







索引
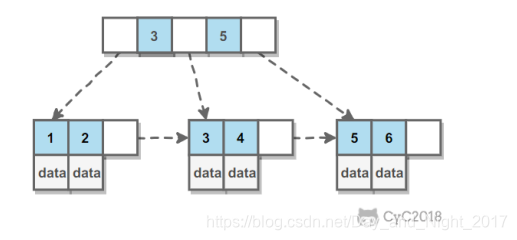
B+ Tree的数据结构
B tree就是平衡树,是一种查找树,所有叶子节点在同一层。
B+ Tree基于B Tree和叶子节点顺序访问指针实现。具备B数的平衡性,又具备顺序指针提高区间查询性能。
一个节点的Key从左到右非减排序。
B+ 树的操作
进行查找的时候,首先在根节点二分查找,找到key所在的指针。然后递归在指针所指向的节点查询。直到找到叶子节点。在叶子节点上二分查找,找到key对应的值。
插入删除数据对平衡性破坏,需要在插入删除后对树进行分裂、合并、旋转操作维护平衡性。
与红黑树的比较
1. B+树有更少的查找次数
O(h) = O(logd(N)) h是树高度,d是每个节点的出度。
红黑树出度2,高度就很大,B+ 树出度大,高度小。
2. 利用磁盘预读性
磁盘操作会预先读取一些数据,顺序读取不需要寻道,速度较快。索引的一个节点大小恰好是磁盘一个页的大小,使得一次IO可以完全载入一个节点,还可以利用预读特性预加载相邻节点。
Mysql索引
聚簇索引
大多数mysql引擎默认的索引类型。
不需要全表扫描,只需要对树搜索,速度较快。
B+树有有序性,所以不仅适应于查找,还可以排序和分组。
可以使用多个列进行索引,适用于全键值,键值范围,键前缀查找。
键前缀查找只适用于最左前缀查找。不是按照索引列顺序进行查找则无法使用索引。
InnoDB的B+索引分为两种,一种主索引,一种辅助索引。主索引的叶子结点记录完整的数据,称为聚簇索引。
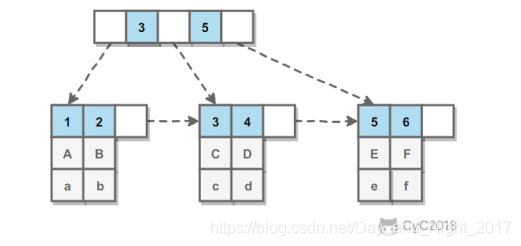
辅助索引的叶子结点记录主键,在使用辅助索引进行查找时,先找到主键值,再到主索引中查找。
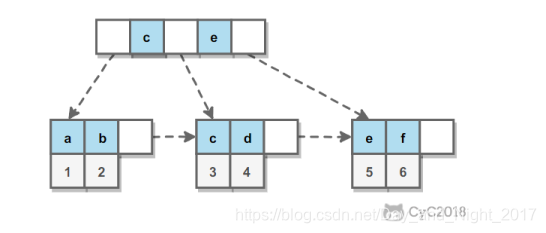
哈希索引
以O(1)速度进行索引,没有顺序概念,不适合分组排序。只能精确查找,不支持范围查找和部分查找。
InnoDB在B+树的基础上增加自适应哈希索引,对于频繁使用的索引值创建哈希索引,加速查找速度。
全文索引
MyISAM存储引擎支持全文索引,并非匹配文字,而是查找关键词。查找条件使用Match Against而不是where
InnoDB在5.6.4版本的Mysql开始支持全文索引。
全文索引是采用倒排索引,根据关键词映射到文章
空间数据索引
MyISAM引擎支持空间数据索引。用于存储地理数据。从所有维度索引数据,有效地组合任意维度查询。
必须使用GIS相关的函数来维护数据。
索引优化
1. 独立的列
查询的时候,索引不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。

2.多列索引比单列索引性能好

建议设置actor_id与film_id设置多列索引
3.索引列的顺序
让更具备唯一性的列放在前面,让查询速度提高。
4. 前缀索引
对于BLOB、TEXT、VARCHAR类型的列,必须使用前缀索引,只索引开始的部分字符。
5. 覆盖索引
索引包含所有要查询的字段。
覆盖索引能够覆盖所有查询的字段就不用访问主索引了。
索引的优点
1. 减少全表扫描带来的性能问题
2. 帮助服务器避免分组和排序
3. 将随机IO变成顺序IO
索引的使用
1. 建议在中大型表中使用索引。
2.在特大型的数据表中维护索引的代价增大。
查询性能的优化
使用Explain进行分析
分析select语句,根据分析结果优化语句
优化数据访问
减少数据的访问量:
1. 尽可能指定column而不是直接select *
2. 只返回必要的行,使用limit限制
3. 缓存重复查询的数据
减少服务端扫描的行数:
使用索引覆盖查询
重构查询方式
1. 切分大的查询
将多个查询切分出来,防止大量的锁表。
2. 分解大连接查询
将大的连接查询分解成每个表的单表查询,在应用程序中进行关联。
可以让缓存更加高效
减少锁的竞争
更容易对数据库拆分。
查询效率更高。
存储引擎
InnoDB
Mysql默认的支持事务的存储引擎。一般优选它。
默认是可重复读级别,通过多版本并发控制和间隙锁防止幻读。
主索引是聚簇索引,在索引中保存了数据,避免直接读盘。
预读性,自适应哈希索引,插入缓冲区等
仅InnoDB支持在线热备份。
MyISAM
设计简单,对于只读数据,表较小可使用。
支持压缩表,空间数据索引等。
不支持事务,
不支持行级锁,只支持锁表。读取的时候对所有涉及到的表加共享锁,写入时加排它锁。有表读取数据的时候,也可以对表插入数据,也就是支持并发插入。
索引可以先存到内存,延时插入磁盘,这样可以提高写入速度。
数据类型





数据库切分
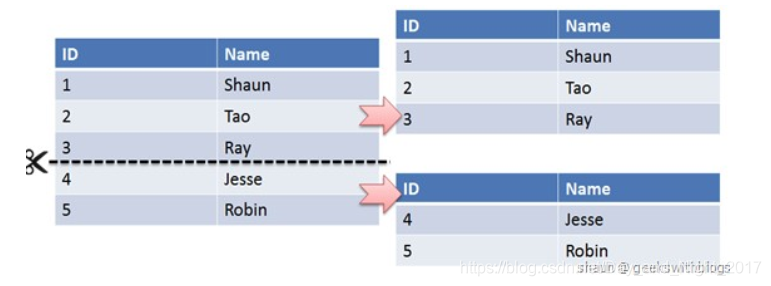
水平切分
将同个表的数据划分不同的表中(按行切分),每个表的数据结构是一致的。
垂直切分
将一张表按照列进行切分,按照列之间的关系,将不同的数据表划分到不同的库中。
Sharding的策略
采用哈希取模,hash(key) & N可以切分
范围映射:根据ID或者时间的范围分割
映射表:使用单独的表存储映射关系
Sharding带来的问题
事务问题:需要分布式事务解决
连接查询:将原来的连接查询分解成多个单表查询,在程序中连接
ID唯一性:
使用全局id,GUID
为分片指定一个范围
使用分布式ID生成器
主从复制
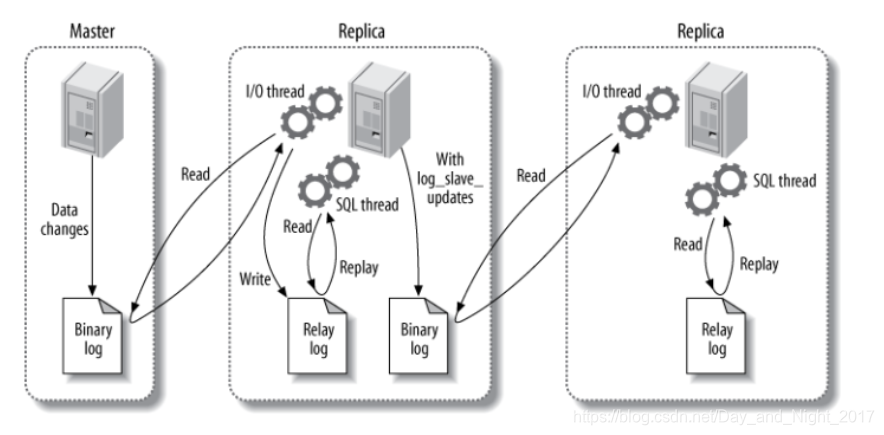
需要三个线程:
1. binlog线程
将主服务器数据更改写入二进制日志中
2. IO线程
将主服务器的二进制日志读取到从服务器并写入从服务器的中继日志
3. SQL线程
从服务器读取中继日志,解析数据并重新放置到服务器中。
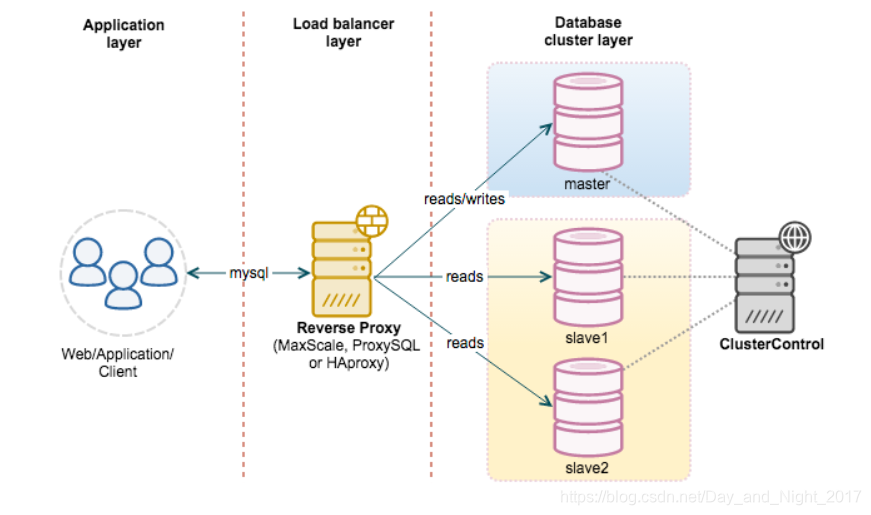
读写分离
主服务器主要涉及写入操作,从服务器涉及读取操作。
读写操作的锁的竞争减少了
从服务器使用MyISAM可以提高查询性能
增加冗余提高可用性。














 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









