






假设现在存在一个csv文件,姑且叫做“成绩单.csv”吧,里面的内容大致如下:
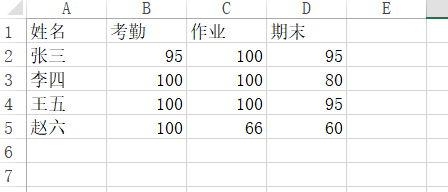
那么现在尝试在最后添加一列叫做‘最终成绩’,且最终成绩的计算准则为:将考勤、作业、期末三项分别以权重0.22, 0.18, 0.6 来计算并相加,且保存到该csv文件中,那么应该怎么做?
对于这个问题,尝试使用python内置的csv以及安装好的numpy模块来操作,首先引用相应模块:
import csv, numpy as np
随后尝试使用open函数对文件进行读取(下列代码预先假设文件存放在D盘根目录):
with open("D:\\成绩单.csv", 'r') as f:
reader = csv.reader(f)
rows = [row for row in reader]
这样,csv中的每一行便以列表内元素的形式存到rows中去了,且rows[0]为标头。
因为本身csv模块并不能支持单独增加一列,所以这个地方“暴力”了一点,直接把csv源文件用覆盖的方式打开(读写操作选择了‘w’,就意味着在打开的一瞬间,该文件内容就被清空了,这个地方务必要慎重!):
# newline 参数给空字符是为了防止写入时写一行空一行
with open("D:\\成绩单.csv", 'w', newline='') as f:
writer = csv.writer(f)
然后,先给标头后面添加‘最终成绩’:
rows[0] += ['最终成绩']
writer.writerow(rows[0])
再依次按照权重计算出相应的成绩。
weights = [0.22, 0.18, 0.6]
for i in rows[1:]:
# 将每个元素从字符串转换为整数,用于计算
s = []
for j in i[1:]:
s.append(int(j))
i += ['%.2f' % np.average(s, weights = weights)]
writer.writerow(i)
也可以写的再简单点:
weights = [0.22, 0.18, 0.6]
for i in rows[1:]:
i += ['%.2f' % np.average(list(map(int, i[1:])), weights=weights)]
writer.writerow(i)
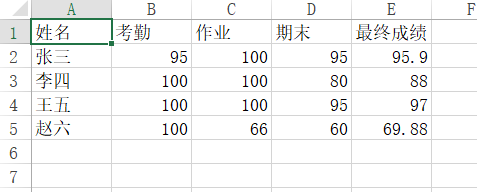
这样,文件结果如下:
完整代码如下:
import csv, numpy as np
# 先读
with open("D:\\成绩单.csv", 'r') as f:
reader = csv.reader(f)
rows = [row for row in reader]
# 再写
with open("D:\\成绩单.csv", 'w', newline='') as f:
writer = csv.writer(f)
rows[0] += ['最终成绩']
writer.writerow(rows[0])
weights = [0.22, 0.18, 0.6]
for i in rows[1:]:
i += ['%.2f' % np.average(list(map(int, i[1:])), weights=weights)]
writer.writerow(i)
小坑: 记得写入时给newline赋值空字符,避免写入时空行的问题,什么是空行?newline去掉试试就知道咯,坑的我不行不行的。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









