






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
数源AI 最新论文解读系列

论文名:CameraCtrl II: Dynamic Scene Exploration via Camera-controlled Video Diffusion Models
论文链接:https://arxiv.org/pdf/2503.10592
开源代码:https://hehao13.github.io/Projects-CameraCtrl-II/

导读
近年来,视频扩散模型取得了显著进展,它可以根据文本描述生成高保真且时间连贯的视频。这些模型接受用户定义的控制,并且在数据集大小和计算资源方面具有可扩展性,能够生成较长且符合物理规律的视频。例如,Sora可以生成具有真实物理效果和复杂运动的一分钟长视频。因此,这些视频扩散模型已成为建模和模拟现实世界动态场景的有前景的工具。
简介
本文介绍了相机控制二代(CAMERACTRL II),这是一个通过相机控制的视频扩散模型实现大规模动态场景探索的框架。先前基于相机条件的视频生成模型在生成相机大幅移动的视频时,存在视频动态性减弱和视角范围有限的问题。我们采用一种逐步扩展动态场景生成的方法——首先增强单个视频片段内的动态内容,然后将这种能力扩展到跨广泛视角范围的无缝探索。具体而言,我们构建了一个具有大量动态且带有相机参数注释的数据集用于训练,同时设计了一个轻量级的相机注入模块和训练方案以保留预训练模型的动态性。基于这些改进的单片段技术,我们允许用户迭代指定相机轨迹以生成连贯的视频序列,从而实现扩展的场景探索。跨多种场景的实验表明,相机控制二代(CAMERACTRL II)在相机控制的动态场景合成方面,比先前方法具有更广泛的空间探索范围。
方法与模型
我们提出了相机控制二代(CAMERACTRL II),以使用视频扩散模型实现相机控制的大规模动态场景生成。为了生成具有高度动态性的此类视频,我们精心策划了一个新的数据集(第 3.2 节),并开发了一种有效的相机控制注入机制(第 3.3 节)。第 3.4 节介绍了我们通过视频扩展技术在动态场景中实现大范围探索的方法。第 3.1 节提供了相机控制的视频扩散模型的必要预备知识。
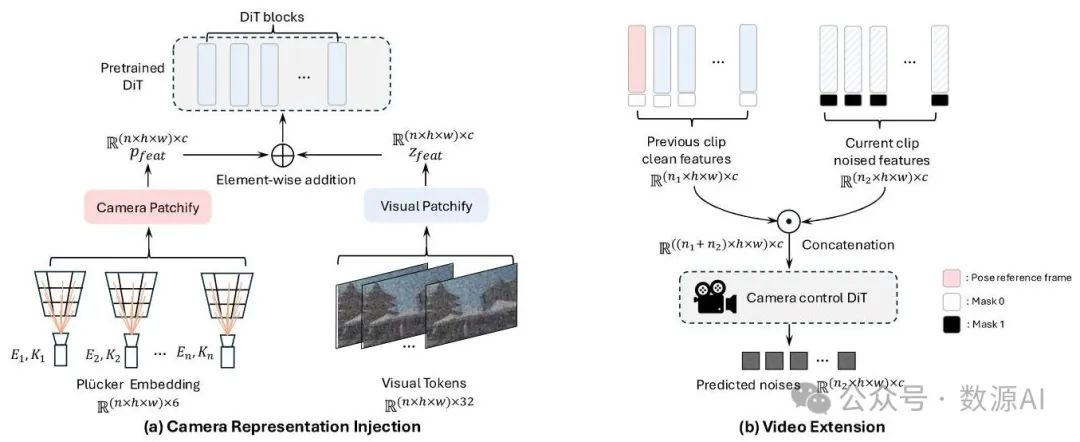
图3. CAMERACTRL II的模型架构。(a) 给定一个预训练的视频扩散模型,CAMERACTRL II在模型初始阶段添加了一个额外的相机分块层。它以普吕克嵌入作为输入,输出与视觉特征形状相同的相机特征。在第一个DiT层之前,将这两种特征逐元素相加。(b) 保留前一个视频片段的特征不变,同时对当前特征添加噪声。拼接后,将特征输入到一个相机控制DiT;我们只计算当前片段的标记的损失。在两个图中我们都省略了文本编码器,在第二个图中省略了相机特征。
1. 预备知识
给定一个预训练的潜在视频扩散模型和相机表示 ,一个相机控制的视频扩散模型学习对视频令牌的条件分布 进行建模,其中 表示来自视觉分词器 [60] 的编码潜在变量, 表示文本/图像提示。训练过程包括在每个时间步 向潜在变量添加噪声 以获得 ,并使用以下目标优化一个变压器模型来预测该噪声:
在推理时,我们从高斯噪声 开始初始化,并使用欧拉采样器迭代恢复视频潜在变量 ,同时以输入图像和相机参数为条件。
对于相机表示,我们遵循最近的工作 [21, 56] 并采用普吕克嵌入 [47],它提供了强大的几何解释和细粒度的逐像素相机信息。具体来说,给定相机外部矩阵 和内部矩阵 ,我们为每个像素 (u, v) 计算其普吕克嵌入 。这里, 表示世界空间中的相机中心, 表示从相机到像素的光线方向, 是归一化的 。最终的普吕克嵌入 为每一帧构建,其空间维度 和 与编码的视觉令牌的维度相匹配。
2. 数据集策划
具有准确相机参数标注的高质量视频数据集对于训练可控制相机的视频扩散模型至关重要。虽然现有的数据集,如RealEstate10K [62]、ACID [36]、DL3DV10K [35]和Objaverse [12]提供了多样的相机参数标注,但它们主要包含静态场景,且专注于单一领域。先前的工作,如CameraCtrl [56]、MotionCtrl [54]和Camco [56]表明,在这些静态场景数据集上进行训练会导致动态内容生成能力显著下降。为解决这一局限性,我们引入了REALCAM数据集,这是一个新的带有精确相机参数标注的动态视频数据集。整体的数据处理流程如图2所示。
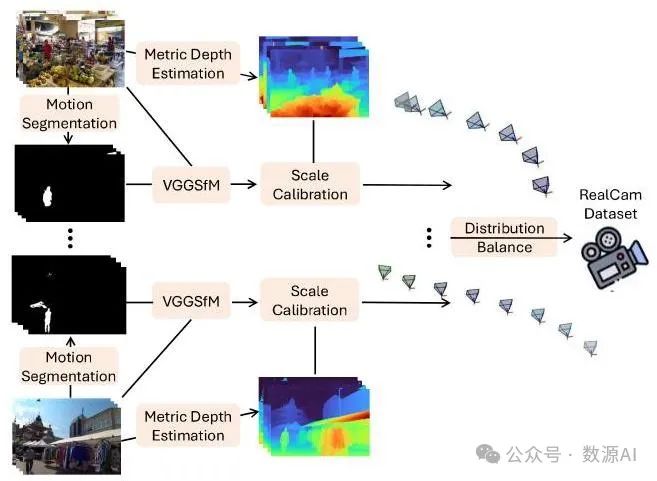
图 2. 数据集策划流程。我们省略了动态视频选择的过程。
从动态视频中进行相机估计。虽然近期工作中使用的合成场景可以提供精确的相机参数标注,但它们需要对单个场景和环境进行大量的手动设计。这种劳动密集型的过程极大地限制了数据集的可扩展性和多样性。因此,我们选择从真实世界的视频中整理我们的数据集。为保持场景多样性,我们获取了包括室内环境、鸟瞰图和街道场景等各种场景的视频。我们的数据处理流程包括几个关键步骤:首先,我们使用运动分割模型TMO [11]来识别视频中的动态前景对象。然后使用RAFT [50]来估计视频的光流。利用掩码和光流,通过对静态背景区域的光流进行平均,我们获得了相机运动的定量度量。仅当视频的平均光流超过一个经验确定的阈值时才选择该视频,以确保有足够的相机运动。之后,我们使用VGG - SfM [53]来估计每一帧的相机参数。然而,初步实验揭示了两个关键挑战:1) 从单目视频进行运动恢复结构重建本质上会产生任意的场景尺度,这使得学习一致的相机运动变得困难。2) 真实世界的视频相机轨迹分布不均衡,某些相机轨迹类型(如向前运动)出现的频率过高。这可能导致模型对常见轨迹类型过拟合,而在出现频率较低的相机运动类型上表现不佳。因此,我们对数据集进行了以下两项修改。
统一尺度的相机参数校准。为了在不同场景间建立统一的尺度,我们开发了一个校准流程,将任意场景尺度对齐到度量空间。对于每个视频序列,我们首先选择个关键帧,并使用度量深度估计器[8]估计它们的度量深度。然后我们从VGG - SfM的输出中获取相应的运动恢复结构(SfM)深度。每一帧的度量深度和VGG - SfM深度之间的比例因子可以表示为:
其中表示像素坐标,是Huber损失函数。我们使用随机抽样一致性(RANSAC)[20]来解决这个最小化问题,以确保对深度估计误差具有鲁棒性。一个场景的最终比例因子计算为各个帧尺度的平均值。将这个因子乘以外部矩阵的相机位置向量,得到。
相机轨迹分布平衡。我们采用一种系统的方法来分析和平衡相机轨迹类型的分布。我们首先在相机轨迹上检测关键相机位置(关键点):对于每个点,我们通过其前后的 个点拟合两条直线,如果这些直线之间的夹角超过阈值 ,则将该点标记为关键点。这些关键点将相机轨迹划分为几个线段,其方向由拟合的直线向量确定。相机移动距离最长的线段定义了轨迹的主要移动方向。沿着每个线段,我们分析相机旋转矩阵以识别显著的视角变化。在相邻线段之间,我们通过测量它们的角度偏差来识别转弯,主线段之后的转弯被定义为轨迹的主要转弯。根据视角变化和转弯的数量及幅度,为每个轨迹分配一个重要性权重。然后,我们根据 个主要方向和 个主要转弯将轨迹分为 个类别。为了平衡数据集,我们通过移除重要性得分较低的轨迹来修剪冗余的轨迹类型,从而使数据集的相机轨迹分布更加均匀。
3. 为视频生成添加相机控制
有了我们的动态视频数据集和相应的相机参数注释,接下来我们探索如何在视频扩散模型中实现相机控制,并保留生成视频的动态特性。这需要精心设计相机参数注入模块和训练策略。一个关键挑战是在纳入相机控制的同时,保持模型生成动态场景的能力。我们将在以下章节详细介绍我们的方法。
轻量级相机注入模块。先前的方法 通常采用一个专用编码器来提取相机特征,然后将其注入到每个扩散变压器(DiT)或卷积层中。这些全局相机注入方法 [2] 可能会过度限制视频动态,限制生成内容中的自然运动变化。相反,我们使用一个新的用于相机标记化的分块层,仅在扩散模型的初始层注入相机条件,该分块层与视觉分块层的维度和下采样率相匹配。视觉标记 和普吕克嵌入 分别通过各自的分块层进行处理,以获得视觉特征 和相机特征 。如图 3 (a) 所示,在流经其余的 DiT 层之前,它们通过逐元素相加 进行组合。如表 4 所示,这种简单而有效的方法在实现更好的相机控制的同时,比编码器 - 注入器方法能更好地保留动态运动。
使用有相机标签和无标签的数据进行联合训练。在 REALCAM 数据集上使用改进的相机注入模块训练 DiT 模型,仍然会限制模型生成多样化内容的能力,因为与预训练数据相比,REALCAM 仅涵盖了一部分场景。为了解决这一局限性,我们提出了一种联合训练策略,该策略同时利用有相机标签和无标签的视频数据。对于有标签的数据,我们如前所述纳入从估计的相机参数得到的普吕克嵌入。对于无标签的数据,我们使用全零的虚拟普吕克嵌入作为条件输入。这种联合训练框架还有一个额外的优势:实现用于相机控制的无分类器引导(cfg),类似于广泛采用的无分类器文本引导 [22]。我们将相机无分类器引导公式化为:
其中 表示时间步 时的加噪潜变量, 表示去噪网络, 表示空条件, 和 分别是文本和相机条件的引导权重。这种公式化允许通过适当调整引导权重来提高相机控制的准确性。通过这种训练方案,我们的模型在学习有效的相机条件的同时,对真实场景保持良好的泛化能力。
4. 用于场景探索的顺序视频生成
在获得一个能够生成相机可控动态视频的模型后,我们尝试通过顺序视频生成来实现更广泛的场景探索。
用于场景探索的剪辑级视频扩展。我们将单剪辑相机可控视频扩散模型进行扩展,以支持逐剪辑的顺序生成。在训练过程中,对于之前生成的视频剪辑,我们从其最后帧中提取视觉标记,作为生成下一剪辑的上下文条件。对于当前剪辑,我们按照标准扩散过程为其视觉标记添加噪声,以获得。这些标记沿着序列维度进行拼接,得到,其中表示拼接后的总标记数量。我们引入一个二进制掩码(条件标记为1,待生成标记为0),并将其与沿着通道维度进行拼接,形成。3.3节中的模型利用这个组合特征以及相应的普吕克嵌入来预测添加的噪声,仅针对生成剪辑中的标记根据公式(1)计算损失。这一过程如图3(b)所示。在推理过程中,给定一条新的相机轨迹,我们从之前生成的剪辑中选择预定义的帧作为条件,使用户能够通过顺序相机轨迹探索生成的场景,同时保持连续剪辑之间的视觉一致性。
在顺序视频生成中,我们使用初始轨迹的第一帧作为参考,来计算所有生成剪辑之间的相对姿态。这个统一的坐标系确保了整个序列的几何一致性,并防止了剪辑之间的姿态误差累积。模型蒸馏以加速推理。为了加快推理速度并改善用户体验,我们实施了一种两阶段蒸馏方法。首先,我们采用渐进式蒸馏[44],在保持视觉质量的同时,将所需的神经函数评估次数(NFE)从96次减少到16次。原来的96次NFE包括32次无条件生成、32次文本条件生成和32次相机条件生成。如表1所示,蒸馏后的模型在相机控制精度方面没有出现明显下降。当使用在中生成一个4秒的视频时,采样时间显著减少,从13.83秒降至2.61秒。这个采样时间包括DiT模型推理时间和VAE解码时间。
为了进一步加速,我们应用了最近提出的蒸馏方法APT [34]进行一步生成。表1展示了蒸馏后的质量和加速情况。显然,APT [34]实现了显著的加速,但导致了条件生成质量的下降。考虑到原始的APT [34]使用了一千多个GPU,更多的计算资源和更大的批量大小可以进一步提高合成质量,我们将这部分工作留待未来进行。
实验与结果
本节对CAM - ERACTRL II进行了全面评估,将其与现有方法进行比较,并验证其设计选择。因此,本节的组织如下。实现细节在4.1节提供。评估指标和数据集规格分别在4.2节和4.3节描述。在4.4节中,我们将CAMERACTRL II与其他方法进行比较。4.5节展示了详细的消融研究。最后,我们在4.6节提供了CAMER - ACTRL II的一些可视化结果。
1. 实现细节
我们的模型基于一个内部的基于Transformer的文本到视频扩散模型,大约有个参数。作为一个潜在扩散模型,它采用了类似于MAGViT2 [60]的时间因果变分自编码器(VAE)分词器,时间下采样率为4,空间下采样率为8。我们每4帧采样一次相机位姿,使得相机位姿的数量与视觉特征的数量相同。在训练过程中,我们保持所有基础视频扩散模型的参数不冻结,允许对所有参数进行联合优化。我们分两个阶段训练模型。第一阶段是针对单剪辑的CAMERACTRL II(3.3节),分辨率为,进行100,000步训练,批量大小为640,使用时长从2秒到10秒的视频剪辑。数据组成保持相机标注数据和未标注数据的比例为4:1。在第二阶段,我们在更高的分辨率下对模型进行微调,同时训练视频扩展(3.4节)。这个阶段进行50,000步训练,批量大小为512。前一个剪辑的条件帧数量范围从最少5帧到总帧数的。两个训练阶段都使用AdamW优化器。学习率最初设置为,在500步内从开始进行预热,权重衰减为0.01,β值分别为0.9和0.95。最后使用余弦学习率调度器将学习率衰减到。我们第一阶段使用,第二阶段使用。在推理过程中,我们采用Euler采样器,步数为32,偏移量为12 [31]。我们将文本和相机的分类自由引导(CFG)尺度分别设置为7.5和8.0。
2. 评估指标
我们使用六项指标来全面评估基线方法和我们的方法的不同方面,更多细节见附录。1) 视觉质量:我们采用弗雷歇视频距离(Fréchet Video Distance,FVD)[51]来衡量生成视频的整体质量。2) 视频动态保真度:我们提出运动强度这一指标来评估生成视频的动态程度。这一量化指标利用RAFT提取的密集光流场,计算视频帧中前景物体的平均运动幅度。为了将物体运动与相机运动分离,我们将TMO生成的分割掩码应用于光流场,计算每个剩余像素的运动为,并将弧度转换为度。最终的运动强度表示所有帧中所有前景像素的平均光流幅度。3) 相机控制精度:参照CameraCtrl [21],我们使用平移误差(TransErr)和旋转误差(RotErr)来衡量条件相机位姿与从生成帧中估计的相机位姿之间的对齐程度。我们使用TMO [11]从生成视频中提取运动模式,并使用VGGSfM [53]估计相机参数。为了解决结构从运动(Structure from Motion,SfM)中固有的尺度模糊性,我们使用绝对轨迹误差(Absolute Trajectory Error,ATE)[48]将估计的相机轨迹与真实轨迹对齐,具体做法是将两条轨迹居中,找到最佳尺度因子,通过奇异值分解(Singular Value Decomposition,SVD)计算旋转,并确定对齐平移。对齐后,我们将平移误差计算为对应相机位置之间的平均欧几里得距离,将旋转误差计算为对应相机方向之间的平均角度差。4) 几何一致性:我们将VGGSfM [53]应用于生成的视频,并计算VGGSfM成功估计相机参数的比例。它表示生成场景的几何一致性的质量。5) 场景外观连贯性:探索一个场景需要模型根据连续的相机轨迹为同一场景生成连续的视频片段。为了评估这些片段之间的视觉一致性,我们首先使用预训练的[43]视觉编码器为视频片段中的每一帧提取特征,然后对这些特征求平均值,以获得每个视频片段的视频特征。之后,我们计算不同视频特征之间的余弦相似度,并将这一指标称为外观一致性。
3. 评估数据集
我们的评估数据集由来自两个来源的800个视频片段组成:从RealEstate [62]测试集中采样的240个视频,以及来自我们处理的带有相机标注的真实世界动态视频的560个视频。我们根据第3.2节中分析的不同相机轨迹类别对视频进行了采样。
4. 与其他方法的比较
定量比较。为了评估CAMERACTRL II的有效性,我们在图像到视频(I2V)设置中将其与两种具有代表性的方法,即MotionCtrl [54]和CameraCtrl [21]进行比较。由于这两种方法无法直接基于先前生成的视频片段生成新的视频片段,我们使用前一个视频片段的最后一帧作为条件图像来生成下一个片段。此外,得益于我们对基础模型架构的最小修改和联合训练策略,我们的方法也可应用于相机控制的文本到视频(T2V)生成。因此,我们在相机控制的T2V任务中将CAMERACTRL II与AC3D [2]进行比较。由于这些方法支持的相机参数数量不同,我们对它们的相机参数进行时间下采样,作为相机输入。如表2所示,在两种设置下,CAMERACTRL II在所有指标上都显著优于先前的方法。在I2V设置中,与MotionCtrl和CameraCtrl相比,我们的方法实现了更好的弗雷歇视频距离(FVD)和更高的运动强度。相机控制精度和几何一致性也得到了提高,表现为更低的平移误差(TransErr)、旋转误差(RotErr)和更高的几何一致性。与AC3D相比,在T2V设置中也观察到了类似的改进。定性比较。我们还在图4中提供了定性比较。如前两行(I2V设置)所示,CAMERACTRL II更准确地遵循输入的相机轨迹,而CameraCtrl [21]忽略了相机的向上移动。此外,CAMERACTRL II能够生成更具动态性的视频,而CameraCtrl倾向于生成静态视频。第三行和第四行在T2V设置中比较了CAMERACTRL II与AC3D [2]。CAMERACTRL II有效地将相机控制与物体运动相结合,成功生成了如移动车辆等动态元素。相比之下,AC3D忽略了相机的向前移动,并且没有严格遵循文本提示,未能生成一辆公交车。


图4. 定性结果。相机轨迹显示在左侧。前两行共享相同的相机轨迹,第二组相机轨迹用于最后两行。我们在图像到视频(I2V)设置下将CAMERACTRL II与CameraCtrl [21]进行比较(前两行),第一张图像为条件图像。我们还在文本到视频(T2V)设置下将其与AC3D [2]在最后两行进行比较。在这两种情况下,CAMERACTRL II都严格遵循相机轨迹的每个部分,并且具有更好的视频动态效果。而CameraCtrl忽略了相机的向上运动,AC3D忽略了轨迹末端相机的向前运动。
5. 消融研究
CAMERACTRL II的设计包含三个关键组件:数据集构建、将相机控制注入预训练的视频扩散模型,以及多片段视频扩展方法。在本节中,我们进行了广泛的消融研究以验证每个组件。所有模型均在分辨率下进行训练,先进行50,000步的单片段训练,然后以相同分辨率进行30,000步的多片段视频扩展训练。
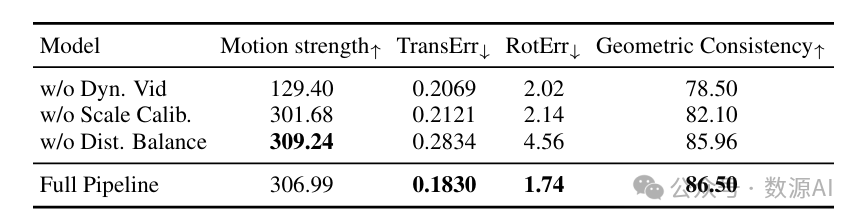
数据构建流程各组件的有效性。首先,我们仅使用静态数据(表3,无动态视频),即RealEstate10K [62]进行训练,研究纳入动态视频的必要性。该模型在运动强度(129.40对比306.99)和相机控制能力方面表现下降。这表明,在相机控制的视频扩散模型训练过程中使用带有相机位姿注释的动态视频,对于在保持相机控制的同时实现高质量和高动态生成至关重要。
然后,我们通过去除尺度校准步骤(表3,无尺度校准)来检验其重要性。结果显示,没有这一步骤,模型的相机控制误差更高(平移误差0.2121对比0.1830,旋转误差2.14对比1.74),几何一致性更低。这验证了我们的假设,即将场景尺度归一化到相同的度量空间有助于模型学习更一致的几何关系,从而实现更精确的相机控制和更轻松的场景重建。
之后,我们分析了相机轨迹类型分布平衡的效果(表3,无分布平衡)。没有这一步骤,模型在相机控制精度和几何一致性方面出现显著下降。这证实了平衡现实世界视频中相机轨迹分布的极端长尾分布,对于在不同相机运动模式下实现稳健的相机控制和几何一致性至关重要。
模型设计和训练策略的有效性。接下来,我们对相机位姿注入模块的设计选择和训练策略进行消融研究。首先,我们评估使用单个分块层从普吕克嵌入中提取相机特征的有效性。为了进行比较,我们实现了一个模型变体,该变体使用了一个类似于CameraCtrl的更复杂的编码器,并在DiT模型开始时使用提取的相机特征。如表4(复杂编码器)所示,虽然这种更复杂的架构在平移误差方面取得了相当的性能,但我们简单的分块层设计在其他指标上取得了更好的结果。这一发现表明,一个简单的特征提取层足以将相机表示转换为生成过程的有效引导信号。
然后,我们研究了相机条件注入位置的影响。虽然在每个DiT层注入相机特征(表4 多层注入)能达到相当的相机控制精度,但会显著降低运动强度。这一结果支持了我们的观点,即相机控制信息应仅用于引导整体视频生成。在模型处理局部细节的较深层添加相机特征,会限制模型生成动态视频的能力。因此,在DiT模型的初始层添加相机表示就足够了。
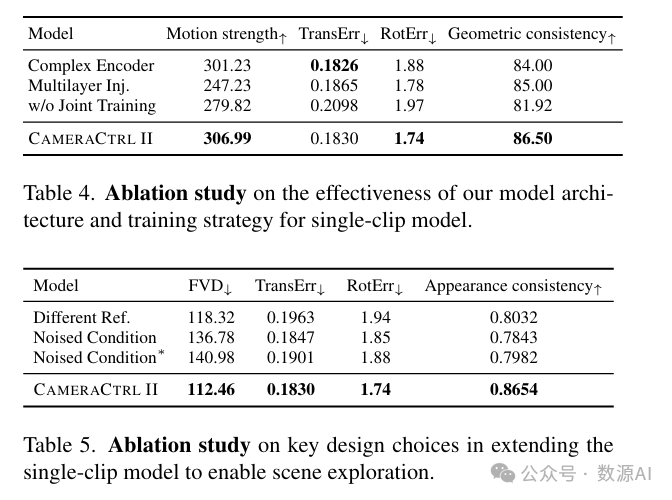
接下来,我们研究了使用无相机标注的额外视频数据联合训练模型的有效性(表4 无联合训练)。结果表明,取消这种联合训练会导致动态性降低。这是因为额外的视频数据使我们的模型接触到更多样的视觉领域和物体运动类型,而这些是RealCam数据集中未涵盖的。此外,联合训练通过实现逐相机的无分类器引导,有助于提高相机控制性能,这在平移误差、旋转误差和几何一致性方面得到了体现。
视频扩展的关键设计选择。最后,我们研究了视频扩展的两个重要设计选择。首先,我们研究了定义用于计算相对相机姿态的参考帧的不同策略。一种方法是使用每个剪辑的第一帧作为该剪辑内的局部参考帧(表5 不同参考)。我们的方法使用第一个剪辑的第一帧作为全局参考帧,来计算所有相机轨迹的相对相机姿态。结果表明,使用全局参考能实现更好的相机控制精度和外观一致性。这是因为共享参考帧有助于在剪辑和相机轨迹条件之间保持一致的几何关系,使模型更容易学习剪辑之间的平滑过渡。
我们将逐剪辑扩展方法与另一种策略进行了比较。在另一种模型(表5 噪声条件)中,训练期间向所有剪辑添加噪声,并在条件剪辑和目标剪辑上计算损失。然而,在推理期间,仅使用干净的条件剪辑,这造成了训练和推理设置之间的差异。这种不匹配导致了FVD和外观一致性指标的性能下降。即使在推理时尝试通过向条件帧添加少量噪声来缩小这种差距,性能仍然不理想(表5 噪声条件')。相比之下,我们的方法在训练和推理中都保持无噪声的条件剪辑一致。
6. 可视化结果
不同场景探索。我们首先展示了CAMERACTRL II在不同场景下的可视化结果,以展示其在相机控制方面的泛化性能。如图5所示,我们的模型可以应用于各种场景(如类似我的世界的游戏场景、19世纪黑白的伦敦雾都街道、废弃医院室内、奇幻世界的户外徒步以及动漫风格的宫殿场景)。此外,CAMERACTRL II可以有效地控制相机运动(相机左右平移、完整旋转等)并保持适当的动态效果。

图5. CAMERACTRL II在不同场景下的可视化结果。我们的模型在各种视觉环境中展示了有效的相机控制能力,包括我的世界风格的游戏场景(第一行)、黑白的伦敦雾都街道(第二行)、废弃医院内部(第三行)、奇幻森林徒步小径(第四行)和动画宫殿场景(最后一行)。结果是在图像到视频(I2V)设置下生成的,以第一张图像作为条件图像。每行左侧显示了相机轨迹。
生成场景的3D重建。我们的方法生成具有条件相机姿态的高质量动态视频,有效地将视频生成模型转变为视图合成器。这些生成视频的强3D一致性使得能够进行高质量的重建。具体来说,我们使用FLARE [61]从生成视频中提取的帧推断详细的3D点云。如图6所示,我们的方法生成的视频可以重建为高质量的点云,证明了我们的模型实现了卓越的3D一致性。

图6. CAMERACTRL II生成场景的3D重建。利用生成的视频帧,我们使用FLARE [61]来估计场景的点云。

图7. 失败案例可视化。围栏位于预期的相机轨迹上。CAMERACTRL II严格遵循轨迹,生成了一个围栏结构受损的视频,这与现实不符。
结论
在本文中,我们介绍了CAMERACTRL II,这是一个使用户能够通过精确的相机控制来探索生成的动态场景的框架。我们首先构建了REAL - CAM,这是一个由带有相机位姿注释的动态视频组成的数据集。然后,我们设计了一个轻量级的相机参数注入器,它在DiT(扩散变压器,Diffusion Transformer)的初始层集成相机条件,并采用相应的联合训练策略来保留预训练模型生成动态场景的能力。此外,我们开发了一种剪辑级扩展方法,该方法允许模型根据先前生成的内容和新的相机轨迹生成新的视频剪辑。实验结果证明了我们的方法在生成由相机控制的动态视频方面的有效性,同时在连续的视频剪辑中保持了高质量和时间一致性。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









