







1、概述
Hudi(Hadoop Update Delete Incremental)官方介绍是为数据湖之上提供事务支持、行级别更新/删除(Row Level Update/deletes)和变更流(Change Stream)的一个数据湖框架,最早是由Uber开发于2016年,2017进入开源社区,并在2020年成为Apache 顶级项目。本文会从Hudi诞生背景条件出发,搞清楚Hudi最初是为了解决什么问题而出现的。
2、近实时场景需求
随着大数据技术的发展,逐渐发展出了两种比较成熟的计算模型:
一种是批处理模型,技术栈以Hadoop为代表,其特点是规模大,容错高,延迟高,主要应用在离线的大规模分析场景下;另一种是流处理模型,技术栈以Strom/Flink此类流处理框架为代表,其特点是延迟非常低,主要应用在要求延迟很低的实时场景下。这两种模型覆盖了绝大多数大数据的应用场景。
但是在流处理与批处理之间却存在一个模糊的边缘地带,即延迟在5分钟~1小时的范围,在这个范围内,既可以用批处理技术也可以用流处理技术,称为近实时(Near Real-time)需求。比如过去若干分钟某些维度指标的变化统计。
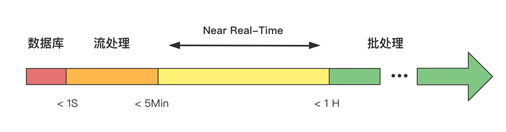
此类场景有有以下3个特点:
1、对延迟度要求在亚小时级别。
2、数据来源于业务数据的统计分析(可能存在多表join)。
3、数据在业务窗口期内会变化。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









