






YOLOV3目标检测
1、backbone骨干网络
YOLOv3使用的是Darknet-53网络,是作者自己写的。
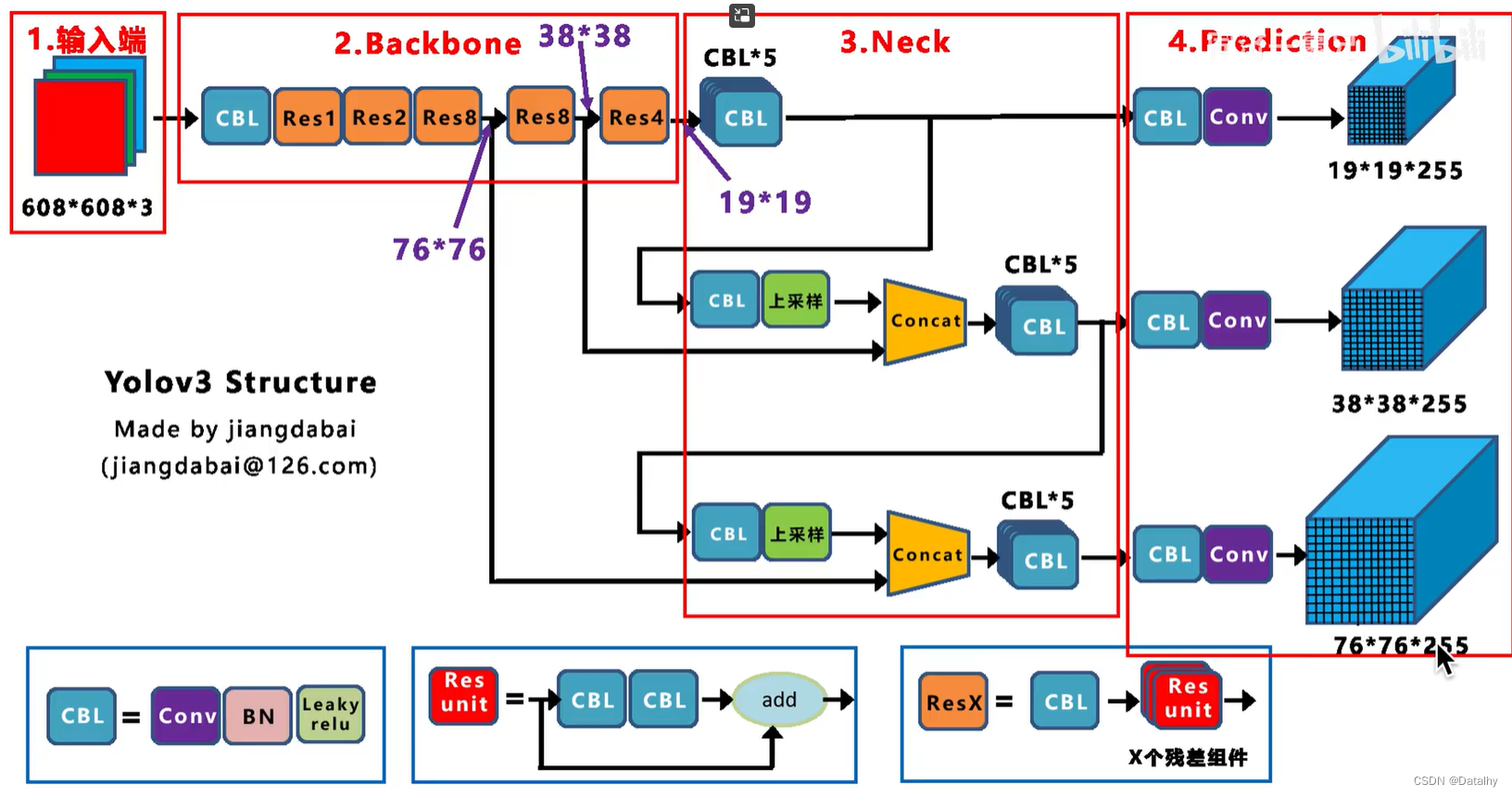
输入图片是416x416,经过各种卷积操作后,输出有3个不同的结果,13x13x255是经过下采样32倍后的结果,26x26x255是经过下采样16倍的结果,52x52x255是经过下采样8倍的结果,前两个数字是图片分为多少个网格,在这里,每个网格有3个anchor,和yolov2中预定义了5个anchor不同,然后每个anchor有5个信息,包括中心点坐标以及长宽,还有置信度信息,然后有80个类别目标,所以一个gridcell就有3x(80+5)=255。13x13对应原图上的感受野为32x32,26x26对应原图上的感受野为16x16,52x52对应原图上的感受野为8x8,所以13x13用来检测大目标,26x26检测中等目标,52x52检测小目标。
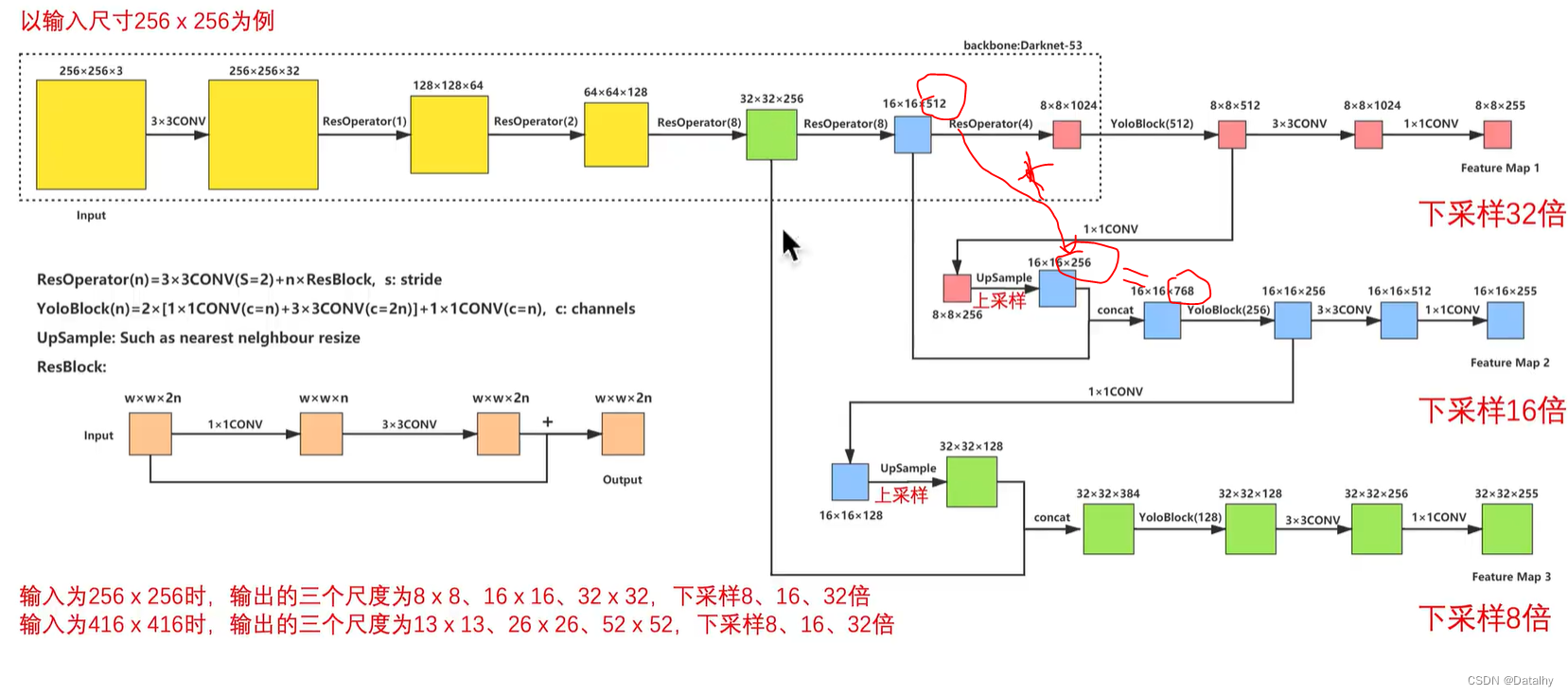
可以看到在26x26x255那个Concat,也就是说26x26的那个是由原图416x416经过Res8(8倍下采样)之后就为26x26的然后和13x13上采样变为26x26一起结合起来的,既包含了13x13的特征也包含了原来的26x26的特征。而后面52x52的那个也是Concat得到的,也就是由上面26x26上采样后和之前Res8后面的52x52的相concat得到的,最后得到的52x52的既包含了13x13的,也包含了26x26的,还包含了52x52的特征。 这个网络没有全连接层,全是卷积,yolov2也是这样的。所以对输入图像没有特定要求,32倍数就行。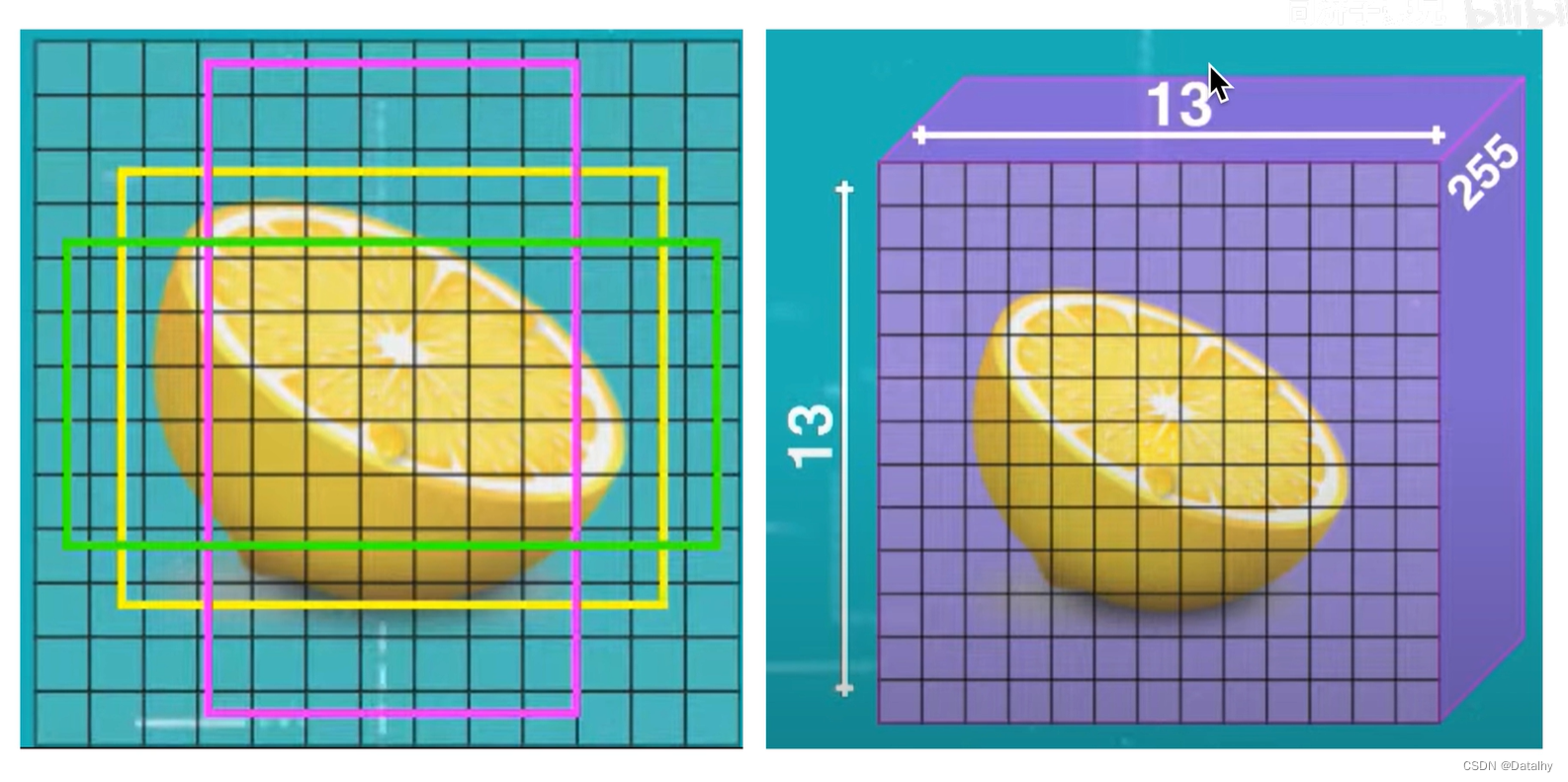 ]
]
由上图这个尺度中与groundtruth IOU最大的那个anchor拟合,一共不是有3个尺度吗,就是13x13,26x26,52x52这三个尺度,每个尺度有3个anchor,一共9个,选其中与groundtruth最大的那个拟合。也就是最大的是正样本,不是最大的不是正样本。
对于预测边界框的数量,yolov3:13x13x3+26x26x3+52x52x3=10647个,因为有3个不同尺度。
yolov2:13x13x5=845个
yolov1:7x7x2=98个
所以可以明白为什么yolov1检测小目标不好,就只能有98个框。
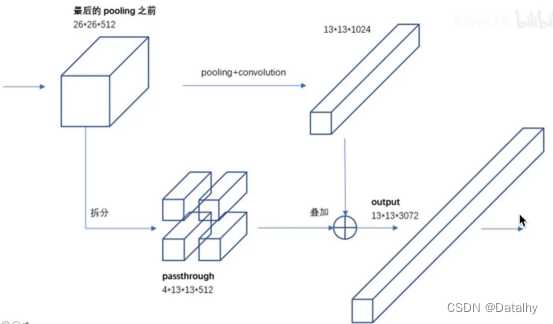
可以看到在concat上是堆叠起来的,尺度是一样,但通道数可以不一样,按照通道数堆叠一起就行,比如16x16x512+16x16x256=16x16x768,这和yolov2的passthrough是不一样的方式。下图是yolov2的passthrough层,也是为了更多尺度。
损失函数
对于正负样本的选取很重要,这里和yolov2中的正负样本选取一样。
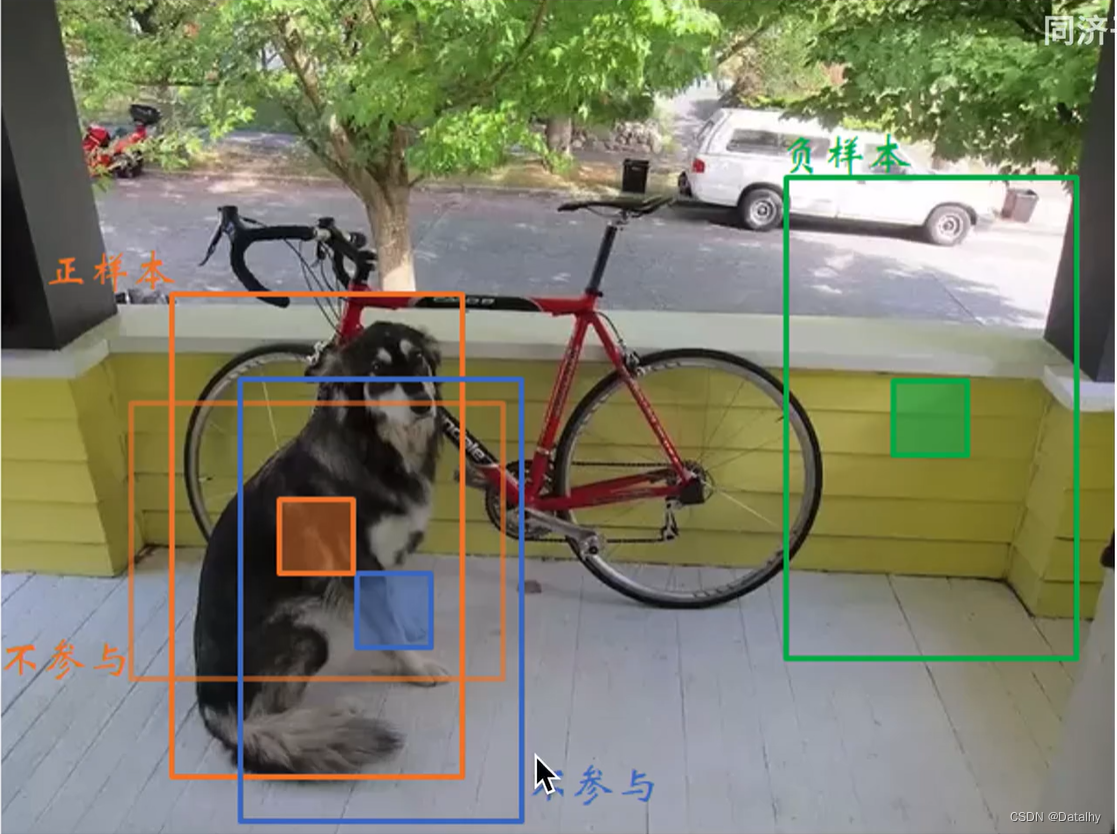
对于anchor与groundtruth具有最大IOU的作为正样本,然后比如有个阈值为0.5,大于这个阈值但不是最大的anchor,就把它舍弃,不考虑,对于小于阈值0.5的就被分为负样本了。
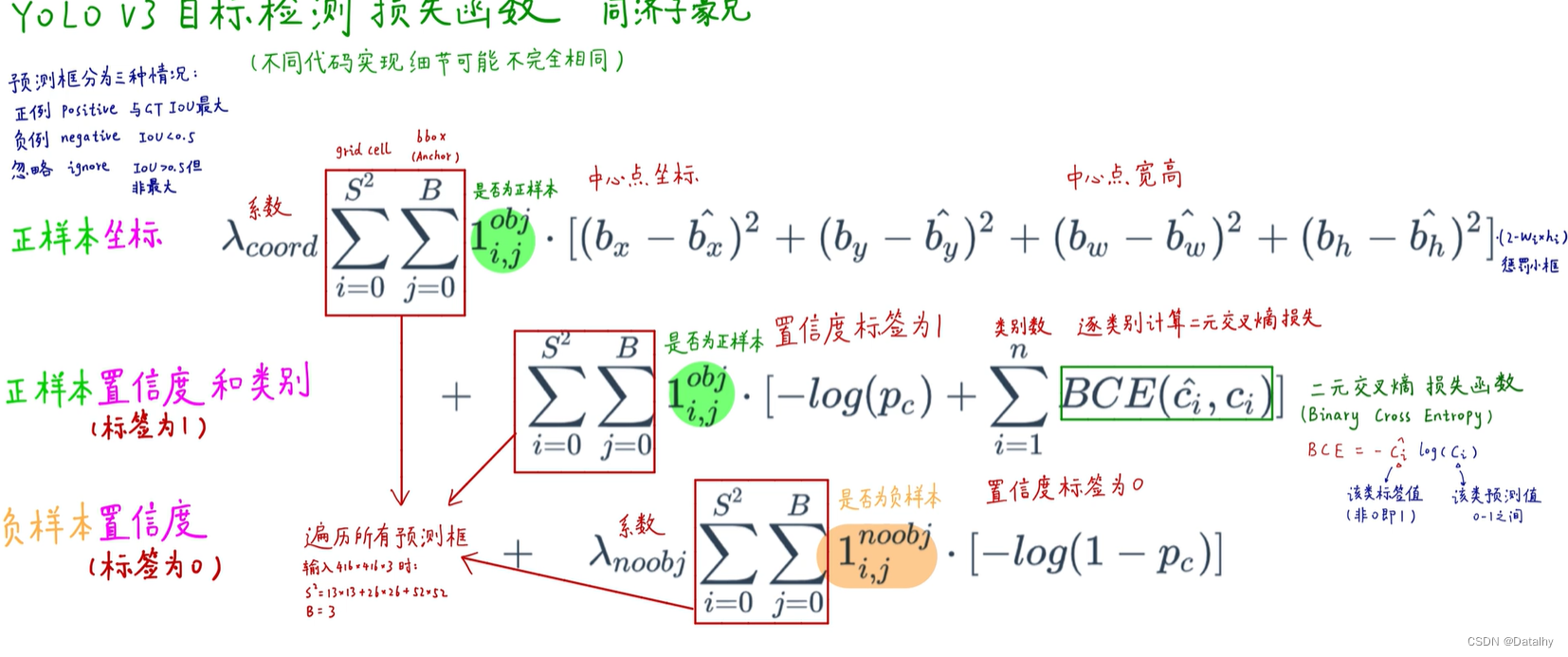
看到在这个损失函数中,当是正样本时,其置信度直接设为1,不是IOU了,之前v1和v2都是置信度等于IOU。为什么v1和v2中使用IOU作为置信度标签不好?因为很多预测框与GT框的IOU最高只有0.7,训练效果就不好,最高只有0.7。并且IOU对小目标误差比较大。对于正样本的置信度损失,首先我们一定要确定目标:那就是为了让损失函数最小更好,所以正样本pc越为1越好,其log值就越为0,损失就越小。对于负样本的置信度损失也是,让pc越为0的时候,其log(1-pc)越小。注意这个pc是置信度,即模型预测的物体是否存在当前网格的置信度,就是IOU,如果当前网格没有预测的物体,那pc该靠近0,如果有物体,那pc该靠近1。
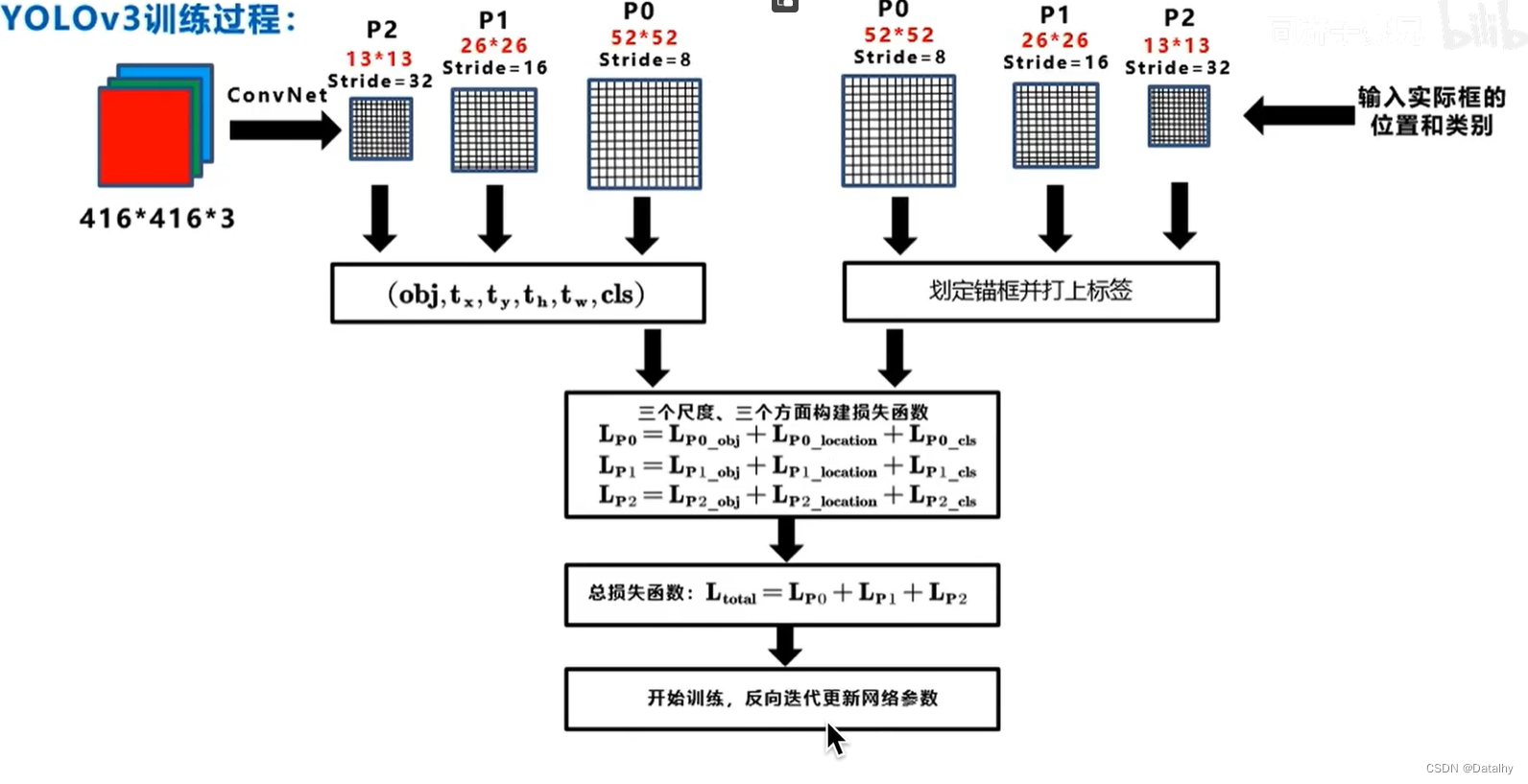
训练过程:
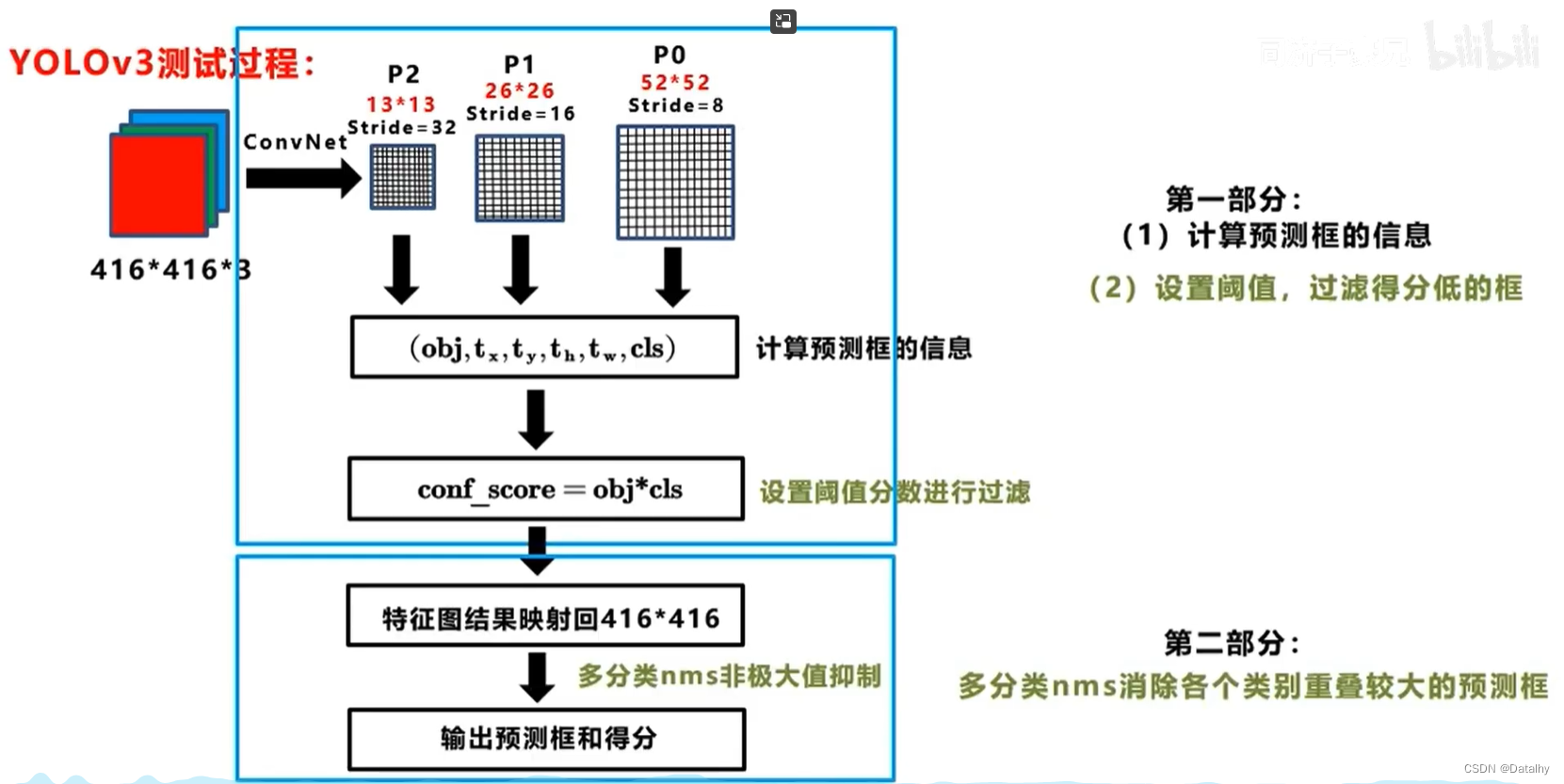
测试过程:
以上笔记内容理解全部参考b站up主同济子豪兄,up主的论文精读非常厉害,建议观看
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









