







本文介绍如何使用GPU云服务器搭建Stable Diffusion模型,并基于ControlNet框架,快速生成特定物体图片。
背景信息
Stable Diffusion(简称SD)是一种AI模型,它经过训练可以逐步对随机高斯噪声进行去噪以生成所需要的图像。
DreamBooth是一种定制化text2image模型的方法,只需提供特定物体的3~5张图片,就能生成该物体的图片。我们使用DreamBooth对模型进行Finetune,并利用阿里云AI加速器中的AIACC-AGSpeed加速Finetune,同时引入ControNet增加生成图片的多样性。
ControlNet是一组网络结构,通过对SD添加额外的Condition来控制SD,目前提供的预训练Condition包括:Canny Edge,M-LSD Lines,HED Boundary,User Scribbles,Fake Scribbles,Human Pose,Semantic Segmentation,Depth,Normal Map,Anime Line Drawing。您可以同时添加多个ControlNet进行多Condition的控制。训练其他Condition来控制SD的具体操作,请参见Train a ControlNet to Control SD。
本文基于阿里云GPU服务器搭建Stable Diffusion模型,并基于ControlNet框架,快速生成特定物体图片。

重要
-
阿里云不对第三方模型“Stable Diffusion”的合法性、安全性、准确性进行任何保证,阿里云不对由此引发的任何损害承担责任。
-
您应自觉遵守第三方模型的用户协议、使用规范和相关法律法规,并就使用第三方模型的合法性、合规性自行承担相关责任。
操作步骤
创建ECS实例
-
在ECS实例创建页面,创建ECS实例。
关键参数说明如下,其他参数的配置,请参见自定义购买实例。
-
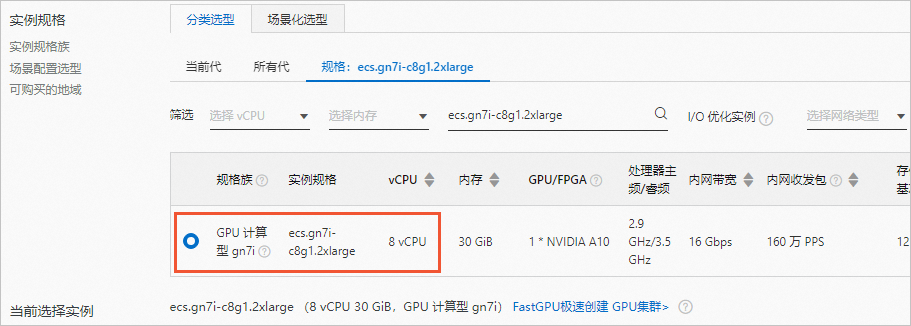
实例规格:选择ecs.gn7i-c8g1.2xlarge(单卡NVIDIA A10)。
-
镜像:使用云市场镜像,名称为aiacc-train-solution,您可以直接通过名称搜索该镜像,选择最新版本即可。
-

-
-
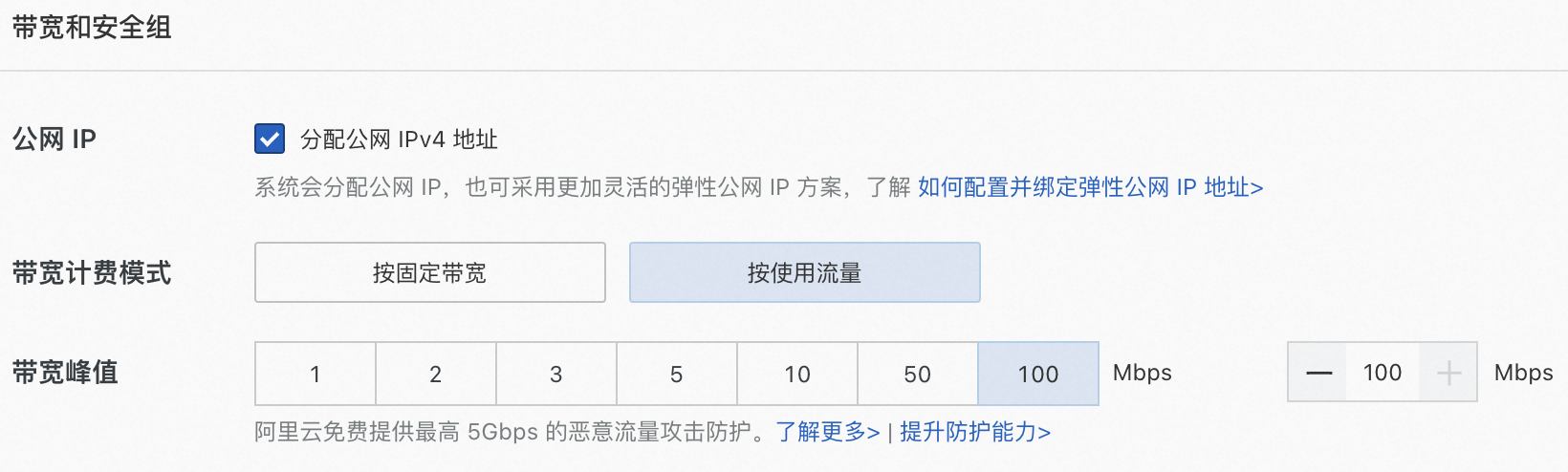
公网IP:选中分配公网IPv4地址,带宽计费方式选择按使用流量,带宽峰值选择100 Mbps,以加快模型下载速度。
-
-
添加安全组规则。
在ECS实例安全组的入方向添加安全组规则并放行7860端口。具体操作,请参见添加安全组规则。
以下示例表示向所有网段开放7860端口,开放后所有公网IP均可访问您的WebUI。您可以根据需要将授权对象设置为特定网段,仅允许部分IP地址可以访问WebUI。

配置模型
-
使用root用户远程登录ECS实例。
具体操作,请参见通过密码或密钥认证登录Linux实例。
-
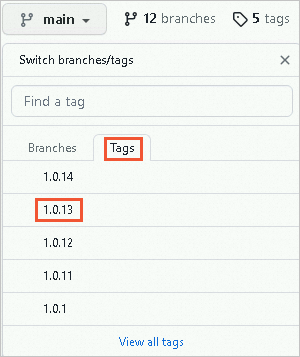
下载1.0.13版本sd_dreambooth_extension项目代码到
/root/stable-diffusion-webui/extensions目录。-
执行以下命令,切换到
/root/stable-diffusion-webui/extensions目录。cd /root/stable-diffusion-webui/extensions -
切换到1.0.13版本。
-
下载1.0.13版本sd_dreambooth_extension项目代码。
-
-
依次执行以下命令,下载文件。
wget https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/sd_utils/train_dreambooth.py -O /root/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/train_dreambooth.py wget https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/sd_utils/utils.py -O /root/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/utils/utils.py wget https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/sd_utils/image_utils.py -O /root/stable-diffusion-webui/extensions/sd_dreambooth_extension/dreambooth/utils/image_utils.py wget https://ali-perseus-release.oss-cn-huhehaote.aliyuncs.com/sd_utils/log_parser.py -O /root/stable-diffusion-webui/extensions/sd_dreambooth_extension/helpers/log_parser.py
启动并访问WebUI服务
-
依次执行以下命令,启动WebUI服务。
重要
WebUI服务启动后请不要关闭,否则无法访问WebUI页面。
cd /root/stable-diffusion-webui export HF_ENDPOINT=https://hf-mirror.com source /root/stable-diffusion-webui/venv/bin/activate python ./launch.py --listen --port 7860 --enable-insecure-extension-access --disable-safe-unpickle --xformersWebUI服务成功启动后,回显信息类似如下所示。

-
在ECS实例页面,获取ECS实例的公网IP地址。

-
在浏览器中输入
http://<ECS实例公网IP地址>:7860,访问WebUI。
模型微调(Finetune)
仅使用预训练的权重的模型,只能生成预训练数据集相似的图片。若您希望生成自定义的图片,可以通过Finetune自定义物体图片,使得模型生成所对应物体的图片。
-
创建模型权重。
-
单击DreamBooth页签,在Model区域,单击Create。
-
输入待生成的模型权重名称,例如:
aliyun_example,并选择创建模型权重的来源v1-5-pruned-emaonly.safetensors [6ce0161689])。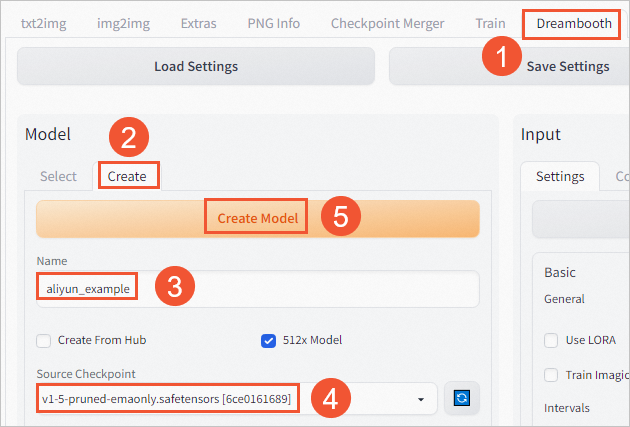
-
单击Create Model,创建模型权重。
等待模型权重创建完成后,在Output区域会显示
Checkpoint successfully extracted to /root/stable-diffusion-webui/models/dreambooth/aliyun_example/working。
-
-
设置训练参数。
-
单击Select,选择生成的模型权重
aliyun_example。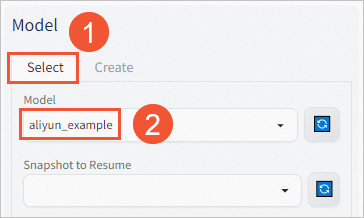
-
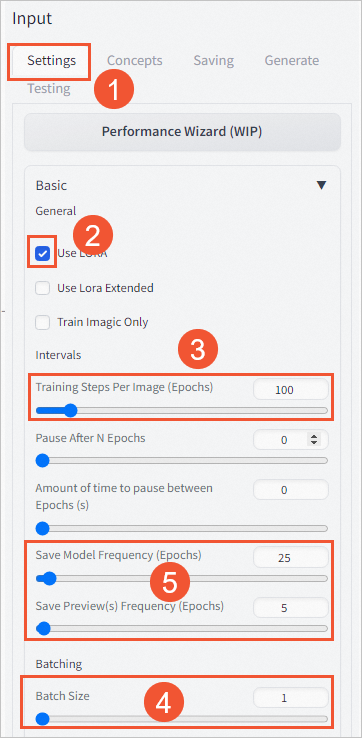
选择Input区域,在Settings页签下,选中Use LORA,并调整训练参数。
-
Training Steps Per Image (Epochs):指训练的迭代次数。默认为100,可根据实际需要调整。
-
Batch Size:训练数据的大小。默认为1,一般设置为1或2。
如果您希望Finetune流程更快,可将Save Model Frequency (Epochs)和Save Preview(s) Frequency (Epochs)参数值调大(如果设置的值较小,可能会导致Finetune时间较长且不稳定),不超过最大的Epochs数即可,最大的Epochs数=每张图片训练迭代次数Epochs*图片数量N。关于性能提升的更多信息,请参见Aiacc-training性能提升。
-
-
滚动鼠标将页面下拉,取消选中Gradient Checkpointing。
-
在Optimizer中选择Torch AdamW,Mixed Precision选择fp16或者no,Memory Attention选择xformers或者no,当Mixed Precision选择fp16时,才能选择xformers。

-
-
选择训练数据集。
-
在Input区域的Concepts页签下,在Dataset Directory中填入云服务器ECS中的数据集路径。
您可以将10张以内同一物体的图片上传到指定路径。
本示例中上传图片的路径为
/root/stable-diffusion-webui/test_imgs。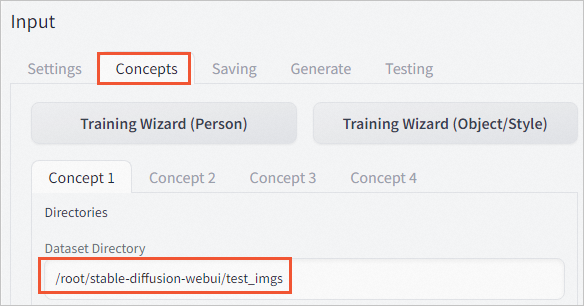
-
在Training Prompts和Sample Prompts区域,配置以下参数。
-
Instance Prompt:输入对数据集物体的描述,格式例如:a <物体名称> <物体类别>。本示例输入
a yunxiaobao doll。 -
Class Prompt:输入数据集物体的类别,格式例如:a <物体类别>,本示例输入
a doll。 -
Sample Image Prompt:输入和Instance Prompt参数一致的内容。本示例输入
a yunxiaobao doll。
-
-
-
单击Train,在弹出的对话框中单击确定。
训练大约需要3分钟,请您耐心等待。训练完成后,在Output区域显示类似如下图片。
说明
训练时间和实例规格、带宽峰值及其相关配置有关,这里的训练时间仅供参考。
生成图片
Finetune完成后,您可以通过以下方法生成图片。
使用Dreambooth生成图片
使用Dreambooth+新的prompt生成图片
使用DreamBooth+ControlNet生成图片
Finetune完成后,可以通过一些文字生成特定物体的图像。
-
单击Stable Diffusion checkpoint中的

按钮,从下拉框中选择之前Finetune好的模型权重。例如:
aliyun_example/aliyun_example_400_lora.safetensors [5b28fda46c]。 -
单击txt2img,在Prompt框中输入之前Finetune使用的Instance Prompt的内容。例如:
a yunxiaobao doll。 -
在Batch count后输入生成图片的数量,默认为1。
-
单击右侧的Generate,即可生成对应的物体图片。
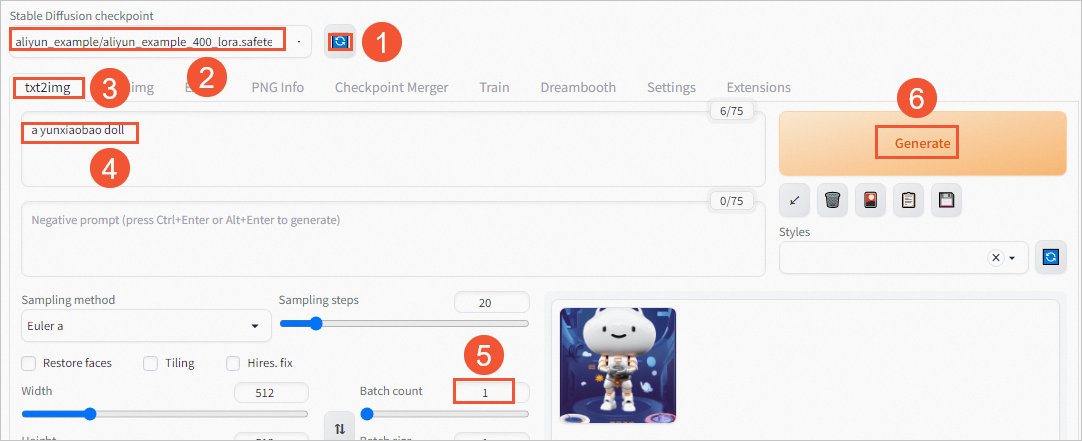
-
单击Save,保存图片。
您也可以单击Zip,压缩后保存图片,然后单击Download下载图片。

如果您选择Finetune前的模型权重v1-5-pruned-emaonly.safetensors [6ce0161689],生成的图片类似如下图所示。
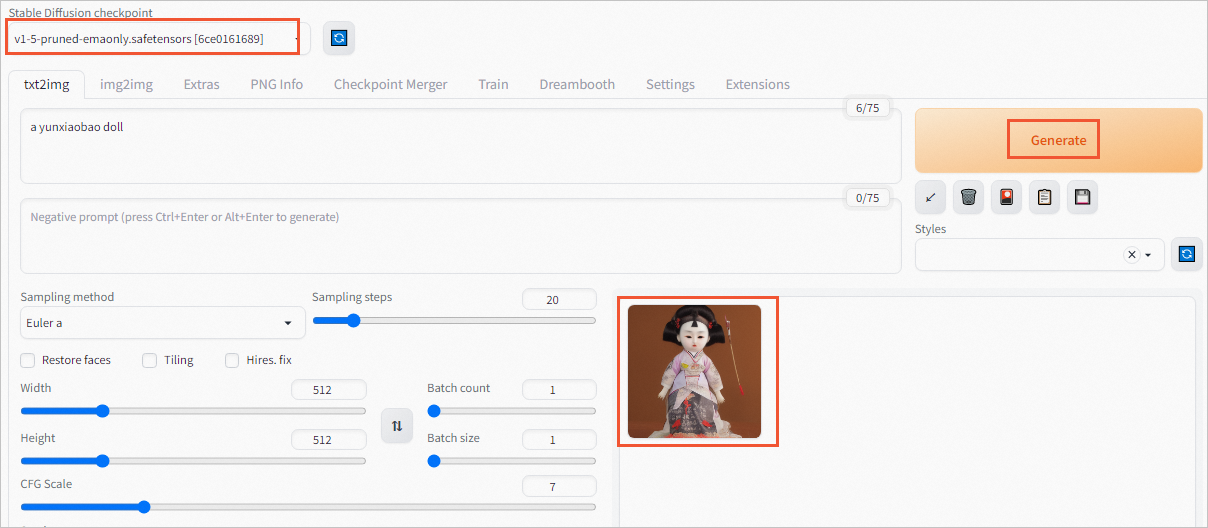
用于Finetune的原图片如下图所示,可见Finetune后的模型能够很好地生成所需图片,而Finetune前的模型则无法生成所需要的云小宝玩偶图片。

Aiacc-training性能提升
本示例以ECS实例的规格为ecs.gn7i-c32g1.32xlarge(4卡A10),Finetune4张图片,Training Steps Per Image(Epochs)设置为200为例,使用eager和AIACC-AGSpeed训练时间对比如下所示:
-
eager(原生训练方式)

-
AIACC-AGSpeed

从上图可以看出,加入AIACC-AGSpeed后,将Save Model Frequency (Epochs)和Save Preview(s) Frequency (Epochs)设置为1000,以减少保存文件的时间对整体时间统计的影响,训练性能提升大约18%。如果您想要获取极致的加速性能,可在WebUI页面修改以下参数值:
-
Training Steps Per Image (Epochs):默认值为100,可修改为150或200。
-
Save Model Frequency (Epochs):默认值为25,可修改为1000。
-
Save Preview(s) Frequency (Epochs):默认值为5,可修改为1000。

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









