







 本文探讨了Spark Streaming中数据处理及输出的最佳实践,强调了使用foreach算子而非Map算子的重要性,并介绍了如何通过建立静态连接池来降低对外部系统输出数据时的负载。
本文探讨了Spark Streaming中数据处理及输出的最佳实践,强调了使用foreach算子而非Map算子的重要性,并介绍了如何通过建立静态连接池来降低对外部系统输出数据时的负载。
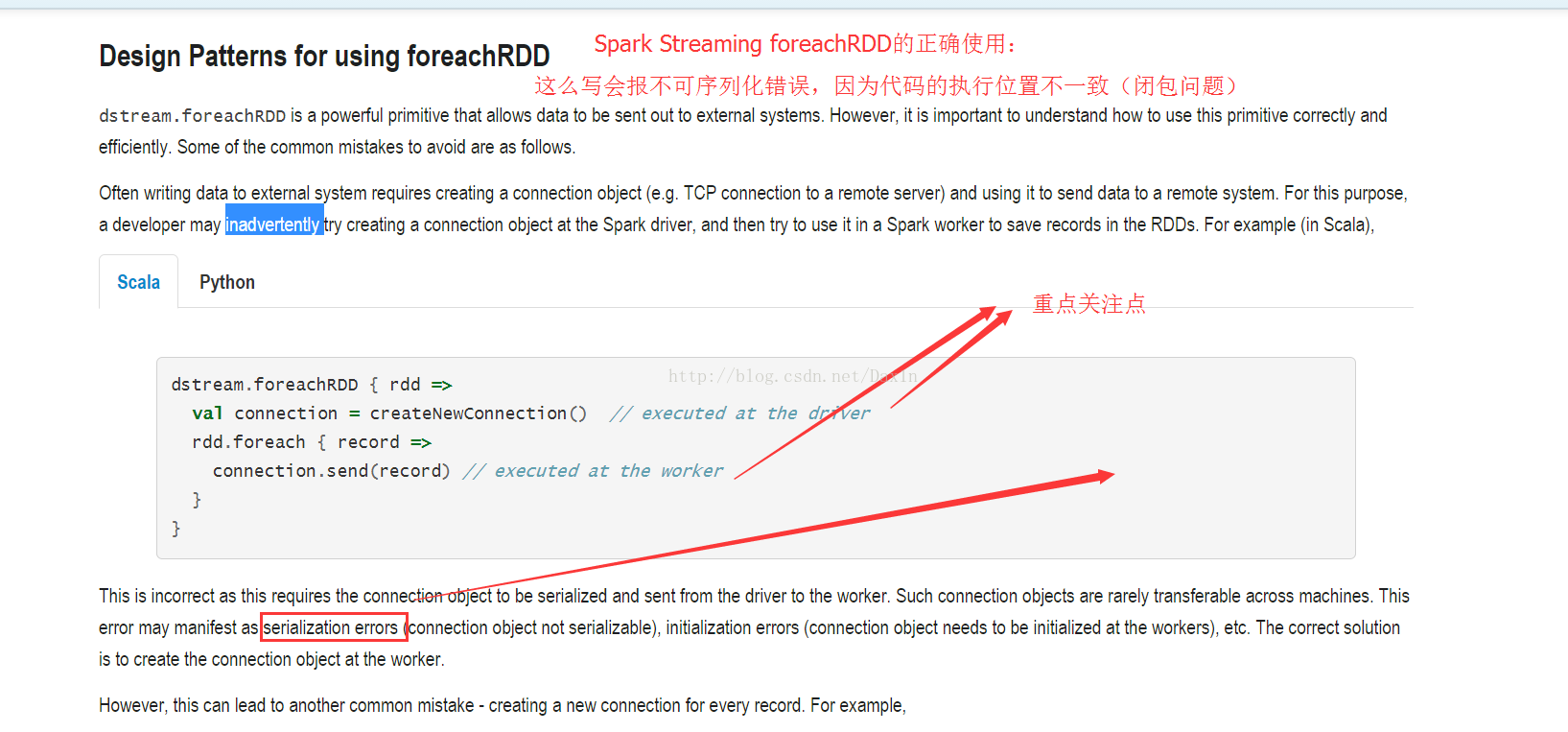
这一块是Spark闭包的问题,不懂自行看文档吧!
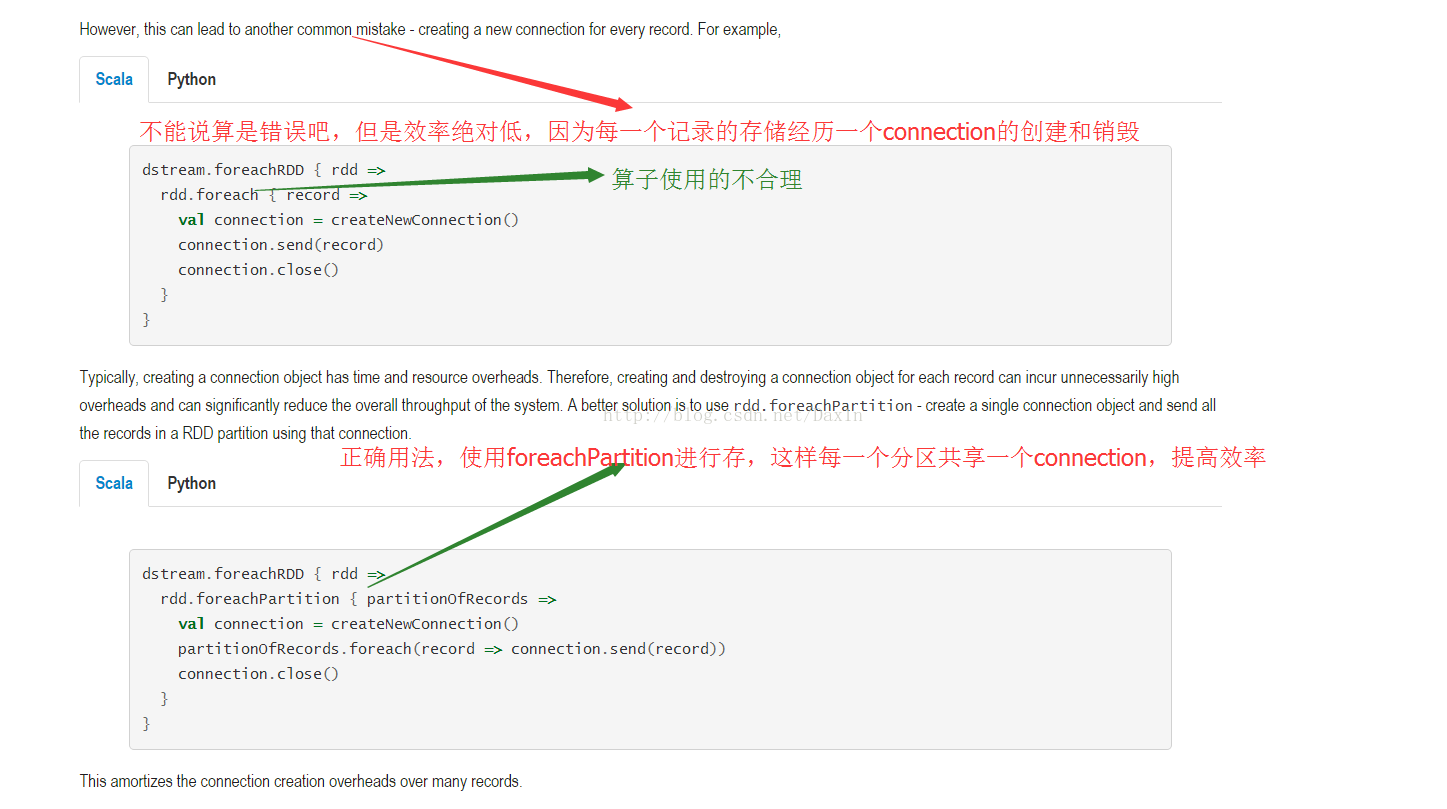
重点:Spark Streaming的foreachRDD运行在Driver端,而foreach和foreachPartion运行在Worker节点。
备注:对数据的向外输出,还是用foreach**算子好,不要用Map**算子,因为Map还要返回一个RDD。
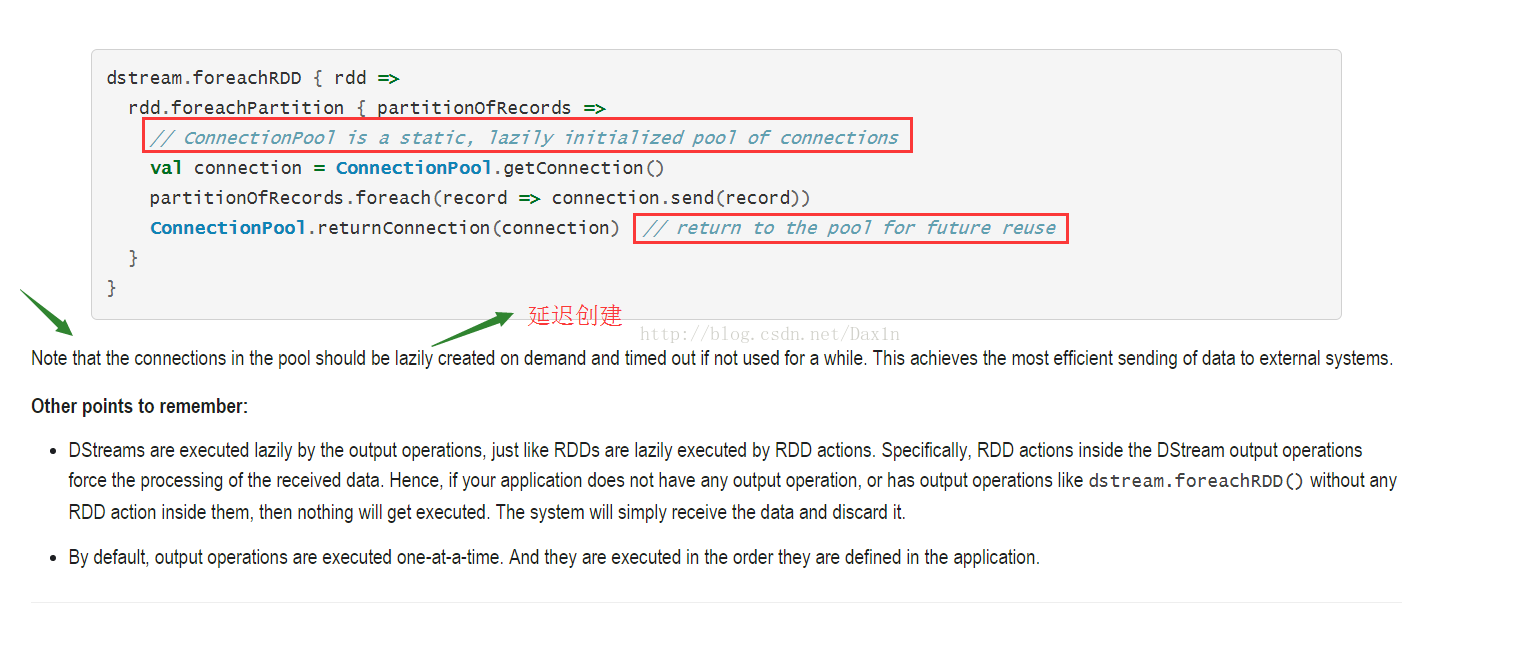
Finally, this can be further optimized by reusing connection objects across multiple RDDs/batches. One
can maintain a static pool of connection objects than can be reused as RDDs of multiple batches are pushed to the external system, thus further reducing the overheads.
最后还可以优化:多个RDD或者批次重用连接对象。可以建一个静态连接池,然后RDD向外Push数据时候可以重用,降低负载!


















 999
999

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











