







工具:sql developer
数据库对象
概述
数据库对象,简而言之就是数据库的组成部分,有表(Table)、触发器(Trigger)、视图(View)、存储过程(StoredProcedure)、索引(Index)、缺省值(Default)、图表(Diagram)、用户(User)、规则(Rule)、序列(sequence) 、表空间、同义词(synonym)等几类
简单解释一下
- 表 即二维表格,或称为关系
- 触发器 指定一个触发条件 触发条件激活时,就触发一系列sql动作
- 视图 为方便特定用户查看特定的数据 而显示的虚拟的表
- 存储过程 为完成特定的功能而汇集在一起的一组SQL程序语句,经编译后存储在数据库中的SQL程序。
- 索引 根据指定字段建立的顺序
- 缺省值 当表中创建列或插入数据时,对没有指定其具体值的列或列数据项,赋予事先设定好的值。
- 图表 数据库表之间的关系示意图
- 用户 有一定权限访问操作数据库的人
- 规则 对数据库表中数据信息的限制
- 序列 产生一系列唯一数字
- 表空间 一个逻辑概念
一个数据库可以包含多个表空间,一个表空间只能属于一个数据库
一个表空间包含多个数据文件,一个数据文件只能属于一个表空间 - 同义词 一种特殊的别名
同义词
基于其他数据库对象进行使用
同义词一般有两种:公有同义词 私有同义词
公有同义词
所有数据库对象都可以访问
创建前的准备工作

准备工作完成后切换到自己创建的用户下 如d用户下

此时,虽然创建了同义词,但我们依然不能通过Mydept来访问scott的dept表
即select * from Mydept会报错
这是因为,这个是个一厢情愿的操作
可以理解为d用户向全世界声明我想要看scott用户的dept表,
但同不同意让d用户看,权力还是在scott用户手里,
所以建立了同义词,还要获取到scott用户给查看的权限,d用户才能完成查看操作
即在scott用户下进行赋权

私有同义词
仅创建者可以访问

其他操作与公有同义词一致
序列
生成连续的整数数据对象
一般来说用来作为主键中的增长列
可以降序 也可以升序生成
创建格式
create sequence seq_name # 指定序列名称
start with num # 序列从指定大小开始
increment by step # 增长步长
maxvalue num|nomaxvalue # 序列最大值,或设为没有最大值
minvalue num |nominvalue # 序列最小值 或没有最小值
cache num|nocache # 指定序列生成有序数字时是否使用序列号
cycle |no cycle # 指定序列是否循环
注意!(一些犹如废话般的注意事项)
- 初始值必须大于等于最小值
- 初始值必须小于等于最大值
- 没有循环时 序列值取到最大值后就不能继续取了
- 有循环时,序列值取到最大值后会重新从最小值开始取 而不是从设定的start with 开始取
这些东西看上去像废话一样 但只有自己亲手用过才能明白是什么意思
创建序列也是需要赋予权限的 (管理员用户下)

d用户下

上述序列的使用
# 取出序列的下一值
序列名.nextval
# 取出序列的当前值
# 该方法在序列没有取出任何一个值的时候 不可用 自己试一下就知道了
序列名.currval

序列在表中的应用
在插入主键数据时,不用一个一个输入

视图
视图是查询语句的集合,视图只是一堆查询语句 不包含任何实质的数据
同样 第一步先赋权
管理员用户下

d用户下
常用的创建视图模式

当你只想看看这个表的具体字段结构时

- where 1=2 实际上是进行筛选 1=2返回的布尔值是false 则表中没有数据要返回 所以只会出现字段
一般为了防止其他权限不足的用户通过视图对基本表进行更改,会在建立视图时加上只读限制,使得视图只能看不能改
即在创建视图时加上with read only

注意!!
- 在创建视图时尽量不要使用group by ,因为视图是虚表,在进行筛选查询时会进行报错,因为where 与group by 的执行顺序问题
表空间
数据库系统的结构

数据库的逻辑结构

多个数据文件的存储空间
分类
- 系统表空间
每个oracle数据库必须具备的
存放表空间名称 表空间所含的数据文件存放数据库管理所需的信息 - 临时表空间
存储数据库运行期间所产生的临时数据,减少内存的压力
在数据库关闭时进行临时文件的清空 - sysaux
系统表空间的辅助表
降低system表空间的负荷 - users表空间
存放用户的数据和私有信息 - 撤销表空间(undodbs)
用户回滚数据的表空间

创建表空间
1、授创建表空间权限
管理员用户下

2、更改linux权限 使可以创建数据文件
创建数据文件时要在linux里进行权限的修改
启动docker的Oracle容器

启动成功后进入oracle,切换用户为root

赋权

3、在d用户下创建表空间

在linux下刚才启动的docker容器里的root下可以看到文件被创建了

解释一下
- '/root/a.ora ’ 表明在root目录下创建a.ora文件
- size 10M 表明a.ora被分配的大小是10M 实际上这个容量在不够时是可以扩展的
- extent management local 定义的是数据文件最小存储单元
# 这里有必要解释一下文件最小存储单元
# 有必要知道的是
# 不同文件系统决定了文件的最小存储单元不同
# 也决定了系统所允许的单个文件的最大存储量的不同
# windows使用的文件系统是NTFS
# FAT32 最小存储单位16KB 支持最大的单个文件大小为4G
# NTFS 最小存储单元4KB 支持最大的单个文件大小为2TB
# 所以最小存储单元也就是一个文件即便实际使用不足最小单元
# 也会占用最小存储单元大小的空间
当使用如下命令时可以在创建表空间时更改最小存储单元

需要注意的是!!
- 在没有删除表空间时,不要在linux里对创建的数据文件进行删除,删除后数据库就会崩溃
- 因为数据库在运行时会对数据库的表空间进行检测,如果发现表空间中的文件不完整,数据库就会崩溃
- 在Linux里使用cat 命令进行查看数据文件时,会发现数据文件里是一堆乱码,这是正常的
在建表和用户时可以进行指定表空间

扩容表空间
授权扩容权限

进行扩容

在Linux中查看修改后的文件大小情况

增加数据文件
授权
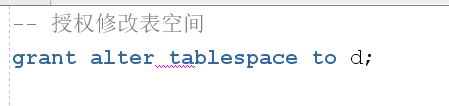
增加

在linux里进行查看

表空间的备份(冷备份)
数据的备份就是数据文件的备份
备份有两种方式
冷备份 和热备份
- 冷备份:在数据库进行关闭后进行备份
- 热备份:数据库运行状态下就可以备份
1、启动docker

2、进入容器、root用户下使环境变量生效

3、切换回oracle用户 登录oracle的管理员用户

4、查询数据库中所有的数据文件、控制文件、重做日志文件的路径



5、关闭数据库 回到docker容器

6、在root下创建bak文件夹,拷贝数据文件到该文件夹
创建文件夹

拷贝所有数据文件到bak
cp /home/oracle/app/oracle/oradata/helowin/*.dbf /root/bak
cp /root/*.ora /root/bak
cp /home/oracle/app/oracle/oradata/helowin/*.log /root/bak
cp /home/oracle/app/oracle/oradata/helowin/*.ctl /root/bak
复制完成后的结果

7、再启动sqlplus及数据库

备份完成后需要时只需要将备份文件对原数据库内的数据库文件替换即可
索引
一些理解
- 索引 类比于书的目录 根据目录上提供的位置 去找到所需的内容
- 索引减少了对数据的遍历,提高了查询的效率 但同时也占据了存储空间 是以空间换时间的做法
- 建立索引的字段会按照不同的算法进行排序,主要算法有二叉树、B树、bitmap,hash方式等
- 建立了索引后,进行查询时可以直接通过预先排好序的字段值,找到数据对应的rowid,通过rowid直接获取到要查找的数据
索引的建立建议
- 数据量较大时 适合建立索引 类比于当一本书很薄时,没有必要去查找目录
- 频繁增删改的表 尽量不要建立索引
- oracle默认对所有主键和建立了唯一约束的字段增加了索引
索引分类
- 普通索引 字段可以拥有重复值
- 唯一索引 只能建立在没有重复值或添加了唯一约束的字段
创建索引
不需要授权,直接创建就行
先建一个表举例说明
d用户下

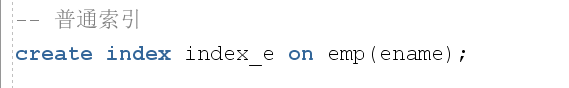

删除索引

重建索引
这里的意思是当前这个索引存在,将这个索引删除后重新建立,并且可以重新赋予该索引其他类型,但unique不能被赋予

SQL优化建议(14则)
- 查询语句尽量不要使用*, 而是select具体字段
因为当字段很多时,遍历起来非常慢 - 统计行数时,尽量使用count(1)而不是count(*) ,
原因同1 - 避免在where子句中使用or进行条件连接
因为or会使数据库放弃索引,直接使用全表扫描 - 避免在like 语句的%放在第一位 如like ‘%123’
因为不会使用索引,而是使用全表扫描 - 使用where 条件限定查询数据时,避免返回多余的行
- 尽量避免在建立索引的字段上使用函数
因为会导致索引失效 - 尽量避免在where条件中使用!=或<>
会导致索引失效 - 尽量在where以及order by涉及到的字段上建立索引
最大程度上避免全表扫描 - 慎重使用distinct关键字
系统在执行distinct时会去进行比对,消耗大量cpu资源 - 不要有超过5个以上的笛卡尔积(这个时候请反思自己)
- 单表的索引一般不要超过五个
- 尽量使用数字型字段,这里是和字符类型作比较
数据库读取字符型数据的开销要大于读取字符型的 - 在连接多个表时,推荐使用表的别名,并将别名缀于每一列上,这样语义更加清晰
- 为了提高group by效率,在使用分组前,在where子句中就将不需要的数据剔除掉 而不要等到使用having时才进行剔除















 945
945











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









