



一,基于多尺度注意力机制的多分支行人重识别算法
江南大学物联网工程学院江苏省模式识别与计算智能工程实验室
论文地址:https://pan.quark.cn/s/2e3c81dcac0a
论文摘要:针对基于深度学习的传统方法对于次显著细节信息关注不足的问题,提出一种基于多尺度注意力机制的多分支网络来统筹图像的显著信息及次显著信息。首先,将多尺度特征融合方法(MSFF)与注意力机制相结合,设计 了一个多尺度注意力模块(MSA),使得网络可以根据输入信息自适应地调节感受野大小,实现了对于不同尺度信 息的充分利用。其次,建立一个多分支网络,实现对于全局特征和多元局部特征的协调统一,并利用多尺度注意力模块,分别实现对于全局显著信息及次显著局部细节信息的加权强化,得到更具判别性的特征用于最终的识别。 实验结果表明,本文所设计的网络在多个数据集上都取得了较好的表现。
网络框架图:
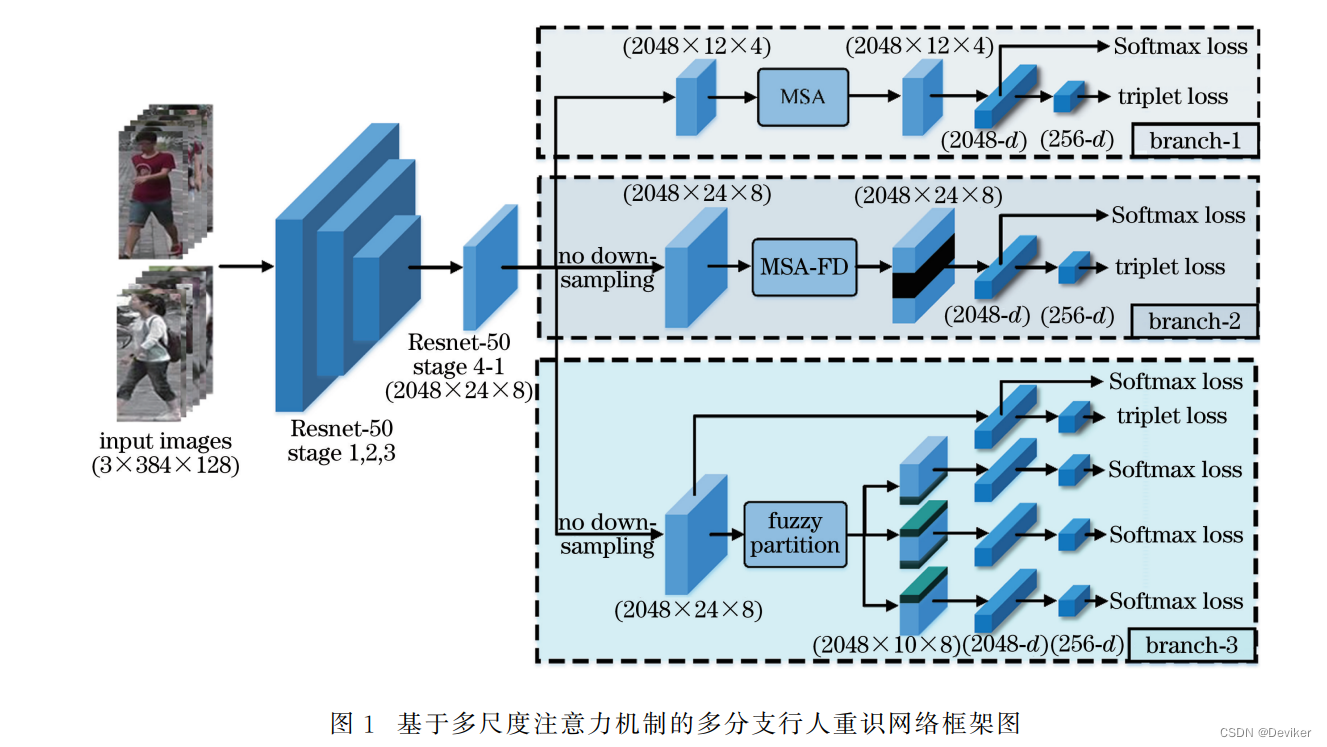
摘要中提到了两个点,首先是多尺度特征融合方法(MSFF),论文中有给出介绍图(上方的蓝色框)
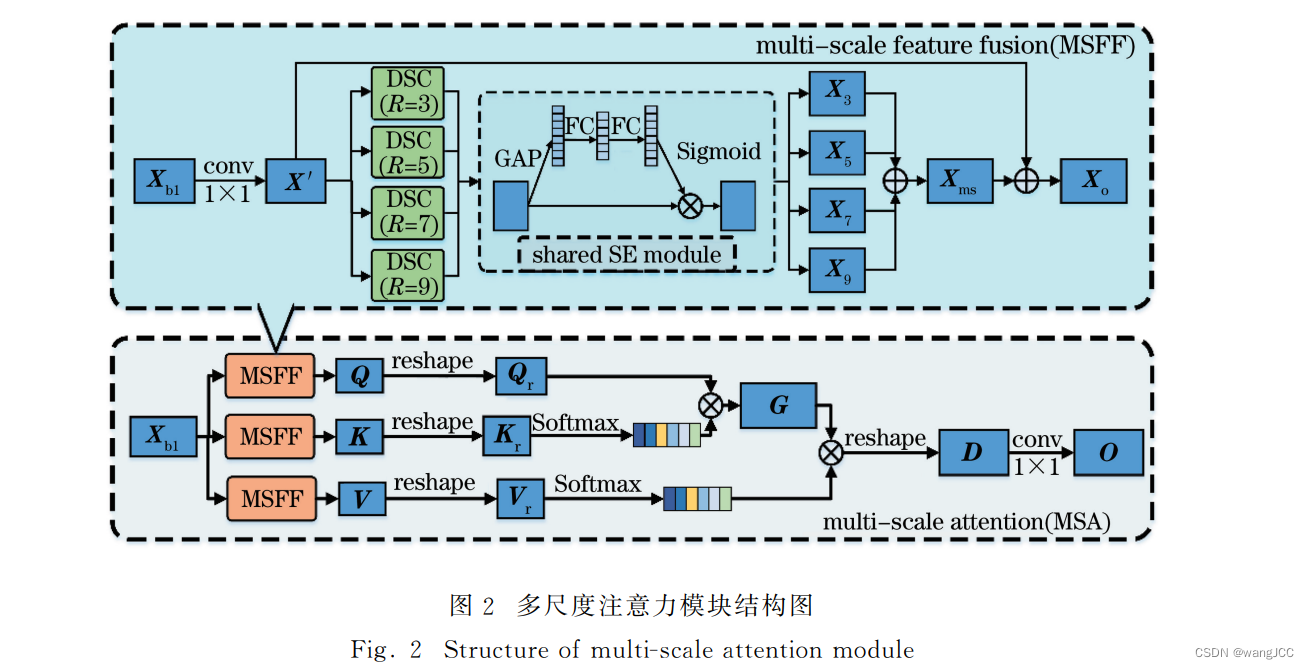
Xb1是经Resnet-50网络第4阶段得到的特征(Xb1∈R C×H ×W),为了减少参数量,对Xb1做1x1的卷积减少通道数,然后将 X' 输入到四个DSC模块。什么是DSC? DSC叫深度可分离卷积(Depthwise Separable Convolution,DSC)原理图如下:
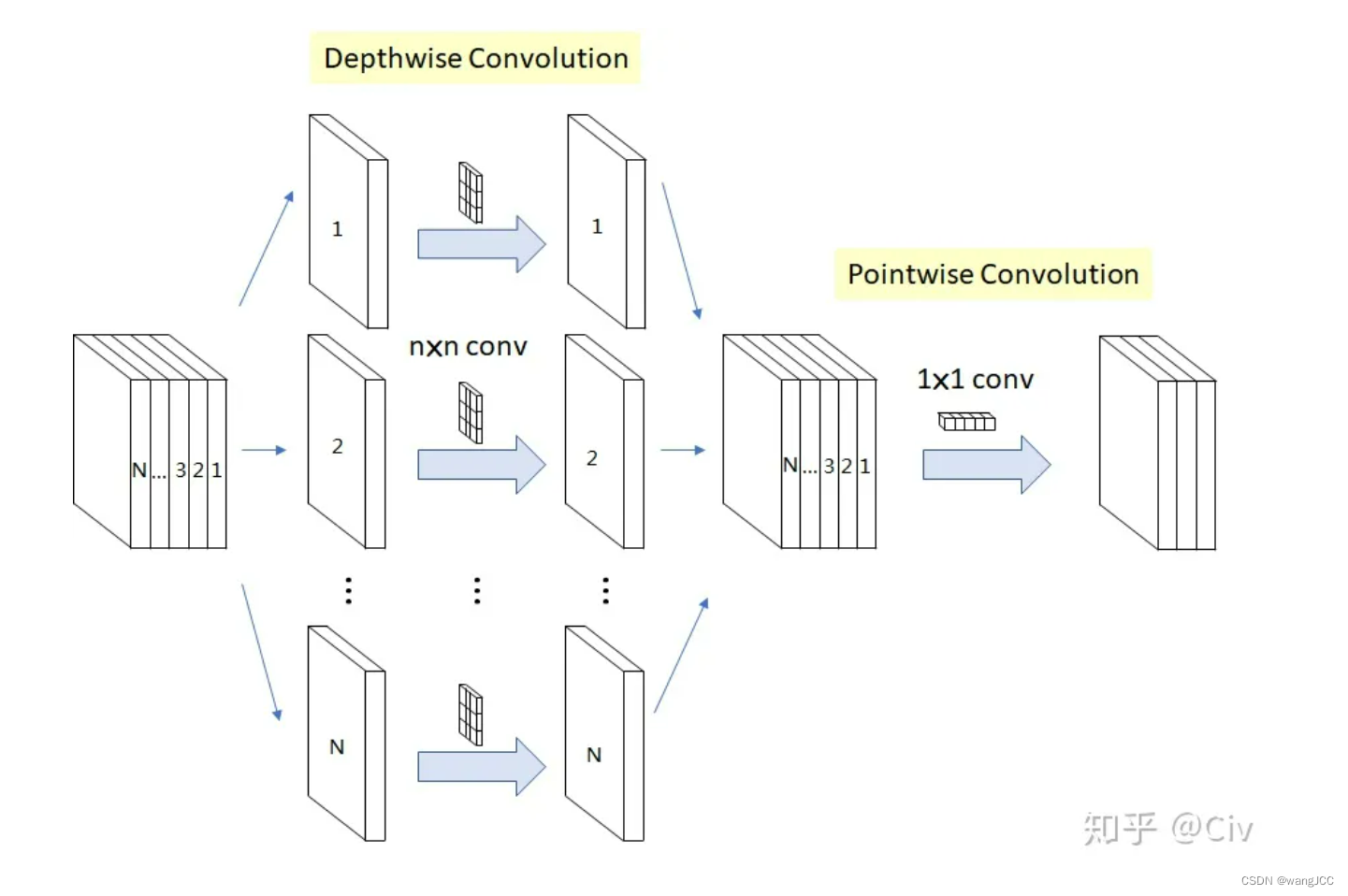
区别于普通的卷积,DSC的特点在于输入有多少个通道数,就有多少个卷积核,并且是一一对应的,做完卷积后将所有的通道拼起来,然后做1x1的卷积来改变通道数并且融合特征。DSC的优点在于计算效率高,相比传统卷积计算量小,但是缺点是精度较低。
回到上述,将X' 输入到四个DSC模块。每个DSC的感受野不同,论文中分别是3,5,7,9。实际上就是卷积核的大小为3,5,7,9。小的感受野更加关注局部的信息,大的感受野关注全局的信息。
接下来,是摘要中提到的第二个点,注意力机制。注意力机制的核心在于让网络自己学习一个权重矩阵,然后让这个权重矩阵乘上特征图,目的是让网络更加关注一些核心的信息。
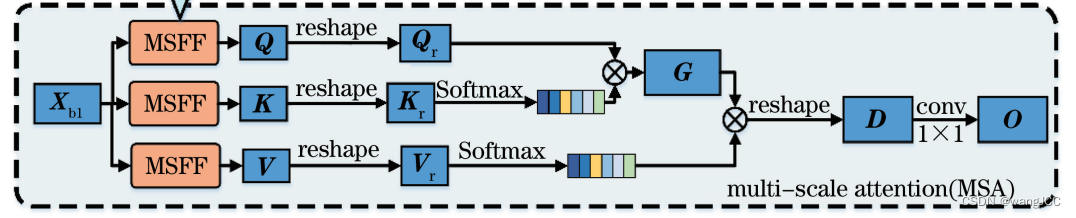
做法是将Xb输入到三个MSFF中,然后将Q和K做矩阵乘法得到权重矩阵G,然后再用G乘V,最后做输出。
网络第二条分支:基于多尺度注意力机制的特征丢弃分支
批量特征丢弃方法[4]以批 量的方式随机丢弃所有输入特征图的相同区域,以 增强局部区域更加精细化的特征学习,但该方法难 以实现对于保留区域特征的加权关注。本研究将 MSA 模块与批量特征丢弃方法相结合,设计了一个 多尺度注意力机制特征丢弃模块(MSA-FD),实现 了对于保留局部区域的特征权重调整,增强了模型 对于局部区域显著不同尺度特征的关注,减少了无 关信息对于模型的影响。
网络第三条分支:图像模糊分块分支
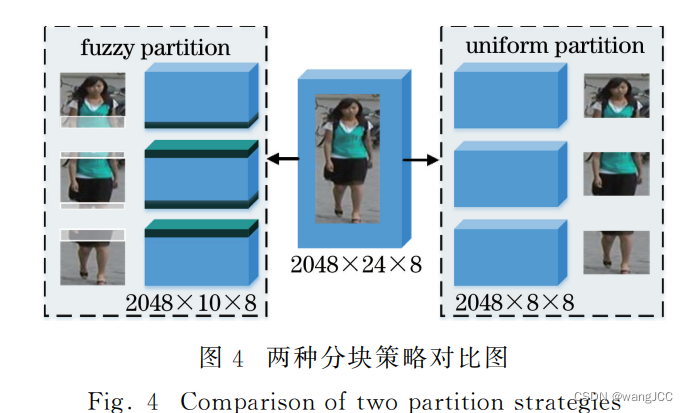
本研究在传统均匀分块的 基础上对切块策略进行了微调,采用一种模糊分块的 方法,给定网络第三分支传递来的特征Xb3∈R 2048×24×8, 如图4所示,沿着垂直方向将图像分为上中下三部分,每一部分的尺寸分别为2048×10×8,上中、中下部分 均有一定程度的重合,互相包含切分边缘的部分信息。 最后,分别计算每一部分的损失,这样就减少了暴力切 分造成的信息丢失的现象。将重叠部分尺寸设定为 2×8的区域,可以在减少信息损失的同时,避免全局显 著特征对于细节信息的弱化。
二,Relation-Aware Global Attention for Person Re-identification
作者:Zhizheng Zhang et al.(中科大&微软亚洲研究院)
论文地址:https://pan.quark.cn/s/7189b2256957
源码地址:RGA
数据集下载:
动机:在行人重识别研究中,注意力机制可以强化区分特征,抑制无关特征。之间的方法主要通过使用局部卷积和编码器-解码器结构的卷积堆叠的方式来学习注意力,忽略了从全局结构模式中挖掘知识。文中为了更好的进行Attention 学习,提出了Relation-Aware Global Attention Module。
如果说上一篇网络是在resNet网络提取完特征后设计算法,那么这篇文章就是在resNet提取特征的过程中设计算法。使网络提取的特征趋向于我们想要的。(如下图所示)

首先,作者回顾了之前关于注意力机制的工作,并指出了其存在的问题。
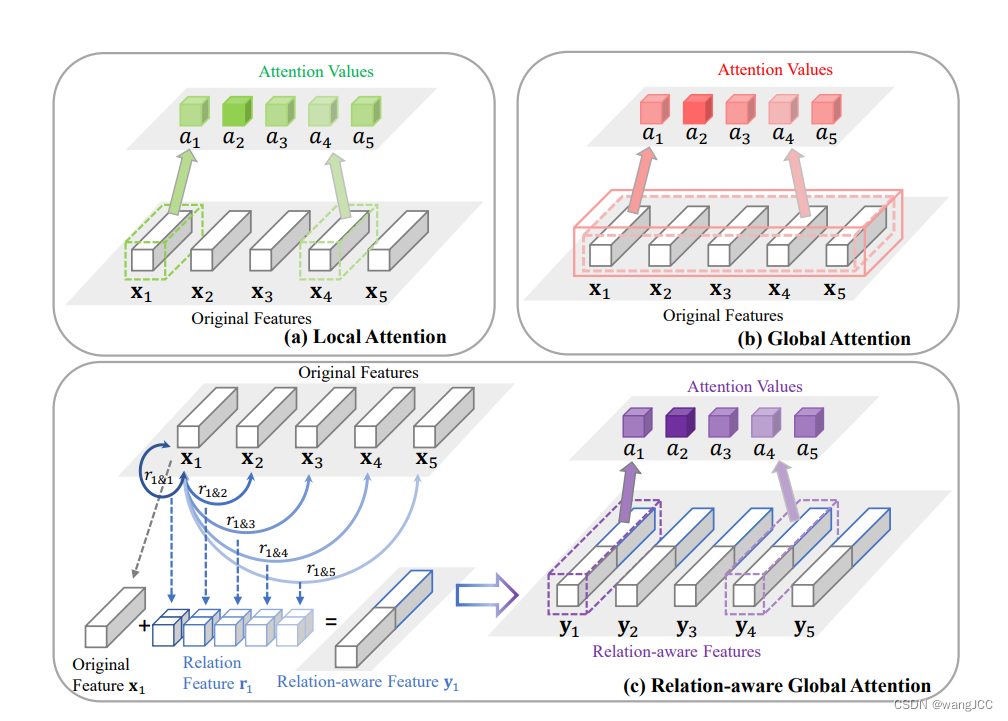
a图,是局部特征的注意力机制, X1~X5是特征图,关于每一个特征图都有一个权重a1~a5,问题是只能学习到局部特征,而忽视了全局特征。b 图使用全连接网络,学习到的attention值来自于所有特征向量的连接,虽然学习到了全局特征,但参数量过大,计算量太大。
那么,本文是如何做的呢?
resNet50有四个block,作者在每一个block 后面加上两个全局注意力机制,一个是对特征图的注意力机制,一个是对通道数的注意力机制。(如图所示)
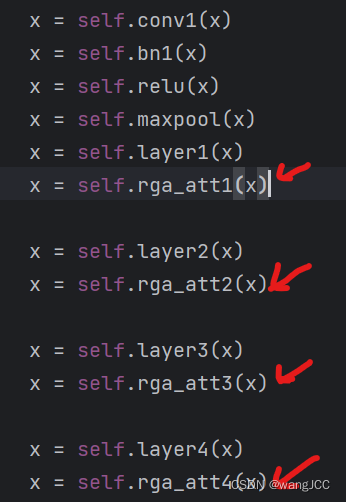
对特征图的注意力机制:
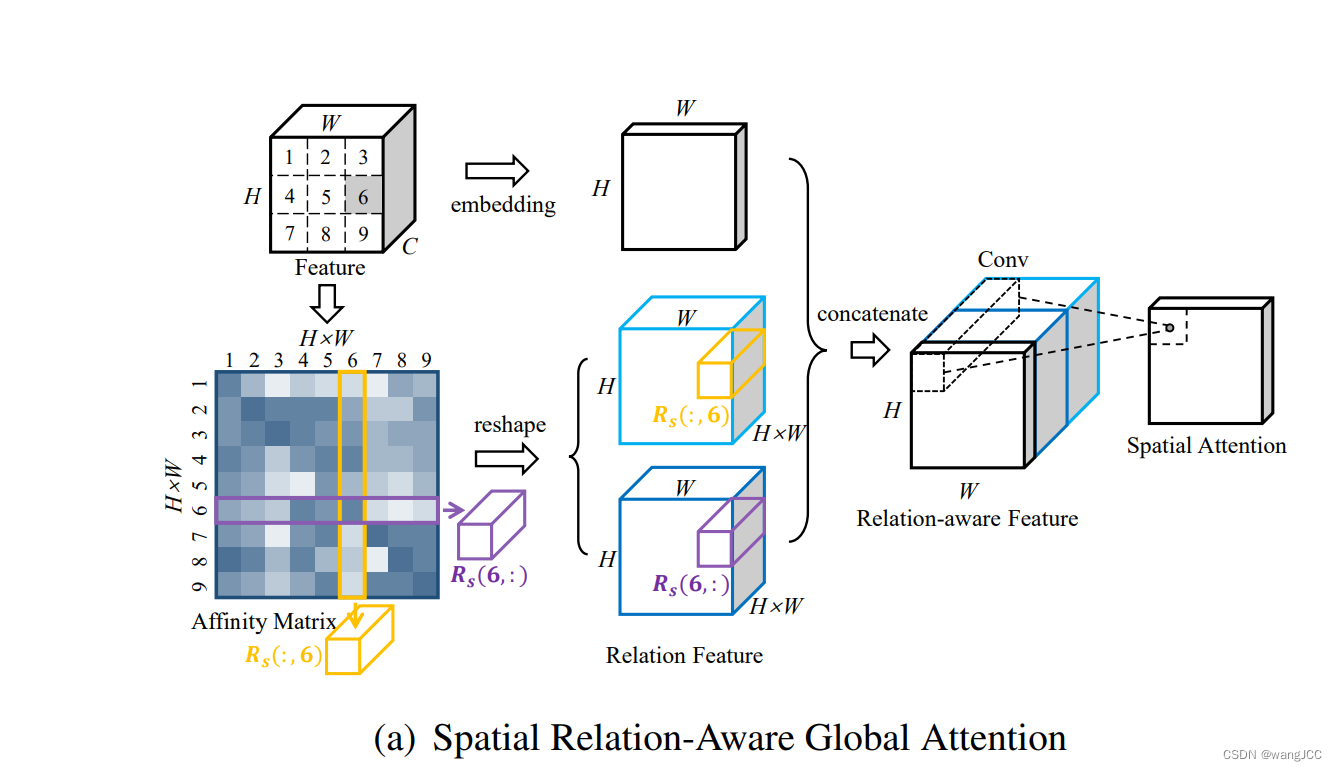
先看向下的箭头,这个9x9的矩阵是怎么得来的呢?(请留意观察每一个变量的shape)
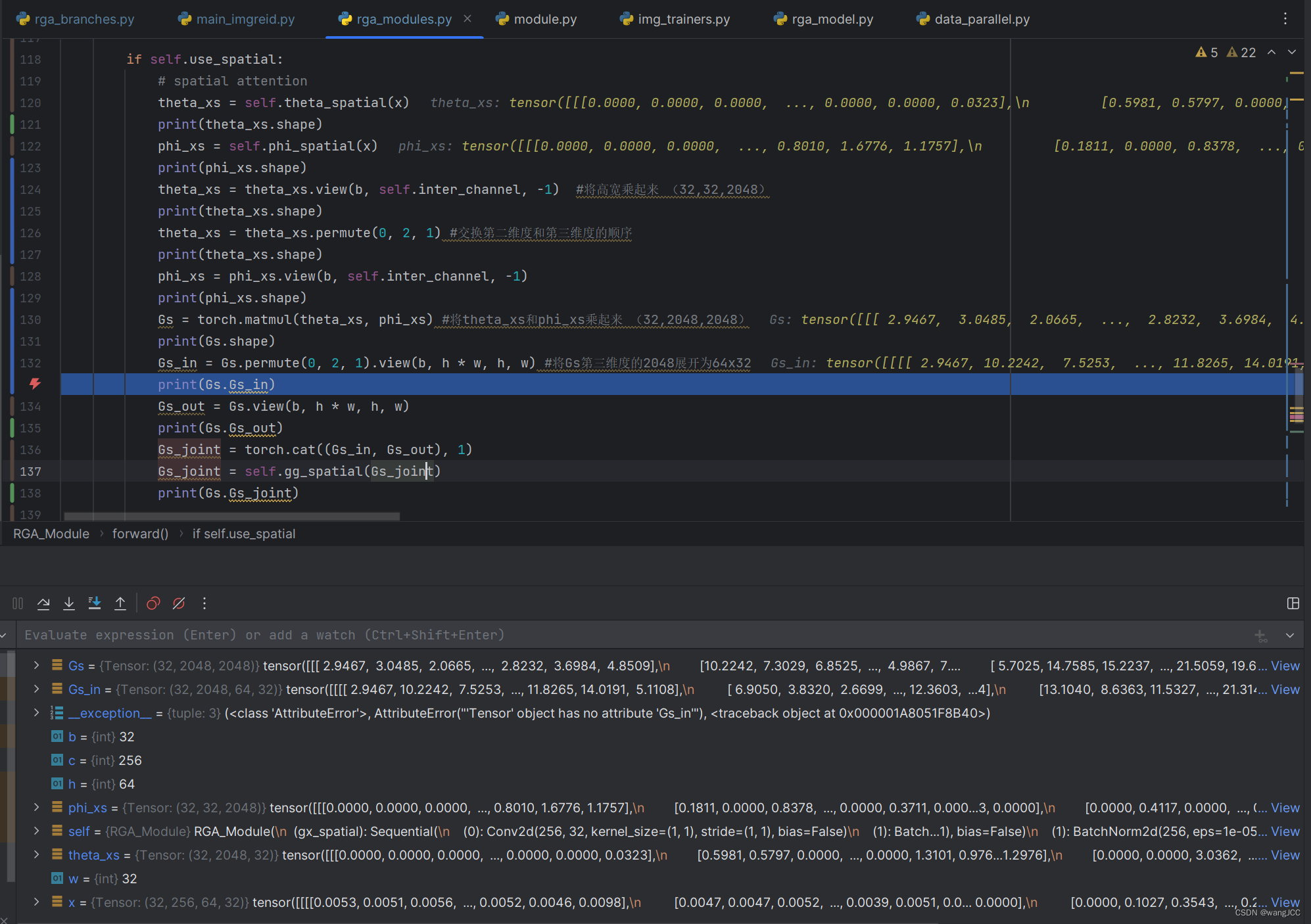
再看向左的箭头embedding:
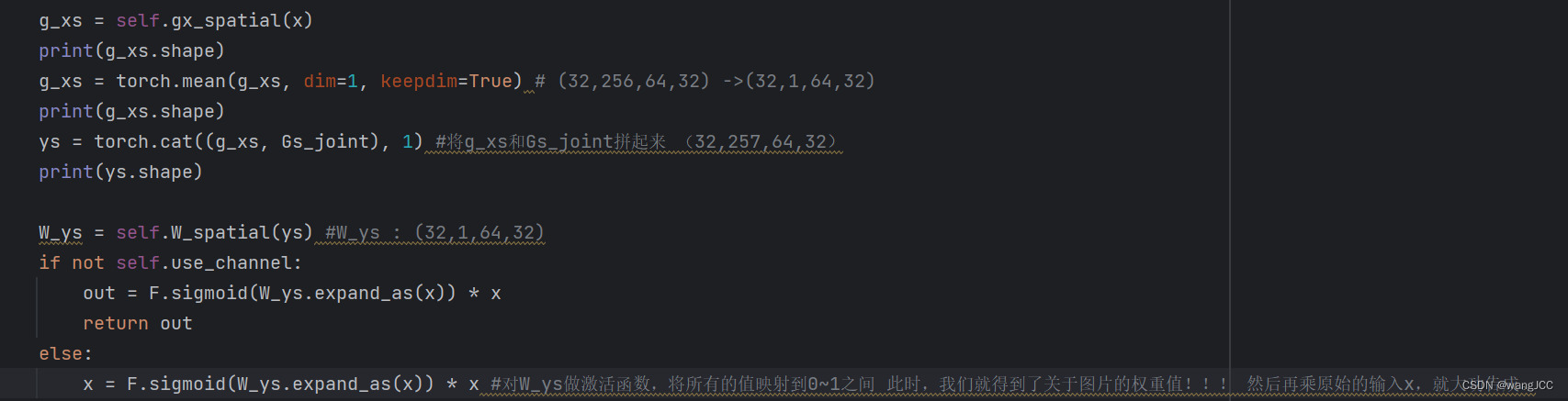
直接将原始的输入x在通道层面求均值,得到代码中的g_xs
然后我们将 g_xs和Gs_joint拼起来 得到 ys(32,257,64,32)
然后将ys在第二维度(257)求均值,变为1,得到W_ys,然后对W_ys做激活函数,将所有的值映射到0~1之间 此时,我们就得到了关于图片的权重值!!! 然后再乘原始的输入x,就大功告成。
对通道的注意力机制:
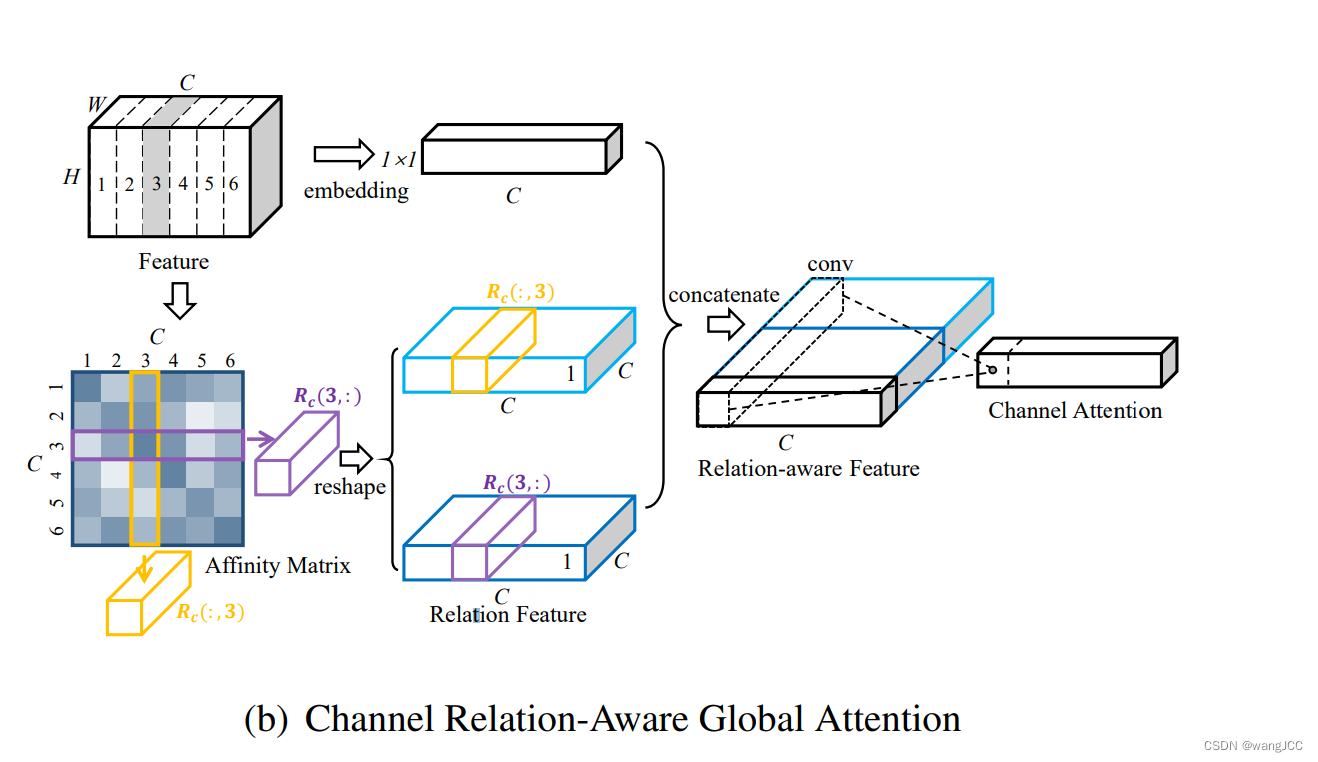
可以看到,和特征图全局注意力一模一样,其实,对于计算机来说,就是对一个张量的不同维度操作而已,无非就是一些数字嘛。
三,AlignedReID: Surpassing Human-Level Performance in Person Re-Identification
论文地址 : https://arxiv.org/pdf/1711.08184.pdf
代码地址:AlignedReid
这篇文章比较早一点,是旷视2017年的一篇文章AlignedReID,作者:浙江大学罗浩等人。
本文的创新点主要是利用了行人的局部区域之间的联系实现对行人的对齐,从而减少局部不对齐导致的距离过大。
主体框架: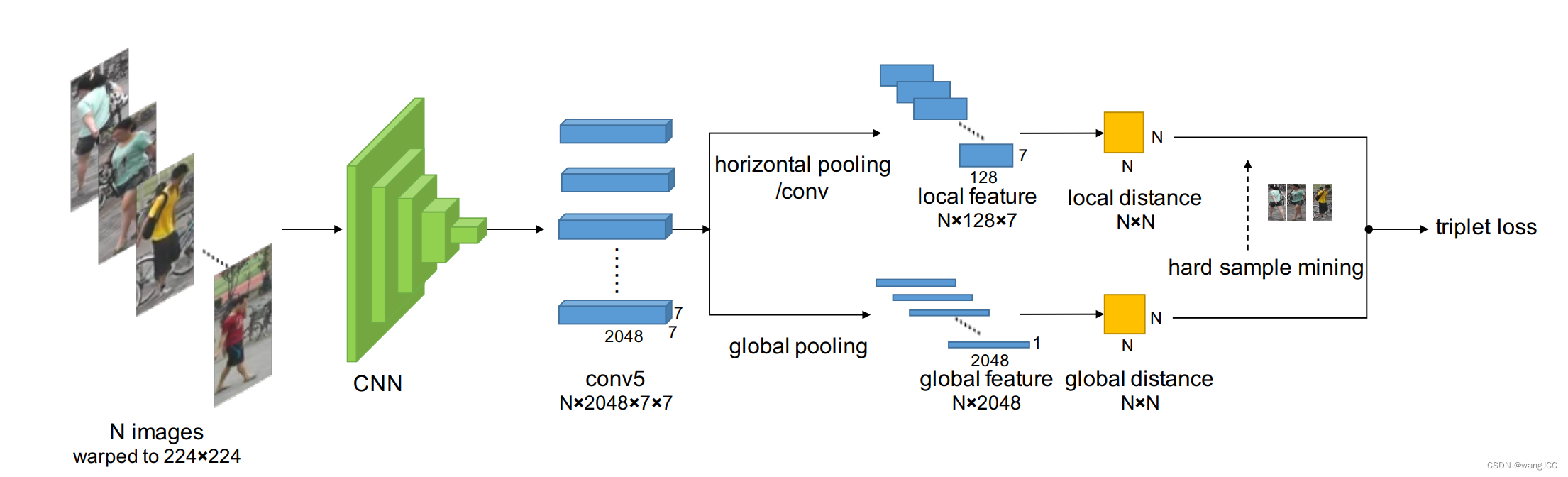
本文的作者也对论文以及代码做了详细介绍,具体细节请看视频。
当然,还有一些同时期的文章比如
High-Order Information Matters: Learning Relation and Topology for Occluded Person Re-Identification
高阶信息问题:行人重识别的学习关系与拓扑
https://arxiv.org/abs/2003.08177
主要针对于行人重识别当中遮挡的问题
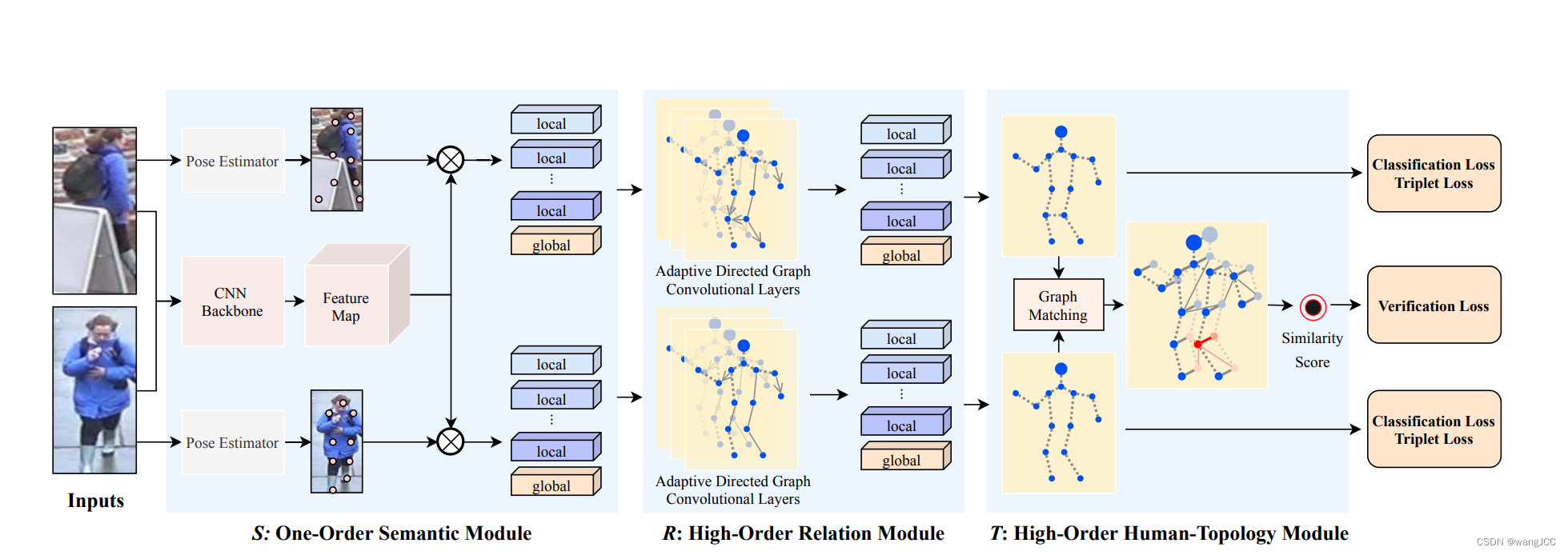
再比如
Relation Network for Person Re-identification
https://arxiv.org/pdf/1911.09318v1.pdf
提出考虑身体的一个局部特征与其它所有局部特征的关系,这个方法使得身体的一个单一部位包含与他部位的位置关系,使其更具有分辨力。
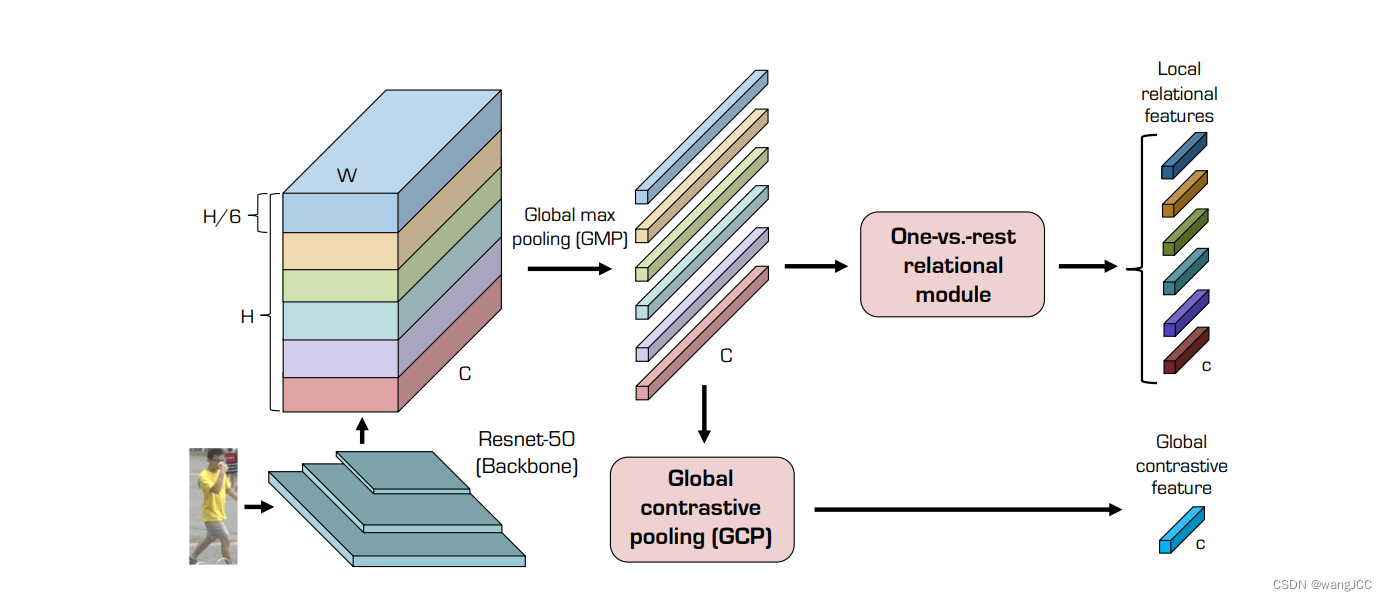
上述文章只是作者了解到的一小部分关于行人重识别的论文,其中,不乏有些思想可以运用到其他的项目中,比如全局注意力机制。还有一点,上述论文都是2020年及以前的文章,最近两年,行人重识别也是得到了长足的发展,同时也出现了大量的论文。
感兴趣的同学可以看以下文章。

















 1732
1732

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









