






🌐 社群导航
🔗 点击加入➡️【AIGC/LLM/MLLM/3D/自动驾驶】 技术交流群
最新论文解读系列

论文名:DualToken: Towards Unifying Visual Understanding and Generation with Dual Visual Vocabularies
论文链接:https://arxiv.org/pdf/2503.14324
项目链接:暂无
导读
视觉理解和生成所需的不同表示空间,给在大语言模型的自回归范式内统一这两者带来了挑战。为重建而训练的视觉分词器(vision tokenizer)擅长捕捉低级感知细节,因此非常适合视觉生成,但缺乏用于理解任务的高级语义表示。相反,通过对比学习训练的视觉编码器(vision encoder)能很好地与语言对齐,但在解码回像素空间以进行生成任务时却面临困难。为了弥合这一差距,我们提出了双令牌(DualToken)方法,该方法在单个分词器中统一了理解和生成的表示。然而,在单个分词器中直接整合重建和语义目标会产生冲突,导致重建质量和语义性能均下降。双令牌(DualToken)没有强制使用单一码本处理语义和感知信息,而是通过为高级和低级特征引入单独的码本将它们分离,有效地将它们固有的冲突转化为协同关系。因此,双令牌(DualToken)在重建和语义任务中都取得了最先进的性能,同时在下游多模态大语言模型(MLLM)的理解和生成任务中表现出显著的有效性。值得注意的是,我们还表明,作为一个统一的分词器,双令牌(DualToken)超越了两种不同类型视觉编码器的简单组合,在统一的多模态大语言模型(MLLM)中提供了更优的性能。
简介
在大语言模型(LLM)的自回归范式内统一视觉理解和生成已成为当前的研究热点,催生了如CM3leon、变色龙(Chameleon)、鸸鹋3(Emu3)和VILA - U等代表性工作。为了实现多模态自回归生成,这些统一模型需要一个视觉分词器(visual tokenizer)来离散化视觉输入,以及一个相应的逆分词器(detokenizer)将令牌映射回像素空间。
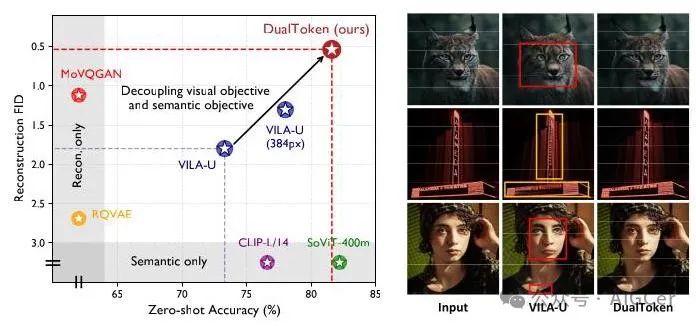
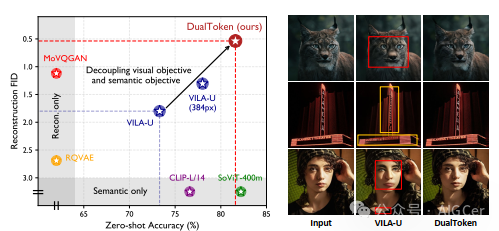
图1. 与最先进的视觉编码器的比较。(左)我们比较了基线方法和双令牌(DualToken)在ImageNet - 1K(验证集)上的零样本分类准确率和重建FID。双令牌(DualToken)在这两项任务中取得了与仅语义方法和仅重建方法相当或更优的结果。(右)VILA - U和双令牌(DualToken)的重建结果,我们的双令牌(DualToken)明显优于VILA - U,后者存在严重的失真和模糊问题。
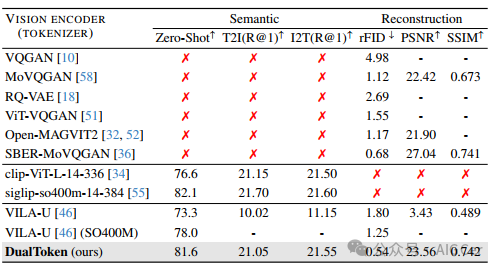
表1. 与最先进的视觉编码器或分词器的比较。对于语义指标,我们测量了ImageNet零样本分类准确率,以及Flickr8K数据集上的文本到图像/图像到文本检索(R@1)。对于重建指标,我们测量了ImageNet - 1K(验证集)上的重建弗雷歇 inception 距离(rFID)、峰值信噪比(PSNR)和结构相似性指数(SSIM)。我们的方法不仅优于VILA - U,并且在语义指标上达到了与最先进的SigLIP ViT - SO400M模型相当的性能,还缓解了VILA - U在重建过程中面临的结构失真和模糊问题。我们的方法在重建指标上也超越了诸如MoVQGAN等专用模型,达到了最先进的性能。
方法
本节正式介绍我们统一分词器的设计,并解释其双视觉码本如何在大语言模型的下一个标记预测范式中用于统一的多模态理解和生成。
1. 动机
正如文献中所讨论的,基于CLIP(对比语言-图像预训练,Contrastive Language-Image Pretraining)的编码器根据语义相似性对图像进行聚类,而基于VQVAE(矢量量化变分自编码器,Vector Quantized Variational Autoencoder)的编码器则根据颜色和纹理等低级属性对图像进行分组。这表明,为重建而训练的编码器主要提取低级感知信息,而经过语言对齐预训练的CLIP系列编码器则天然地捕捉高级语义信息。我们认为,这种表示空间上的差异在下游多模态大语言模型(MLLM,Multimodal Large Language Model)的性能中起着至关重要的作用。
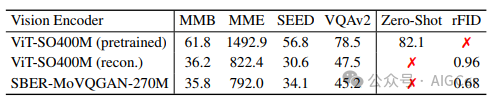
为了验证这一观点,我们首先按照LLaVA - 1.5的流程进行了一项初步实验。如表2所示,与原始的SigLIP模型相比,以重建为目标训练的编码器在下游MLLM视觉 - 语言理解任务中的性能显著下降,这证实了在MLLM中,高级语义特征对于视觉推理比低级感知特征更为关键。
然而,要在单个MLLM中同时实现视觉理解和生成,必须尽可能准确地将视觉标记解码回像素空间。但是,由于SigLIP编码器专注于高级语义信息且缺乏纹理细节,简单地对其特征进行离散化并在不调整编码器的情况下训练解码器会导致图像重建质量不佳。因此,提出一种统一的标记器对于在单个MLLM中实现高质量的视觉理解和生成至关重要。
2 具有双码本的统一视觉标记器
为了构建统一的标记器,我们从最简单的方法入手,即直接将重建损失和语义损失相结合来优化整个视觉塔,并使用单一的视觉词汇表对其特征进行标记,这与VILA - U类似。具体来说,如图2(左)所示,我们使用siglip - so400m - patch14 - 384的预训练权重初始化视觉编码器,以确保强大的文本 - 图像对齐。然后,在模型的深层特征与其初始状态之间计算语义损失,以约束模型不丧失其语义能力。
表2. 在LLaVA - 1.5框架内,不同视觉编码器的下游视觉理解性能。ViT - SO400M(预训练)指的是原始的预训练siglip - so400m - 14 - 384模型,而ViT - SO400M(重建)指的是采用相同架构但从头开始仅为重建而训练的编码器,以控制模型大小和架构等因素。
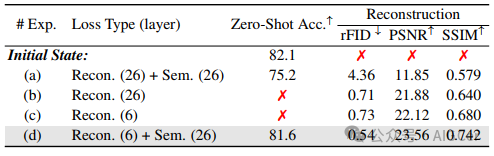
然而,如表3(a)所示,这种直接的方法导致了两个目标之间的明显冲突。一方面,尽管应用语义损失来保留模型原有的语义表示能力,但事实证明实现这一目标很困难,因为语义性能指标与原始模型相比显著下降,这反映了重建训练目标对语义能力造成的破坏。另一方面,模型也难以实现令人满意的重建质量,重建图像往往会出现失真和模糊的情况(图2)。
为了解决这个问题,我们通过一种分层方法将重建目标和语义目标的学习解耦,如图2(右)所示。具体来说,应用重建损失来监督视觉塔的浅层(第1 - 6层),而应用语义损失来监督更深的层(第26层和池化头)。然后,通过残差向量量化分别对浅层和深层的特征进行离散化,从而得到低级和高级视觉词汇表。
我们采用指数移动平均(Exponential Moving Average,EMA)策略来更新码本。为了提高码本利用率,我们实施了一种重启策略,即如果码本中的某个聚类在一定步数内未被使用,则用当前批次的一个输入随机替换它。为了确保编码器输出与码本条目紧密对齐,我们使用向量量化(Vector Quantization,VQ)承诺损失。VQ承诺损失定义为:
因此,总损失被公式化为重建损失、语义损失和VQ承诺损失的加权和。
其中,重建损失是用于重建输入图像的逐像素损失、学习感知图像块相似度(Learned Perceptual Image Patch Similarity,LPIPS)损失和对抗损失的组合:
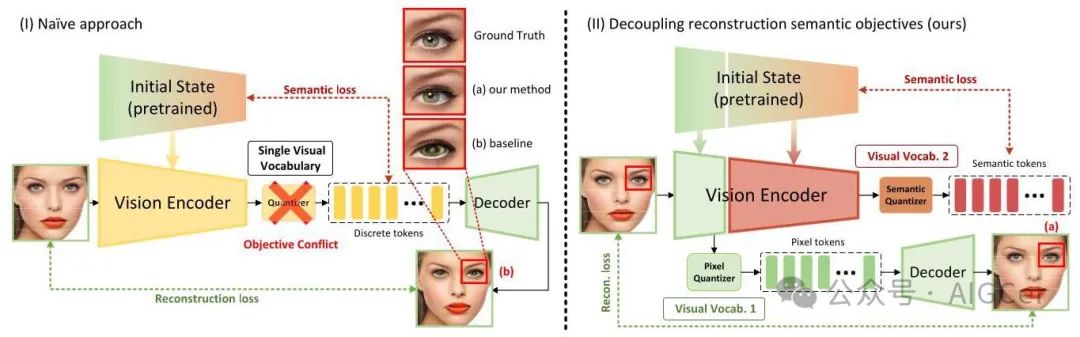
图2. 我们统一视觉分词器的概述。给定输入图像,视觉编码器提取的特征使用残差量化进行离散化。然后,离散的视觉特征同时被输入到视觉解码器中以重建图像,并用于执行文本 - 图像对齐。在此过程中,计算重建损失和对比损失以更新视觉塔,使其能够生成与文本对齐的离散视觉特征。
表3. 双令牌(DualToken)将重建目标和语义目标之间的冲突转化为协同关系。直接结合这两个目标会导致重建性能急剧下降(a与b对比)。然而,与仅使用重建作为目标相比,分层结合重建损失和语义损失可获得更好的重建性能(d与c对比)。我们在最后一行突出显示了我们的方法。
而语义损失简单地计算为模型第26层特征表示 与其对应的初始状态 之间的 距离
有趣的是,如表3 (d) 所示,即使不添加额外的对比学习阶段来增强语义能力,仅依靠简单的 损失来约束语义表示,在我们的分层学习策略中加入重建学习目标对模型的语义能力造成的损害也极小。更有趣的是,如表3 (b)、(c) 和 (d) 所示,与仅进行重建训练相比,在更深层学习语义目标实际上增强了浅层的重建任务,成功地将语义目标和重建目标之间的冲突转化为积极关系。
3. 统一理解与生成
在本节中,我们展示了如何在统一的多模态大语言模型(MLLM)中集成 DualToken 的双视觉码本。如图3 (c) 所示,为了在大语言模型(LLM)的自回归范式下对文本和视觉内容进行建模,首先将像素视觉标记和语义视觉标记沿着它们的嵌入维度拼接,形成统一的视觉标记。然后将这些统一的视觉标记与文本标记拼接,构建一个多模态标记序列。接着以自回归的方式训练模型,以预测视觉和文本标记的下一个标记。为简单起见,我们将我们的多模态大语言模型的语言词汇表定义为一个有限集 ,而将低级和高级视觉词汇表分别定义为 和 ,其中 、 分别表示语言标记、低级视觉标记和高级视觉标记的词汇表大小。
对于视觉标记,由于残差量化在每个视觉位置 引入了代码的深度堆叠结构,我们基于 RQ - VAE中的深度变换器实现我们的视觉头。与原始的深度变换器不同,原始深度变换器使用单个头来预测所有深度的对数几率,我们引入了单独的分类头来计算每个对应深度的残差的对数几率。具体来说,高级语义标记和低级像素标记由独立的视觉头——像素头和语义头——处理,如图3所示。两个头共享相同的结构,包括三层深度变换器(每层深度为8)和八个分类头。
给定位置 处视觉标记的大语言模型隐藏状态 ,我们的深度变换器自回归地预测 个残差标记 。对于 ,深度 处深度变换器的输入,记为 ,定义为直至深度 的标记嵌入之和
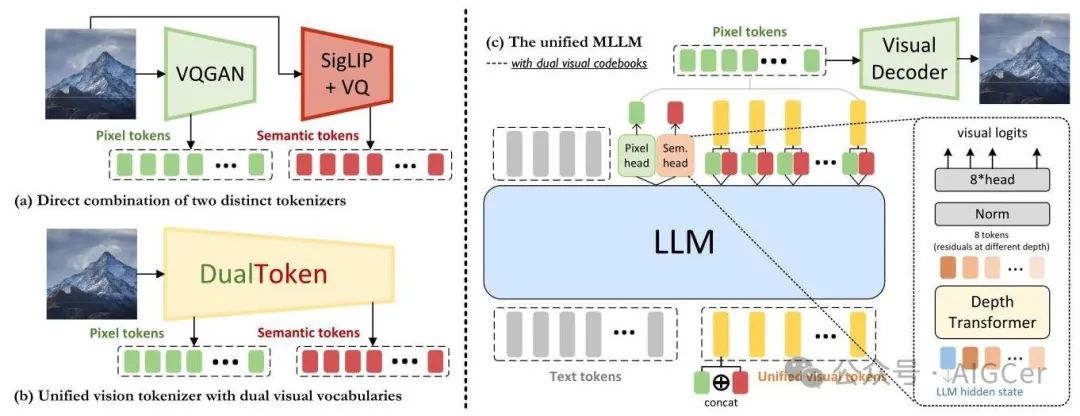
图3. 我们利用双视觉码本进行统一视觉理解和生成的框架概述。(a) 直接使用 VQGAN 和 SigLIP 分别获取高级(语义)和低级(像素)视觉码本。(b) 我们的方法:在统一的视觉分词器中解耦高级和低级视觉码本。图像被转换为低级视觉标记(绿色)和与文本对齐的语义标记(红色)。(c) 为了在大语言模型的自回归范式下对文本和视觉内容进行建模,首先将像素视觉标记和语义视觉标记沿着它们的嵌入维度拼接,形成统一的视觉标记(黄色)。然后将这些统一的视觉标记与文本标记拼接,构建一个多模态标记序列。训练模型以预测视觉和文本标记的下一个标记。具体来说,高级和低级视觉标记由独立的视觉头(像素头和语义头)处理,每个视觉头包括一个深度变换器(3层,深度为8)和8个分类头,以预测相应视觉标记在不同深度的残差。在推理过程中,生成的低级标记由我们的视觉解码器解码以重建视觉内容。
其中 用于像素头, 用于语义头。深度为 1 时的初始输入由 给出。这种公式确保深度变换器通过利用直至深度 的先前估计值逐步细化预测的特征表示。因此,长度为 的整个多模态序列的总体负对数似然损失定义为
其中,
如果一个文本标记出现在位置 ,并且
如果视觉标记出现在位置 。在多模态预训练期间,深度变换器的权重被随机初始化,并与大语言模型(LLM)一起进行训练。在推理过程中,我们的视觉解码器仅使用低级标记来重建视觉内容。
实验
在本节中,我们展示了一系列全面的实验,以评估我们的方法在一系列视觉理解和生成任务中的表现。我们首先详细介绍我们的实验设置。接下来,我们分析我们统一的视觉标记器的性能。最后,我们将我们的方法与领先的多模态大语言模型(MLLM)进行基准对比,展示其在视觉理解和生成方面的优势。然而,请注意,这项研究仍在进行中,最终结果、完整指标和其他技术细节可能会在最终发布前更新。
1. 实验设置
我们使用 Qwen - 2.5 - 3B作为基础语言模型,并采用 SigLIP - SO400M - patch14 - 384的预训练权重用于我们的视觉标记器。所有图像都被调整为 大小,并转换为 8 个语义或像素标记,残差深度为 。我们的视觉标记器在 CC12M上进行训练,并在 ImageNet上评估零样本分类和重建性能。我们将我们的模型与广泛使用的视觉 - 语言理解基准进行评估,包括 VQAv2、POPE、MME、SEED - IMG、MMBench和 MM - Vet。对于视觉生成,我们应用无分类器引导,CFG 值为 3 以提高生成输出的质量。

图 4. 使用 DualToken 的视觉生成结果。(左)给定文本输入,我们的 DualToken 可以生成高质量的图像。(右)按照图 3(a)中介绍的流程,我们尝试使用 SBER - MoVQGAN 的码本作为低级词汇表,使用经过矢量量化(VQ)处理的 SigLIP 的码本作为高级词汇表,同时在下游多模态大语言模型训练中保持相同的方法和训练数据。然而,这种直接的方法导致图像生成性能明显变差。
2. 视觉标记器
为了评估我们统一的视觉标记器的语义能力,我们报告了在 ImageNet - 1K(验证集)上零样本图像分类的 Top - 1 准确率,以及在 Flickr8K 上的文本到图像和图像到文本检索性能(R@1)。如表 1 所示,我们的 DualToken 在分类和检索任务中都显著优于 VILA - U,同时在零样本图像分类中也超过了专用的 CLIP - L - 14 - 336 模型。值得注意的是,由于我们的分层解耦方法,DualToken 在语义性能上与最先进的 SigLIP ViT - SO400M - 14 - 384 模型相当,而无需任何专门为增强语义能力而设计的额外阶段。我们认为,加入一个额外的对比学习阶段(在该阶段中,负责重建的浅层被冻结,而仅对深层进行语义目标优化)可以进一步提高模型的语义性能。
为了评估重建能力,我们在 ImageNet - 1K 验证集上测量了重建弗雷歇 inception 距离(rFID)、峰值信噪比(PSNR)和结构相似性指数(SSIM)。我们的 DualToken 在包括 Open - MAGVIT2和 SBER - MoVQGAN在内的各种最先进的专用方法中实现了最高的结构相似性和最低的 rFID。这表明我们的方法有效地缓解了 VILA - U 在重建过程中遇到的结构失真和模糊问题。
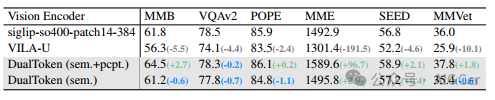
表 4. 各种视觉 - 语言理解基准上的对照实验。我们在 LLaVA - 1.5 框架内评估不同的视觉编码器/标记器,包括 siglip - so400m - 14 - 384、VILA - U 和 DualToken。MMB 表示 MMBench - dev。
3. 下游性能
视觉理解模型。在正式展示我们的统一模型的性能之前,我们首先进行了一项对照实验,以验证我们的视觉分词器在下游多模态大语言模型(MLLM)视觉理解任务中的有效性。为了通过控制训练数据、模型大小和架构等因素来确保公平比较,我们在LLaVA - 1.5框架内评估了DualToken的下游视觉理解性能。具体来说,我们用DualToken替换了LLaVA - 1.5的视觉编码器,同时严格遵循其训练数据,并使用LLaMA - 2 - 7B作为基础大语言模型(LLM)。如表4所示,我们的DualToken作为一种离散的统一视觉分词器,在用作视觉编码器时,性能优于VILA - U,甚至超过了原始的连续SigLIP模型。更有趣的是,我们分别进行了实验,仅使用从第26层提取的语义标记(sem.),以及将语义标记和像素标记(sem.+pcpt)沿着嵌入维度拼接作为视觉输入。与仅使用语义标记相比,联合利用语义标记和像素标记在各种视觉推理基准测试(如MMBench和MME)中通常能带来更好的性能。这表明低级纹理特征不仅对生成任务至关重要,而且对增强模型的视觉理解能力也有积极贡献。
表5. 多模态理解基准测试评估。与其他统一模型相比,我们的DualToken(3B)表现出强大的性能,并且取得了与LLaVA - NeXT和ShareGPT4V等专用理解模型相当的结果。请注意,最新版本仍在训练中,指标可能会在最终发布前更新。
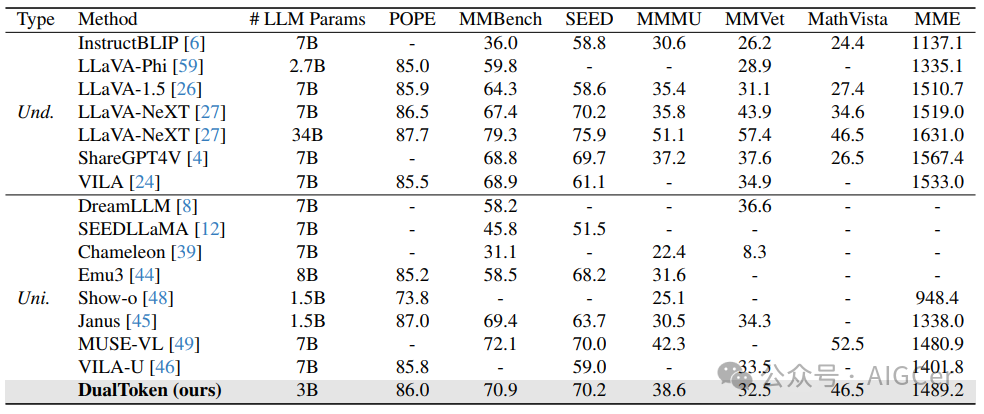
生成与理解的统一模型。我们基于3.3节和图3中介绍的方法,进一步实现了用于视觉理解和生成的统一多模态大语言模型(MLLM)框架,其中单独的视觉头用于预测语义和像素标记。如表5所示,我们的双标记模型(30亿参数)与其他统一模型相比表现出色,取得了与像LLaVA - NeXT和ShareGPT4V这样的专用理解模型相当的结果。同时,如图4所示,我们的统一模型可以根据文本输入生成视觉上引人注目的内容。生成的图像与文本高度匹配,即使对于长而复杂的提示也是如此。由于双标记模型的高重建质量,生成的图像细节丰富,结构逼真,能够准确捕捉动物毛发、水波等精细纹理和其他复杂图案。
为了进一步回答一个基本问题:为什么我们需要在统一的标记器中获取双视觉词汇表,而不是简单地组合现有的专用编码器?我们进行了实验,使用SBER - MoVQGAN的码本作为低级词汇表,使用经过矢量量化(VQ)处理的SigLIP的码本作为高级词汇表,同时在下游MLLM训练中保持相同的方法和训练数据。如图4(右)所示,这种直接的方法导致图像生成性能显著下降,进一步证明了在统一的视觉标记器中获取双视觉词汇表的重要性。值得注意的是,这种简单的组合方法与Janus不同,Janus的语义编码器连续运行,无需标记化,仅作为理解任务的编码器,不参与视觉生成过程。
总结
综上所述,我们的贡献主要有三点:(i)解耦重建和语义目标:我们通过分层方法成功地将重建和语义学习目标解耦,将它们之间的内在冲突转化为有益的关系。(ii)用于增强理解和生成能力的双视觉码本:我们证明了使用双视觉码本在理解和生成任务上优于单码本方法。(iii)用于视觉理解和生成的统一模型:我们提出了一种使用双视觉码本统一视觉理解和生成的可行范式。然而,这项工作只是该范式的基线实现,仍有很大的进一步探索空间。值得注意的是,先前用于理解和生成的统一模型并未在这些任务之间展现出明显的相互强化作用。一个关键的研究方向是探索充分利用双视觉码本实现视觉理解和生成之间真正协同作用的潜力。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









