







大模型推荐系统有哪些成功的落地经验?
大模型训练推理如何优化?
GNN推荐系统如何用LLM调优?
多模态大模型如何与精排模型融合?
大模型如何解决冷启动问题?
除了大模型,经典推荐问题如何解决?
6月22日,邀请您参加DataFunSummit2024: 推荐系统架构峰会,共同探讨大模型与推荐系统的融合之路,感兴趣的小伙伴欢迎识别二维码免费报名,收看直播:

扫码免费报名,收看直播
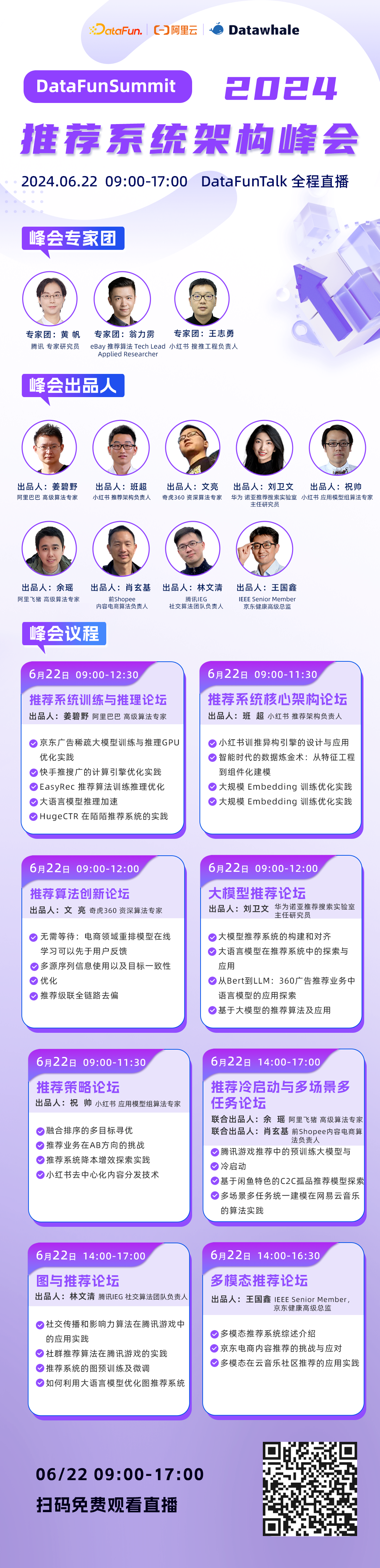
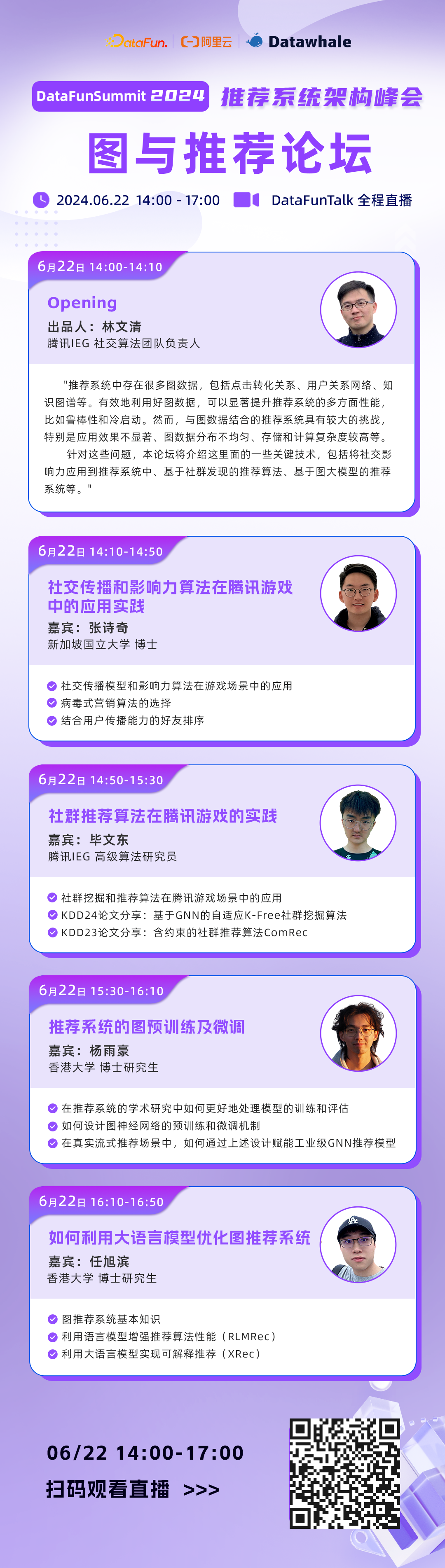
峰会日程

详细介绍







大模型推荐系统有哪些成功的落地经验?
大模型训练推理如何优化?
GNN推荐系统如何用LLM调优?
多模态大模型如何与精排模型融合?
大模型如何解决冷启动问题?
除了大模型,经典推荐问题如何解决?
6月22日,邀请您参加DataFunSummit2024: 推荐系统架构峰会,共同探讨大模型与推荐系统的融合之路,感兴趣的小伙伴欢迎识别二维码免费报名,收看直播:
扫码免费报名,收看直播
峰会日程
详细介绍

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























