







一、操作字段sql
1、往表中添加一个字段
# a、简单版
alter table 表名 add 字段名 字段类型
# b、(msql中的格式)全量
ALTER TABLE table_name ADD COLUMN column_name VARCHAR(100) DEFAULT NULL COMMENT '新加字段' AFTER old_column;
VARCHAR(100):字段类型为varchar,长度100;
DEFAULT NULL:默认值NULL;
AFTER old_column:新增字段添加在old_column字段后面。
# c、oracle中略有不同;
# 示例:register表添加字段“ADDR_SUPPLY”,
# mysql与oracle备注的添加方式不同,oracle中给字段添加备注,是单独的语句,如果按mysql的方式添加,会执行失败
ALTER TABLE API_APP_REGISTER ADD ADDR_SUPPLY VARCHAR2(255) DEFAULT '';
COMMENT ON COLUMN API_APP_REGISTER.ADDR_SUPPLY IS '地址补充,将会在检测主机状态时、拼接在地址后面';
2、删除一个字段
alter table 表名 drop column 字段名
3、修改一个字段
1)改字段名字
alter table <表名> change <字段名> <字段新名称> <字段的类型>
2)改字段类型、长度
ALTER TABLE 表名 MODIFY COLUMN 字段名 数据类型(修改后的长度)
## oracle略有不同,不能加关键字COLUMN(mysql加不加都行)
ALTER TABLE 表名 MODIFY 字段名 数据类型(修改后的长度)
3)修改表备注、修改字段备注
#修改表备注
alter table 表名 comment '注释内容';
#修改字段备注,修改备注和修改字段其他属性是同样的sql;字段名、类型不修改就照抄原来的,不能省略、否则报错
alter table 表名 modify column 字段名 类型 comment '注释内容';
二、索引相关sql
1、创建索引
CREATE INDEX index_name ON table_name (column_name);
# 示例:在客户表的name列上创建索引
CREATE INDEX cust_name_idx ON customers (cust_name);
2、创建唯一索引
在CREATE之后添加关键字UNIQUE即可
# 示例:在客户表的name列上创建唯一索引
CREATE UNIQUE INDEX cust_name_idx ON customers (cust_name);
3、创建联合索引
格式与单列索引类似
CREATE UNIQUE INDEX idx_user_course_id
ON nhms_study_record(user_id, course_id);
4、(在MySQL中)查看指定表的索引
mysql> SHOW INDEXES FROM customers \G
# 注意:用\G代替分号(;)终止SQL语句
三、操作表sql
1、sql清空表数据的三种方式:
1)truncate –删除所有数据,保留表结构,不能撤销还原,速度快
truncate table 表名
2)delete –是逐行删除,不适合大量数据删除,速度极慢
delete from 表名 where 列名="value "
3)drop –删除表,表数据和表结构一起删除,速度快
drop form 表名
四、查询相关sql
1、having和where
1)where每次筛查一行数据,将满足条件的数据行留下,group by在where之后执行,将where筛选出的数据行进行分组;因为where每次操作一行数据,所以其后的判断条件不能使用聚合函数。
2)having在group by之后执行,筛查的是分组后的整个临时表,它会将不满足条件的临时表整个删除;因为having操作整个临时表,所以having后可以使用聚合函数作为判断条件;
3)示例
假设有这样一组数据,我们要查询某个课程下,必修课、非必修课的数量
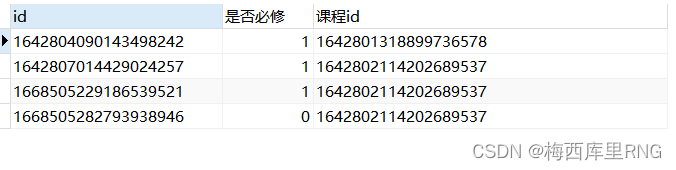
A、如果用having筛选,sql如下
SELECT * FROM 表名
GROUP BY 是否必修
HAVING 课程id='1642802114202689537'
结果只有是否必修=0的数据
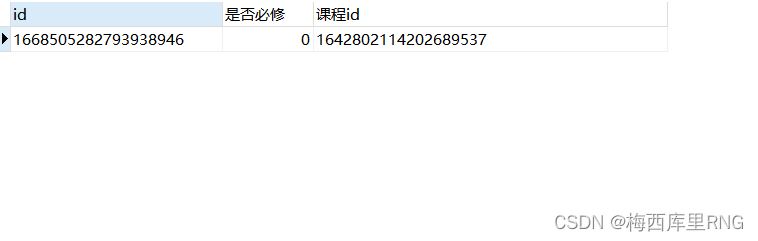
因为分组后,是否必修=1的那组,有一行数据的课程id尾号是6578;
goup by后,having条件要求课程id尾号为9537,这个要求是要整个分组临时表都符合才行,所以是否必修=1的那组不满足条件、被筛掉了。
B、如果用where筛选,sql是这样
SELECT * FROM 表名
WHERE 课程id='1642802114202689537'
GROUP BY 是否必修
结果有两行数据,是否必修=0、是否必修=1的都有
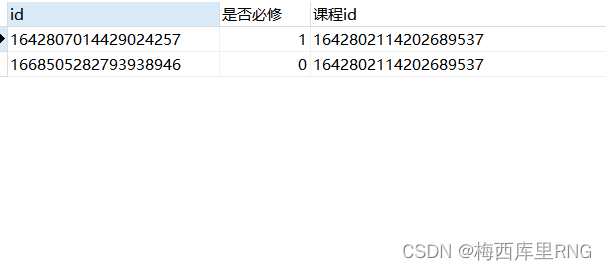
where条件执行后,已经把课程id尾号是6578的数据筛掉了;之后再group by分组,是否必修=0、是否必修=1的组,都只有课程id尾号是9537的数据;最后两个分组各取第一条组成最后结果。
所以,where和having,相同的筛选条件、查询结果并不相同。
2、in查询元素超过1000条mybais不支持-解决方案
方案一:核心思路是,将集合拆分,使用or 连接。(太复杂、太慢,不推荐)
select * from A where id in (1, 2, …, 1000) or id in (1001, …, 1999)
用mybatis的话就是这样
select * from test_1
<where>
<if test="list != null and list.size > 0">
(id IN
<!-- 处理in的集合超过1000条时Oracle不支持的情况 -->
<trim suffixOverrides=" OR id IN()">
<foreach collection="list " item="Id" index="index" open="(" close=")">
<if test="index != 0">
<choose>
<when test="index % 1000 == 999">) OR id IN (</when>
<otherwise>,</otherwise>
</choose>
</if>
#{Id}
</foreach>
</trim>
)
</if>
但是这种方法不好用,实测中3万条左右的机构,用这种查询查了好久都没出来,感觉数据库都要奔溃了。
方案二:用子查询(推荐)
其实in查询不能超过1000个元素,是mybatis的限制,数据库是支持的。
一般来说,超过1000多条的数据,肯定不是用户填写的,而是从其他地方查询出来的。
那么我们就不要把这些数据先查出来、再作为条件查询一次;而是直接用子查询,然后in这个子查询结果,这样就绕过mybatis的限制了。
前面说了,数据库是支持in元素超过1000条的,只要绕过mybatis限制,就能执行in中元素超过1000的sql。

该查询中,机构关系表SEP_SYSTEM_ORG_RELATION中有20多万条数据,但子查询走了我们创建的组合索引;整个查询只用了0.367秒

3、查询结果拼接
1)多条结果,合并成一条
对oracle
wm_concat(risk_rule)
默认用“,”分割;也可以设定分隔符
wm_concat(risk_rule Separator '、')
对mysql
group_concat(coursename Separator ',')
2)多个字段,拼接成一个
Oracle数据库,可以使用字符串连接运算符 ||
# 示例1
select province || city as 用户地区 from TEST_USER;
# 示例2
select ID || '-' || USER_ID 合并id from TEST_USER;
Mysql数据库有以下两种方法
法一:通过函数CONCAT()
此函数可以把任意多个字符串拼接到一起,多少个字段也能拼接、多少个符合也能拼接
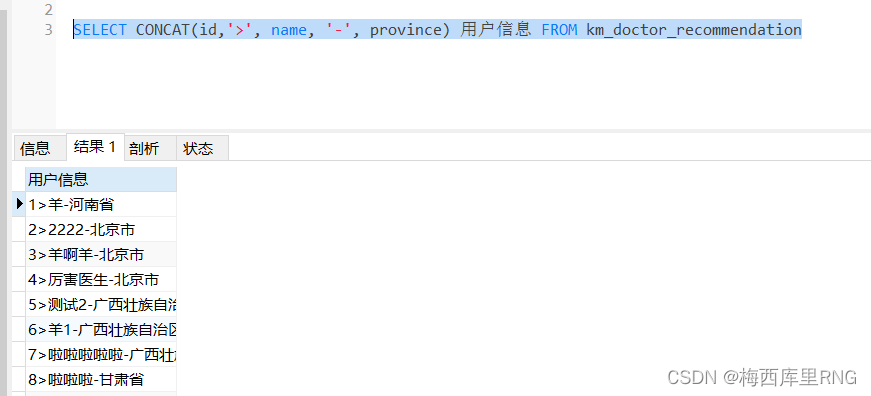
# 示例
SELECT CONCAT(id,'>', name, '-', province) 用户信息 FROM km_doctor_recommendation
法二:通过函数CONCAT_WS(‘符号’, 字段1, 字段2, 字段3, …)
此函数可以拼接任意多个字段,但是分割的符号是相同的;如果不需要分隔符,符号那儿就写''
# 示例
SELECT CONCAT_WS('-', province, city, name) 用户信息 FROM km_doctor_recommendation

3)多条查询sql结果拼接
使用关键字union 或 union all实现多条查询结果的拼接,两者区别:
Union会自动去重;
Union All不会去重;
补充:很多时候or查询为了增加命中索引的概率,会把or查询变为多条查询、并用union或union all拼接
4、case…when…语法
case后如果写字段,那when后就写值,判断的就是字段是否等于值;
case后可以不写字段,这时when后要写‘字段与值的对比’,判断的就是这个对比是否成立。
1)针对单个字段,最简单的判断
SELECT
CASE g.is_auth
WHEN 0 THEN '待审核'
WHEN 1 THEN '审核通过'
WHEN 2 THEN '审核拒绝'
ELSE '其他'
END 审核状态,
g.goods_id
FROM es_goods g
WHERE g.goods_belong=1
2)通过两个字段共同判断
SELECT g.goods_id 商品id,
CASE
WHEN g.is_auth=0 AND g.market_enable=0 THEN '待审核'
WHEN g.is_auth=0 AND g.market_enable=1 THEN '待审核'
WHEN g.is_auth=0 AND g.market_enable=2 THEN '审核拒绝'
WHEN g.is_auth=1 AND g.market_enable=0 THEN '已下架'
WHEN g.is_auth=1 AND g.market_enable=1 THEN '售卖中'
WHEN g.is_auth=1 AND g.market_enable=2 THEN '已下架'
ELSE '其他'
END 课程状态
FROM es_goods g
WHERE g.goods_belong=1















 194
194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









