







哈夫曼编码和译码
实验目的 :
理解最优二叉树,即哈夫曼树(Huffman tree)的概念,熟悉它的构造过程。
实验内容:
实现对ASCII字符文本进行Huffman压缩,并且能够进行解压。 将给定的文本文件使用哈夫曼树进行压缩,并解压。
基本要求为:
能将文本文件压缩、打印压缩后编码、解压压缩后的文件。对实际使用的具体数据结构除必须使用二叉树外 不做要求。
参考信息 :
用一个二叉树表示哈夫曼树,因为ASCII表一共只有127个字符,可以直接使用数组来构造Huffman树。 leftChild和rightChild分别表示当前结点左儿子和右儿子的下标。因为1到127分别表示与ASCII表的符号相对应,所以这里 无需记录每个结点代表什么符号。
struct Node
{
int leftChild;
int rightChild;
} tree[256];
题目中给出了一个数组其中可以存放256个元素,而ASCII字符除去ASCII值为0的字符之外有127个,他们如果进行哈夫曼树的构造组合在一起(不重复)形成的新节点最多也才127-1即126个,这种存储思路是符合给存储结构的。
按照我的思路,先全部读取ASCII字符文本的内容( \n 也是ASCII字符,不可忽略),然后统计出每个字符所出现的频率,再根据哈夫曼树的构造原理实现出一课哈夫曼树并返回其根节点,在通过返回的根节点进行编码操作并存入编码文件同时打印在屏幕中,再读取编码文件中的内容进行译码操作存入编码文件并进行打印输出操作。
在这其中有几个关键操作:
CreatMtree:
创建一个vector容器cs,里面存放的是pair<int,int>类型的元素,前一个int存放的是字符对应的ASCII值或者是构造哈夫曼树过程中ASCII值之和,后一个int对应的是该字符出现的次数(权重)。
用一个for循环,遍历所有的字符,并定义一个标签初始化为0,再定义一个for循环,遍历所有cs字符,如果外层for循环的字符的ASCII值有和cs的相同,那么其次数++,如果遍历完了cs都没有,那么就将这个字符的ASCII值加入cs并初始化为1.
void CreatMtree(vector<pair<int, int>>&cs,string tmp)
{
for (int i = 0; i < tmp.size(); i++)
{
int tag = 0;//添加标签
for (int j = 0; j < cs.size(); j++)
{
if ((int)tmp[i] == cs[j].first)//如果有相等的情况
{
cs[j].second++;//出现次数++
tag = 1;//if有相等的,标签记录
}
}
//遍历完了之后都没有相等的情况
if (tag == 0)
{
cs.push_back({ tmp[i],1 });
}
}
}
CreatTree:
在tree数组中,前1-127对应的是ASCII字符,那么从128开始便是对应构建哈夫曼树节点的存储,再根据哈夫曼树的构建规则,找到2个最小的构建成一棵树并将其权重相加存入,再找最小的(ASCII值或者相加的值),直到只剩一棵树。在中间操作过程中,由于是数组操作,即需要下标更新,每回进行更新最小时都是选择容器中第一个作为参照,需要在每一次操作后能够更新下标,避免出现错误。同时返回根节点。
int CreatTree(vector<pair<int, int>>& cs, Node* tree)
{
int tree_index = 127;//tree_index 记录的是树中的下标,从127开始
while (cs.size() != 1)//当cs中只有一个数时,结束
{
int cs_min1_power = cs[0].second;//找到最小的2个(权)将其存储构建树
int cs_min1_ascii = cs[0].first;//找到最小的2个(ASCII)将其存储构建树
int cs_index = 0;//cs_index是最小值的下标,便于删除
for (int i = 0; i < cs.size(); i++)//找第一个最小值
{
if (cs[i].second < cs_min1_power)
{
cs_min1_power = cs[i].second;//找到最小赋给cs_min1
cs_min1_ascii = cs[i].first;
cs_index = i;//更新下标
}
}
//找完了
cs.erase(cs.begin() + cs_index);//删除最小值的那个节点
//tree[cs_index].leftChild = -1;//将该节点左右孩子赋为-1
//tree[cs_index].rightChild = -1;
cs_index = 0;//更新
int cs_min2_ascii = cs[0].first;
int cs_min2_power = cs[0].second;
for (int j = 0; j < cs.size(); j++)//找第二个最小值
{
if (cs[j].second < cs_min2_power)
{
cs_min2_power = cs[j].second;//找到最小赋给cs_min2
cs_min2_ascii = cs[j].first;
cs_index = j;//更新下标
}
}
//找完了
cs.erase(cs.begin() + cs_index);//删除最小值的那个节点
//tree[cs_index].leftChild = -1;//将该节点左右孩子赋为-1
//tree[cs_index].rightChild = -1;
tree_index++;
tree[tree_index].leftChild = cs_min1_ascii;//将左右孩子存入树中的节点位置
tree[tree_index].rightChild = cs_min2_ascii;
cs.push_back({ tree_index ,cs_min1_power + cs_min2_power });//将新的节点存入cs
}
//执行完操作后只剩一个跟节点还在cs中
cs.clear();//进行清空操作,便于下一行进行操作
return tree_index;
}
CodeFream:
因为在编码过程中需要找到每一个节点的路径才能实现编码的目的,而如果使用深度优先搜索每回都要从头开始重新来过,这里便构造一个函数将每个节点的路径存储起来,便于整个编码过程。
在哈夫曼树中的节点的孩子节点只有2种情况:1种是叶子结点,一种是有2个孩子,所以分2种情况讨论(采用递归形式),顶一个tag存储没每个节点的路径,root表示当前节点的下标,cf为每个节点的路径:
- 如果是叶子节点的情况,那么将root和tag加入cf.
- 如果是非叶子节点,那么tag先添加0,在进入左子树递归,左子树递归出来后往回退一步表示返回上一个节点,在tag添加1,递归右子树。
void CodeFream(vector<pair<char, string>>& cf,int root,Node* tree,string tag)//将字符对于的编码存入数组
{
//在哈夫曼树中的节点的孩子节点只有2种情况:1种是叶子结点,一种是有2个孩子
if (tree[root].leftChild == 0)//如果是叶子节点的情况
{
cf.push_back({ (char)root,tag });
return;
}
else//非叶子节点
{
tag.append("0");//先走左子树,添0
CodeFream(cf, tree[root].leftChild, tree, tag);
tag.pop_back();//往回退一位
tag.append("1");//走右子树,添1
CodeFream(cf, tree[root].rightChild, tree, tag);
}
}
Code:
编码就很简单了,根据ASCII文件中的字符一个个访问cf,然后进行路径打印操作并存入定义好的编码文件中,同时将编码的字符存入tag便于译码。
void Code(ofstream& ofs, string tmp, vector<pair<char, string>>& cf, string& tag)//进行编码操作
{
cout << "编码结果:" << endl;
for (int i = 0; i < tmp.size(); i++)
{
for (int j = 0; j < cf.size(); j++)
{
if (tmp[i] == cf[j].first)
{
ofs << cf[j].second;
cout << cf[j].second;//进行打印操作
tag.append(cf[j].second);//将字符存入tag便于译码操作
}
}
}
cout << endl;
//刚开始用了 cf.clear(),因为是一行行读取,现在不用(全文读取),便于后续操作
}
Decode:
译码也不难,根据根节点和编码的步骤一步步往下走,当找到了叶子节点就输出返回到根节点,要注意的是这种输出方式是输出的节点后必须有操作,而最后一个节点不满足此条件,那么只需将其单独拿出来输出就ok,同时译码也将结果存入定义好的文件中。
void Decode(ofstream& yofs,Node* tree, string tag,int root)//进行译码操作
{
int tmp = root;//临时下标
cout << "译码结果:" << endl;
for (int i = 0; i < tag.size(); i++)//逐步骤进行
{
if (tree[tmp].leftChild == 0)
{
cout << (char)tmp;
yofs << (char)tmp;
tmp = root;//回到跟节点进行下一次操作
}
if (tag[i] == '0' && tree[tmp].leftChild !=0)
{
tmp = tree[tmp].leftChild;
}
if (tag[i] == '1' && tree[tmp].rightChild != 0)
{
tmp = tree[tmp].rightChild;
}
}
cout << (char)tmp << endl;//这个结构属于要打印出一个节点,那么该节点后面必须还有操作,因为最后一个节点无法打印,这就需要单独进行操作
yofs << (char)tmp;
}
最后放一下结果对比图吧
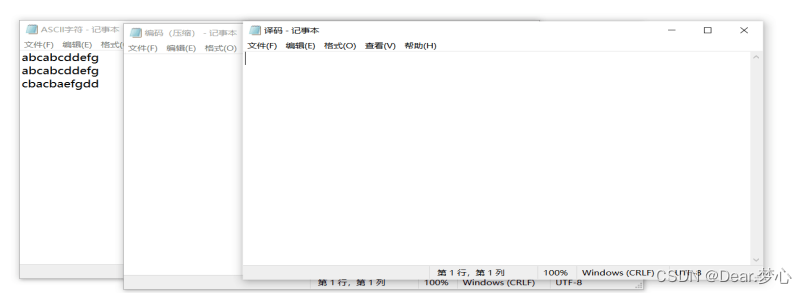
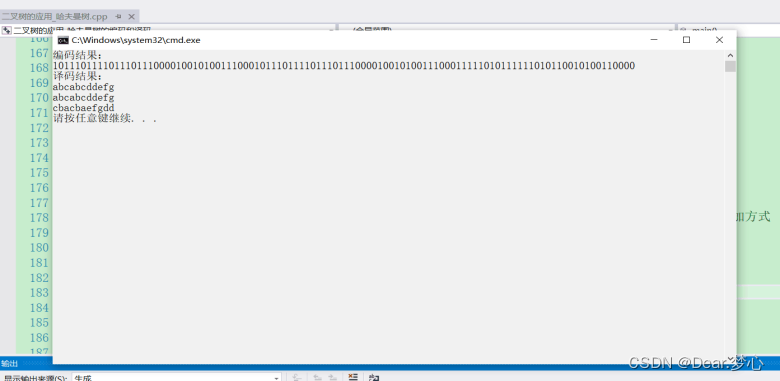
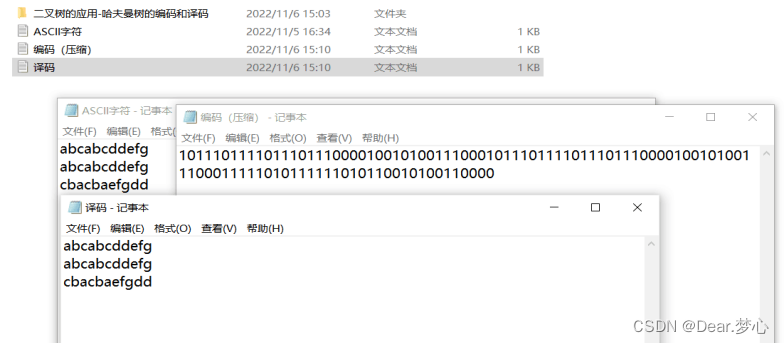
如果你和朋友构造哈夫曼树方法是一样的,构造的哈夫曼树是一样的,那你们是可以完成 0 1 加密通话哟。同时上诉方法只能实现ASCII字符存在的。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









