







快速排序
基本思想

1.i =L; j = R; 将参照数挖出形成第一个坑a[i]。
2.j--由后向前找比它小的数,找到后挖出此数填前一个坑a[i]中。
3.i++由前向后找比它大的数,找到后也挖出此数填到前一个坑a[j]中。
4.再重复执行2,3二步,直到i==j,将参照数填入a[i]中。
我们很容易写出这个时间复杂度为O(N)的代码:
int partSort1(int s[], int l, int r) //返回调整后参照数的位置
{
int i = l, j = r;
int x = s[l]; //s[l]即s[i]就是第一个坑
while (i < j)
{
// 从右向左找小于x的数来填s[i]
while(i < j && s[j] >= x)
j--;
if(i < j)
{
s[i] = s[j]; //将s[j]填到s[i]中,s[j]就形成了一个新的坑
i++;
}
// 从左向右找大于或等于x的数来填s[j]
while(i < j && s[i] < x)
i++;
if(i < j)
{
s[j] = s[i]; //将s[i]填到s[j]中,s[i]就形成了一个新的坑
j--;
}
}
//退出时,i等于j。将x填到这个坑中。
s[i] = x;
return i;
} void quick_sort(int s[], int l, int r)
{
if (l < r)
{
Swap(s[l], s[(l + r) / 2]);
int i = l, j = r, x = s[l];
while (i < j)
{
while(i < j && s[j] >= x) // 从右向左找第一个小于x的数
j--;
if(i < j)
s[i++] = s[j];
while(i < j && s[i] < x) // 从左向右找第一个大于等于x的数
i++;
if(i < j)
s[j--] = s[i];
}
s[i] = x;
quick_sort(s, l, i - 1); // 递归调用
quick_sort(s, i + 1, r);
}
} 接下来我们再使用分治法的思想使用递归,让每个区间的元素只有一个那么我们就已经达到了目的.
2>>左右指针法快速排序
我们开始介绍第二种方法左右指针法,那么何为左右指针法?? 有一个数组a[N],做指针left指向待排序列的最左边. 指针right指向指
向待排序列的最右边.然后选取我们的key这里假设选的是a[right]的Key,然后让left先走,遇到比key的数字停下来.然后让right往左
走,当遇到比key小的数的时候,停下来. 然后将a[left]和a[right]交换.当left >= right的时候说明单次快排结束了. 最后让left的
值与key的值交换即可. 为什么选择right的时候需要让Left先走? 这里下面会有答案.
那么我们先来了解一下整个左右指针法的排序思想吧:

相信这个图你只要仔仔细细的看完,你就可以着手写代码了. 当你明白了思想,大的框架你就已经知道怎么写了.但是在这个时候尤其的
注意我们要注重细节!! 什么begin越界啊 还有哪里没有交换上. 书写代码! 这里我就直接添加代码了.
//左右指针法.
int partSort(int* a, int begin, int end)
{
int key = a[end];
int left = begin;
int right = end;
//key选择的是最左边,那么最右边就先走.
while (left < right)
{
while (left < right && a[left] <= key)
{
++left;
}
while (left < right && a[right] >= key)
{
--right;
}
if (left < right)
{
swap(a[right], a[left]);
}
}
swap(a[end], a[left]);
return left;
}
void quick_Sort(int *a, int begin,int end)
{
if (begin >= end)
return;
int pos = partSort(a, begin, end);
quick_Sort(a, begin, pos-1);
quick_Sort(a, pos+1, end);
}3>>前后指针法快速排序
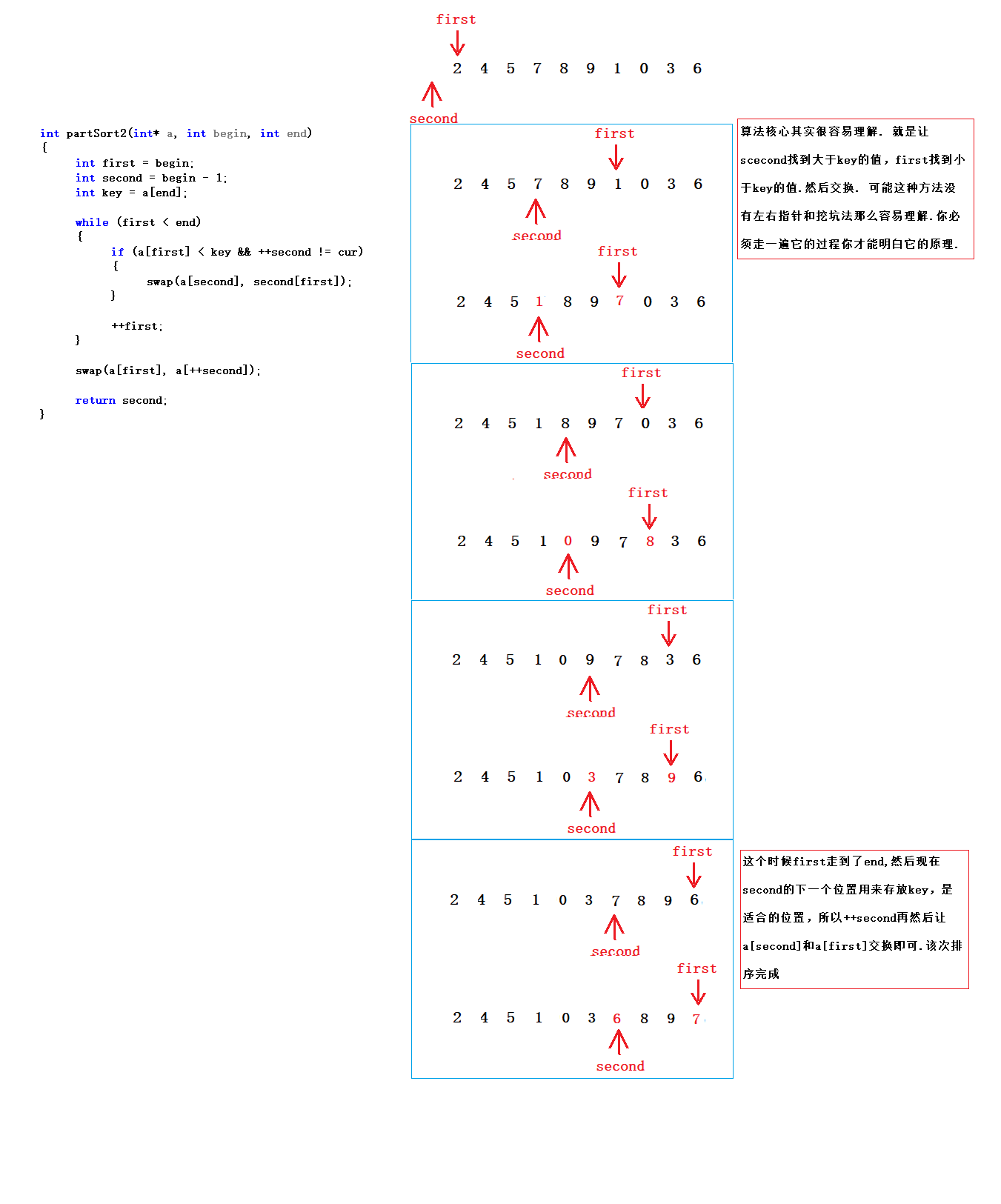
int partSort2(int* a, int begin, int end)
{
int first = begin;
int second = begin - 1;
int key = a[end];
while (first < end)
{
if (a[first] < key && ++second != first)
{
swap(a[second], a[first]);
}
++first;
}
swap(a[first], a[++second]);
return second;
}
void quick_Sort(int *a, int begin,int end)
{
if (begin >= end)
return;
int pos = partSort2(a, begin, end);
quick_Sort(a, begin, pos-1);
quick_Sort(a, pos+1, end);
}int GetMid(int *a, int left, int right)
{
int mid = left + (right - left) / 2;
if (a[left] < a[mid])
{
if (a[left]>a[right])
{
return left;
}
else if (a[mid] > a[right])
{
return right;
}
else
{
return mid;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
int GetMid(int *a, int left, int right)
{
int mid = left + (right - left) / 2;
if (a[left] < a[mid])
{
if (a[left]>a[right])
{
return left;
}
else if (a[mid] > a[right])
{
return right;
}
else
{
return mid;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return right;
}
else
{
return left;
}
}
}
int partSort2(int* a, int begin, int end)
{
int first = begin;
int second = begin - 1;
swap(a[end], a[GetMid(a, begin, end)]);
int key = a[end];
while (first < end)
{
if (a[first] < key && ++second != first)
{
swap(a[second], a[first]);
}
++first;
}
swap(a[first], a[++second]);
return second;
}
void quick_Sort(int *a, int begin,int end)
{
if (begin >= end)
return;
if (//在这里想办法判断层数)
{
Insert_sort();
}
int pos = partSort2(a, begin, end);
quick_Sort(a, begin, pos-1);
quick_Sort(a, pos+1, end);
}非递归实现:
//左右指针快速排序 非递归
void Quick_Sort(int* a,int size)
{
int left = 0;
int right = size - 1;
stack<int> q;
q.push(right);
q.push(left);
while (!q.empty())
{
left = q.top();
q.pop();
right = q.top();
q.pop();
int end = right;
int begin = left;
if (left < right)
{
swap(a[right], a[GetMid(a, left, right)]);
int key = a[right];
while (left < right)
{
while (left < right && a[left] <= key)
{
++left;
}
a[right] = a[left];
while (left < right && a[right] >= key)
{
--right;
}
a[left] = a[right];
}
a[right] = key;
q.push(end);
q.push(right + 1);
q.push(right - 1);
q.push(begin);
}
}
}总结
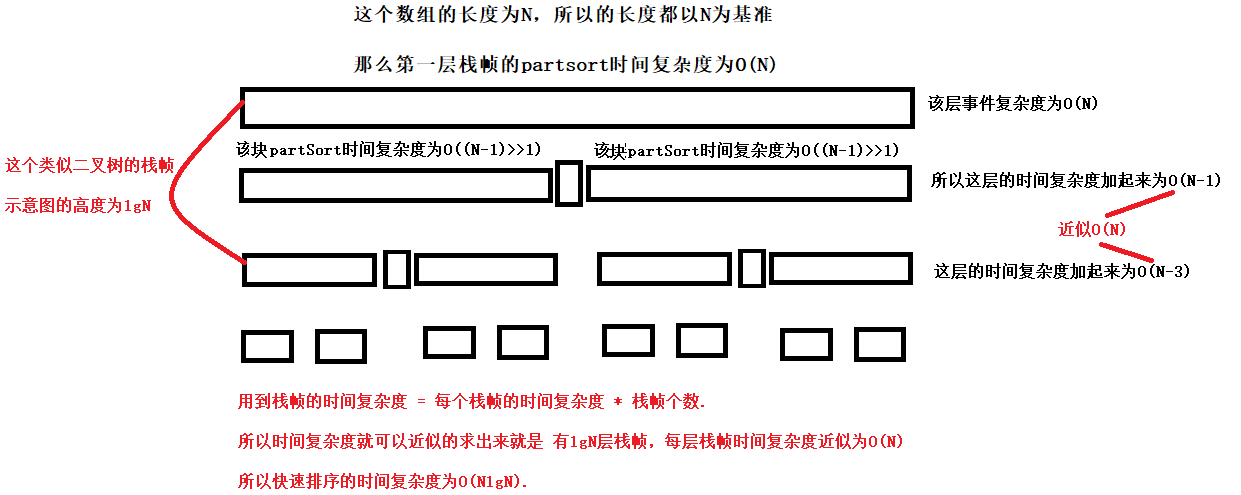
快速排序的时间主要耗费在划分操作上,对长度为k的区间进行划分,共需k-1次关键字的比较。最坏情况是每次划分选取的基准都
是当前无序区中关键字最小(或最大)的记录,划分的结果是基准左边的子区间为空(或右边的子区间为空),而划分所得的另一个非
空的子区间中记录数目,仅仅比划分前的无序区中记录个数减少一个。时间复杂度为O(NlgN)在最好情况下,每次划分所取的基准
都是当前无序区的"中值"记录,划分的结果是基准的左、右两个无序子区间的长度大致相等。总的关键字比较次数:O(NlgN)尽管
快速排序的最坏时间为O(n2),但就平均性能而言,它是基于关键字比较的内部排序算法中速度最快者,快速排序亦因此而得名。
它的平均时间复杂度为O(NlgN)。
算法名称 最差时间复杂度 平均时间复杂度 最优时间复杂度 空间复杂度 稳定性
快速排序 O(n2) O(NlgN) O(NlgN) O(n) 不稳定















 1630
1630

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









