







从一个程序异常说起
最近的一个项目走到线下测试阶段,同事写了一堆测试数据进Kafka,我的代码负责通过KafkaSpout消费消息。结果出现一个很怪异的事情,对方每20秒写10000条消息进Kafka,我的Spout却读到了这样的消息:
- 20秒统计一次进入Spout的消息数量,第一个20秒正常,有10000条整。(因为写入速度够快,20秒足够完成写入和读取工作)
- 第二个20秒也正常,10000条消息整。
- 第三个20秒就开始异常了,数据量在20000~30000之间。
- 越往后数据量越来越多。
经过一顿排查终于发现问题出在Bolt没有ack()应答上级Spout,导致Spout重发消息。
BaseRichBolt,BaseBasicBolt,BaseBatchBolt,BaseTransactionalBolt的差别
但是隐隐然记得当初在某个地方还看过介绍说某个Bolt是不需要用户手动ack的,但是这里却因为没有现实调用ack而出错,看来是Storm提供的多个Bolt实现在这方面是有不同点的。借这个机会,就来看看这些Bolt之间的异同点。
先来看看这几个Bolt的继承关系:
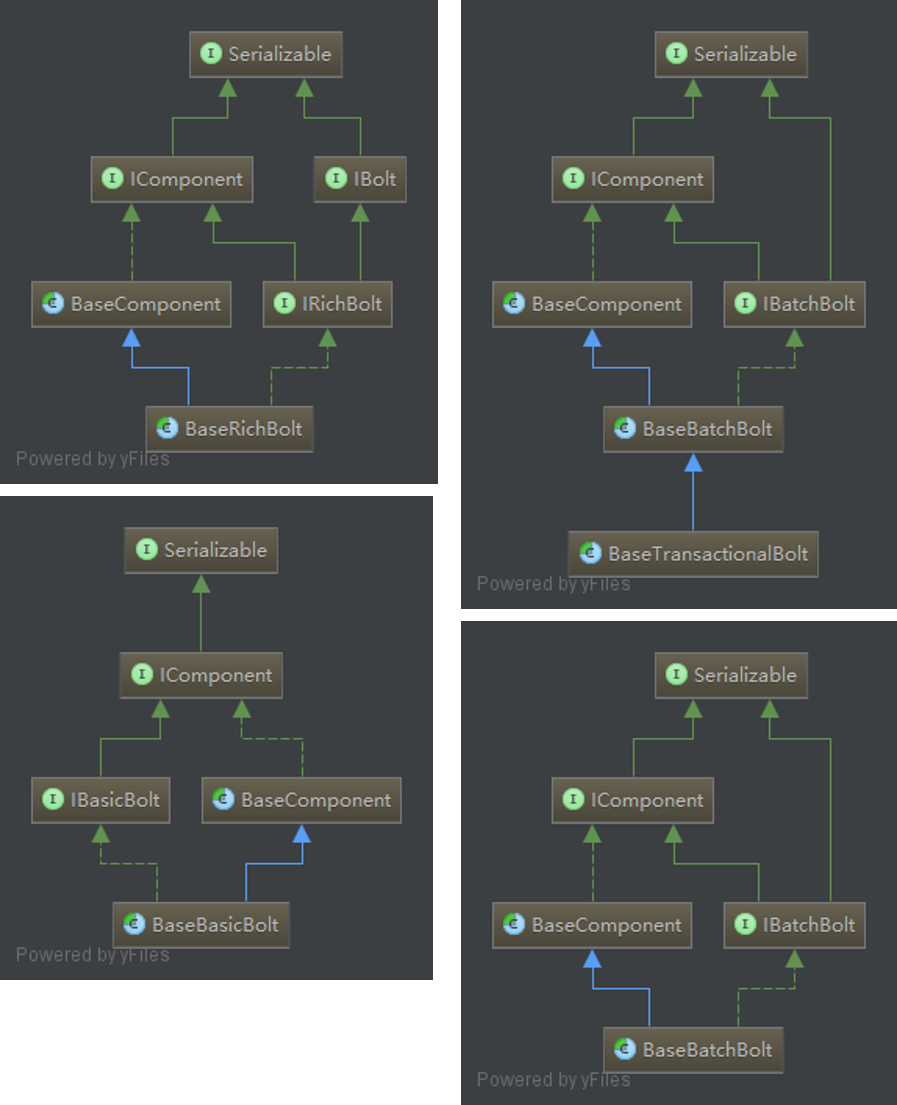
首先可见BaseTransactionalBolt其实是继承自BaseBatchBolt的一个拓展,有更本质区别的应该是初前者之外剩下的三个类。他们都继承自BaseComponent,并分别实现了IRichBolt、IBasicBolt和IBatchBolt接口。
IComponent
BaseRichBolt,BaseBasicBolt,BaseBatchBolt三个抽象类直接继承的BaseComponent其实并没有做什么事情。
# BaseComponent.java
package backtype.storm.topology.base;
import backtype.storm.topology.IComponent;
import java.util.Map;
public abstract class BaseComponent implements IComponent {
@Override
public Map<String, Object> getComponentConfiguration() {
return null;
}
}而它所实现的IComponent核心则定义了两个方法,一个是上面被BaseComponent实现了的getComponentConfiguration(),负责返回Component的配置参数。一个是需要实现类自己定义的declareOutputFields()。方法中声明了该bolt/spout输出的字段个数,供下游使用,在该bolt中的execute方法中,emit发射的字段个数必须和声明的相同,否则报错:
Tuple created with wrong number of fields. Expected 2 fields but got 1 fields。 当我们使用fieldsGrouping(id,fields)方法来做tuple分发时,Fields的定义也要根绝这里的fields声明来,否则会报错:
“Topology submission exception. (topology name='HelloStorm')
<InvalidTopologyException InvalidTopologyException(msg:Component: [3] subscribes from
stream: [default] of component [2] with non-existent fields: #{"ahah1"})>”BaseComponent的定义很清晰简单,但是几个Bolt的差别却主要体现在他们实现的IxxxBolt接口。
IBasicBolt vs IRichBolt
三个Bolt刚好实现了三个不同的IxxxBolt,而其中的IBasicBolt和IRichBolt都在backtype.storm.topology包内,可见他们两个还是比较相像的。
两者都有三个抽象方法:
/**
* 在Bolt启动前执行,提供Bolt启动环境配置的入口
*/
void prepare();
/**
* 每次调用处理一个输入的tuple,当然,也可以把tuple暂存起来批量处理。
* 但是!!!千万注意,所有的tuple都必须在一定时间内应答,可以是ack或者fail。否则,spout就会重发tuple。这也正是上文描述的意外事件的根本原因。
* 两个bolt不同的地方在于,`IBasicBolt`自动帮你ack,而`IRichBolt`需要你自己来做。
*/
void exexute();
/**
* 当组件关闭时被调用,但是当supervisor使用`kill -9`强制关闭worker进程时,不能保证这个方法一定会被执行。
*/
void cleanup();Spout重发策略的配置
现在我们知道了默认情况下,Spout如果在一定时间内没有发出去的tuple对应的ack,就会触发fail。那么这一套策略是怎么实现的呢?我们又可以做什么配置呢?
且先看看用来发射tuple的SpoutOutputCollector,他的类图很简单:
主要提供了以下几个方法:
public List<Integer> emit(String streamId, List<Object> tuple, Object messageId)
public List<Integer> emit(List<Object> tuple, Object messageId)
public List<Integer> emit(List<Object> tuple)
public List<Integer> emit(String streamId, List<Object> tuple)
public void emitDirect(int taskId, String streamId, List<Object> tuple, Object messageId)
public void emitDirect(int taskId, List<Object> tuple, Object messageId)
public void emitDirect(int taskId, String streamId, List<Object> tuple)
public void emitDirect(int taskId, List<Object> tuple)
public void reportError(Throwable error) 我们发送消息用的emit()在这里提供了四种不同的实现方式,但是要注意的是,只有提供了messageId参数,Storm才会追踪这条消息是否发送成功。而当我们一路追踪KafkaSpout的tuple发射机制,会发现它的底层使用的是:
collector.emit(tup, new KafkaMessageId(_partition, toEmit.offset));即它用了自己自定义的一个对象(KafkaMessageId有两个字段,一个是partition一个是offset,可以定位消息以便重发)来作为MessageId。
来到这里,很自然的就会产生几个疑问,每条消息的过期时间怎么定呢?消息过期是不是全部都会被重发呢?重发后如果还不成功怎么办?这是另一个话题了,这里且不谈,只对涉及到的几个参数做一下交代:
topology.max.spout.pending /*在一个spout task消息发送队列中最多可保存的未ack或者fail的数量,默认为null。如果超过这个值,storm便选择不再发送新数据,知道有消息ack或者fail,腾出队列空间为止。*/
topology.message.timeout.secs /*消息过期时间,通过public void backtype.storm.Config.setMessageTimeoutSecs(int secs)设置。超时之后storm会调用fail()方法,可以自定义重发或者别的动作。*/















 761
761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









