







一、List与String一些常用的方法
1、List与String的相互转换
/**
* list 转 string 逗号拼接
*/
public static String listToString(List<String> list) {
if (list == null) {
return null;
}
return String.join(",", list);
}
/**
* string 转 list
*/
public static List<String> stringToList(String strs) {
return Arrays.asList(strs.split(","));
}
注意,这里list转string,不能用toString(),因为toString得到的是一个数组、格式与要求的不一样,如下图

2、对List元素进行去重的几种方法
1)遍历判断去重,或者迭代去重,代码不好看、而且很麻烦,这里就不说了。
2)用stream流去重,代码简洁,元素顺序与原先一致
List<T> resultList = targetList.stream().distinct().collect(Collectors.toList())
3)用set去重
a、LinkedHashSet去重(有序)
LinkedHashSet<T> set = new LinkedHashSet<>(targetList);
b、HashSet去重(无序)
HashSet<T> set = new HashSet<>(targetList);
3、lambda表达式+stream流 操作List
1)过滤对象list,得到一个普通类型(字符串、long、int)的list
List<JcWecomTag> importList = 。。。
List<Long> ids = importList.stream()
.map(JcWecomTag::getId)
.collect(Collectors.toList());
2)去除为null的值
List<Long> ids = importList.stream()
.map(JcWecomTag::getId)
.filter(Objects::nonNull)
.collect(Collectors.toList());
3)去重
List<Long> ids = importList.stream()
.map(JcWecomTag::getId)
.distinct()
.filter(Objects::nonNull)
.collect(Collectors.toList());
4、List分组
// 分批执行,防止更新超1000
for (int index = 0; index <= userIds.size()/50; index++) {
int fromIndex = 50 * index;
int toIndex = 50 * (index + 1);
if (toIndex > userIds.size()) {
toIndex = userIds.size();
}
//拆分
List<String> batchList = userIds.subList(fromIndex, toIndex);
//分批执行
。。。
}
二、json字符串与类对象的相互转换
1、json字符串转成类对象
JSONObject用的是fastjson包下的
String ddstr = "{\"dicCategoryCode\":\"SEX\",\"dicCategoryId\":25,\"dicCode\":\"032307\",\"dicName\":\"测试032307\",\"status\":1}"
Dictionary dd = JSONObject.parseObject(ddstr, Dictionary.class);
2、Object对象、普通类对象转换成json字符串
这里的JSON和JSONObject指的都是fastjson包下的
//法一
String jsonStr = JSONObject.toJSONString(data);
//法二
String jsonStr = JSON.toJSONString(data);
三、Bigdecimal–运算+限定格式+取余判断
1、运算
1)初始化
初始化就是创建bigdecimal对象,无论是转换格式、还是做运算,都要先将目标数据初始化成bigdecimal对象。
a、数值是String类型,转换成bigdecimal
String unitSave = micMicrobeRecordTo.getUnitSave();
BigDecimal unitSavebd = new BigDecimal(unitSave);
b、数值直接是数字类型,转换成bigdecimal
BigDecimal num1 = new BigDecimal(0.005);
BigDecimal num2 = new BigDecimal(1000000);
BigDecimal num3 = new BigDecimal(-1000000);
c、bigdecimal提供了一些常用的常量,可以直接生成,比较方便、也不易出错,例如:
//值为0的bigdecimal
BigDecimal.ZERO
//值为1的bigdecimal
BigDecimal.ONE
//值为10的bigdecimal
BigDecimal.TEN
2)加减乘除方法
加法 add()
减法 subtract()
乘法 multiply()
除法 divide()
绝对值 abs()
a、对于加、减、乘方法没什么问题,对于除法要注意,如果不做设置、结果是无线小数的话,会报错,例如 1 / 3,直接用
new BigDecimal("1").devide(new BigDecimal("3"));
就会报错。
解决方法也很简单,其实divide()方法可以参数除了传除数,还可以再传两个参数,一个是结果保留位数,一个是舍入模式
BigDecimal sampleCountbd = sampleAmoutbd.divide(unitSavebd, 0, BigDecimal.ROUND_DOWN);
b、可以做混合运算,例如:
月度剩余总量=上个月月度剩余总量+月接收量-月运出量
resultMonthAmountbd = lastMonthAmoutbd.add(monthReceivebd).subtract(monthOutbd);
2、结果格式化
对于最后的结果,工作中往往有具体的要求,比如要求统一保留2位小数、多余小数位采取四舍五入,比如要求保留整数、不是整数的部分舍去;这些对数据结果格式的要求,bigdecimal处理起来都很方便和准确,实际上正是这个原因,涉及到数字运算,尤其是涉及钱、实验结果等,都要求后台用bigdecimal来处理数据。
数字的格式化,涉及到两个维度,一个是保留位数、一个是舍入方式
两者都可以用setScale()函数来完成设置。
BigDecimal lastSampleCountbd = lastSampleAmoutbd.divide(unitSavebd, 0, BigDecimal.ROUND_DOWN);
String lastSampleAmoutStr = lastSampleAmoutbd.setScale(2, BigDecimal.ROUND_HALF_DOWN).toString();
3、取余运算
1)两种取余运算方式+各自判断是否有余数的方法
//法一:
BigDecimal outdiv = monthOutbd.divide(unitSavebd, 2, BigDecimal.ROUND_DOWN);
if(new BigDecimal(outdiv.intValue()).compareTo(outdiv)!=0){//运出量必须为单位存储量的整数倍
Result result = Result.failure();
result.setInfo("月度运出量必须为单位存储量的整数倍,请正确填写");
return result;
}
//法二:
BigDecimal[] receiveArr = monthReceivebd.divideAndRemainder(unitSavebd);
if(receiveArr[1].compareTo(BigDecimal.ZERO)!=0){//运入量必须为单位存储量的整数倍
Result result = Result.failure();
result.setInfo("月度接收量必须为单位存储量的整数倍,请正确填写");
return result;
}
第一种方法就是正常的做除法,得到结果后用intValue()方法、取结果的整数部分,然后拿“结果的整数部分”和“结果”对比,如果是整数,两者是相等的,如果是小数则两者不相等,依此判断结果是否为整数。
第二种方法是使用divideAndRemainder()方法,该方法返回一个Bigdecimal类型的数组,数组中包含两个元素,第一个元素为两数相除的商,第二个元素为余数;这样的话通过判断余数是否为0,就可以判断结果是否为整数了。
2)八种舍入模式
a、ROUND_UP
非零就进一位
b、ROUND_DOWN
始终舍去
c、ROUND_CEILING
如果 BigDecimal 为正,则舍入行为与 ROUND_UP 相同;
如果为负,则舍入行为与 ROUND_DOWN 相同。
d、ROUND_FLOOR
如果 BigDecimal 为正,则舍入行为与 ROUND_DOWN 相同;
如果为负,则舍入行为与 ROUND_UP 相同。
e、ROUND_HALF_UP
四舍五入
f、ROUND_HALF_DOWN
五舍六入
g、ROUND_HALF_EVEN
在重复进行一系列计算时,此舍入模式可以将累加错误减到最小。
此舍入模式也称为“银行家舍入法”,主要在美国使用。四舍六入,五分两种情况。
如果前一位为奇数,则入位,否则舍去。
以下例子为保留小数点1位,那么这种舍入方式下的结果。
1.15>1.2 1.25>1.2
h、ROUND_UNNECESSARY
断言请求的操作具有精确的结果,因此不需要舍入。
如果对获得精确结果的操作指定此舍入模式,则抛出ArithmeticException。
四、常用实体类-类型介绍(POJO、Domain、DO、DTO、VO)
1、POJO
POJO 是 Plain Old Java Object 的简称,它指的是一个没有限制或要求下的纯平对象。POJO 用于表示没有任何框架或技术限制的纯数据对象。在 Java 开发中,POJO 通常用于简化复杂对象和降低对象的耦合度,是面向对象编程中 “高内聚、低耦合” 设计思想的体现。
2、Domain
Domain 是 Domain Object 的简称,即领域对象。它主要是用来表示一个领域或业务的对象,包含业务领域所需的属性和行为。Domain 对象更注重业务逻辑的封装,与数据存储相较而言更加抽离出来,以达到重用和可扩展性的目的。
3、DO
DO 是 Data Object 的缩写,即数据对象,它主要是用来映射关系型数据库的对象实体。DO 对象通常和数据库表一一对应,其属性名称和类型与表中的属性名称和类型对应。DO 通常使用 ORM 框架来实现数据的 CRUD 操作,例如Hibernate、MyBatis 等。
4、DTO
DTO 是 Data Transfer Object 的简称,即数据传输对象,用于传输数据。与 DO 和 Domain 对象相比,DTO 对象更注重数据传输的目的,通常只包含必要的属性,以便于在不同层之间传输数据。DTO 对象通常可以包含多个 Domain 对象的相关属性,因此也被称为组合对象。
5、VO
VO 是 View Object 的缩写,即视图对象,它用于显示数据或在前端展示。VO 对象是以“视图”为基础的对象,通常从 DTO 或 Domain 对象中抽取必要的属性来构建对象。在所有前端渲染中,VO 对象都是最常用的元素之一。
总结
1)pojo可以代表任何实体类,此类型下的实体类没有独特的特征;
2)domain对应业务(可以叫业务类),
比如系统对于用户有用户表、扩展信息表、角色表、组织表等,但是有时候需要一个类包含用户的所有信息,包括基本信息、扩展信息、角色信息、组织信息,这样的类对应业务,和表不一致,就应该放在domain下;
3)DO类与表一一对应;
4)DTO是接受、传输数据用户的,比较临时和简洁;
5)VO用户传给前端(方法返回),也是比较临时和简洁。
五、变量的基本数据类型与包装类型
1、基本数据类型与包装类型各自的适用范围
2、拆箱与装箱
3、生产中遇到的相关问题
1)现象:
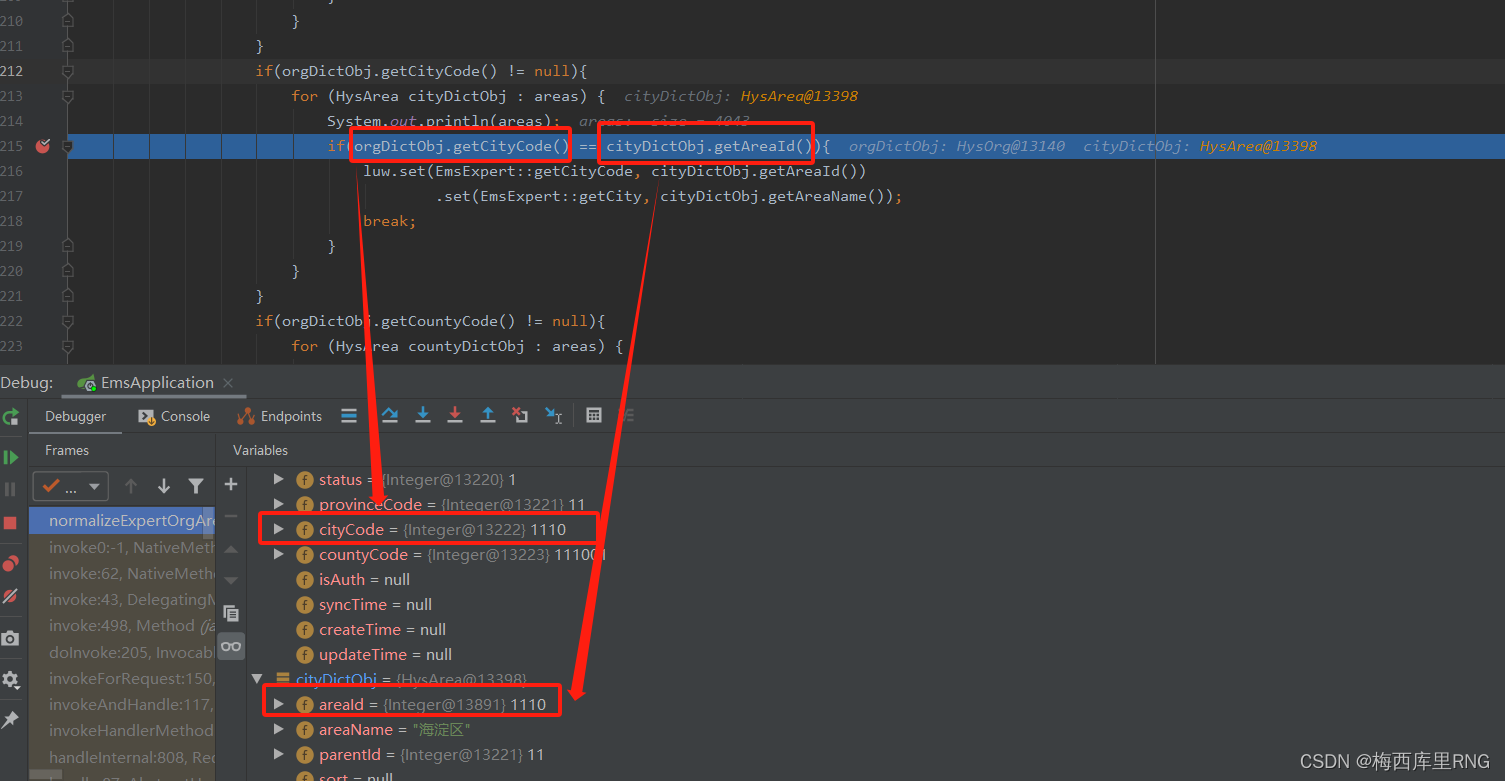
在比较两个地区的编码时(编码为Integer类型),出现编码相等、但是比较结果是“不相等”的“奇怪”情况,如图一;
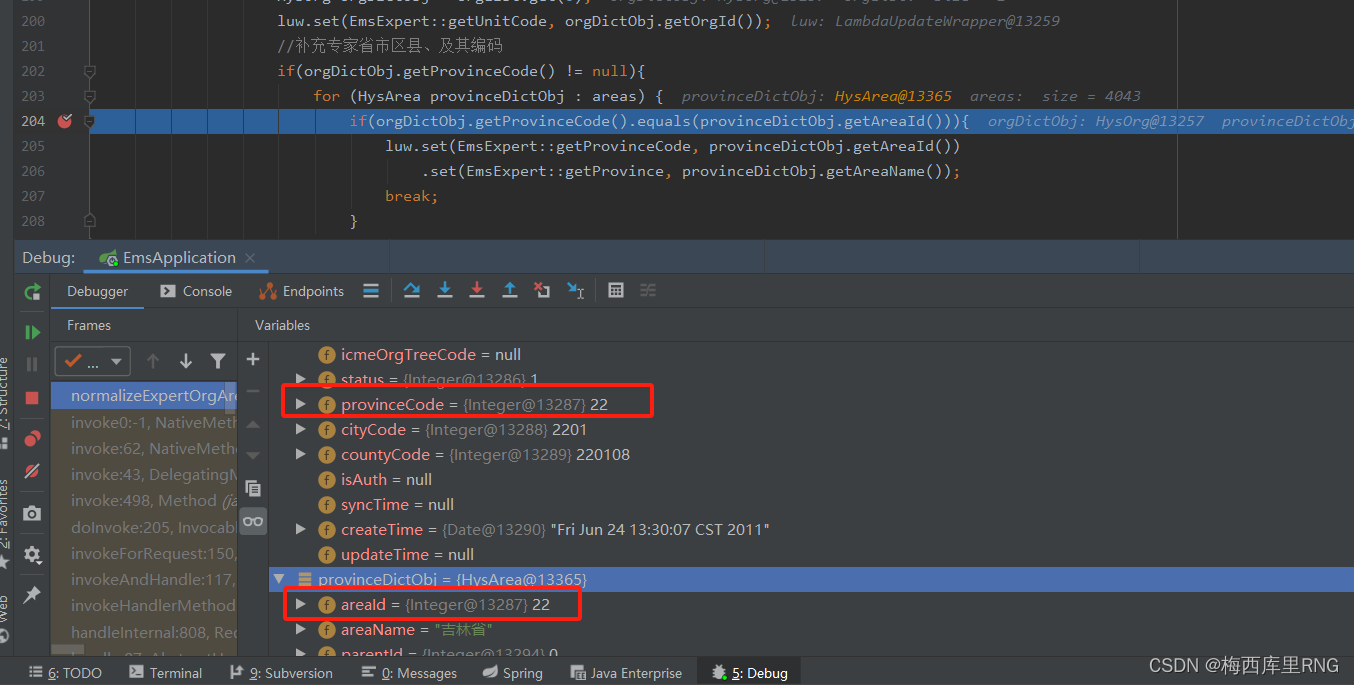
但是,在代码不变的前提下,有些时候它又是可以正常比较大小,如图二
2)原因:
Java认为-128~127之间的整数使用最频繁,这个范围内的整数装箱后,存储在共享池中,采用“享元模式”;
就是Integer类型变量,实际和String等对象变量一样,变量存的是内存地址,理论上是不能通过“”作等值比较的,应该用equals判断是否相等;
但是呢,对于-128~127之间的数值,都是存在共享池中,如果有两个变量x和y,它们都是22,那么x和y的内存地址是相同的 -> 都指向共享池中的22;这时,你用“”对两者进行是否相等的判断,它就歪打正着的可以判断,正如我遇到的图2那种情况。
而图1,则是因为市、县一级的编码都大于1000(即不在-128~127之间),所以它不采用享元模式存储,就是正常的对象变量,即使两个Integer都是1110的装箱,但它们放在两个内存空间,变量中存的地址是不一样的,不能用“==”判断是否相等,而是得用equls判断。
同理,比较Integer类型的大小,也优先用a.compareTo(b)>0这样。
六、时间数据的处理
1、Date
Date 类表示系统特定的时间戳,可以精确到毫秒。Date 对象表示时间的默认顺序是星期、月、日、小时、分、秒、年。
1) 构造方法
Date 类有如下两个构造方法。
a、Date()
此种形式表示分配 Date 对象并初始化此对象,以表示分配它的时间(精确到毫秒),使用该构造方法创建的对象可以获取本地的当前时间。
b、Date(long date)
此种形式表示从 GMT 时间(格林尼治时间)1970 年 1 月 1 日 0 时 0 分 0 秒开始经过参数 date 指定的毫秒数(注意,毫秒数不是时间戳,时间戳是秒值)。
这两个构造方法的使用示例如下:
Date date1 = new Date(); // 调用无参数构造函数
System.out.println(date1.toString()); // 输出:Wed May 18 21:24:40 CST 2016
Date date2 = new Date(60000); // 调用含有一个long类型参数的构造函数
System.out.println(date2); // 输出:Thu Jan 0108:01:00 CST 1970
2) 常用方法
Date 类提供了许多与日期和事件相关的方法,其中常见的方法如下图所示:

2、Calendar
1)简介
Calendar 类为特定瞬间与 YEAR、MONTH、DAY_OF—MONTH、HOUR 等日历字段之间的转换提供了一些方法,并为操作日历字段(如获得下星期的日期) 提供了一些方法。
Calendar 类是一个抽象类,创建 Calendar 对象不能使用 new 关键字;Calendar 提供了一个 getInstance() 方法来获得 Calendar类的对象。getInstance() 方法返回一个 Calendar 对象,其日历字段已由当前日期和时间初始化。
Calendar c = Calendar.getInstance();
当创建了一个 Calendar 对象后,就可以通过 Calendar 对象中的一些方法来处理日期、时间。Calendar 类的常用方法如下图所示:

2)常用一
Calendar 对象可以调用 set() 方法将日历翻到任何一个时间,当参数 year 取负数时表示公元前。Calendar 对象调用 get() 方法可以获取有关年、月、日等时间信息,参数 field 的有效值由 Calendar 静态常量指定。
# Calendar 类中定义了许多常量,分别表示不同的意义。
Calendar.YEAR:年份。
Calendar.MONTH:月份。
Calendar.DATE:日期。
Calendar.DAY_OF_MONTH:日期,和上面的字段意义完全相同。
Calendar.HOUR:12小时制的小时。
Calendar.HOUR_OF_DAY:24 小时制的小时。
Calendar.MINUTE:分钟。
Calendar.SECOND:秒。
Calendar.DAY_OF_WEEK:星期几。
例如,要获取当前月份可用如下代码:
int month = Calendar.getInstance().get(Calendar.MONTH);
如果整型变量 month 的值是 0,表示当前日历是在 1 月份;如果值是 11,则表示当前日历在 12 月份。
3)常用二:使用 Calendar 类处理日期时间的实例
Calendar calendar = Calendar.getInstance(); // 如果不设置时间,则默认为当前时间
calendar.setTime(new Date()); // 将系统当前时间赋值给 Calendar 对象
System.out.println("现在时刻:" + calendar.getTime()); // 获取当前时间
int year = calendar.get(Calendar.YEAR); // 获取当前年份
System.out.println("现在是" + year + "年");
int month = calendar.get(Calendar.MONTH) + 1; // 获取当前月份(月份从 0 开始,所以加 1)
System.out.print(month + "月");
int day = calendar.get(Calendar.DATE); // 获取日
System.out.print(day + "日");
int week = calendar.get(Calendar.DAY_OF_WEEK) - 1; // 获取今天星期几(以星期日为第一天)
System.out.print("星期" + week);
int hour = calendar.get(Calendar.HOUR_OF_DAY); // 获取当前小时数(24 小时制)
System.out.print(hour + "时");
int minute = calendar.get(Calendar.MINUTE); // 获取当前分钟
System.out.print(minute + "分");
int second = calendar.get(Calendar.SECOND); // 获取当前秒数
System.out.print(second + "秒");
int millisecond = calendar.get(Calendar.MILLISECOND); // 获取毫秒数
System.out.print(millisecond + "毫秒");
int dayOfMonth = calendar.get(Calendar.DAY_OF_MONTH); // 获取今天是本月第几天
System.out.println("今天是本月的第 " + dayOfMonth + " 天");
int dayOfWeekInMonth = calendar.get(Calendar.DAY_OF_WEEK_IN_MONTH); // 获取今天是本月第几周
System.out.println("今天是本月第 " + dayOfWeekInMonth + " 周");
int many = calendar.get(Calendar.DAY_OF_YEAR); // 获取今天是今年第几天
System.out.println("今天是今年第 " + many + " 天");
Calendar c = Calendar.getInstance();
c.set(2012, 8, 8); // 设置年月日,时分秒将默认采用当前值
System.out.println("设置日期为 2012-8-8 后的时间:" + c.getTime()); // 输出时间
3、SimpleDateFormat
1)简介
4、格式转换
1)Date转化String
要用到SimpleDateFormat,可以指定格式
SimpleDateFormat sdf= new SimpleDateFormat("yyyy-MM-dd");
String dateStr=sdf.format(new Date());
2)String转Date,
String str="2010-5-27";
SimpleDateFormat sdf= new SimpleDateFormat("yyyy-MM-dd");
Date birthday = sdf.parse(str);
3)Date 转化Calendar
Calendar calendar = Calendar.getInstance();
calendar.setTime(new java.util.Date());
4)Calendar转化Date
Calendar calendar = Calendar.getInstance();
java.util.Date date =calendar.getTime();
5)Calendar 转化 String
要用到SimpleDateFormat,可以指定格式
Calendar calendat = Calendar.getInstance();
SimpleDateFormat sdf = new SimpleDateFormat("yyyy-MM-dd");
String dateStr = sdf.format(calendar.getTime());
6)String 转化Calendar
不能直接转换,需要先转成Date、再转Calendar
String str="2010-5-27";
SimpleDateFormat sdf= new SimpleDateFormat("yyyy-MM-dd");
Date date =sdf.parse(str);
Calendar calendar = Calendar.getInstance();
calendar.setTime(date);
5、前后端互传接时间的方式
1)使用时间戳(最建议)
这样做的好处:
首先,前端好处理。
后端来说,如果数据库存时间用的bigint,后端也不需要做任何处理,用Long接收参数就行;
如果数据库存时间用的timestamp或者datetime,那后端需要将接到的Long类型,转换成Date,但是也很简单。
唯一要注意的一点是,用的是时间戳、还是毫秒值不要混了,而且要一开始就说好、前后端要统一。强烈建议,都用时间戳,精确到秒够用了。
2)使用注解@JsonFormat(次建议)
a、应用背景
有时候可能那个环节轴住了,就是要用时间字符串比如“2023-08-23 15:50:34”这种格式。
咱们也不用和他们犟,说时间戳的好处有时别人也听不懂、或者不在意;其实后端哪种格式都能处理。
这里介绍一下@JsonFormat这个注解,可以方便的对Date和Json进行转换。
b、注解介绍
@JsonFormat注解由Jackson提供,Jackson 是一个由java编写的、专门用于处理json数据的开源工具包,spring默认使用Jackson 处理json数据。
@JsonFormat注解,可以将日期数据在JSON和java.util.Date对象之间进行转换,注解提供了两个属性

pattern用来设置日期格式,这个好理解;
timezone用来设置时区,我们是东八区,如果不设置用默认时区,与我们东八区差8个小时,比如前端传了一个12点,后端得到的就是20点。
c、前端传给后端
@JsonFormat注解,是将日期数据在JSON和java.util.Date对象之间进行转换,所以前端传参必须是json格式,@JsonFormat才会起作用。
如果单独@JsonFormat注解,前端传参只能放到body中、并以json格式传输,如下图
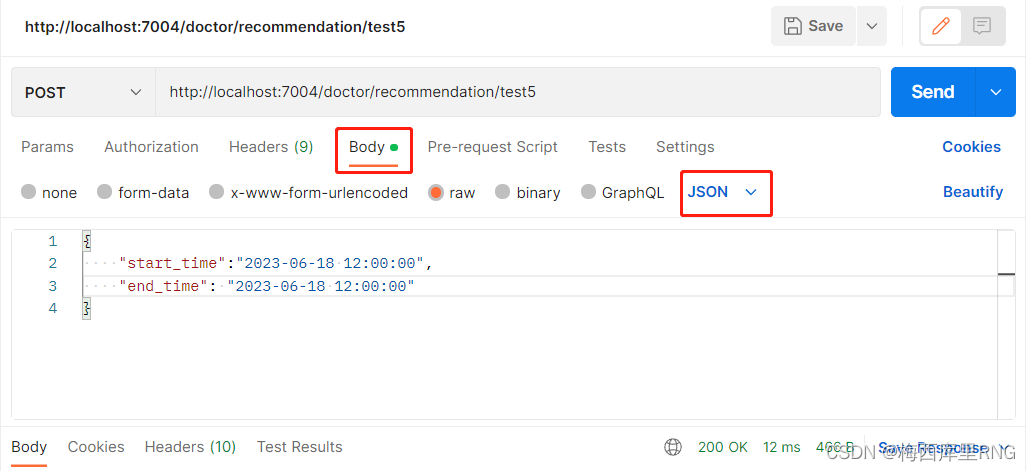
这时后端需要通过实体类接收(使用实体类,才能用@JsonFormat注解);又因参数放在请求体中,所以接口需要使用@RequestBody注解才能解析参数
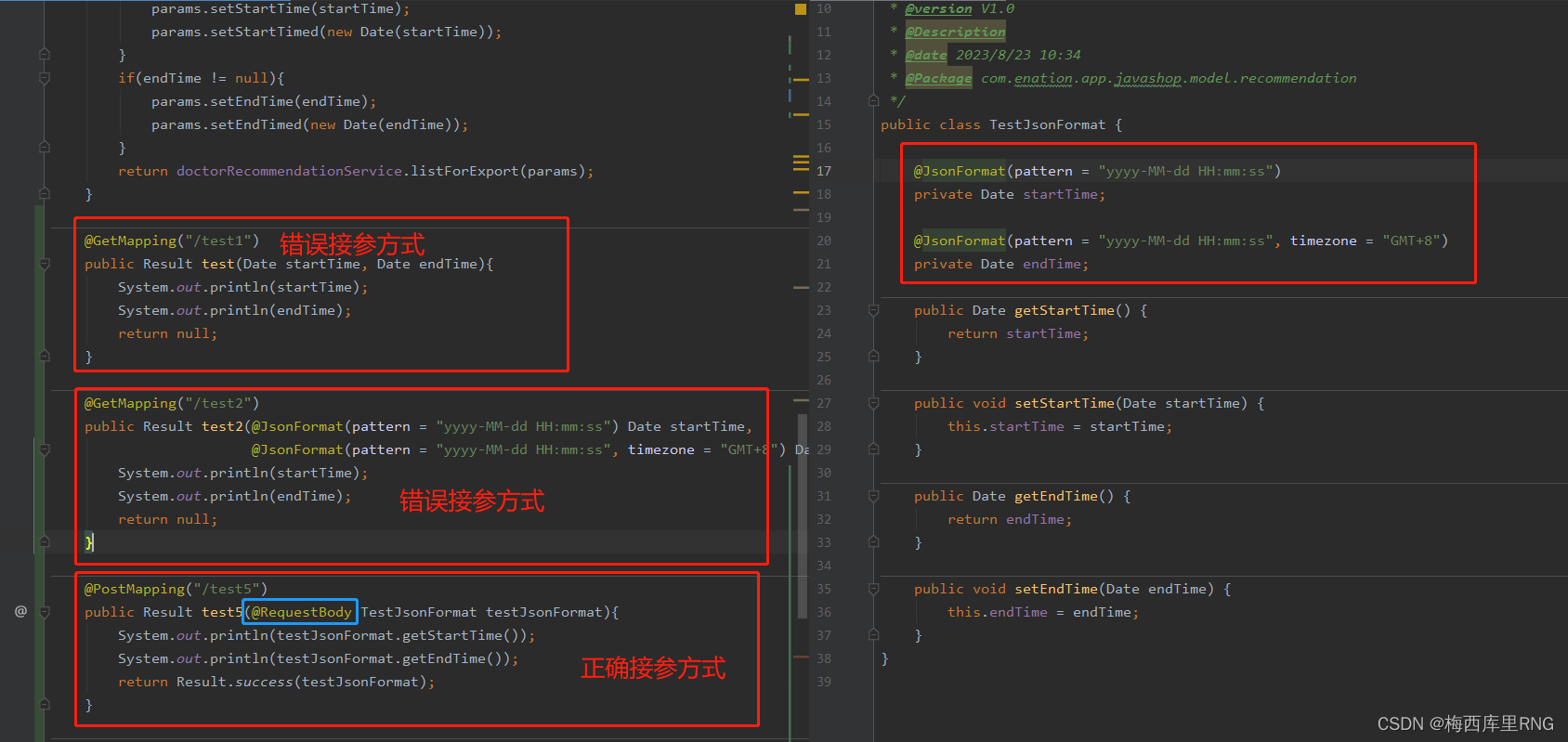
而且可以看到,没设置@JsonFormat的时区,会导致时间和前端传的入参对不上,退后了8小时
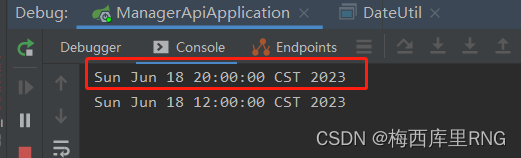
d、后端返回前端
因为@JsonFormat注解,是将日期数据在JSON和java.util.Date对象之间进行转换,所以后端返回前端的Date,也会被@JsonFormat转换成指定格式的json串。
也就是说,@JsonFormat注解还会对接口返回的时间进行格式规范
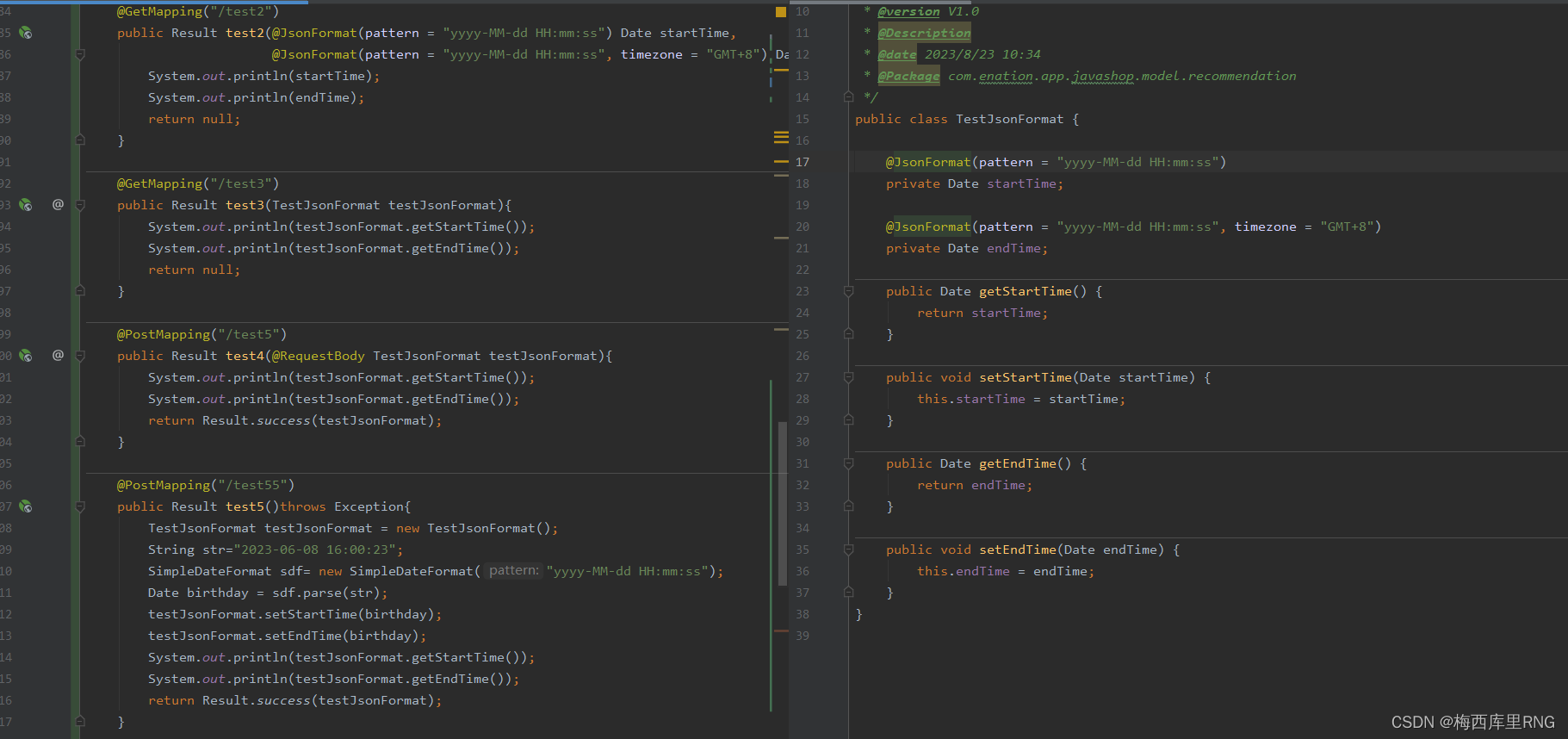
如上图test55接口,其调用结果如下图
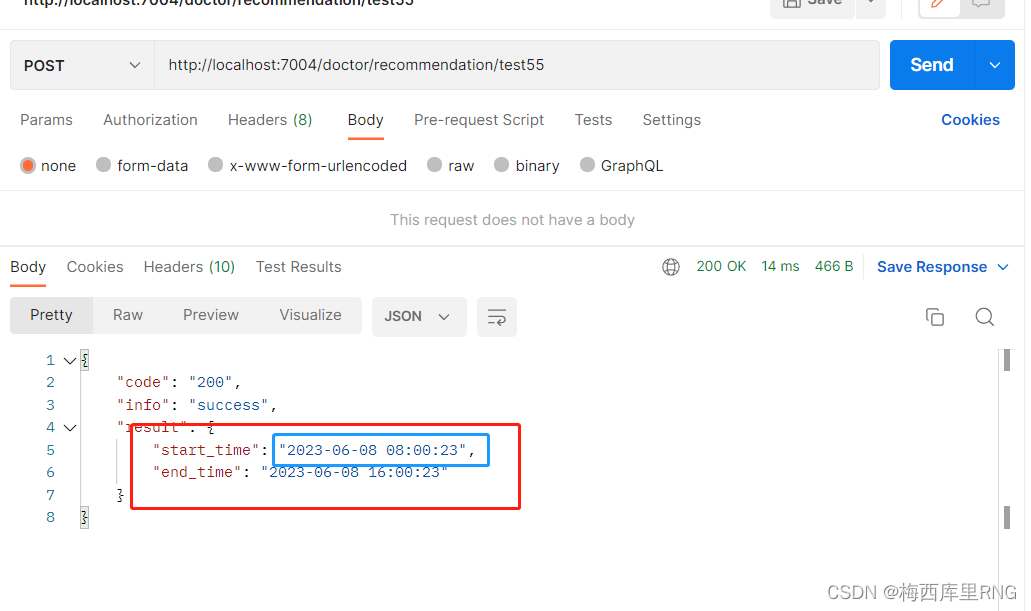
可以看到,Date类型返回值,被@JsonFormat注解按指定格式规范成json串了,和预期一样;
而且没有设置时区的start_time时间提前了8小时(所以使用@JsonFormat请设置时区)。
3)使用注解@DateTimeFormat(不建议)
a、注解介绍
@DateTimeFormat是spring框架的fomat工具包提供的注解;
注解有三个属性可设置,如下图:
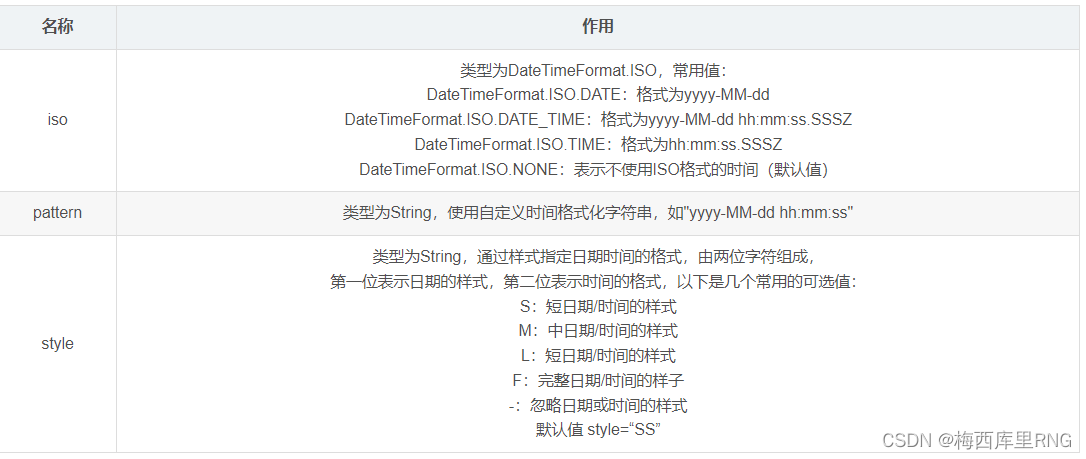
该注解的作用有两方面:
一是限制,对于前端传过来的参数,如果不符合patteren设置的格式,那么接口不能接收,会报格式转换错误。
二是转换,对于符合patteren格式的时间参数,@DateTimeFormat会将其转换成Date类型。
小结:@DateTimeFormat注解不用设置时区,
b、前端传给后端
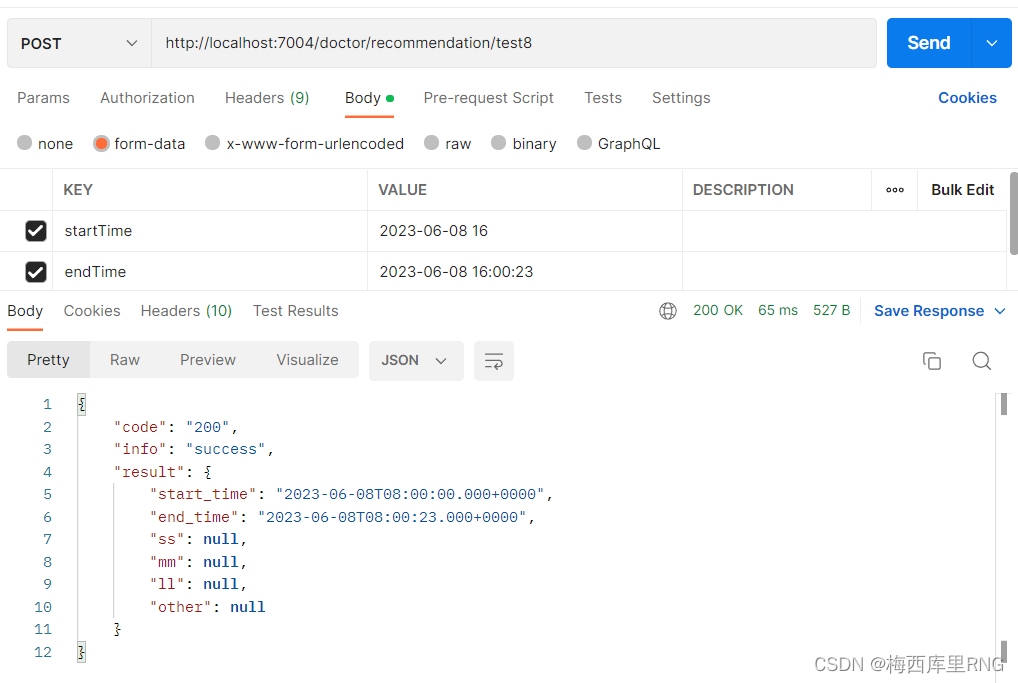
后端使用@DateTimeFormat注解接收时间数据时,前端可以通过form-data格式传输,如下图所示:
理论上,后端使用@DateTimeFormat注解接收时间数据,前端也可以通过json格式传参,如下图:
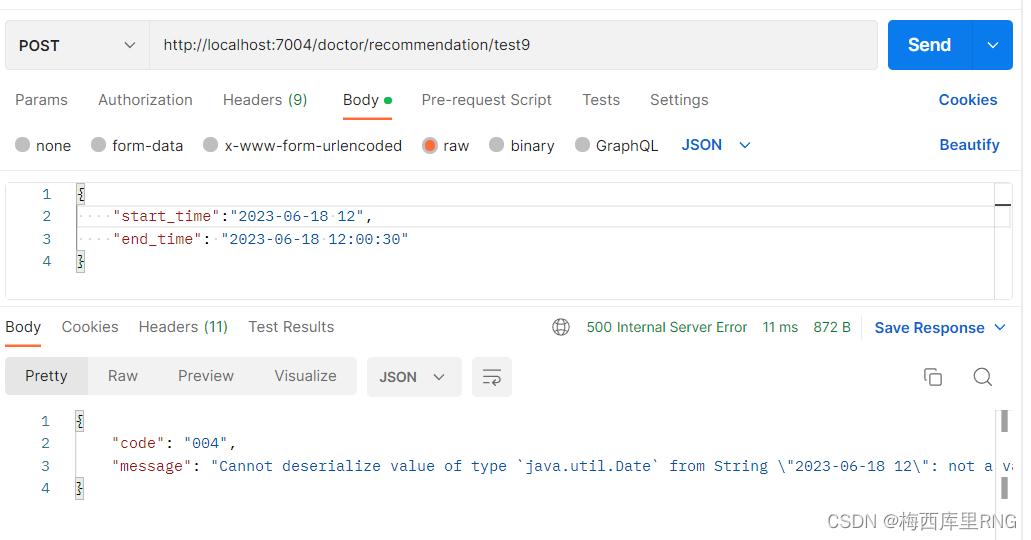
但是实际测试,这样不能接到参数,会报如下错误:
error: Failed to parse Date value '2023-06-18 12:00:30': Cannot parse date "2023-06-18 12:00:30": while it seems to fit format 'yyyy-MM-dd'T'HH:mm:ss.SSSZ'
意思是:你传的参数“格式不对”,所以转换Date时失败,正确的格式是“yyyy-MM-dd'T'HH:mm:ss.SSSZ”这样的。
但是从截图可以看到,我们设置的时间格式是这样的:
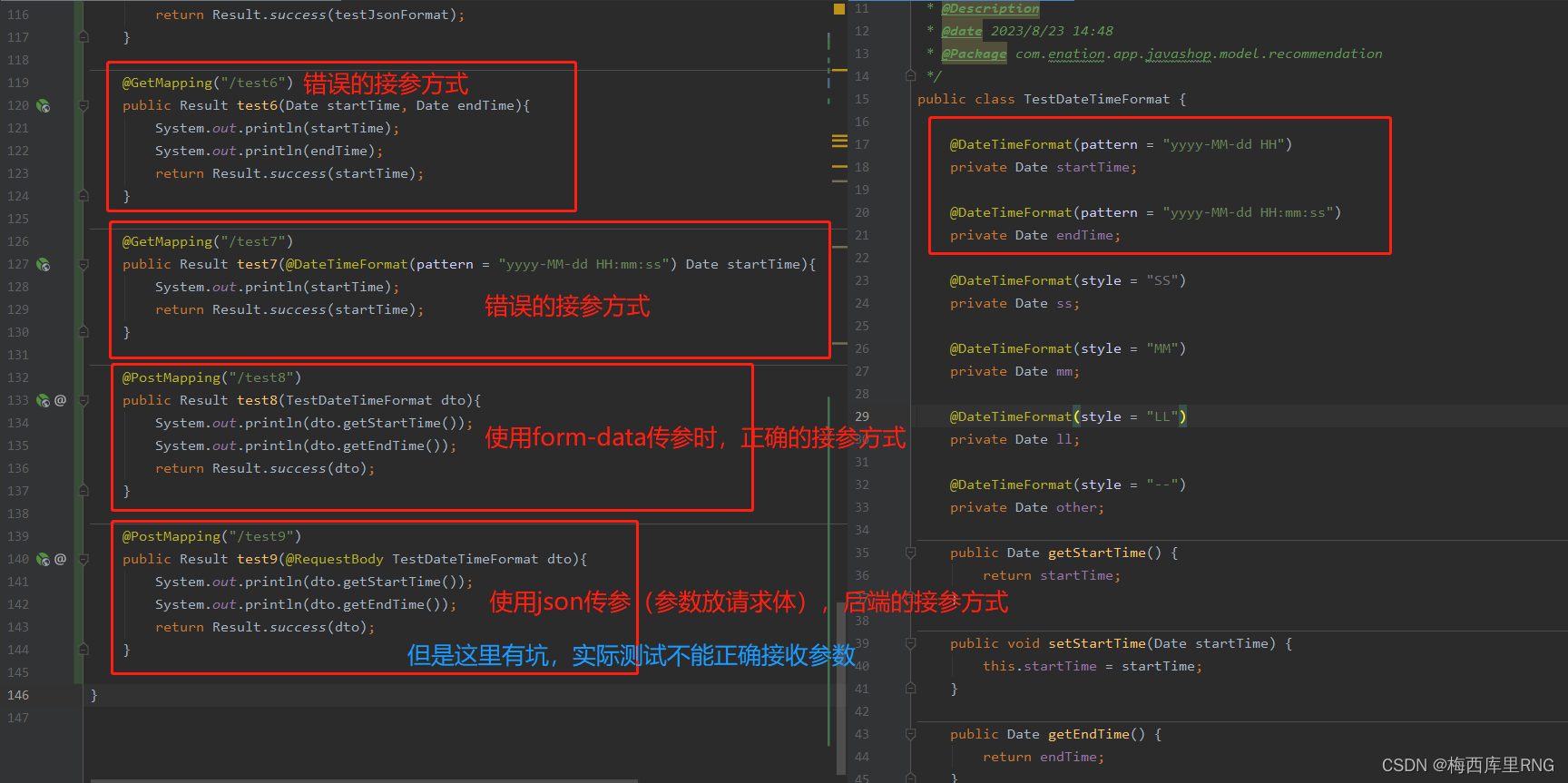
@DateTimeFormat(pattern = "yyyy-MM-dd HH")
private Date startTime;
@DateTimeFormat(pattern = "yyyy-MM-dd HH:mm:ss")
private Date endTime;
而且使用form-data类型传参时已经成功接收了,说明@DateTimeFormat属性设置是没问题的。
它错误提示那里,要求格式是yyyy-MM-dd'T'HH:mm:ss.SSSZ这样,只能说:看不懂、完全没道理!
小结
@DateTimeFormat注解,只能处理前端传给后端的时间参数,还对传输方式作了狭窄的限制,还不能处理后端传给前端的时间格式,还b问题一堆,建议不要单独用、很麻烦!
4)@JsonFormat与@DateTimeFormat对比
@JsonFormat 既可以约束前端传入的时间类型参数格式,也可以约束后端响应前端的时间类型格式;可以设置时区,设置好以后,前后端传输时间不会有误差。
@DateTimeFormat :
只能约束前端入参时间类型的格式,并不会修改原有的日期对象的格式,如果想要获得期望的日期格式,是需要自己手动转换的;
如果单独使用@DateTimeFormat 时,响应给前端的时间会比实际时间晚8个小时(时区原因,而且它不能设置时区)。
两个注解孰优孰劣大家应该自有判断。
a、@JsonFormat与@DateTimeFormat合用
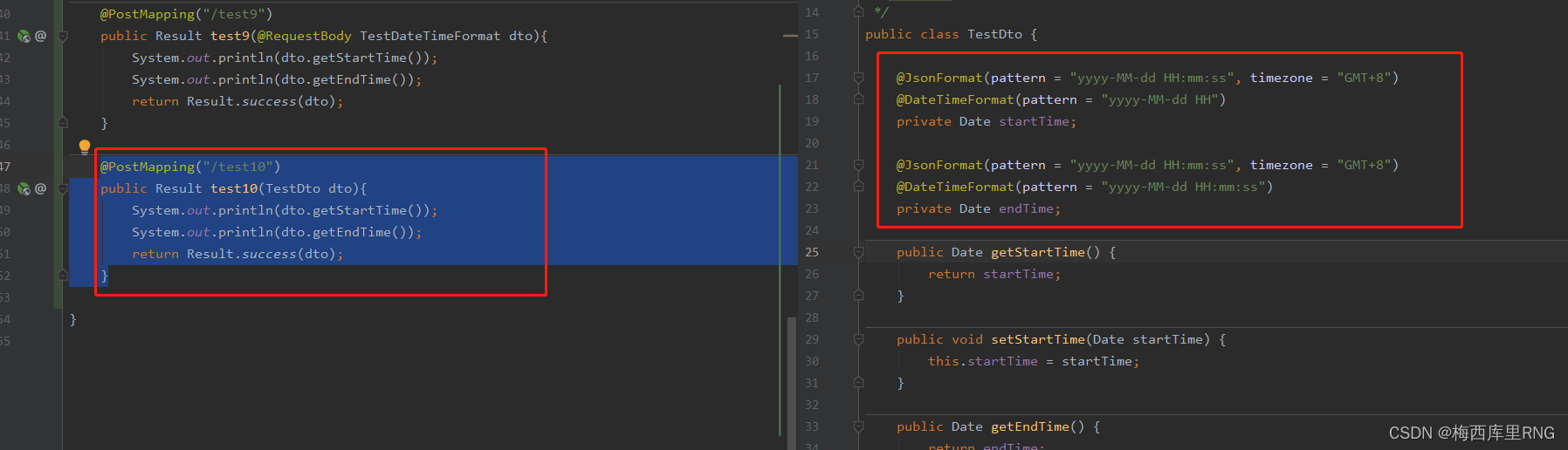
@JsonFormat比@DateTimeFormat好用的多,但是有一个问题:后端用@JsonFormat处理时间参数,前端只能用json格式传输。
这时可以通过@JsonFormat与@DateTimeFormat合用的方式,这样以后,@JsonFormat会“覆盖”@DateTimeFormat的作用,但是又支持前端通过form-data的方式传参数(@DateTimeFormat的功能);属于“1 + 1 > 2”了!
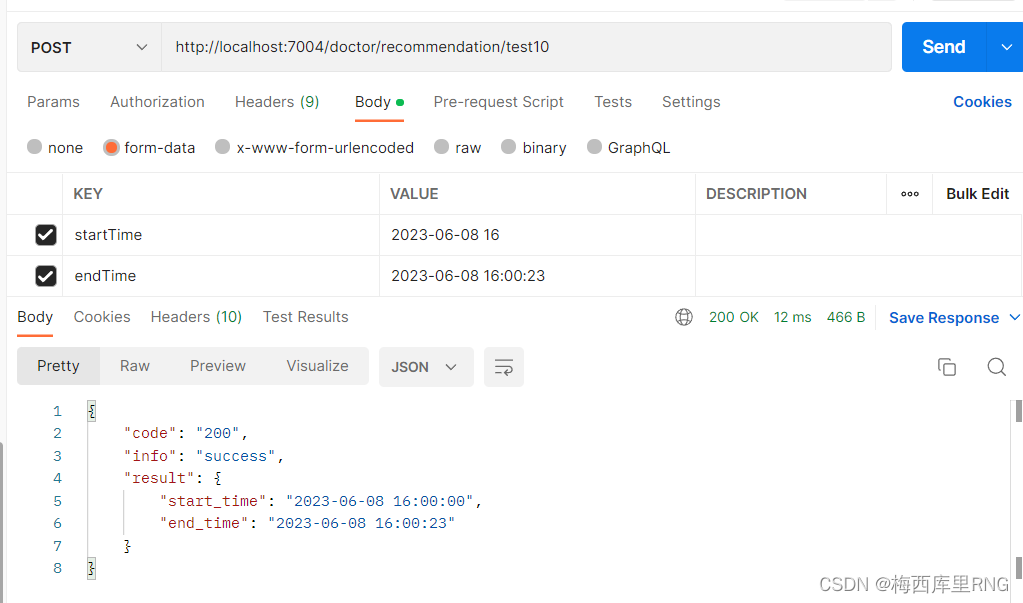
补充
刚才测试了一下,也不是@JsonFormat完全“覆盖”@DateTimeFormat的作用,@DateTimeFormat对时间格式限制还是起作用的(格式不对仍会报错)。
6、数据库几种时间字段的说明及处理方式
1)要点说明
以mysql为例,时间字段主要有date、time、datetime、timestamp、year这几种,其存储空间、显示格式如下图:
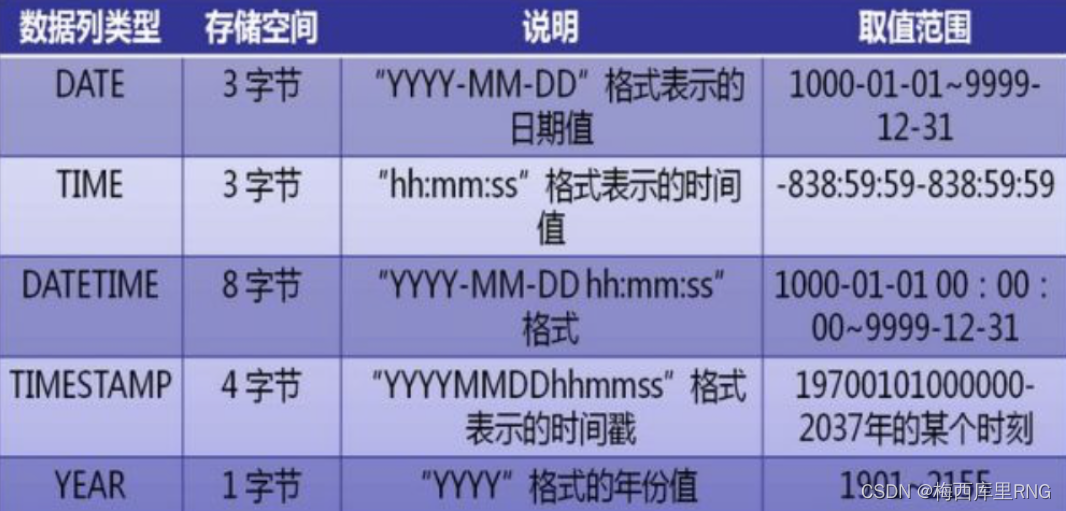
其中最常用的要数datetime和timestamp两种了;另外,有些为了查询方便,也可以用bigint类型来存时间。
分别说一下,当数据库采用这三种类型来存放时间,后端该如何传值。
2)bigint
先说最简单的bigint,这个类型就是常见的整型数字,一般用它存时间戳,也就是某时间点到格林威治时间之间的秒值,这个时间戳可以转换成时间(精确到秒值)。
也可以存时间的毫秒值,也就是某时间到格林威治时间之间的毫秒值,这时它的数值是13位、比时间戳多3位;这样可以让记录的时间精确到毫秒值。
但是一般用bigint存时间,都是为了简单,毫秒值这个需要手动转换用到较少,大多还是用时间戳。
a、sql查询
使用bigint存时间时,sql做增删改非常方便,尤其对时间进行范围查询时优势明显,和处理数字一样,对比其它类型我个人感觉很方便;
b、后端接收前端传的参数
因为前端从时间控件直接获取的时间值就可以是数字类型,所以后端controller方法可以直接用Long类型接收,这样前后端处理都很方便;后面接口间参数传递,直到放入sql进行查询都不需要处理。
唯一要注意的是,前端可以获取时间戳or时间毫秒值,后端也可以;为了效率、方便,两边要统一。一般以数据库设计为准,如果数据库存的是时间戳,那么后面增删改查前后端都应该拿时间戳交互,不然还需要手动处理,多此一举了属于是。
c、后端返回前端
后端直接返回数字类型就可以,前端可以处理;如果前端要求后端处理,可以在DateUtils类中,写一个方法。
方法核心就是先把Long类型转成Date,再把Date转成相应格式字符串
long time = 1609296070000L;
Date date = new Date(time);
SimpleDateFormat sdf= new SimpleDateFormat("yyyy-MM-dd");
String dateStr=sdf.format(date);
还是上面说的,前后端都可以处理时间格式,但是为了大家都省事要从一开始就约定好,都使用时间戳大家都不用做额外的转换工作;方便,是使用bigint存时间的初衷。
3)timestamp
timestamp也叫时间戳(英文翻译就是时间戳),记录某时间与1970年1月1号0点0分0秒(格林威治时间)之间的秒值(注意是秒值,不是毫秒值,总共10位数字、而不是13位),数据库占用4字节,比bigint的8字节、datetime的8字节要小,包含的时间信息到秒值、一般已够用。
a、sql查询
使用timestamp类型存时间,查询时有些麻烦。
a、直接使用数值类型是不行的,比如时间2023-06-08 16:36:24,它的时间戳是1686213384,但是如下sql并不能查出正确结果、返回为空,意思没有create_time<=1686213384的数据(实际是有的)
SELECT * from test_table WHERE create_time<=1686213384
mysql有两个时间戳相关的函数:FROM_UNIXTIME()和UNIX_TIMESTAMP(),两者互为反函数。
FROM_UNIXTIME函数,可以把时间戳转换成具体时间。
UNIX_TIMESTAMP函数,就是把时间转换成时间戳。
两个函数的使用方式、及效果如下:
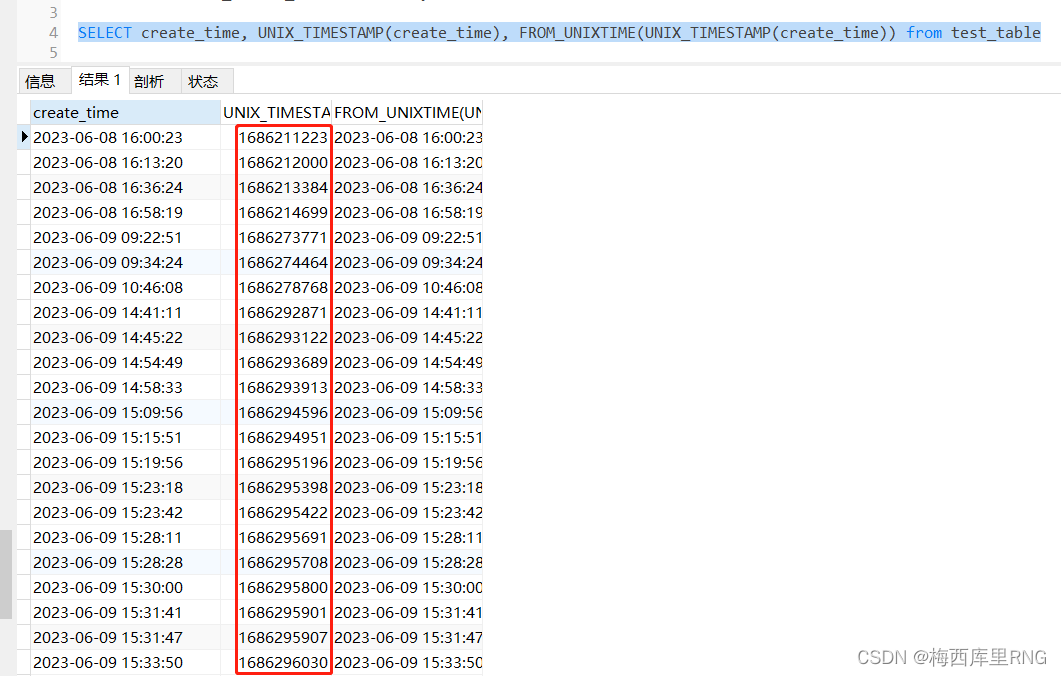
所以上面不能运行的查询的sqlSELECT * from test_table WHERE create_time<=1686213384,实际上可以写成这样:
SELECT * from test_table WHERE create_time<=FROM_UNIXTIME(1686213384)

b、对timestamp进行范围查询的话,还可以直接使用时间格式字符串,这样不用做转换,例如
SELECT * from test_table WHERE create_time>="2023-08-15 10:40:51" and create_time<='2023-08-17 10:40:51'
# 或者
SELECT * from test_table WHERE create_time>="2023-08-15" and create_time<='2023-08-17'
c、如果拿到的查询参数是具体时间、而不是时间戳,这时做查询就应该如上面b所说一样直接查;而不要多此一举、再用一下UNIX_TIMESTAMP函数,像下面这样的sql,是查不出结果的
SELECT * from km_doctor_recommendation WHERE create_time>=UNIX_TIMESTAMP("2023-08-15 10:40:51")
小结:通过实测发现,timestamp虽然叫“时间戳”,但是实际上数据库还是把它当作时间处理的、而不是当作数值,所以查询时的参数,要么直接是时间,要么把时间戳转换成时间,否则就不能正常查出结果。
其实java后端也是一样,等会儿2)中会说。
b、后端接收前端传的参数
其实怎么接都行,只要和前端商量好就行;一般看系统以前的习惯、偏好。
像我们这个系统,前端之前传的都是时间戳,我们就用Long类型接收参数,拿到以后给它转换成Date类型,然后传到mybatis做sql查询的参数。
这里要补充说明一下,对于数据库是时间戳类型的时间字段,java后端也需要把入参转换成Date类型,这个入参才能正确的参与sql查询。
虽然时间戳应该是“某个时间与格林尼治时间之间的秒值”,按定义来讲、时间戳应该是个具体的整型数值,但好像再mysql查询时,还是把timestamp当作时间运算。
当然,如果某个前端,想要传时间类型(类似2023-08-15 10:40:51这种),后端也能支持;这种情况要么手动转换(先用String接收,然后转成Date),要么用注解协助接收(使用@JsonFormat 或 @DateTimeFormat,具体怎么用要看前端的传输方式,可以参照本章中《前端后端传接时间参数的方式》)。
c、后端返回前端
timestamp类型时间,从数据库查出来可以直接映射到Date中,Date类型直接返回前端,他们就能处理。
七、Java线程池
1、线程池简介
1)使用场景
java开发中的很多功能,都需要用到并行、异步操作,来提高工作效率,而并行、异步操作都需要使用多个线程。
创建线程和销毁线程的花销是比较大的(手动new Thread 类),创建和销毁线程的时间有可能比处理业务的时间还要长,如果频繁的创建和销毁线程、将非常的耗费资源;而使用线程池,就可以很大程度的解决上述问题。
2)定义及优点
线程池就是存放线程的池子,池子里存放了很多可以复用的线程。
创建好一定数量的线程放在池中,等需要使用的时候就从池中拿一个,这要比需要的时候创建一个线程对象要快的多;
线程池中的核心线程,使用完重新放回线程池、不销毁,这减少了创建和销毁线程的次数,每个核心线程都可以被重复利用;
假如创建线程用的时间为T1,执行任务用的时间为T2,销毁线程用的时间为T3,那么使用线程池就免去了T1和T3的时间。
所以,线程池以极小的开销,极大的提高了线程的复用性和多线程任务的工作效率。
2、常见的几种线程池创建方式
总体来说线程池的创建可以分为以下两类:
通过 ThreadPoolExecutor 手动创建线程池。
通过 Executors 执行器自动创建线程池。
1)通过ThreadPoolExecutor创建线程池
ThreadPoolExecutor 是最原始、也是最推荐的手动创建线程池的方式,它在创建时最多提供 7 个参数可供设置。
a、ThreadPoolExecutor核心参数:

创建方法参数展示:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
b、ThreadPoolExecutor 使用示例:
public static void myThreadPoolExecutor() {
// 创建线程池
ThreadPoolExecutor threadPool = new ThreadPoolExecutor(5, 10, 100, TimeUnit.SECONDS, new LinkedBlockingQueue<>(10));
// 执行任务
for (int i = 0; i < 10; i++) {
final int index = i;
threadPool.execute(() -> {
System.out.println(index + " 被执行,线程名:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
程序执行结果如下图所示:

ThreadPoolExecutor 相比于其他创建线程池的优势在于,它可以通过参数来控制最大任务数和拒绝策略,让线程池的执行更加透明和可控,所以在阿里巴巴《Java开发手册》是这样规定的:
【强制要求】
线程池不允许使用 Executors 去创建,而是通过 ThreadPoolExecutor 的方式,
这样的处理方式让写的同学更加明确线程池的运行规则,规避资源耗尽的风险。
2)通过Executors创建线程池
a、FixedThreadPool
创建一个固定大小的线程池,可控制并发线程数。
例如使用 FixedThreadPool 创建一个并发数为 2的线程池,具体实现代码如下:
public static void fixedThreadPool() {
// 创建 2 个线程的线程池
ExecutorService threadPool = Executors.newFixedThreadPool(2);
// 创建任务
Runnable runnable = new Runnable() {
@Override
public void run() {
System.out.println("任务被执行,线程:" + Thread.currentThread().getName());
}
};
// 线程池执行任务(一次添加 4 个任务)
// 执行任务的方法有两种:submit 和 execute
threadPool.submit(runnable); // 执行方式 1:submit
threadPool.execute(runnable); // 执行方式 2:execute
threadPool.execute(runnable);
threadPool.execute(runnable);
}
代码执行结果如下图:

b、CachedThreadPool
创建一个可缓存的线程池,若线程数超过任务所需,那么多余的线程会被缓存一段时间后才被回收,若线程数不够,则会新建线程。
CachedThreadPool 使用示例如下:
public static void cachedThreadPool() {
// 创建线程池
ExecutorService threadPool = Executors.newCachedThreadPool();
// 执行任务
for (int i = 0; i < 10; i++) {
threadPool.execute(() -> {
System.out.println("任务被执行,线程:" + Thread.currentThread().getName());
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
});
}
}
代码执行情况如下:

从上述结果可以看出,线程池创建了 10 个线程来执行相应的任务。
使用场景
CachedThreadPool 是根据短时间的任务量来决定创建的线程数量的,所以它适合短时间内有突发大量任务的处理场景。
c、SingleThreadExecutor
创建单个线程的线程池,它可以保证先进先出的执行顺序。
SingleThreadExecutor 使用示例如下:
public static void singleThreadExecutor() {
// 创建线程池
ExecutorService threadPool = Executors.newSingleThreadExecutor();
// 执行任务
for (int i = 0; i < 10; i++) {
final int index = i;
threadPool.execute(() -> {
System.out.println(index + ":任务被执行");
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
});
}
}
代码执行结果如下:

单个线程的线程池有什么意义?
单个线程的线程池相比于线程来说,它的优点有以下 2 个:
- 可以复用线程:即使是单个线程池,也可以复用线程。
- 提供了任务管理功能:单个线程池也拥有任务队列,在任务队列可以存储多个任务,这是线程无法实现的,并且当任务队列满了之后,可以执行拒绝策略,这些都是线程不具备的。
d、ScheduledThreadPool
创建一个可以执行延迟任务的线程池。
使用示例如下:
public static void scheduledThreadPool() {
// 创建线程池
ScheduledExecutorService threadPool = Executors.newScheduledThreadPool(5);
// 添加定时执行任务(1s 后执行)
System.out.println("添加任务,时间:" + new Date());
threadPool.schedule(() -> {
System.out.println("任务被执行,时间:" + new Date());
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
}
}, 1, TimeUnit.SECONDS);
}
代码执行结果如下:任务在 1 秒之后被执行了,实现了延迟 1s 再执行任务。

3)线程池创建方式总结:
a、Executors 返回的线程池对象有如下弊端:
1)FixedThreadPool 和 SingleThreadPool:允许的请求队列长度为 Integer.MAX_VALUE,可能会堆积大量的请求,从而导致 OOM。
2)CachedThreadPool:允许的创建线程数量为 Integer.MAX_VALUE,可能会创建大量的线程,从而导致 OOM。
补充:oom就是我们常说的Out Of Memory—内存溢出,它是指需要的内存空间大于系统分配的内存空间,oom后果就是项目程序crash(系统崩了)。
b、推荐线程池创建方式
推荐使用 ThreadPoolExecutor 的方式来创建,因为使用它可以明确线程池的运行规则,规避资源耗尽的风险。
3、线程池的工作流程

4、多线程四种拒绝策略
这四种拒绝策略,在ThreadPoolExecutor里是四个内部类。
1)AbortPolicy
当任务添加到线程池中被拒绝时,直接丢弃任务,并抛出RejectedExecutionException异常。
AbortPolicy abortPolicy = new ThreadPoolExecutor.AbortPolicy();
2) DiscardPolicy
当任务添加到线程池中被拒绝时,丢弃被拒绝的任务,不抛异常。
DiscardPolicy discardPolicy = new ThreadPoolExecutor.DiscardPolicy();
3)DiscardOldestPolicy
当任务添加到线程池中被拒绝时,丢弃任务队列中最旧的未处理任务,然后将被拒绝的任务添加到等待队列中。
DiscardOldestPolicy discardOldestPolicy = new ThreadPoolExecutor.DiscardOldestPolicy();
4)CallerRunsPolicy
被拒绝任务的处理程序,直接在execute方法的调用线程中运行被拒绝的任务;就是被拒绝的任务,直接在主线程中运行,不再进入线程池。
CallerRunsPolicy callerRunsPolicy = new ThreadPoolExecutor.CallerRunsPolicy();
5、如何合理配置线程池
使用线程池时通常我们可以将执行的任务分为两类:
- cpu 密集型任务
- io 密集型任务
cpu 密集型任务,需要线程长时间进行的复杂的运算,这种类型的任务需要少创建线程(以CPU核数+1为准),过多的线程将会频繁引起上文切换,降低任务处理速度。
而 io 密集型任务,由于线程并不是一直在运行,可能大部分时间在等待 IO 读取/写入数据,增加线程数量可以提高并发度,尽可能多处理任务。
补充,配置线程池最好的方式是可以动态修改线程池配置,
例如调用线程池的threadPoolExecutor.setCorePoolSize();方法,
搭配分布式配置中心可以随着运行场景动态的修改核心线程数等功能。
6、一个项目要配置几个线程池?
1)个人认为一个项目应该尽量用一个线程池
项目可以配多个线程池,但我个人认为,应该尽量少建,如果可以满足需求,最好整个个项目只用一个线程池,理由如下:
1)线程池本身也会耗费资源;
2)我们需要控制线程池的核心线程数、队列数、拒绝策略等,如果建多个线程池,想要统一管理非常麻烦;而且很难估计多个线程池、在各自的应用模块,实际有多少线程在运行,这样不仅不好配置线程池参数、搞不好还容易造成内存溢出。
2)spring项目如何实现一个项目只用一个线程池?
a、如果使用多线程的地方只有一个类,
那么可以在类中new一个静态线程池对象,这样这个类无论新建多少个对象,该线程池都是同一个对象,如下:
public class TestThreadPoolUtil {
private static ThreadPoolExecutor threadPool = new ThreadPoolExecutor(
5,
10,
10,
TimeUnit.SECONDS,
new LinkedBlockingQueue<>(100),
new ThreadPoolExecutor.AbortPolicy());
****任务代码****
}
用上述方式,即可实现只用一个线程池的目标(前提是你的项目只有这一个地方需要多线程,你只在这个地方new了线程池)。
原理就是static修饰的静态变量独立于对象,无论一个类实例化多少对象,它的静态变量只有一份拷贝。
b、如果你的项目需要在多个地方使用多线程呢?
按照上面的思路,应该建一个全局范围的静态变量,但是我不知道这个咋实现。
我是通过spring-ioc容器实现全项目只用一个线程池的,下面通过测试实例说明一下具体方法,同时论证确实是同一个线程池:
第一步,先在applicationContext.xml中配置线程池参数,核心线程、队列长度、最大线程、允许空虚时间、拒绝策略;
<!-- 线程池配置 -->
<bean id="threadPool" class="org.springframework.scheduling.concurrent.ThreadPoolTaskExecutor">
<!-- 核心线程数 -->
<property name="corePoolSize" value="5" />
<!-- 最大线程数 -->
<property name="maxPoolSize" value="30" />
<!-- 队列最大长度 >=mainExecutor.maxSize -->
<property name="queueCapacity" value="500" />
<!-- 线程池维护线程所允许的空闲时间 -->
<property name="keepAliveSeconds" value="200" />
<!-- 线程池对拒绝任务(无线程可用)的处理策略 -->
<property name="rejectedExecutionHandler">
<bean class="java.util.concurrent.ThreadPoolExecutor$CallerRunsPolicy" />
</property>
</bean>
第二步,将要用到线程池的类交给spring容器管理,然后在类中注入线程池,下边写上测试方法
@Component
public class TestThreadPoolUtil {
@Resource(name = "threadPool")
private ThreadPoolTaskExecutor threadPool;
public void testMehtod01(){
// 创建线程池
for (int i = 0; i < 10; i++) {
final int index = i;
threadPool.execute(() -> {
System.out.println("A类方法一 " + index + " 被执行,线程名:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
public void testMehtod02(){
// 创建线程池
for (int i = 0; i < 10; i++) {
final int index = i;
threadPool.execute(() -> {
System.out.println("A类方法二 " + index + " 被执行,线程名:" + Thread.currentThread().getName());
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
});
}
}
}
第三步,为了检查这样做用的是不是同一个线程池,上面的测试类,我弄了两个,代码逻辑基本一样,名字改为TestThreadPoolUtil ,输出“B类***”与第一个类区分开。
同时,为了并发访问两个测试类(必须并发,才能检测是不是同一线程池,串行不能确认),我新建了两个线程(继承Thread类,重写run()方法)
/**第一个**/
@Component
public class Thread1 extends Thread{
@Autowired
private TestThreadPoolUtil a;
@Override
public void run() {
System.out.println("【线程一】" + "group:"+ Thread.currentThread().getThreadGroup() + "; id:" +Thread.currentThread().getId()+"; name:"+ Thread.currentThread().getName());
a.testMehtod01();
a.testMehtod02();
}
}
/**第二个**/
@Component
public class Thread2 extends Thread{
@Autowired
private TestThreadPoolUtil02 b;
@Override
public void run() {
System.out.println("【线程一】" + "group:"+ Thread.currentThread().getThreadGroup() + "; id:" +Thread.currentThread().getId()+"; name:"+ Thread.currentThread().getName());
b.testMehtod01();
b.testMehtod02();
}
}
然后写一个controller方法调用,测试
@Controller
public class TestThreadPoolController {
@Autowired
private Thread1 t1;
@Autowired
private Thread2 t2;
@GetMapping("/test01")
public void testMethod01() {
t1.start();
t2.start();
}
}
执行结果如下:
【线程一】group:java.lang.ThreadGroup[name=RMI Runtime,maxpri=10]; id:83; name:Thread-16
【线程一】group:java.lang.ThreadGroup[name=RMI Runtime,maxpri=10]; id:84; name:Thread-17
B类的方法一 0 被执行,线程名:threadPool-2
A类方法一 0 被执行,线程名:threadPool-1
A类方法一 1 被执行,线程名:threadPool-3
B类的方法一 1 被执行,线程名:threadPool-4
A类方法一 2 被执行,线程名:threadPool-5
B类的方法一 2 被执行,线程名:threadPool-5
B类的方法一 4 被执行,线程名:threadPool-4
B类的方法一 5 被执行,线程名:threadPool-1
B类的方法一 3 被执行,线程名:threadPool-2
B类的方法一 6 被执行,线程名:threadPool-3
B类的方法一 7 被执行,线程名:threadPool-1
A类方法一 3 被执行,线程名:threadPool-5
A类方法一 4 被执行,线程名:threadPool-4
B类的方法一 9 被执行,线程名:threadPool-3
B类的方法一 8 被执行,线程名:threadPool-2
A类方法一 5 被执行,线程名:threadPool-2
A类方法一 7 被执行,线程名:threadPool-1
A类方法一 9 被执行,线程名:threadPool-4
A类方法一 6 被执行,线程名:threadPool-3
A类方法一 8 被执行,线程名:threadPool-5
A类方法二 0 被执行,线程名:threadPool-1
A类方法二 3 被执行,线程名:threadPool-4
A类方法二 4 被执行,线程名:threadPool-5
A类方法二 2 被执行,线程名:threadPool-3
A类方法二 1 被执行,线程名:threadPool-2
A类方法二 5 被执行,线程名:threadPool-3
A类方法二 6 被执行,线程名:threadPool-2
A类方法二 8 被执行,线程名:threadPool-5
A类方法二 7 被执行,线程名:threadPool-4
A类方法二 9 被执行,线程名:threadPool-1
B类的方法二 0 被执行,线程名:threadPool-2
B类的方法二 1 被执行,线程名:threadPool-5
B类的方法二 4 被执行,线程名:threadPool-1
B类的方法二 3 被执行,线程名:threadPool-4
B类的方法二 2 被执行,线程名:threadPool-3
B类的方法二 5 被执行,线程名:threadPool-2
B类的方法二 6 被执行,线程名:threadPool-1
B类的方法二 9 被执行,线程名:threadPool-4
B类的方法二 8 被执行,线程名:threadPool-5
B类的方法二 7 被执行,线程名:threadPool-3
【分析】
从结果可以看到,A类、B类的方法交替执行,但是他们的线程都来自同一个线程池“threadPool”、也就是我在application.xml中配置的。
不仅如此,它们还遵循我对线程池的配置(核心线程数5),每当正在运行的线程满5,不论是A类还是B类、接下来的任务就先放入队列,等有空余线程再执行。
从以上两点可以确认,A类和B类用的是同一个线程池,我们这种方式可以实现同一个项目共用一个线程池的目标。
八、二进制标识位
1、使用场景
建表、建类通常会用到标识位,比如通过/没通过、删除/没删除、状态、渠道、来源等等;如果少了还好说,如果多了,比如渠道有5~6个,状态有10来个,这时若再一个字段一个标识,就需要建太多字段了,“很浪费”。
有没有什么方法,可以用一个字段表示很多表示呢?
二进制标识就可以做到;
比如,用来表示歌曲标签,个位表示“是否为纯音乐”,十位表示“是否为经典歌曲”,千位表示是否为“是否为情歌”,万位表示“是否为动感歌曲”;每一位都用0表示否定、1表示肯定。
那么0101表示什么呢?
说明这首歌是情歌、纯音乐,但不是动感歌曲、不是经典歌曲;
同理,0110呢/
表示这首歌是经典歌曲、且是情歌。
而0101在数据库只需要存一个5,0110在数据库只需要存一个6。
上述,就是用二进制作标识位。
2、具体实例
1)写个工具类
工具类,一方面是为了记录每个位置代表的含义;另一方面是为了转义标识,比如给一个10进制的数->识别出代表了那些标识、并转成好几个数字,方便前端显示。
/**
* @author litian
* @version V1.0
* @Description 歌曲标签
* @date 2024/4/6 16:50
* @Package com.ruoyi.common.utils.system
*/
public class SongTagsUtils {
public static final int INIT = 0;
public static final int LOVE = 1 << 0; //情歌,0001
public static final int GOLDEN = 1 << 1; //经典,0010
public static final int DYNAMIC = 1 << 2; //动感,0100
// 检查入参是否包含任一个标签,将所有包含的标签、放到List<Integer>中返回
public static List<Integer> getAllContainTagsList(int songTags){
List<Integer> tagList = new ArrayList<>();
if(hasTag(songTags, LOVE)){
tagList.add(LOVE);
}
if(hasTag(songTags, GOLDEN)){
tagList.add(GOLDEN);
}
if(hasTag(songTags, DYNAMIC)){
tagList.add(DYNAMIC);
}
return tagList;
}
// 检查入参是否包含任一个标签,将所有包含的标签、放到List<String>中返回
public static List<String> getAllContainTagsStrList(int songTags){
List<String> tagStrList = new ArrayList<>();
if(hasTag(songTags, LOVE)){
tagStrList.add("情歌");
}
if(hasTag(songTags, GOLDEN)){
tagStrList.add("经典");
}
if(hasTag(songTags, DYNAMIC)){
tagStrList.add("动感");
}
return tagStrList;
}
// 授予标签:source是要贴标签的初始值,targetTag是要贴的标签值(eg:SongsTags.LOVE.code,即贴情歌标签)
public static int grant(int source, int targetTag) {
source |= targetTag;
return source;
}
// 撤销标签
public static int revoke(int source, int targetTag) {
source &= ~targetTag;
return source;
}
// 检查是否具有某标签、是否具有某几个标签
// 若要检查是否具有某个标签,targetTag入参就是某一个标签标签的code码
// 若要检查是否具有某几个标签,targetTag入参就是某几个标签标签的code码合集,比如又是情歌、又是经典老歌,targetTag=0011
public static boolean hasTag(int source, int targetTag) {
return (source & targetTag) == targetTag;
}
// 检查入参是否包含任一个标签,将所有包含的标签、放到Integer[]中返回
public static Integer[] getAllContainTagsArry(int songTags){
List<Integer> tagList = getAllContainTagsList(songTags);
Integer[] tagArr = new Integer[tagList.size()];
tagList.toArray(tagArr);
return tagArr;
}
// 检查入参是否包含任一个标签,将所有包含的标签的描述、放到String[]中返回
public static String[] getAllContainTagsArryText(int songTags){
List<String> tagStrList = getAllContainTagsStrList(songTags);
String[] tagArr = new String[tagStrList.size()];
tagStrList.toArray(tagArr);
return tagArr;
}
}
2)数据库
数据库建一个数字类型的字段就行
`song_tags` int(8) NULL DEFAULT 0 COMMENT '歌曲标签,用2进制位作标记,具体含义看后端代码',
3)后台代码
新增的时候,把前端传来的数组转换成一个标识字段
@PostMapping("/add")
public AjaxResult add(@RequestBody SmsSongs params)
{
//校验
if(StringUtil.isEmpty(params.getSongName())){
return AjaxResult.error("歌名不能为空!");
}
//转义标签字段
params.setCreateTime(curr);
Integer[] tagArr = params.getTagArr();
if(tagArr != null){
int songTags = Arrays.stream(tagArr).mapToInt(Integer::intValue).sum();
params.setSongTags(songTags);
}else {
params.setSongTags(0);
}
//保存
boolean save = songsService.save(params);
//响应
return save ? AjaxResult.success(params) : AjaxResult.error();
}
查询的时候,把数据库标识字段(十进制),转换成数组,方便前端展示
@GetMapping("/getById")
public AjaxResult getById(Long id)
{
//根据id查询对象
SmsSongs byId = songsService.getById(id);
//将标签字段进行拆解
Integer songTags = byId.getSongTags();
if(songTags != 0){
Integer[] tagArr = SongTagsUtils.getAllContainTagsArry(songTags);
byId.setTagArr(tagArr);
}
//返回
return AjaxResult.success(byId);
}
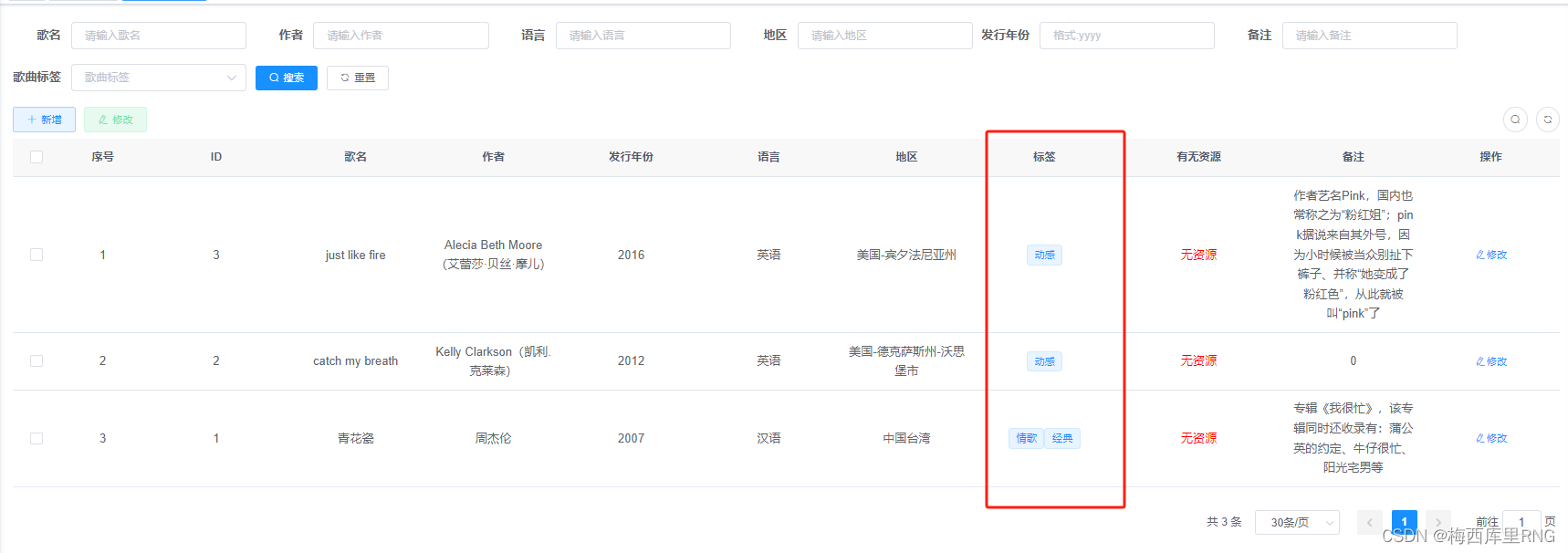
4)前端效果展示
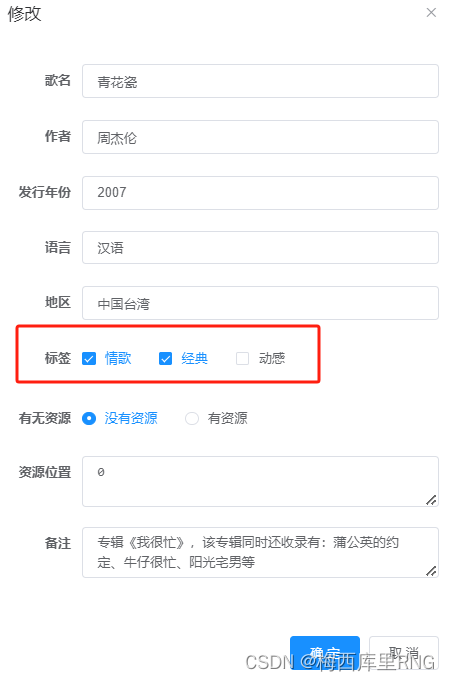
5)一个小难点
多条件查的时候,标签怎么查?
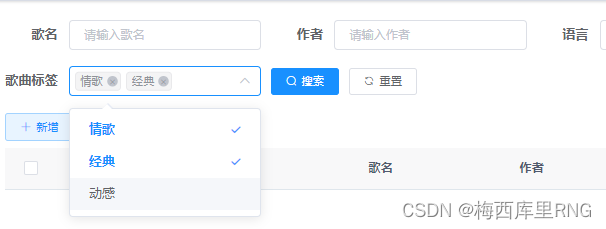
首先前端传过来的查询条件、标签是个数组,先处理成一个标签值,方便后续使用
@GetMapping("/page/query")
public IPage<SmsSongs> pageQuery(SmsSongs params) throws ParseException {
//分页查询
Integer[] paramTagArr = params.getTagArr();
if(paramTagArr != null){
int paramSongTags = Arrays.stream(paramTagArr).mapToInt(Integer::intValue).sum();
params.setSongTags(paramSongTags);
}
IPage<SmsSongs> smsSongsIPage = songsService.pageQuery(params);
...
}
然后重点是,在sql查询时的逻辑
先作与运算:参数 & 库中标签值,
结果再与入参对比,相等就是符合查询条件;
额~就是与运算,与0与都是0,说明白很麻烦,但其实好理解,大家感谢兴趣自己推算一下,给具体的sql作参考
<select id="pageQuery" resultType="com.ruoyi.system.domain.SmsSongs">
select
<include refid="Base_Column_List"></include>
from sms_songs
<where>
<!--是否包含入参标签:参数与库标签先作'与'运算,结果等于参数就是全包含、否则就是不全包含-->
<if test="params.songTags!=null">
and (song_tags & #{params.songTags}) = #{params.songTags}
</if>
</where>
ORDER BY id DESC
</select>
注意,mybatis里直接写&运算符识别会出问题,要转义成&
X、琐碎
1、@Deprecated注解
表示此方法已废弃、暂时可用,但以后此类或方法都不会再更新、后期可能会删除,建议后来人不要调用此方法。
使用场景示例:科教平台对接icme系统,暂时采用互相同步数据的方式,以后要重构icme项目至科教平台;所以互相调用阶段的接口是暂时,以后随时会删除,为了防止这些方法被其他地方调用,导致不必要的耦合度增加,就使用了@Deprecated,有非常醒目的提醒。

















 229
229











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









