







一、五大常用聚合函数
- SUM():求总和,只适用于数值类型字段,如果是字符串类型不会报错会返回0,会自动过滤空值
- AVG():求平均值,只适用于数值类型字段,字符串类型不会报错会返回0,会自动过滤空值
- MAX():求最大值,适用于数值类型、字符串类型和日期时间类型字段
- MIN():求最小值,适用于数值类型、字符串类型和日期时间类型字段
- COUNT():用于计算查询结果集中的数据共有多少条
- COUNT(*)
- COUNT(常数):例如COUNT(0),COUNT(1)
- COUNT(指定字段):此方式只能用于那种不存在NULL的字段,如果存在空值,统计总数时不计入
- 如果是MyISAM引擎,这三种方式的效率相同,因为此引擎内部有一个计数器在维护着行数。如果是InnoDB引擎,那么第一和第二种效率高于第三种,后面会细说
注意:MySQL中聚合函数是不能嵌套使用的
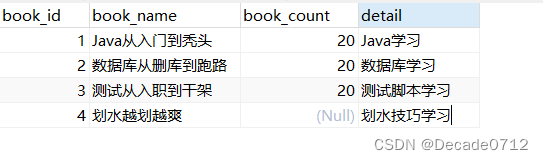
我们创建一个表t_decade_book来进行验证
DROP TABLE IF EXISTS `t_decade_book`;
CREATE TABLE `t_decade_book` (
`book_id` int(10) NOT NULL AUTO_INCREMENT COMMENT '书id',
`book_name` varchar(100) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '书名',
`book_count` int(10) DEFAULT NULL COMMENT '数量',
`detail` varchar(200) CHARACTER SET utf8 COLLATE utf8_general_ci NOT NULL COMMENT '描述',
PRIMARY KEY (`book_id`) USING BTREE
) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_general_ci ROW_FORMAT = Dynamic;
INSERT INTO `t_decade_book` VALUES (1, 'Java从入门到秃头', 20, 'Java学习');
INSERT INTO `t_decade_book` VALUES (2, '数据库从删库到跑路', 20, '数据库学习');
INSERT INTO `t_decade_book` VALUES (3, '测试从入职到干架', 20, '测试脚本学习');
INSERT INTO `t_decade_book` VALUES (4, '划水越划越爽', NULL, '划水技巧学习');
得到的表数据如下
SELECT AVG(book_count),SUM(book_count),AVG(book_count)*4 FROM t_decade_book;
SELECT MAX(book_count),MIN(book_count),MAX(book_name),MIN(book_name) FROM t_decade_book;
SELECT COUNT(book_id),COUNT(1),COUNT(*),COUNT(book_count) FROM t_decade_book;
SELECT AVG(book_count),SUM(book_count),SUM(book_count)/4,SUM(book_count)/COUNT(book_count) FROM t_decade_book;
执行结果如下
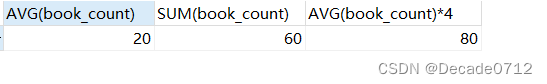



二、GROUP BY
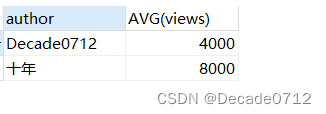
首先我们向之前创建的t_decade_blog表中插入一条数据
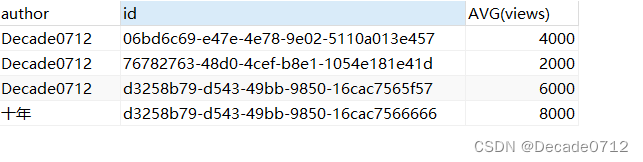
INSERT INTO t_decade_blog(id,name,author,create_time,views)VALUES('d3258b79-d543-49bb-9850-16cac7566666','JVM系列','十年',NOW(),8000);
表格中结果如下

然后我们测试一下GROUP BY操作
# 根据单列进行分组
SELECT author,AVG(views) FROM t_decade_blog GROUP BY author;
# 根据多列进行分组,如果分组的条件相同,顺序不同不会影响最终结果
# 我们可以理解为根据这些条件进行组合,只有符合这些条件的才会分到一个组里
SELECT id,author,AVG(views) FROM t_decade_blog GROUP BY id,author;
SELECT author,id,AVG(views) FROM t_decade_blog GROUP BY author,id;
# 当使用GROUP BY关键字时,SELECT中涉及到的非聚合函数包含的字段,必须出现在GROUP BY后面
# 但是GROUP BY关键字后面的字段不一定要出现在SELECT之后
# 另外,在不使用GROUP BY时,聚合函数不能和普通字段放在一起进行查询
SELECT author,id,AVG(views) FROM t_decade_blog GROUP BY author;
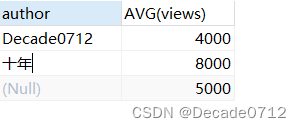
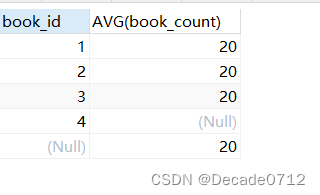
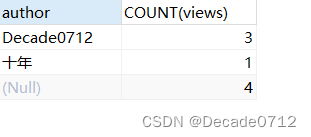
# with rollup作用在聚合函数。如果聚合函数是COUNT(*)则会在统计的记录中再次求COUNT(*)
# 如果是AVG(),则会去除分组条件,求该字段的AVG()
# 使用WITH ROLLUP后不能再使用ORDER BY
SELECT author,AVG(views) FROM t_decade_blog GROUP BY author WITH ROLLUP;
SELECT book_id,AVG(book_count) FROM t_decade_book GROUP BY book_id WITH ROLLUP;
SELECT author,COUNT(views) FROM t_decade_blog GROUP BY author WITH ROLLUP;
执行结果如下

注意GROUP BY的使用顺序
- 放在
FROM、WHERE后面 - 放在
ORDER BY、LIMIT前面
三、HAVING
1、HAVING 子句可以让我们筛选分组后的各组数据
- 当我们想使用聚合函数作为数据的过滤条件时,就不能搭配
WHERE使用了,必须使用HAVING来进行替换。比如我们想筛选出哪些部门的最高工资大于10000,那么就要先根据部门id进行分组,然后再使用HAVING对MAX(salary)进行过滤 - 如果过滤条件中没有聚合函数,那就强烈建议使用
WHERE HAVING必须声明在GROUP BY后面- 在日常开发中,使用
HAVING的前提是我们使用了GROUP BY
2、HAVING和WHERE的对比
- 从适用范围来说,
HAVING更广 - 如果过滤条件中没有聚合函数,那么
WHERE的执行效率要高于HAVING。因为WHERE的执行顺序是排在HAVING前面的,它会筛选掉不满足条件的数据,这样后面GROUP BY分组以及HAVING要处理的数据量就更小了
# 错误演示
SELECT id,MAX(views)
FROM t_decade_blog
WHERE MAX(views) > 4000
GROUP BY id;
SELECT id,MAX(views)
FROM t_decade_blog
GROUP BY id
HAVING MAX(views) > 4000;
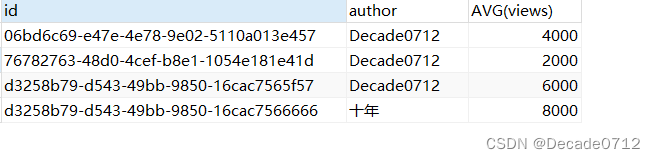
# 如果我们想查出特定博客id中最大浏览量大于4000的书籍
# 方式一:WHERE搭配HAVING,推荐此方式,执行效率更高
SELECT id,MAX(views)
FROM t_decade_blog
WHERE id IN ('76782763-48d0-4cef-b8e1-1054e181e41d',
'd3258b79-d543-49bb-9850-16cac7565f57',
'd3258b79-d543-49bb-9850-16cac7566666')
GROUP BY id
HAVING MAX(views) > 4000;
# 方式二
SELECT id,MAX(views)
FROM t_decade_blog
GROUP BY id
HAVING MAX(views) > 4000
AND id IN ('76782763-48d0-4cef-b8e1-1054e181e41d',
'd3258b79-d543-49bb-9850-16cac7565f57',
'd3258b79-d543-49bb-9850-16cac7566666');
四、SQL底层执行原理
1、SELECT语句的完整结构
SQL92语法结构
SELECT 字段1,字段2,...(可能存在聚合函数)
FROM 表1,表2,...
WHERE 多表的连接条件 AND 不包含聚合函数的过滤条件
GROUP BY 分组字段1,分组字段2...
HAVING 包含聚合函数的过滤条件
ORDER BY 排序字段1,排序字段2...(ASC / DESC)
LIMIT 偏移量,条目数
SQL99语法结构
SELECT 字段1,字段2,...(可能存在聚合函数)
FROM 表1 (LEFT / RIGHT) JOIN 表2 ON 多表的连接条件
(LEFT / RIGHT) JOIN 表2 ON 多表的连接条件2...
WHERE 不包含聚合函数的过滤条件
GROUP BY 分组字段1,分组字段2...
HAVING 包含聚合函数的过滤条件
ORDER BY 排序字段1,排序字段2...(ASC / DESC)
LIMIT 偏移量,条目数
2、SQL语句的执行过程
我们就以SQL99语法结构为例进行分析
- 首先执行
FROM至HAVING范围内的语句- 先根据
FROM找出所需要的表,这里相当于之前说过的CROSS JOIN—>然后根据ON后面的连接条件去除无法被关联的数据—>判断是否是左/右外连接(LEFT / RIGHT JOIN)—>根据WHERE过滤数据—>根据GROUP BY分组(这一步之后,针对每组的聚合函数进行过滤才有了意义,这就能说得通为什么WHERE中不能使用聚合函数)—>根据HAVING进行分组
- 先根据
- 然后执行
SELECT:执行完第一步会查出所有字段,这一步筛选出我们需要哪些字段,如果有DISTINCT关键字,那么还会进行去重 - 最后执行
ORDER BY和LIMIT:对上一步得到的结果集进行排序,然后再进行分页
如有错误,欢迎指正!!!















 2171
2171











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









