







数据编辑与格式化
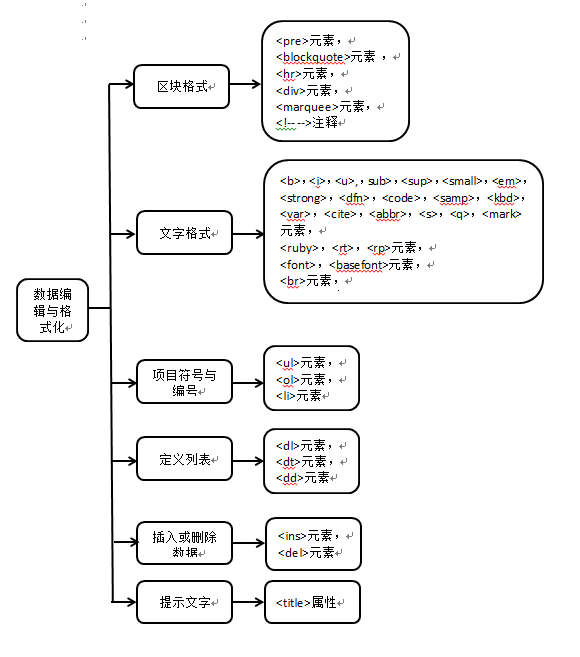
1.区块格式
1.1<pre>元素(预先格式化的区块)
适合在页面显示整块代码等内容。
<body>
<pre>
void main()
{
printf("Hello World!\n");
}
</pre>
</body>1.2<blockquote>元素(左右缩排的区块)
<body>
<blockquote>天命之谓性,率性之谓道,修道之谓教。</blockquote>
<blockquote>道也者,不可须臾离也﹔可离,非道也。</blockquote>
<p>是故,君子戒慎乎其所不赌,恐惧乎其所不闻。</p>
<p>莫见乎隐,莫显乎微,故君子慎其独也。</p>
</body>1.3<hr>元素(水平线)
<body>
<hr color="green" align="left" width="50%" size="8">
<hr color="red" align="left" width="50%" size="15">
<hr color="gray" align="right" width="300px" size="10">
</body>1.4<div>元素(群组成一个区块)
(1)<div>元素用来将HTML中某个范围内的内容和元素组成一个区块,令文件的结构更清晰,其属性如下所列。
(2)所谓区块级(block level)指的是元素的内容在浏览器中会另起一行,例如<div>,<p>,<pre>,<h1>等均属于区块等级的元素。
(3)通常会搭配class,id,style等属性。
<body>
<div>
<h1>快乐出版社</h1>
<ul>
<li><a href="products.html">产品部</a></li>
<li><a href="sales.html">业务部</a></li>
</ul>
</div>
</body>1.5<marquee>元素(跑马灯)
<body>
<p><marquee bgcolor="yellow" width="500" height="20">鹿港灯会热闹登场</marquee></p>
<p><marquee bgcolor="pink" width="80%" height="2%" behavior="alternate"
scrollamount="5" scrolldelay="100" >欢迎你我斗阵来参加~~~</marquee></p>
</body>1.6<!– –>元素(注释)
2.文字格式
2.1<ruby>,<rt>,<rp>元素(注音或拼音)
(1)<ruby>:用来包住字符串及其注音或拼音。
(2)<rt>:用来包住拼音部分。
(3)<rp>:当<ruby>不能被浏览器支持时,显示<rp>中的内容。
<body>
<h1><ruby>汉<rt>ㄏㄢˋ</rt>字<rt>ㄗˋ</rt></ruby></h1>
<h1><ruby>汉<rt>かん</rt>字<rt>じ</rt></ruby><br></h1>
<h1><ruby>汉<rp>(</rp><rt>ㄏㄢˋ</rt><rp>)</rp>字<rp>(</rp><rt>ㄗˋ</rt><rp>)</rp></ruby></h1>
<h1><ruby>汉<rp>(</rp><rt>かん</rt><rp>)</rp>字<rp>(</rp><rt>じ</rt><rp>)</rp></ruby></h1>
</body>2.2<font>,<basefont>元素(字体)
<body>
<p>听风在唱</p>
<p><font size="1" color="green" face="微软正黑体">听风在唱</font></p>
<p><font size="2" color="purple" face="微软正黑体">听风在唱</font></p>
<p><font size="3" color="red" face="标楷体">听风在唱</font></p>
<p><font size="4" color="navy" face="标楷体">听风在唱</font></p>
<p><font size="5" color="teal" face="新细明体">听风在唱</font></p>
<p><font size="6" color="blue" face="新细明体">听风在唱</font></p>
<p><font size="7" color="olive" face="华康粗圆体">听风在唱</font></p>
</body>2.3<br>元素(换行)
2.4<span>元素(群组成一行)
所谓行内层级(inline level )指的是元素的内容在浏览器中不会另起一行,例如<span>,<i>,<b>,<img>,<a>等均属于行内层级的元素。
<body>
注释1:<span class="note">“章台路”</span>意指歌妓聚居之所。<br>
注释2:<span class="note">“冶游生春露”</span>意指春游。
</body>3.项目符号与编号
<ul>元素为数据加上项目符号,<ol>元素为资料加上编号,然后再使用<li>元素指定各个的项目资料。
3.1<ul>元素
<body>
<ul type="square">
<li>射雕英雄传</li>
<li>神雕侠侣</li>
<li>倚天屠龙记</li>
<li>碧血剑</li>
</ul>
</body>3.2<ol>元素
<body>
<ol type="A" start="1">
<li>半生缘</li>
<li>倾城之恋</li>
<li>小团圆</li>
<li>流言</li>
<li>秧歌</li>
</ol>
</body>4.定义列表
定义列表(definition list) 指的是将数据格式化成两个层次,可以将它想象成类似目录的东西,第一层资料是某个名词,而第二层资料是该名字的解释。
<body>
<dl>
<dt>黑面琵鹭</dt>
<dd>黑黑面琵鹭最早的栖息地是韩国及中国的北方沿海,但近年来它们觅着了
一个新的栖息地,那就是宝岛台湾的曾文溪口沼泽地。</dd>
<dt>赤腹鹰</dt>
<dd>赤腹鹰的栖息地在垦丁、恒春一带,只要一到每年的八、九月,赤腹鹰
就会成群结队的到台湾过冬,爱鹰的人士可千万不能错过。</dd>
</dl>
</body>5.插入或删除数据——<ins>,<del>元素
<body>
天数剩下<del datetime="2012-02-14t00:00:00">2</del>
<ins datetime="2012-02-14t00:00:00">1</ins>天
</body>6.提示文字——<title>属性
<p>,<body>,<div>,<span>,<ul>,<ol>等有title属性的元素均能指定提示文字。
<body>
<p title=" 大学 经一章 大学之道">
大学之道在明明德,在亲民,在止于至善。
知止而后有定,定而后能静,静而后能安,
安而后能虑,虑而后能得,物有本末,事有终始,
知所先后,则近道也。</p>
</body>














 673
673











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









