我们的框架将条件分支隔离为一个独立于计算的模块,该模块与去噪时间步无关。这种独特的设计使得键值缓存(KV Cache)技术在推理过程中能够得到新颖的应用。
由于条件分支的计算与去噪时间步无关,我们在初始时间步仅对所有条件特征的键值(KV)对进行一次预计算并存储。这些缓存的键值对可在所有后续时间步中重复使用,从而避免了相同条件特征的冗余重新计算。这种方法通过避免 倍的重新计算(针对 个去噪步骤)来减少推理延迟,同时保持生成质量和模型灵活性(详见补充材料 D 节)。
实验与结果
本节首先介绍EasyControl(简易控制)的实现细节,接着概述评估指标。然后,我们展示实验结果,包括定性和定量分析以及消融实验。
1. 实现细节
我们采用FLUX. 1 dev作为预训练的DiT(扩散变压器,Diffusion Transformer)。对于每个空间或主题条件训练,我们使用4块A100 GPU(80GB),每块GPU的批量大小为1,学习率为1e - 4,训练100,000步。在推理过程中,应用流匹配采样,采样步骤为25步。(训练数据详情见补充材料的C节。)
2. 实验设置
视觉比较:我们评估以下设置:(1)单条件生成;(2)使用定制模型的单条件适配;(3)多条件整合(如图3和图4所示,我们还在补充材料的F节中详细比较了几种身份定制方法[15, 35, 71]);(4)分辨率适应性(补充材料的G节中有详细说明)。定量比较:我们评估以下方面:(1)单条件和双条件生成下的推理时间和模型参数数量(以评估效率,如表1所示);(2)以人脸 + OpenPose作为多条件时的可控性、生成质量和文本一致性(补充材料的F节中有详细说明);(3)单条件设置下的可控性、生成质量和文本一致性(补充材料的E节中有详细说明)。
比较方法:对于单条件情况,我们将我们的方法与Controlnet[83]、OminiControl[69]和Uni-ControlNet[88]进行比较。对于多条件设置,我们将我们的方法与几种即插即用的基线方法进行评估,包括Controlnet+IP-Adapter[80]、Controlnet+Redux[30]和Uni-Controlnet[88]。我们还比较了几种与ControlNet集成的身份定制方法[15, 35, 71]。
3. 实验结果
3.1. 定性比较
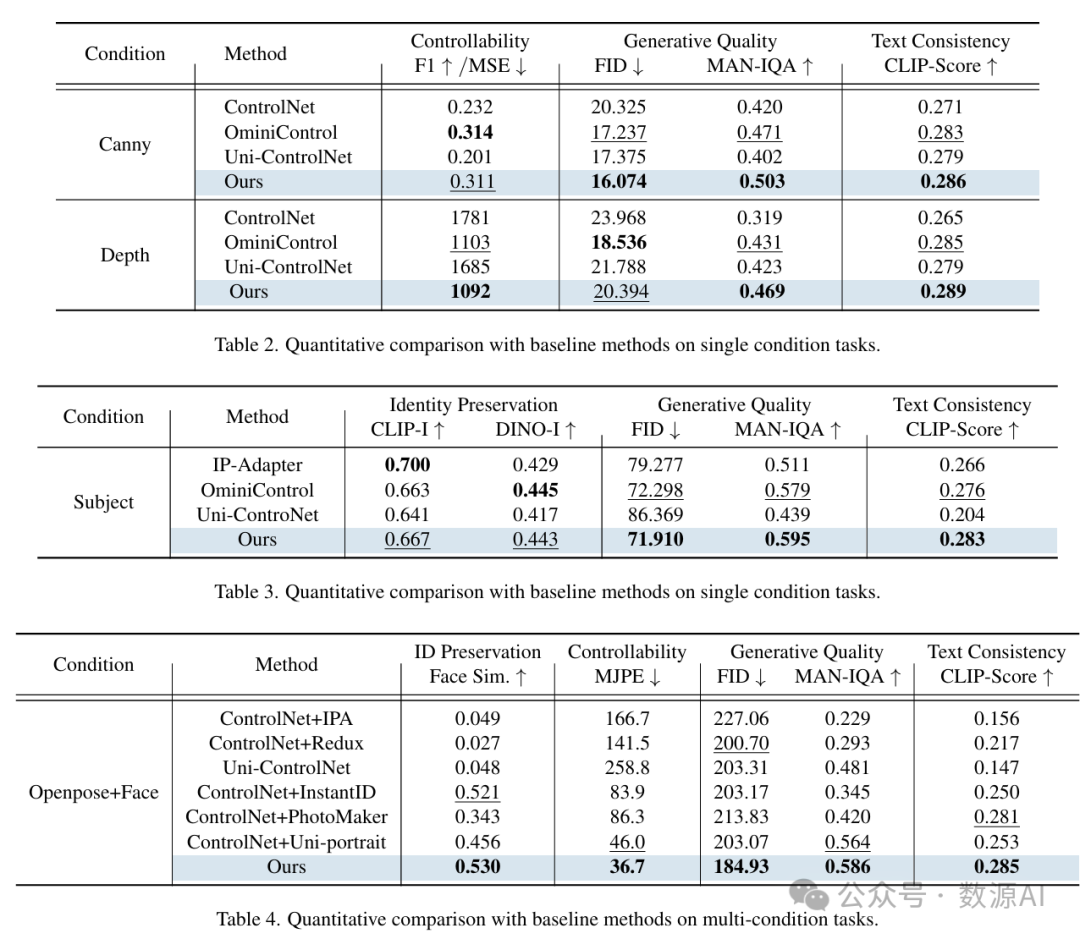
图3 (a)比较了不同方法在单控制条件下的性能。在Canny控制下,Uni-ControlNet和ControlNet出现颜色不一致的情况,导致与输入文本存在偏差。在深度控制下,Uni-ControlNet无法生成连贯的图像,而ControlNet和OmniControl会产生伪影,例如狗和沙发融合在一起。在OpenPose控制下,我们的方法能够保留文本渲染效果,而其他方法则会削弱或失去这种能力。在主体控制方面,IP-Adapter和Uni-ControlNet无法与参考图像对齐。总体而言,我们的方法在各种控制条件下都能确保文本一致性和高质量的图像生成。
图3 (b)比较了不同方法在四个自定义模型上生成图像的即插即用能力。最左侧的列展示了来自LoRA微调的Flux 1 Dev模型的原始文本到图像(T2I)结果。ControlNet和OminiControl都牺牲了风格化效果,并且存在质量下降的问题。相比之下,我们的方法展示了在不损失可控性的情况下将风格化损失降至最低的能力,这体现了我们方法的即插即用能力。
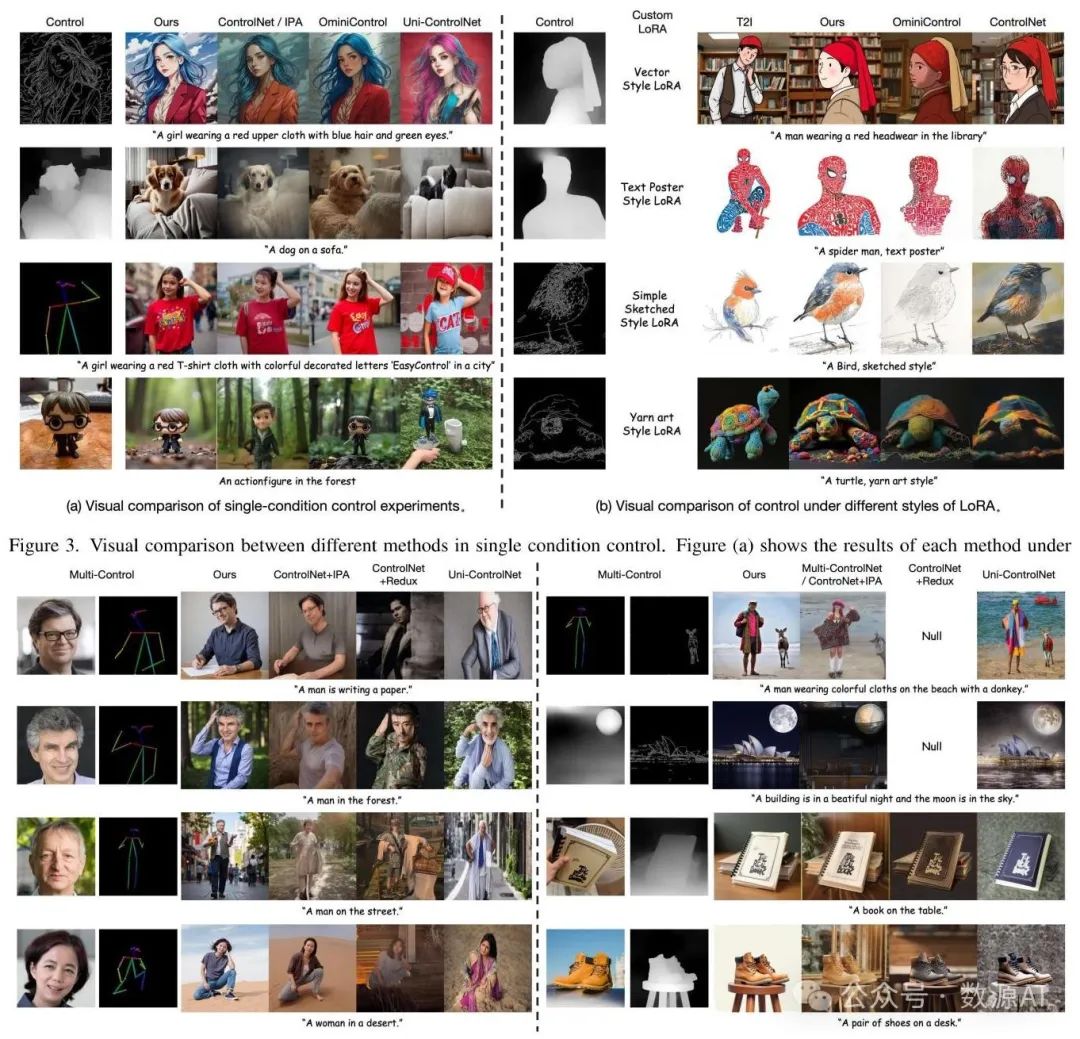
图4. 多条件控制下不同方法的视觉比较。
图4展示了多条件控制下不同方法的可视化比较。对于OpenPose和面部(Face)控制,我们的方法实现了更优的身份一致性和可控性。相比之下,其他方法在控制条件之间存在冲突。虽然ControlNet和IP-Adapter的组合保持了可控性,但牺牲了身份一致性。ControlNet+Redux和Uni-ControlNet既无法保持身份一致性,也无法保证可控性,这在主体深度控制场景(右数第三/第四行)中也有所体现。对于OpenPose-Canny和Depth-Canny组合,我们的方法和Uni-ControlNet生成的图像都能满足控制条件。然而,Uni-ControlNet难以与文本输入相匹配,生成的图像质量较低。Multi-ControlNet无法同时满足这两个条件。这些结果证明了我们的方法在无缝整合多个条件方面的灵活性。
3.2. 定量比较
表1展示了在配备20个采样步骤的单块A100 GPU上,各种算法的推理时间和相应的模型参数数量。在单条件设置下,我们的完整模型表现最佳,推理时间为16.3秒,与没有位置感知训练范式(Position-Aware Training Paradigm,PATP)和键值缓存(KV Cache)的简化版本相比,推理时间减少了58%。值得注意的是,我们的方法在实现这种效率的同时,将参数数量保持在最低限度(),这明显低于ControlNet的30亿个参数。对于双条件任务,我们的完整模型推理时间为18.3秒,比没有PATP和KV Cache的简化版本快75%。这一性能与ControlNet + IPA(16.8秒)相当,同时模型规模要小得多(3000万个参数,而ControlNet + IPA为)。这些结果凸显了我们提出的PATP和KV Cache机制在不影响模型紧凑性的情况下提高推理效率的有效性。
3.3. 消融实验
在我们的消融研究中,我们分析了移除每个模块的影响。首先,用标准的低秩自适应(LoRA)结构(无条件注入LoRA,W.O. CIL)取代条件注入LoRA(CIL),可以实现单条件控制,但无法以零样本的方式推广到多条件控制。对于位置感知训练范式(PATP),我们训练了一个无PATP的模型,在保持其他训练设置不变的情况下,控制信号和噪声都固定在分辨率。当生成高分辨率(例如)或非正方形宽高比(例如)的图像时,该模型会出现伪影和质量下降的问题。相比之下,我们基于PATP的训练有效地缓解了这些问题。对于因果注意力,由于注意力的自适应特性,移除因果相互注意力(CMA)仍然可以进行图像生成。然而,条件之间的冲突会降低控制精度,导致在多控制场景中出现诸如人体姿势改变等偏差,以及物体位置的偏移,例如月亮的位置。当所有模块一起使用时,我们的方法实现了最高的可控性、生成质量,以及对不同分辨率和宽高比的适应性。

图5. 不同设置下的可视化消融实验。
结论
总之,我们推出了EasyControl,这是一个用于统一条件引导扩散模型的高效且灵活的框架。我们的框架利用了三项关键创新:(1)轻量级条件注入低秩自适应(LoRA)模块,该模块能够在不改变核心模型功能的情况下无缝集成各种条件信号。(2)位置感知训练范式,可确保适应各种分辨率和宽高比。(3)一种结合键值缓存(KV Cache)技术的新型因果注意力机制,显著提高了效率。这些组件共同解决了可控图像生成中效率和灵活性的挑战。EasyControl在广泛的视觉任务中实现了强大的可控性和高质量的结果。大量实验证明,它能够处理复杂的多条件场景,同时适应不同的分辨率和宽高比。我们的框架为条件图像生成提供了一个强大且适应性强的解决方案。

















 920
920

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









