







环境:
Windows 7
Hadoop2.5.2
JDK1.7
工具:
Eclipse
Hadoop程序在Linux下运行会显得非常正常,但国内的很多Hadoop程序的开发,尤其是学生的大多都是在Windows上做开发,如果再将其打包提交到集群运行也显得稍微有些麻烦,如果在Eclipse上做完开发,直接进行程序的运行测试倒是显得方便了很多,上一篇文章讲了如何在Windows下做Hadoop的本地开发,并没有将程序提交到集群,这并不能达到很好利用集群来做运行测试,但对于本地调试还是很有好处的,这篇文章是讲述如何在Eclipse中开发完成Hadoop程序之后,直接像运行Java或者JavaWeb一样来运行Hadoop程序,本文中以经典的WordCount为例。
1.当然你需要有一个集群,将集群的节点相关信息写入到windows下的hosts文件中,这样做是为了方便访问Hadoop集群,形式如下:
192.168.x.x master
192.168.x.x salve1
... ...
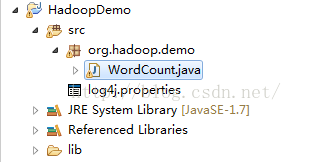
2.将下载的Hadoop文件中的WordCount实例解压放到Eclipse中新建的Java项目中去,如下图所示:
3.对已经放置好的WordCount程序进行改造,因为所给的原有的WordCount程序肯定是不能直接提交到远程的集群中去的。添加如下一些配置信息:

这里设置的是手动配置的一些Hadoop集群的参数,在相应的集群中的$HADOOP_HOME/etc/hadoop的配置文件中也要进行相应一些参数的配置。其中的master在就是1中的配置,如果没有配置就需要直接写主节点的IP地址了。
4.将该改造完成的WordCount程序打成jar包,然后给打成的jar包命一个自己喜欢的名字。
5.在Eclipse中右键单击Run As-->Run Configuration,对Arguments进行输入输出路径的配置,如下图:
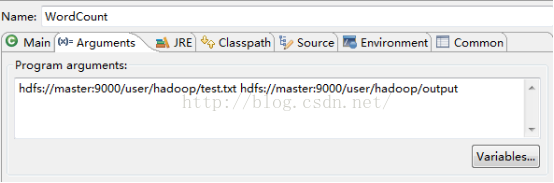
其中的test.txt是已经在Hadoop集群中上传的一个有几句英语句子的文件,需要你自己手动上传到hdfs上。
6.运行时可能会出现以下异常,但仍旧能够保证mapreduce的运行

之所以会出现这个异常是因为在WordCount中有这么一条语句:
String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
在调用这个语句的时候,如果是Windows环境它就会去在你的环境中寻找winutils.exe这个文件,当然你完全可以在Windows系统里面解压一个Hadoop文件之后再在它的bin目录下放置这个文件,这个方法类似我上篇文章讲述的在windows系统本地运行WordCount程序,但是想想办法肯定是可以跳过去的,但目前我还没有想
更好的方式(~__ ~)















 1679
1679

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









