









免责声明:本次实践不含有商业成分,不存在商业目的。

图片,批量下载,再合成PDF
使用多线程,提速下载,一气呵成
获取PDF,真就如同探囊取物

代码如下:(皮皮用的是Python3)(使用Python2至少需要在多线程部分进行修改)
import requests
import threading
import os
import img2pdf
# 脚本爬取的目标是雨课堂的图片,目前只爬取一个PPT的所有图片,然后合成PDF
# 注意运行脚本时,cookie和UA已经替换成有效的,且必需连网
headers = {
'Cookie': '_ga=你的cookie;'
'sensorsdata2015jssdkcross=你的cookie;'
'django_language=你的cookie;'
'JG_fcdf8e635093adde6bef42651_PV=你的cookie;'
'login_type=你的cookie;'
'csrftoken=你的cookie;'
'sessionid=你的cookie',
'User-Agent': '你的UA伪装'
}
def WinPathToLinuxPath(p):
ll = p.split('\\') # delete the '\' of path
linux_path = '/'.join(ll) # add the '/' into path
# 判断文件夹结尾判断有没有'/'
if linux_path[-1].__eq__('/'):
return linux_path
else:
return linux_path+'/'
def downLoad(response, i, path_, path_2_):
print('正在下载第'+str(i+1)+'张图片', end='\r', flush=True)
pic = requests.get(url=response[i]['cover'], headers=headers).content
# 都用三个数字来命名,位数不足的在前面补零。如果不这样做,合成出的pdf可能页面顺序不对
if i<9:
name = path_+'00'+str(i+1)+'.jpeg'
elif i<99:
name = path_+'0'+str(i+1)+'.jpeg'
else:
name = path_+str(i+1)+'.jpeg'
with open(name, "wb") as f:
f.write(pic)
f.close()
if response[i]['problem'] is not None: # 保存那些作为题目发送的PPT页面的答案
with open(path_2_+'课堂练习答案.txt', "a") as f:
f.write(str(response[i]['index'])+str(response[i]['problem']['content']['answer'])+'\n')
f.close()
def get_YuKeTang_pic(path_, path_2_, xhr_url_):
url_ = xhr_url_.split('?')[0]
param = {
'presentation_id': xhr_url_.split('?')[1].split('&')[0].split('=')[1],
'lesson_id': xhr_url_.split('?')[1].split('&')[1].split('=')[1]
}
response = requests.get(url=url_, params=param, headers=headers).json()
with open(path_2_+'课堂练习答案.txt', "a") as f:
ppt_name = response['data']['presentation']['title'] # 获取PPT的名称,用作PDF的名称
f.write(ppt_name+'\n')
f.close()
response = response['data']['slides']
threads = [] # 使用多线程
for i_ in range(len(response)):
t = threading.Thread(target=downLoad, args=(response, i_, path_, path_2_))
# target参数指向目标函数,args参数传入该函数所需的参数
t.start()
threads.append(t)
for t in threads: # 等待所有的线程都运行完
t.join()
return ppt_name
def picToPDF(picPath_,pdfPath_,name_):
# 1、生成地址列表
photo_list = os.listdir(picPath_)
photo_list = [os.path.join(picPath_,i) for i in photo_list]
# 2、指定pdf的单页的宽和高,单位'mm'或'px'
# 一像素大约等于0.35毫米
category = input('指定单位:')
width = int(input('指定pdf的单页的宽:'))
high = int(input('指定pdf的单页的高:'))
if category=='mm':
pass
elif category=='px':
width=int(0.35*width)
high=int(0.35*high)
a4inpt = (img2pdf.mm_to_pt(width), img2pdf.mm_to_pt(high))
layout_fun = img2pdf.get_layout_fun(a4inpt)
# 3、生成pdf文件
with open(pdfPath_+name_+'.pdf', 'wb') as f:
f.write(img2pdf.convert(photo_list, layout_fun=layout_fun, rotation=img2pdf.Rotation.ifvalid))
f.close()
# 【img2pdf.convert参数rotation=img2pdf.Rotation.ifvalid】
# 使用rotation=img2pdf.Rotation.ifvalid是因为之前出现过如下报错【非必要时该参数可不加】
# img2pdf.ExifOrientationError: Invalid rotation (0): use --rotation=ifvalid or rotation=img2pdf.Rotation.ifvalid to ignore
# 【参考链接】https://github.com/ocrmypdf/OCRmyPDF/issues/894【img2pdf.ExifOrientationError很容易修复】
if __name__=='__main__':
print('input the path of Windows:', end='') # 输入保存图片的文件夹的路径
winPath = input()
path = WinPathToLinuxPath(winPath) # 格式化这个路径
print('input the path_2 of Windows:', end='') # 输入另一个路径,用来保存一个txt文件
winPath = input()
path_2 = WinPathToLinuxPath(winPath) # 格式化这个路径
print('input the url:', end='')
xhr_url = input()
ppt_name_ = get_YuKeTang_pic(path, path_2, xhr_url)
print('是否需要立刻合成PDF?', end='') # 询问是否需要立刻合成PDF
judge = input()
if judge=='YES':
print('input the pdf path of Windows:', end='')
winPath = input()
pdfPath = WinPathToLinuxPath(winPath) # 格式化这个路径
picToPDF(path, pdfPath, ppt_name_)看一下皮皮的输入示例:
input the path of Windows:C:\Users\x\Desktop\pic
input the path_2 of Windows:C:\Users\x\Desktop
input the url:https://www.yuketang.cn/api/v3/lesson-summary/student/presentation?presentation_id=******&lesson_id=******
是否需要立刻合成PDF?YES
input the pdf path of Windows:C:\Users\x\Desktop\pdf
指定单位:px
指定pdf的单页的宽:1280
指定pdf的单页的高:960这里面的URL,是雨课堂网站里抓包复制来的,
只抓取PPT打开的一瞬间的那个Ajax请求就可以
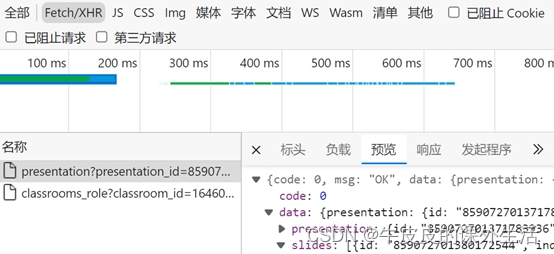
对于小白来说,这100多行的代码里,有一些方法可能没学过,比如:
怎样将win路径转化为Linux路径?
怎样用Python语句索引json文件中的值?
怎样使用多线程?
怎样等待所有线程运行完毕之后再运行之后的代码?
怎样将大量的图片合成一个PDF?
皮皮把之前学习过的一些链接放在下面,也许能提供一些帮助
python怎么索引json中的值 https://blog.csdn.net/weixin_39779537/article/details/111443084多线程实现多任务节省工作时长https://blog.csdn.net/qq_41604569/article/details/129802437如何使python中线程等待其他线程完了再执行https://blog.csdn.net/weixin_39589455/article/details/126809443python下将图片合成PDFhttps://blog.csdn.net/weixin_42081389/article/details/100734926
https://blog.csdn.net/weixin_39779537/article/details/111443084多线程实现多任务节省工作时长https://blog.csdn.net/qq_41604569/article/details/129802437如何使python中线程等待其他线程完了再执行https://blog.csdn.net/weixin_39589455/article/details/126809443python下将图片合成PDFhttps://blog.csdn.net/weixin_42081389/article/details/100734926


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









