






Datawhale分享
组织方:集智俱乐部、Datawhale
导语
2023年终于在此起彼伏的AI狂潮中涌向终点。通用人工智能AGI的实现路径逐渐雾消路现。而社会各界对AI技术可靠性、AI系统安全性、AI伦理风险性等问题的担忧也在持续加深。尤其在复杂系统视角下,AI系统正在展现出非线性的、远超预期的涌现能力,这是AI技术的新机遇,也是AI安全的新挑战。如何确保&谁来确保AGI的安全?
在此背景下,集智俱乐部和安远A联合举办“AI安全与对齐”读书会,由多位海内外一线研究者联合发起,针对AI安全与对齐所涉及的核心技术、理论架构、解决路径以及安全治理等交叉课题,展开共读共研活动。读书会自2024年1月20日开始,每周六上午举行,为期8-10周。欢迎从事相关研究与应用工作的朋友报名加入!

读书会背景
近年来,以OpenAI ChatGPT和GPT-4为代表的大语言模型 (Large Language Model, LLM) 发展迅速,重新唤醒了人们对AI技术的热情和憧憬。然而,与AI技术和能力不断突破相伴随的是人们对AI模型本身存在的社会伦理风险及其对人类生存构成的潜在威胁的普遍担忧。很多人担心未对齐的AI模型可能带来人类生存风险 (Existential Risk, X-Risk),即超过人类知识和智能水平的AI会形成自己的目标,且该目标与人类赋予的目标不一致,为了实现自己的目标,AI自主体可能会获取更多的资源,实现自我保护、自我提升,这种发展将会持续扩展至对整个人类进行权力剥夺,从而不可避免地导致人类生存灾难。因此,为了保证AI能够持续推动人类社会的进步,让AI的目标与人类价值观和目标始终保持一致就显得尤为重要。
在此背景下,AI安全与对齐得到了越来越广泛的关注,这是一个致力于让AI造福人类,避免AI模型失控或被滥用而导致灾难性后果的研究方向。一方面,AI安全与对齐从AI模型本身出发,寻求克服AI模型自身的局限性和固有行为,如奖励破解、目标错误泛化、寻求权力等,并尝试通过不同的监督策略和运行机理层面的解释加深我们对AI模型的理解和控制。另一方面,AI安全与对齐也从人类视角出发,跟踪、评估、预测和防范人类主动滥用AI模型的风险,实现。除此之外,AI安全与对齐领域正在研究如何将这些对齐与治理策略应用到能力更为强大的通用人工智能 (Artificial General Intelligence, AGI) 系统中。
AI安全与对齐和复杂科学有着极为密切的联系。AI模型的一些行为往往难以理解和事先预测,而复杂科学中关于如何理解和管理复杂系统的不可预测性的研究对于AI安全和对齐有很大的帮助。另一方面,AI模型具有不确定性,且能与复杂环境和其它智能体进行交互并从中学习,所以本身也可以被视为是一种复杂系统。因此,对AI模型的研究也能够促进复杂科学的研究,加深我们对复杂系统的认识和理解。
读书会框架
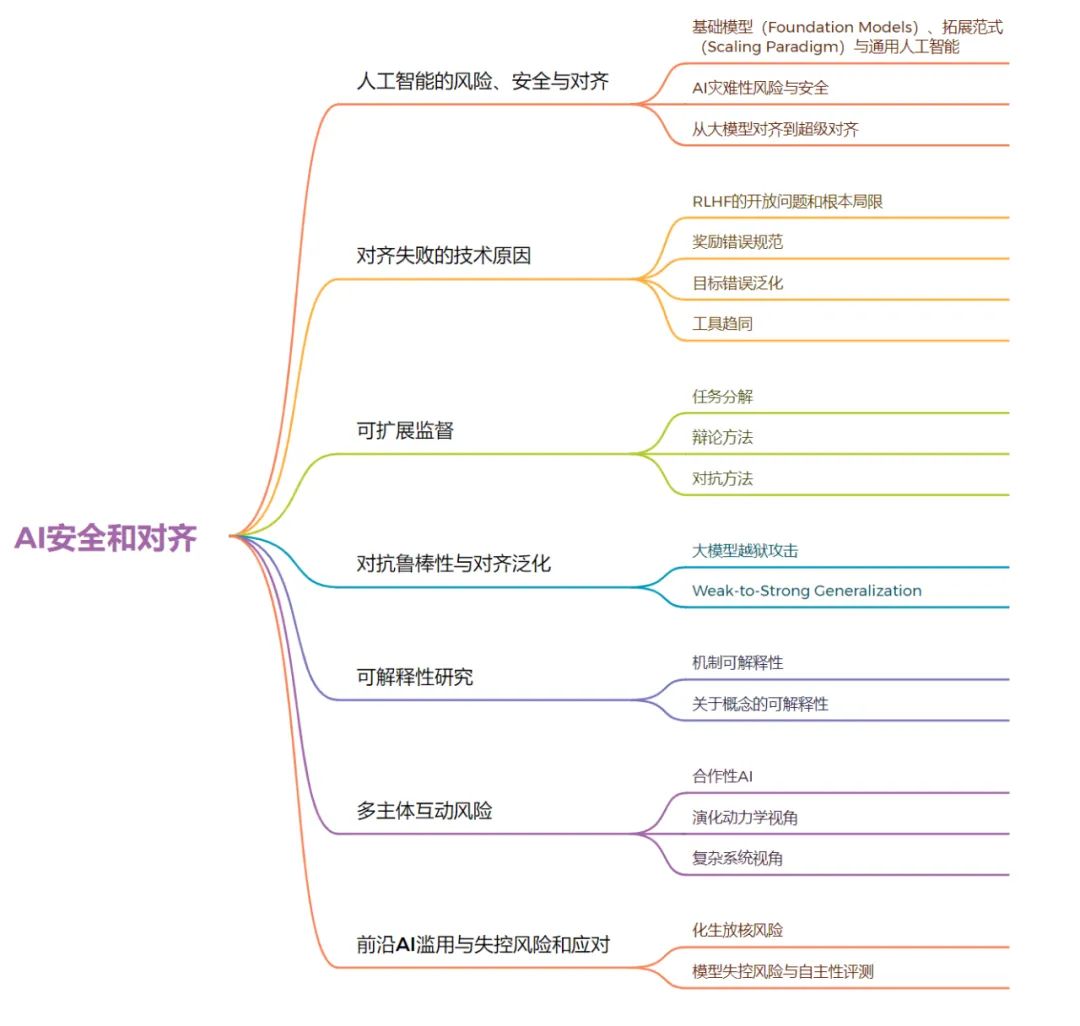
本次读书会将详细讨论AI安全与对齐话题,涵盖分支有AI风险、安全与对齐导论、对齐失败的技术原因、可扩展监督、对抗鲁棒性与对齐泛化、可解释性研究、多主体互动风险、前沿AI滥用风险与失控风险和应对。
主要的目的是希望能够帮助各个不同学科领域的学者了解AI安全和对齐的这个领域,尤其是深度学习、强化学习、自监督学习、自然语言处理、AI4Science、大模型/大语言模型/多模态大模型、通用人工智能等方向的研究者,如何扩展自己的研究方向。
发起人团队介绍

苏炜杰,现为宾夕法尼亚大学沃顿商学院统计与数据科学系和工学院计算机系副教授,同时还兼任宾大机器学习研究中心联合主任。此外还供职于宾大沃顿智能商务中心,Warren网络数据科学中心。苏炜杰为首届2022年数据科学青年奖得主,曾在2019年和2020年分别获得NSF CAREER Award和斯隆研究奖。
研究兴趣:超级对齐、可扩展监督、AI安全和对齐等研究方向。

刘鹏飞,上海交通大学长聘教轨副教授,博士生导师。生成式人工智能研究组负责人,国家高层次人才计划青年项目,上海市领军人才 (海外青年);在自然语言处理和人工智能领域发表学术论文 70 余篇。谷歌学术引用 9900余次。ACL会议史上首次实现连续两年获得System & Demo Paper Award;提示工程(Prompt Engineering)概念最早提出者之一。代表作包括:高数学推理大模型“阿贝尔”、Auto-J,LIMA等。
研究方向:专注于大模型的训练和价值对齐。

段雅文,安远AI技术项目经理,致力于AI安全技术社区建设。他是未来生命研究所AI Existential Safety PhD学者,关注大模型安全和对齐研究。他曾在UC Berkeley的Stuart Russell组和剑桥大学David Krueger实验室进行AI安全和对齐研究。他曾在NeurIPS组织Socially Responsible Language Model Research工作坊,参与的研究项目曾在CVPR、ECCV、ICML、ACM FAccT、NeurIPS MLSafety Workshop等ML/CS会议和工作坊上发表。他拥有剑桥大学机器学习硕士学位和香港大学理学士学位。
研究方向:人工智能安全与对齐等。

沈田浩,天津大学自然语言处理实验室(TJUNLP)三年级博士生,导师为熊德意教授,曾获得第九届对话技术挑战赛 (DSTC9) “端到端多领域任务型对话”赛道第一名,在ACL、EMNLP等国际会议上发表多篇学术论文,撰写了大规模语言模型对齐技术的综述(https://arxiv.org/abs/2309.15025),并担任ACL, EMNLP, AACL等会议的审稿人。
研究方向:对话系统、检索式问答和大规模语言模型
报名参与读书会
本读书会适合参与的对象
基于AI安全和对齐的相关学科研究,特别是感兴趣RLHF和大模型、超级智能和超级对齐的一线科研工作者;
想了解深度学习、强化学习、自监督学习、自然语言处理、AI4Science、大模型/大语言模型/多模态大模型、通用人工智能等方向的研究者;
能基于读书会所列主题和文献进行深入探讨,可提供适合的文献和主题的朋友;
能熟练阅读英文文献,并对复杂科学充满激情,对世界的本质充满好奇的探索者;
想锻炼自己科研能力或者有出国留学计划的高年级本科生及研究生。
本读书会谢绝参与的对象
为确保专业性和讨论的聚焦,本读书会谢绝脱离读书会文本和复杂科学问题本身的空泛的哲学和思辨式讨论;不提倡过度引申在社会、人文、管理、政治、经济等应用层面的讨论。我们将对参与人员进行筛选,如果出现讨论内容不符合要求、经提醒无效者,会被移除群聊并对未参与部分退费,解释权归集智俱乐部所有。
运行模式
本季读书会预计讨论分享8-10次,1次导论 + 6-8次专题内容 + 1次圆桌讨论,按暂定框架贯次展开;
每周进行线上会议,由 1-2 名读书会成员以PPT讲解的形式领读相关论文,与会者可以广泛参与讨论,会后可以获得视频回放持续学习。
举办时间
从2024年1月20日开始,每周六早上 9:00-11:00,持续时间预计8-10 周。我们也会对每次分享的内容进行录制,剪辑后发布在集智斑图网站上,供读书会成员回看,因此报名的成员可以根据自己的时间自由安排学习时间。
参与方式
此次读书会为线上闭门读书会,采用的会议软件是腾讯会议(请提前下载安装)。在扫码完成报名并添加负责人微信后,负责人会将您拉入交流社区(微信群),入群后告知具体的会议号码。
报名方式
第一步:扫码填写报名信息。

扫码报名
第二步:填写信息后,付费299元。
第三步:添加负责人微信,拉入对应主题的读书会社区(微信群)。
本读书会可开发票,请联系相关负责人沟通详情。
共学共研模式与退费机制
读书会采用共学共研的机制,围绕前沿主题进行内容梳理和沉淀。读书会成员可通过内容共创任务获得积分,解锁更多网站内容,积分达到标准后可退费。发起人和主讲人作为读书会成员,均遵循内容共创共享的退费机制,暂无其他金钱激励。读书会成员可以在读书会期间申请成为主讲人,分享或领读相关研究。
阅读材料
以下部分阅读材料所附时间为预估阅读时间。
人工智能的风险、安全与对齐
基础模型(Foundation Models)、拓展范式(Scaling Paradigm)与通用人工智能
Bommasani R, Hudson D A, Adeli E, et al. On the opportunities and risks of foundation models[J]. arXiv preprint arXiv:2108.07258, 2021.(仅第 3-6 页,主要关注图表1和2) (12分钟)
Bommasani et al 综述了基础模型(foundation models)的基本概念、训练方式以及在机器学习中的广泛应用。可以重点关注(1)基础模型的概念和术语来源以及(2)基础模型的训练方式。
Kaplan, Jared, et al. Scaling Laws for Neural Language Models[J]. arXiv preprint arXiv:2001.08361, 2020.
“扩展定律/规模法则”(“Scaling Laws”)观察到大型语言模型的性能(通过测试损失衡量)与计算量、参数量和数据量在幂律关系下成比例。“Scaling Laws”也常被译作规模法则、缩放定律、比例定律、标度律等。
注:DeepMind近期提出了新的扩展定律:Hoffmann, Jordan, et al. Training Compute-Optimal Large Language Models[J]. arXiv preprint arXiv:2203.15556, 2022(Chinchilla Scaling Laws)。特别是,关于最佳扩展涉及将模型大小放大远远超过数据量的说法现在已被证明是不正确的:事实上,它们应该以大致相同的倍数进行放大。
其他参考:Sutton R. The bitter lesson[J]. Incomplete Ideas (blog), 2019, 13(1).,其中指出“利用计算的一般方法最终是最有效的”("general methods that leverage computation are ultimately the most effective")。文章给出了基于历史的论据,认为扩展可以继续产生更好的结果。
Morris M R, Sohl-dickstein J, Fiedel N, et al. Levels of AGI: Operationalizing Progress on the Path to AGI[J]. arXiv preprint arXiv:2311.02462, 2023.
Google DeepMind的文章提出新的框架试图衡量通往AGI的进程,提出AGI等级(类似于自动驾驶的等级),新框架注重模型能力和通用性,并且着重讨论了不同等级的AGI的自主性以及带来的风险。
AI灾难性风险与安全
Hendrycks D, Mazeika M, Woodside T. An Overview of Catastrophic AI Risks[J]. arXiv preprint arXiv:2306.12001, 2023.
发起《AI风险声明》(微信中文译版)的人工智能安全中心(Center for AI Safety, CAIS)发表了题为《灾难性AI风险概述》的论文,旨在全面讨论AI技术为何可能导致灾难性风险,以及克服这一挑战有益的应对举措。文中涉及四类灾难性AI风险:滥用风险、AI竞赛风险、组织风险、失控AI风险。
Bengio, Yoshua, et al. "Managing ai risks in an era of rapid progress." arXiv preprint arXiv:2310.17688 (2023).(授权中译版)
论文代表了顶尖人工智能学者就政府应如何应对人工智能风险达成的首次共识,同时也是迄今为止来自广泛专家群体对此问题提出的最具体和全面的建议。例如,文章提出分配至少三分之一的人工智能研发资金用于确保人工智能系统的安全性和合乎伦理的使用(与其对人工智能能力的投资相当)。
Hendrycks D, Carlini N, Schulman J, et al. Unsolved problems in ml safety[J]. arXiv preprint arXiv:2109.13916, 2021.
文章提出ML Safety的四大抓手:对齐(Alignment)、鲁棒性(Robustness)、监测(Monitoring)和系统安全性(Systemic Safety),旨在系统性地分解AI安全问题。
从大模型对齐到超级对齐
Christiano P F, Leike J, Brown T, et al. Deep reinforcement learning from human preferences[J]. Advances in neural information processing systems, 2017, 30.
大语言模型对齐技术RLHF的前身之作,虽然是2017年的论文,但是里面关于为何要引入human preference以及在simulated Robotics上面整个pipeline是非常值得阅读并思考的。
Ouyang L, Wu J, Jiang X, et al. Training language models to follow instructions with human feedback[J]. Advances in Neural Information Processing Systems, 2022, 35: 27730-27744.
在语言模型上进行RLHF的开山之作, OpenAI首次提出了完整的RLHF的pipeline,并在大语言模型场景中展现出了极大的潜力。经过RLHF的1.3B模型InstructGPT比175B的GPT-3效果更加好。
Bai Y, Kadavath S, Kundu S, et al. Constitutional ai: Harmlessness from ai feedback[J]. arXiv preprint arXiv:2212.08073, 2022.
Anthropic的代表性工作之一,首次提出了AI监督AI的范式,也叫RLAIF,并通过完整的实验流程证明使用另一个AI的反馈,能够训练一个具有帮助性且无害的聊天助手。
Rafailov R, Sharma A, Mitchell E, et al. Direct preference optimization: Your language model is secretly a reward model[J]. arXiv preprint arXiv:2305.18290, 2023.
NeurIPS2023的Best paper,其核心的一个Motivation在于简化RLHF的流程,去除了Reward Model的显式学习,通过人类偏好的数据直接来对Language Model进行优化,建议大家可以阅读这篇论文的一个前置工作:Advantage-Weighted Regression: Simple and Scalable Off-Policy Reinforcement Learning
对齐失败的技术原因
RLHF的开放问题和根本局限
Casper S, Davies X, Shi C, et al. Open problems and fundamental limitations of reinforcement learning from human feedback[J]. arXiv preprint arXiv:2307.15217, 2023.
论文从人类反馈(Human Feedback)、奖励模型(Reward Model)、策略优化(Policy)的三个角度探讨了RLHF尚有的问题以及根本缺陷。
奖励错误规范
Krakovna V, Uesato J, Mikulik V, et al. Specification gaming: the flip side of AI ingenuity[J]. DeepMind Blog, 2020, 3.(12 分钟)
这篇文章说明,通常用于训练RL智能体的默认技术往往由于设计奖励函数的难度而导致不良行为。Krakovna等人在简单的环境中展示了智能体利用错误指定的奖励(称为奖励破解 )的例子。文章中提到的“规范博弈”(specification gaming)是一个广义术语,包括RL智能体的奖励破解以及类似的非RL智能体行为。
Ngo R, Chan L, Mindermann S. The alignment problem from a deep learning perspective[J]. arXiv preprint arXiv:2209.00626, 2022. (只需阅读第2部分, 关于“reward hacking”) (12分钟)
“奖励破解”指的是模型利用奖励错误规范获得高奖励而不优化我们试图传达的最初目标。这篇文章认为,一旦AI具有态势感知(situational awareness;即将抽象知识应用于它们运行的特定环境的能力)能力,奖励破解将变得更难检测。态势感知能力可能使AI能够进行欺骗性奖励破解(deceptive reward hacking),即通过推理如何欺骗提供反馈的人来进行奖励破解。
Perez E, Ringer S, Lukošiūtė K, et al. Discovering language model behaviors with model-written evaluations[J]. arXiv preprint arXiv:2212.09251, 2022.
文章展示了一些基于RLHF进行强化学习的inverse scaling现象,即RLHF让模型在某些方面变差的现象。
Sharma M, Tong M, Korbak T, et al. Towards understanding sycophancy in language models[J]. arXiv preprint arXiv:2310.13548, 2023.
Anthropic的文章介绍了大模型的谄媚(Sycophancy)行为:在这里指的是AI模型产生的回应趋向于符合用户的立场或偏好,但有时可能以牺牲真实性或准确性为代价的行为。是Discovering Language Model Behaviors with Model-Written Evaluations论文中谄媚现象的深入研究。
目标错误泛化
Shah R, Varma V, Kumar R, et al. Goal misgeneralization: Why correct specifications aren't enough for correct goals[J]. arXiv preprint arXiv:2210.01790, 2022. (36分钟)
Shah等人认为,即使智能体在“正确”的奖励函数上进行训练,也可能会学到以不可取的方式泛化的目标。本文实际展现了自主体学习的目标可能与我们从训练设置和最初在测试环境中观察到的行为预期的目标不同。这与一般的“能力错误泛化”不同,因为在测试环境中自主体仍然可以有效地追求其学习到的目标,但是其学习到的目标与我们训练它的目标不同,因此,自主体会在测试环境中的得低分。
Di Langosco, Lauro Langosco, et al. "Goal misgeneralization in deep reinforcement learning." International Conference on Machine Learning. PMLR, 2022.
ICML 2022文章,展现了跟上面文章中相似的DRL“目标错误泛化”行为。
工具趋同
以下阅读会研究一种假设:ML系统还可能以意想不到的方式最大化奖励:寻求权力(power seeking)。换句话说,系统可能产生出“工具”目标,比如获取资源、自我保护和自我增强等。工具趋同的概念来源于Superintelligence: Instrumental convergence (Bostrom, 2014)。它提出存在一些工具性目标可以提高智能体实现最终目标的可能性,意味着这些工具性目标可能会被广泛的智能体所追求。Bostrom提出了AI智能体可能内化的五个目标,这些目标是实现其整体目标的“工具”。
Turner A M, Smith L, Shah R, et al. Optimal policies tend to seek power[J]. arXiv preprint arXiv:1912.01683, 2019.
Turner等在强化学习环境中形式化了权力寻求(power seeking)的概念,并证明了许多智能体会趋同到权力寻求的目标。这篇文章详细说明Bostrom (2014) 的论点(另请参见相关博客文章和论文)。
Pan A, Chan J S, Zou A, et al. Do the rewards justify the means? measuring trade-offs between rewards and ethical behavior in the machiavelli benchmark[C]//International Conference on Machine Learning. PMLR, 2023: 26837-26867.
文章提出了“马基亚维利基准”(MACHIAVELLI Benchmark),收集了134个基于文本的冒险游戏。这些游戏试图去评估:语言模型在多大程度上倾向于追求权力而在奖励与道德行为间做权衡。作者发现,被训练去优化任意目标的自主体(agent)倾向于采取"为达目的,不择手段"的行为:它们寻求权力,伤害他人,并违反如盗窃或谎言等道德规范以达成其目标。其中似乎存在着在行为道德与实现高回报之间的权衡。
可扩展监督
Bowman S R, Hyun J, Perez E, et al. Measuring progress on scalable oversight for large language models[J]. arXiv preprint arXiv:2211.03540, 2022. (仅简介) (6分钟)
这篇论文介绍了“可扩展监督”的问题——试图对人类难以完全理解的任务提供反馈。主要关注理解可扩展的监督问题。另外,论文介绍了“夹心”(sandwiching)的场景。当人工智能系统“夹在”人类学科专家和外行之间时,它比外行更有能力,但不如特定领域的专家。“夹心”可以让我们评估我们的可扩展监督假设是否适用于未来的系统(届时将没有专家能够独自监督人工智能系统)。
任务分解
Wu J, Ouyang L, Ziegler D M, et al. Recursively summarizing books with human feedback[J]. arXiv preprint arXiv:2109.10862, 2021. (6分钟)
Wu等人给了一个递归任务分解(recursive task decomposition)的例子,可以看成是下一篇阅读中迭代扩增的一个特殊情况。
Wei, Jason, and Denny Zhou. "Language Models Perform Reasoning via Chain of Thought." Google AI Blog. Google Research. Online verfügbar unter https://ai. googleblog. com/2022/05/language-models-perform-reasoning-via. html, zuletzt aktualisiert am 11 (2022): 2022.(12分钟)
思维链(Chain of thought / CoT)是一种通过一系列推理步骤促使大型语言模型提供更好答案的技术。
Zhou D, Schärli N, Hou L, et al. Least-to-most prompting enables complex reasoning in large language models[J]. arXiv preprint arXiv:2205.10625, 2022.(仅到第 3.1 节结尾) (18分钟)
Least-to-most prompting 是一种提示工程的技术。与CoT相比,它通过更明确地将任务分解为多个步骤来产生更好的答案。这可能会使结果输出更易于监督。
辩论方法
AI-written critiques help humans notice flaws: blog post (Saunders et al., 2022) (12分钟)
作者训练了一个语言模型来评价另一个语言模型的性能,帮助人类对其进行评估。这也是下一篇阅读中讨论的辩论协议(debate)的一个简单示例。特别要注意判别(discrimination)和评论(critique)能力之间的差距,这是一个需要降低的重要指标。
Irving G, Christiano P, Amodei D. AI safety via debate[J]. arXiv preprint arXiv:1805.00899, 2018. (仅到第3部分结尾) (42分钟)
辩论涉及多个人工智能之间反复的自然语言交流,旨在让人类更容易判断哪个是更真实的。没有复杂性理论(complexity theory)背景的读者可以跳过 2.2 节。
对抗方法
Perez E, Huang S, Song F, et al. Red teaming language models with language models[J]. arXiv preprint arXiv:2202.03286, 2022. (12分钟)
Perez等人使用语言模型自动生成测试用例,在不需要获得网络参数的情况下导致目标语言模型产生不良行为,可以看做是一种“黑盒攻击”。
这是一个生成“无限制对抗样本”的例子。“无限制”指的是语言模型可以生成任何示例的情况,而“受限的”对抗样本通常与训练数据点密切相关。
Casper S, Nadeau M, Hadfield-Menell D, et al. Robust feature-level adversaries are interpretability tools[J]. Advances in Neural Information Processing Systems, 2022, 35: 33093-33106. (36分钟)
Casper等人通过操作输入样本的高层特征(可以获取网络权重,使其成为“白盒”攻击)构建攻击。
对抗鲁棒性与对齐泛化
大模型越狱攻击
Wei A, Haghtalab N, Steinhardt J. Jailbroken: How does llm safety training fail?[J]. arXiv preprint arXiv:2307.02483, 2023.
越狱攻击指的是一种针对LLM特殊设计的提示输入,用于诱导模型输出有害内容或者隐私信息。NeurIPS 2023 Oral, 论文较为系统的研究了jailbreak这类攻击为什么会成功以及如何制造这些攻击,并阐述了安全训练的两种失败模型competing objectives和mismatched generalization。
Zou A, Wang Z, Kolter J Z, et al. Universal and transferable adversarial attacks on aligned language models[J]. arXiv preprint arXiv:2307.15043, 2023.
作者使用了一种基于白盒梯度的贪心方法在开源模型Llama 2上自动化生成“对抗字符串”。作者发现该“越狱”攻击同时可以迁移到一系列闭源应用上。
Pelrine K, Taufeeque M, Zając M, et al. Exploiting Novel GPT-4 APIs[J]. arXiv preprint arXiv:2312.14302, 2023.
作者通过用少量有害数据基于GPT-4 Fine-tuning API微调,即让GPT-4模型协助用户的有害请求。
Weak-to-Strong Generalization
Burns C, Izmailov P, Kirchner J H, et al. Weak-to-Strong Generalization: Eliciting Strong Capabilities With Weak Supervision[J]. arXiv preprint arXiv:2312.09390, 2023.
OpenAI 超级对齐团队成立以后第一份技术报告,提出了weak-to-strong的研究设置:如何用小模型(性能弱)监督更大的模型(性能强),对于如何从经验上对齐超级智能有启发。对于OpenAI 超级对齐团队的研究议程也可以参照Introducing Superalignment。
可解释性研究
机制可解释性
Elhage N, Hume T, Olsson C, et al. Toy models of superposition[J]. arXiv preprint arXiv:2209.10652, 2022.(仅第1、2部分) (36分钟)
Elhage等人研究了为什么一些神经元会对多个无关特征作出反应(“多语义性”),发现模型会处于“叠加态”来存储的特征数量超过了它们的维度。模型神经元的“多语义性”是Anthropic机制可解释性研究的核心假设。
Towards Monosemanticity: Decomposing Language Models With Dictionary Learning
Anthropic 研究了如何将复杂的神经网络(特别是语言模型)分解为更易于理解的组成部分。作者发现,与其直接分析单个神经元,不如分析某些神经元激活的组合,这些组合被称为“特征”(features)。原本512神经元的语言模型层通过这种分解方法,可以被分解成4000多种不同的特征,每种特征可以代表不同的模型性质,如DNA序列、法律语言、HTTP请求、希伯来文本等。
关于概念的可解释性
Burns C, Ye H, Klein D, et al. Discovering latent knowledge in language models without supervision[J]. arXiv preprint arXiv:2212.03827, 2022. (仅第1-3部分) (36分钟)
本文设计了一种无需任何真实标签的无监督技术来自动识别模型是否“相信”一些陈述的真假。
McGrath T, Kapishnikov A, Tomašev N, et al. Acquisition of chess knowledge in alphazero[J]. Proceedings of the National Academy of Sciences, 2022, 119(47): e2206625119. (仅到第2.1节结尾) (24分钟)
本文提供了一个使用基于概念的可解释性研究来探究AlphaZero对于人类国际象棋的概念。前两节对可解释性领域做了一个回顾。
Meng, Kevin, et al. "Locating and editing factual associations in GPT." Advances in Neural Information Processing Systems 35 (2022): 17359-17372.(12分钟)
Meng等人演示了如何使用基于概念的可解释性在语义层面修改神经网络权重。
Zou, Andy, et al. "Representation engineering: A top-down approach to ai transparency." arXiv preprint arXiv:2310.01405 (2023).
机制可解释性(Mechanistic Interpretability)侧重于理解神经网络中的神经元和电路,符合传统的“Sherringtonian”认知神经科学观点,这种观点认为认知是神经元间连接的结果。相比之下,表征工程(Representation Engineering; RepE)借鉴了“Hopfieldian”视角,将认知视为由神经元群体活动模式实现的表征空间的产物。
6. 多主体互动风险
合作性AI:Dafoe A, Hughes E, Bachrach Y, et al. Open problems in cooperative AI[J]. arXiv preprint arXiv:2012.08630, 2020.
演化动力学视角:Hendrycks D. Natural selection favors ais over humans[J]. arXiv preprint arXiv:2303.16200, 2023.
Hendrycks从演化动力学视角阐述了“演化的力量可能会导致未来最有影响力的智能体出现自私倾向”。自然选择会偏向选择适应环境并能取得最大回报的AI系统,而不一定是对人类最有益的AI系统;智能体间由于竞合博弈和/或协作能力缺失可能导致多方互动风险。
复杂系统视角
Introduction to AI Safety, Ethics, and Society Textbook (Chapter 5.3 Complex Systems for AI Safety)
Introduction to AI Safety, Ethics, and Society Textbook (Chapter 8.1-8.5 Collective Action Problems)
前沿AI滥用与失控风险和应对
OpenAI Preparedness Framework (Beta)
OpenAI Preparedness团队的框架文件。具体阐述了重点风险分类的跟踪、评估、预测和防范方法。重点风险领域包括:网络安全(Cybersecurity)、化生放核风险(Chemical, Biological, Nuclear, and Radiological threats)、诱导与操纵(Persuasion)、模型自主性(Model Autonomy)和未知风险(Unknown Unknowns)。
化生放核风险(Chemical, Biological, Nuclear, and Radiological)
He J, Feng W, Min Y, et al. Control Risk for Potential Misuse of Artificial Intelligence in Science[J]. arXiv preprint arXiv:2312.06632, 2023.
文章介绍了三种化学领域的AI模型:合成规划模型(Synthesis Planning Model)、毒性预测模型(Toxicity Prediction Model)和大型语言模型(LLM)以及科学自主体(Agents),并展示了它们可能被误用和滥用的方式。
OpenAI Preparedness Framework (Beta)
化生放核风险(Chemical, Biological, Nuclear, and Radiological threats)部分
模型失控风险与自主性评测
OpenAI Preparedness Framework (Beta)
模型自主性(Model Autonomy)部分
“Evaluating Language-Model Agents on Realistic Autonomous Tasks”
与Anthropic和OpenAI合作进行危险能力评测的非营利第三方机构METR(原Alignment Research Center Evaluation Team)发布的第一份技术报告。介绍了其针对大语言模型获取资源、创建自身副本以及适应其在实践中遇到新挑战的能力的评测方法。
可扫描以下二维码,查看此次读书会参考文献详情:

AI安全与对齐读书会参考文献清单
点击“阅读原文”,报名读书会


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









