






项目背景
随着人工智能技术的飞速发展,机器学习训练已成为推动行业智能化转型的关键力量。这些大模型以其强大的语言理解和生成能力,在自然语言处理、图像识别、智能推荐等多个领域展现出极大的潜力。然而,机器学习的训练与部署对存储系统提出了前所未有的挑战。海量的训练数据、复杂的模型结构以及高频的数据读写需求,使得传统的非结构化存储方案难以胜任。
滴滴不断致力于提升用户体验,积极拥抱人工智能技术,在探索过程中,也遇到了数据存储与处理的瓶颈。传统的存储系统往往只支持单一协议,数据在不同协议间的转换不仅耗时费力,还极大地影响了机器学习模型的训练效率和部署速度。具体问题表现如下 :
机器学习等业务数据非常多,最少百PB级别存储量,主要小文件为主,基本上每个卷文件数达到几千万到百亿之间。
提供一定性价比。充分利用资源的同时有不错的性能,通常元数据延迟在10MS以下,带宽吞吐要求百GB以上。
机器学习等业务希望拥有对象存储的易用性,又能支持文件系统,同一份数据能支持多协议无损访问互通。业务通常会把需要训练的大模型、机器学习数据通过S3协议上传,通过机器学习的POSIX协议挂盘训练,过一段时间后自动删除,降低数据在多存储系统迁移成本、训练效率和数据管理成本。
支持云原生,同一块的机器学习数据盘,会被1万个容器根目录或子目录挂载读取。
多团队之间高效利用同一集群同一份数据且互不干扰。用户使用不同协议访问数据,不同权限管理数据保持数据不被影响干扰,最典型是A用户上传数据后,不希望B用户有权限删除。
为了满足业务需求,我们总结了新一代的非结构化存储系统,最少需要满足以下几个特性:
最少要支持百PB以上数据存储。
单卷或桶需要支持百亿级别的文件存储。
高性能低延迟的元数据存储服务,写控制2MS以内,读控制在10MS以内。
高并发高吞吐的存储底座,带宽吞吐要求百GB以上。
支持云原生,基于CSI插件可以快速地在Kubernetes上使用。
支持多租户,充分利用物理资源,同时支持相应的QoS能力来保证租户之间隔离。
多协议无损融合互通,实现Posix、S3、HDFS三种不同存储协议无损访问互通。
支持多云架构,充分利用公有云能力,能保证云上云下架构一致,应用与不同的场景,云下可以使用滴滴自研的存储引擎,云上可以使用AWS S3、阿里云OSS、腾讯云COS、谷歌云等。
方案探索
探索已有存储
我们对滴滴内部现有的非结构化存储来探索否满足以上特性?
GIFT对象存储系统:自研的对象存储,起源于滴滴基础平台,项目2016年9月开始建设,我们2017年4月开始接手,目前分成2.0和3.0版本, 2.0支持百亿级小文件系统,3.0兼容S3协议。这系统支持多租户、百PB以上数据存储、单桶最高支持百亿级文件数、高并发高吞吐存储底座、兼容S3协议。但是不支持POSIX协议、也不支持HDFSF协议、更不支持多协议融合,所以不满足需求。
Ceph存储系统:提供对象、块、文件等存储系统,但文件和对象是两个独立系统,数据迁移成本高,不满足需求。
HDFS开源项目:主要离线hadoop大数据生态场景,大文件存储为主,不满足需求。
GlusterFS开源项目:只POSIX协议的文件存储,性能满足需求,但不支持多租户、不支持HDFS协议、不兼容S3协议、不支持多存储语义、同时单卷容量也不满足需求。
探索多存储组合
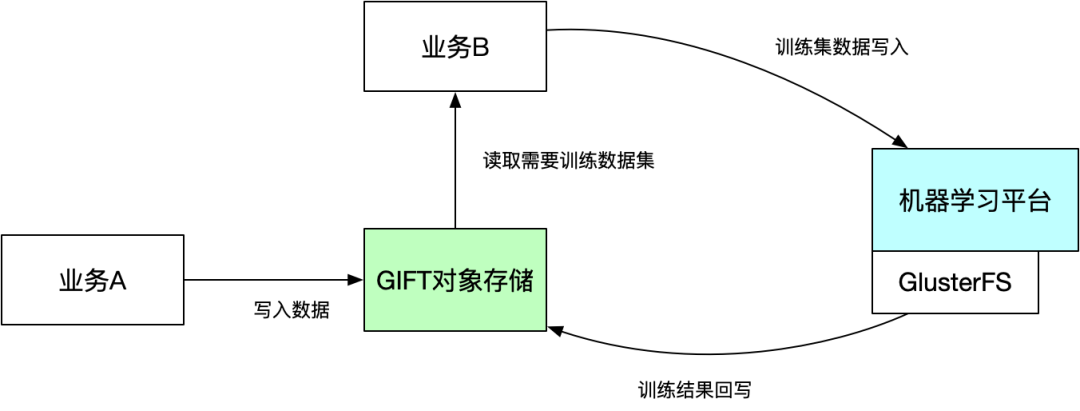
通过上面单一系统结论,发现滴滴内部的单个非结构化存储系统是不满足需求,所以我们是不是可以考虑多个系统组合支持来解决业务问题,我们的组合方案:GlusterFS文件系统 + GIFT对象存储方案 和 类S3FS + GIFT对象存储方案。
将大批量的机器学习数据存储到GIFT对象存储系统中,需要训练时,再将需要训练的数据集复制到GlusterFS文件系统中,由机器平台挂载训练。
随着训练集数据越来越多,需要复制数据集占用整体训练时间比例越来越长。
GlusterFS文件系统支持数据盘的容量也越来越不满足训练需求。
同时数据在GlusterFS和GIFT对象存储都需要各存储一份,也比较浪费空间。
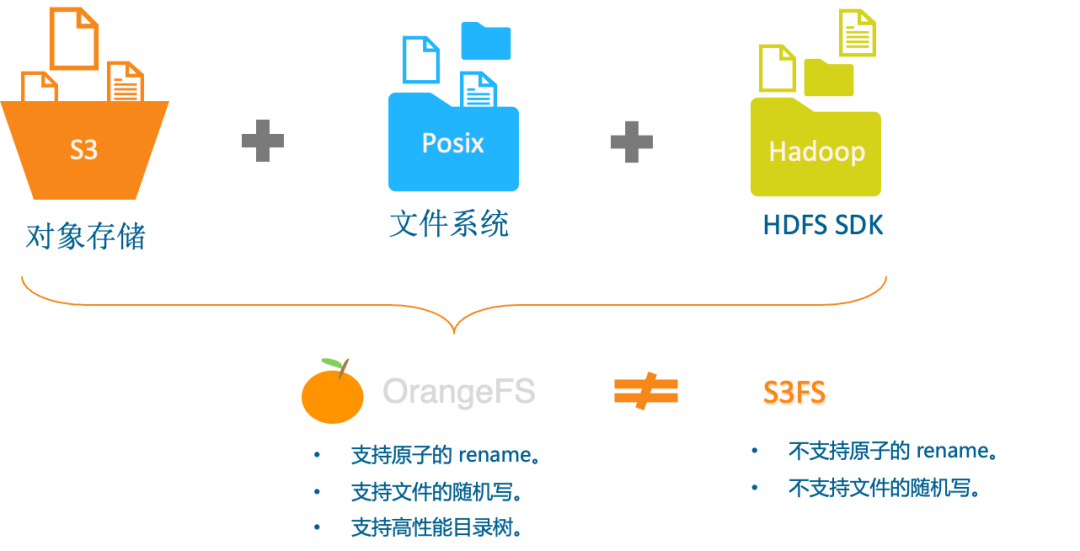
我们思考,是不是可以直接用一套系统来实现,上面实现S3和POSIX协议,这样就解决掉空间浪费和数据复制效率等问题。所以,我们就开始探索GIFT对象存储基础上直接使用类S3FS的文件系统。但又带来另外2个新的问题,即:无法提供原子的 rename 和 随机写,具体如下:
基于GIFT对象存储实现的S3FS,可以把 GIFT的 bucket 挂载到系统中以 POSIX 方式访问,但无法提供原子的 rename。例如:在test桶中有“/a/a1/a2/1.txt…”等文件,需要rename根目录下的a/文件夹为x/。
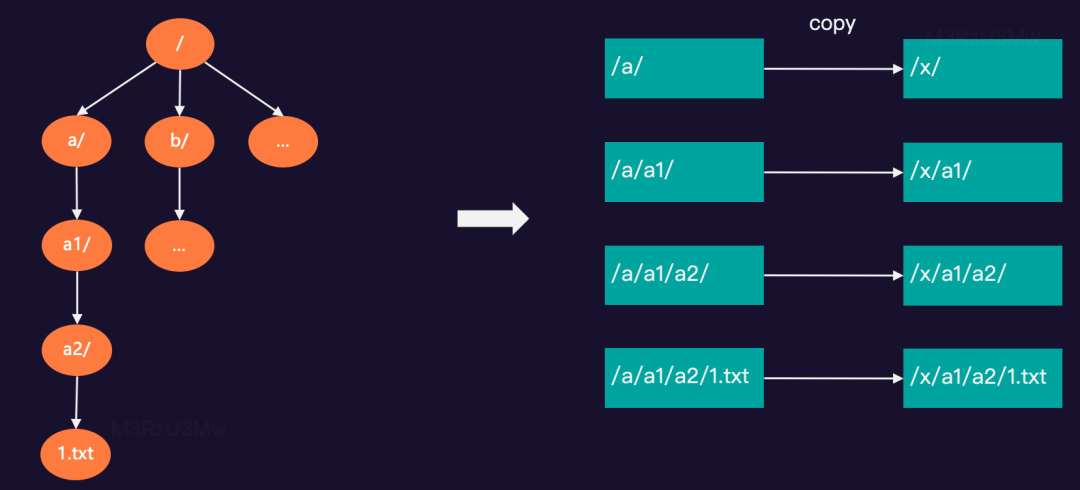
同时对随机写的操作也非常重,需要对整个先文件下载下来,修改后在重新上传到对象存储中。
探索业界方案
无论是使用已有单个存储系统,还是多个存储系统组合,都不能完美解决业务问题,所以我们开始探索业界的解决方案:Juicefs+RDS+Gift对象存储系统
JuiceFS 是个非常优秀的分布式文件系统,它兼容Posix、S3和HDFS协议,同时支持云原生。我们在社区版JuiceFS本的的基础上支持多租户、黑洞,超时、异步写等能力,满足了我们DBPROXY业务日志存储1PB左右存储需求。但应用于机器学习、大模型训练这类的场景还是有些问题,具体如下:
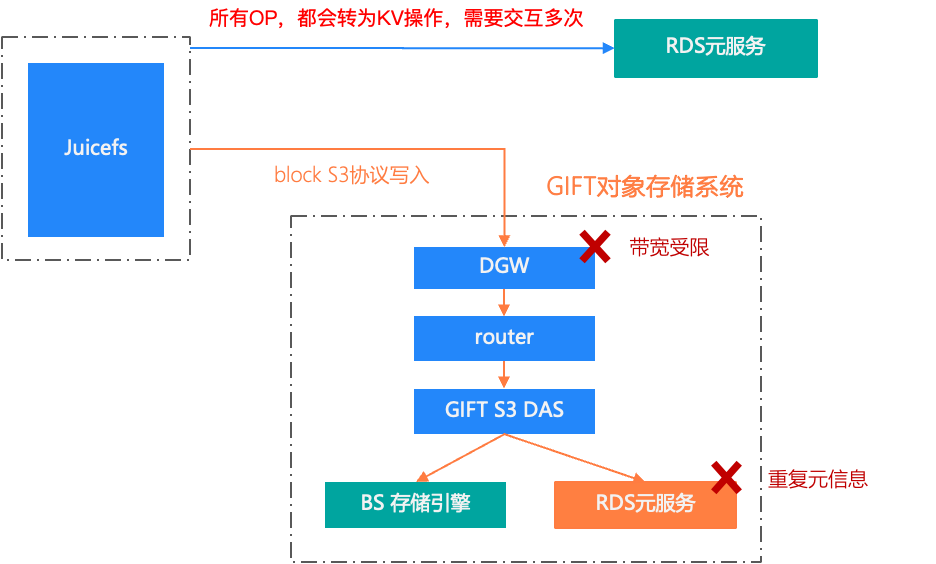
社区版JuiceFS使用RDS存储元服务,主从同步本身有延迟,所以我们使用主库写,备库读会读写不一致问题,如果直接切到主库读写压力又非常大。
所有的OP操作都会被转为KV,需要多次与RDS元服务交互,延迟相对比较高。
读写数据块的链路比较长。读一个数据块,需要经过GIFT多层才能到的BS存储引擎,同时GIFT本身也需要元服务,在加上JuiceFS元数据,就存在两份元信息。
所有流量都要经过GIFT的DGW服务,而DGW的带宽是非常有限,无法最大化的利用机器网带宽。
新一代存储
OrangeFS 新一代存储系统设计吸收探索方案的经验,同时研究并吸取了 Ceph、HDFS、CubeFS、JuiceFS、seaweedfs(Facebook haystack思想)等开源的设计思想,结合GIFT对象存储等原架构的设计思想和线上实践经验基础上演进。
复用GIFT技术
GIFT是滴滴自研的对象存储系统,从2017年接手以来,自研的2.0发版至今已支撑滴滴千亿级别大小文件存储,单桶最高达百亿级。这个系统主要由协议层、配置中心,RDS元数据、数据存储引擎等子系统组成。
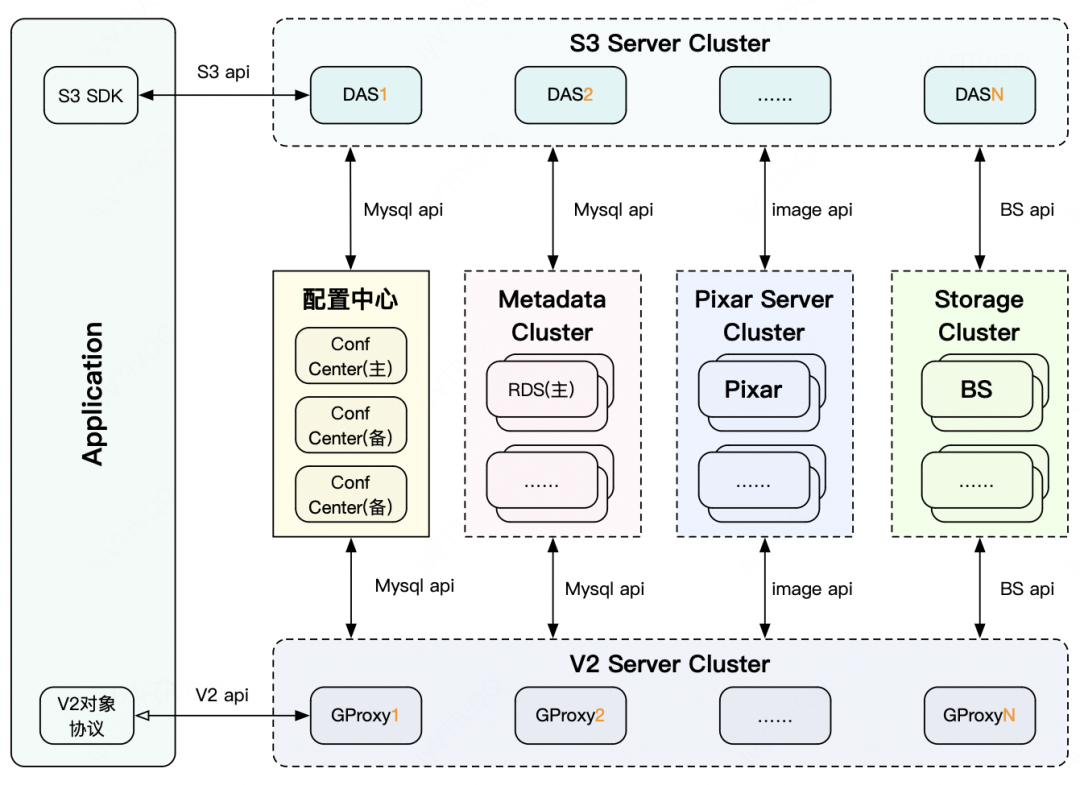
接入服务:提供S3和GIFT V2协议解析的入口服务。
RDS元数据服务:提供文件的元数据存储。
配置中心:提供租户信息、流量控制、桶信息等配置管理。
BS数据存储引擎:提供对象存储的数据分片存储。
Pixar图片处理服务:提供简单分布式图片处理服务。包括:压缩、水印、剪裁等能力。
1、是否复用配置中心

快速存储组件配置变更并自动执行,包括:QPS、流量、开关等。
统一桶命名和管理。
多租户管理,包括:密钥管理、配置信息管理。
快速扩容和管理元服务。
快速扩容和管理存储引擎。包括:禁写等能力。
一个集群管理多少个节点?如何做隔离域?快速扩容?
一个集群管理N个存储引擎分组,每个分组可以管理M台机器(可配置)。故障域为一个分组池,异常最大影响一个分组,可随时设只读,分组间数据可自动或半自动平衡。所以一个集群最终可管理N*M个节点。
一个集群可以管理N个元服务分组,一个元服务管理N个桶/卷。
无论是存储引擎还得元服务,扩容只需要配置中心插入一条记录,10秒以内生效。
元服务快速扩容:

存储引擎快速扩容:

2、是否复用S3协议
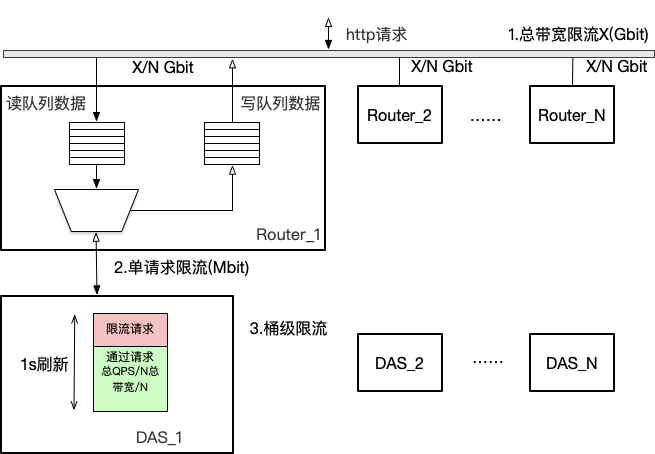
我们可以复用GIFT的接入服务设计,提供S3协议,可以节省研发周期同时又能吸取过去经验,为新服务提供稳定的接入层,包括:QoS能力。
限制总带宽和桶级带宽。
快速隔离。
容量预估,项目分等级预留资源。
桶级QPS限流。
3、是否复用元服务
从GIFT技术架构中我们可以看到元服务主要是采用RDS分库分表模式,数据分片存储采用多组BS数据储引擎进行并发分流。我们通过上传下载来理解下分库分表和并发分流,上传流程具体如下:
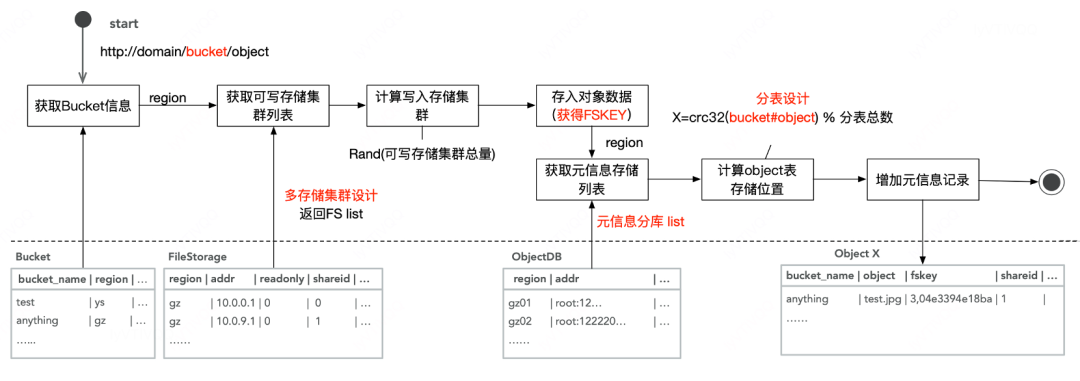

元信息分库表采用主从模式,如果全部从主库读写压力非常大,如果从从库读,那么就会有主从同步延迟问题,也就是刚写入的文件实时是读不到,产生不一致现象,所有这个就无法应用与新的架构中。
3、是否复用存储引擎
BS存储引擎是一套自研的数据分片存储系统,主要是基于facebook haystack论文件实现的。主要包含两大系统,Master server和 block server。Master server主要负责节点管理;block server主要负责数据分片存储。具体架构如下 :
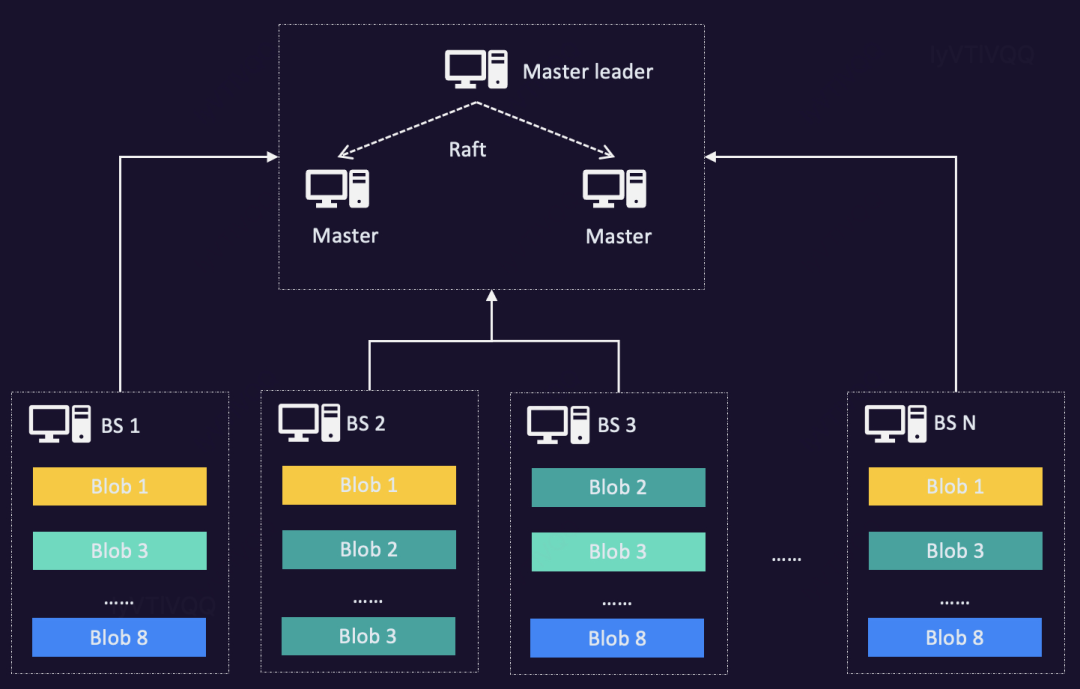
GIFT的BS存储引擎采用小文件合并,大文件分片设计。来解决小文件过多造成性能、存储空间浪费等问题。大于设定块大小的阈值时协议层需要对大文件进行切片,切到可支持的最大文件片,最后一片不限制。异步GC设计,主要是回收删除Needle时造成的空洞。

OrangeFS架构实践
解决了多租户、配置中心、S3协议层实现、存储引擎一期等能力后,我们还需要解决哪些问题?
文件存储结构需要重新设计,能支持多个协议,包括:POSIX和HDFS协议。
元服务需要重新设计,支持最终能支持千亿级别大小文件存储。
支持云原生,基于CSI插件可以快速地在Kubernetes上使用。
存储引擎一期支持完数据分块存储后,还需要继续成本和性能优化。
1、文件存储结构
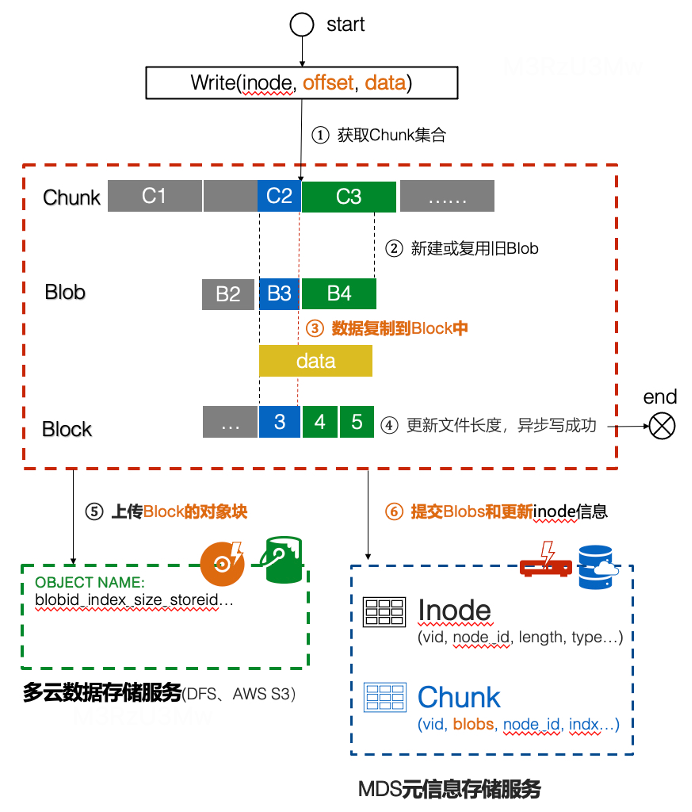
我们结合行业相关方案和复用GIFT的大文件拆块思路,把一个文件拆成多个固定大小段,提高系统读写的并发性能,我们称之为Chunk。每个Chunk内部都会存在多次写入或修改的可能,我们把每次写入或修改不固定的大小块称之为Blob(Binary Large Object)。一个Blob是由多个固定长的数据块组成,我们称之为Block。具体如下图所示:
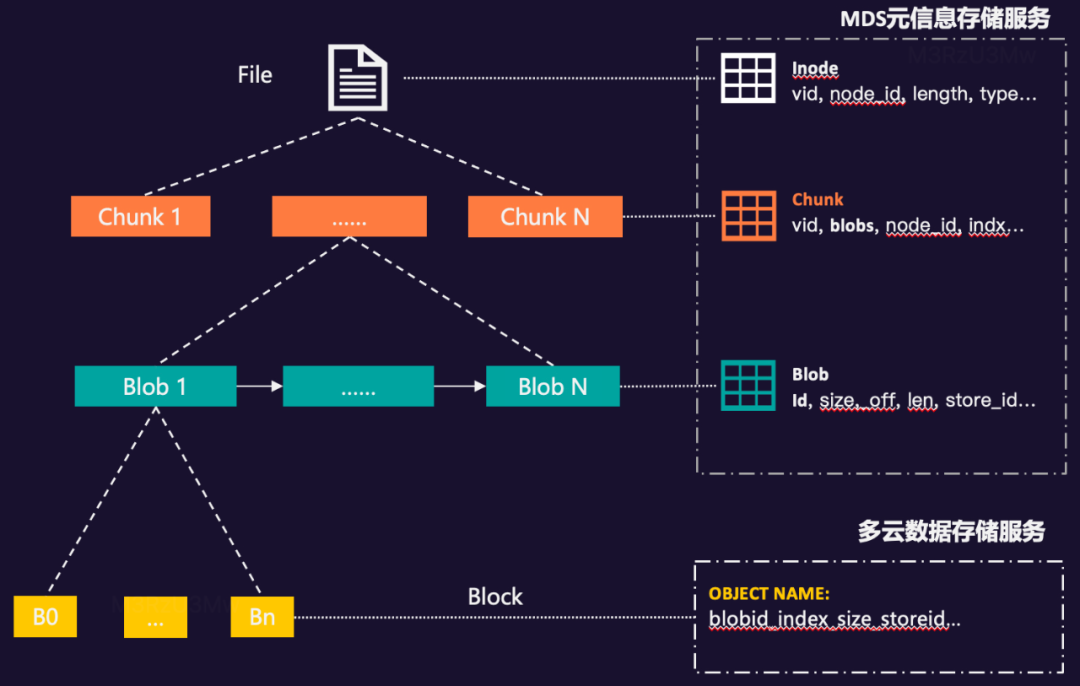
Chunk和Blob数据信息我们存储到自研的MDS元信息存储服务中,而Block分块,我们存储在自研的数据存储服务或公有云的S3、cos、oss等产品中。
A、写组织结构
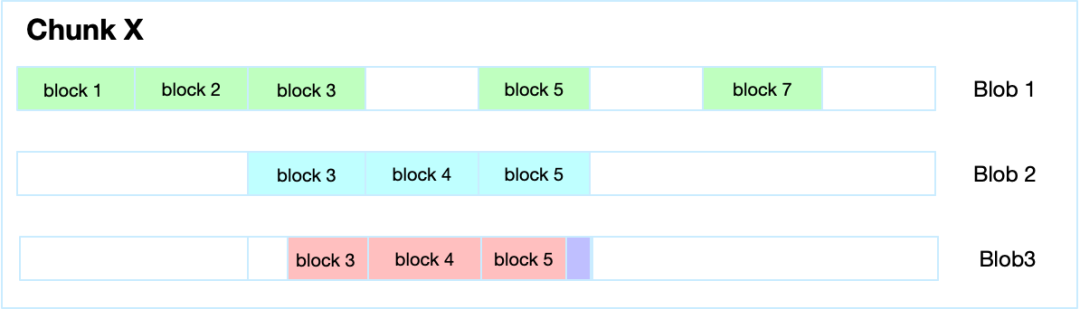
文件在写场景时,提高性能减少Blob数量,每个Chunk默认只生成一个Blob。
当业务写入或修改的内容对应的数据块与上一个Blob有重叠时,就会生成新的Blob,只要数据不重叠,那么就不生新的Blob。
当业务写入数据刚好介于block3 中间部分,那么这类场景也是生成新的Blob,来保证每次写入都是顺序写。
当业务写入的数据刚好是在Block5 数据块上,而且新写入的数据与Block 5原内容不重叠,那么可以做append操作。
数据块超过设定的值就直接提交到远程。元信息写满足后提交或超时后自动聚合的提交到远程。
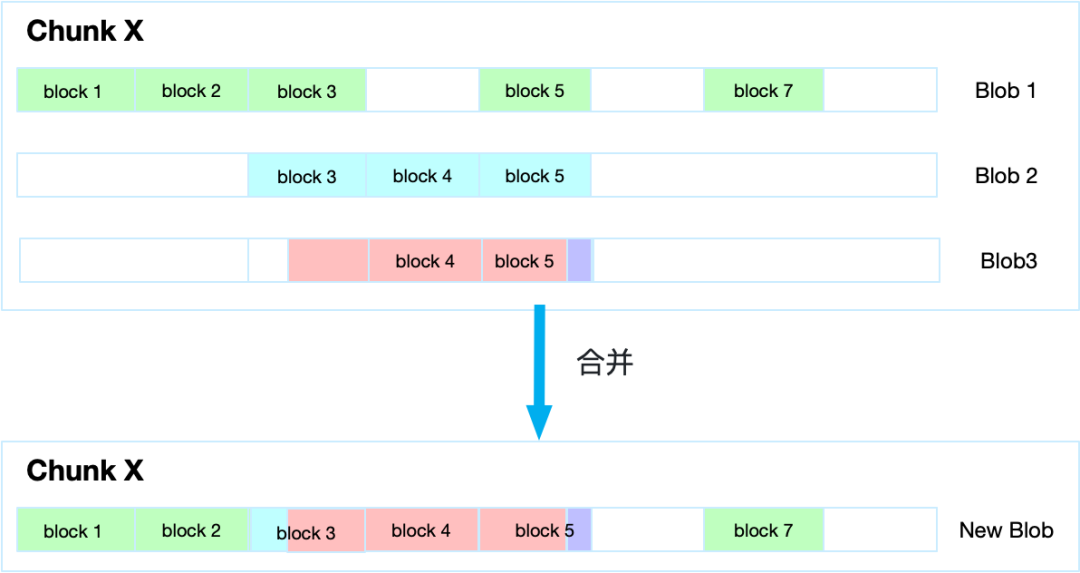
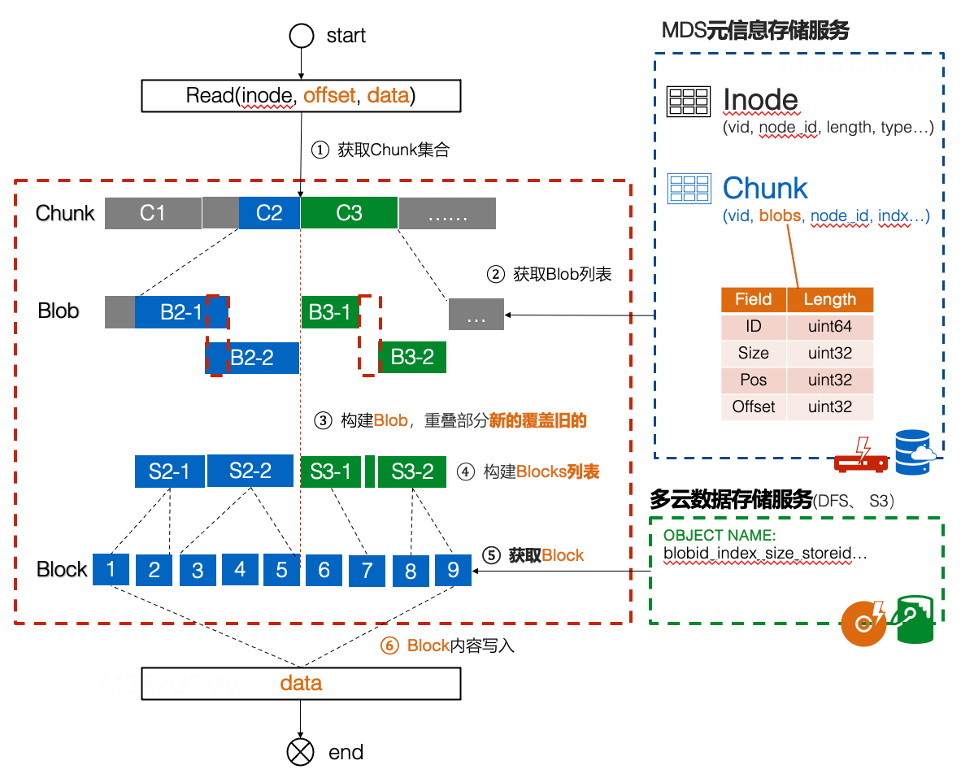
B、读组织结构
文件在读的场景时,读取到某个Chunk时,会将所有了Blob进行合并,获取到一个新的Blob,在将新的Blob对应的数据块Block返回给上层调用服务。具体如下图所示:
2、多协议融合
我们在 OrangeFS 实现上封装相对路径的VFS层和绝对路径的PathFS层。VFS提供给Posix协议使用,封装了文件所有操作接口,包括:打开、创建、读、写、同步等操作。PathFS提供给 S3、HDFS 协议使用,主要是单文件多个操作集合,例如:上传文件,就是创建、写操作集合。具体如下图所示:
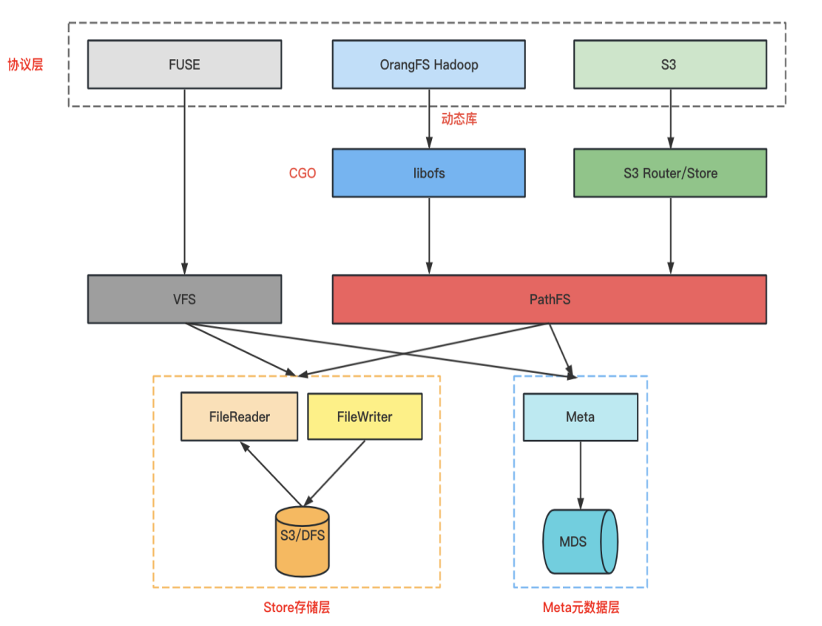
POSIX(Fuse):基于相对路径VFS层之上实现,Kernel缓存部分目录路径, POSIX Client自己缓存其余路径。
S3:基于绝对路径的PathFS层之上实现,是一个扁平KV结构。
HDFS:基于绝对路径的PathFS层之上实现,不经过内核层,所以没有缓存目录树,基于PathFS 构建Libofs动态库与SDK互通。
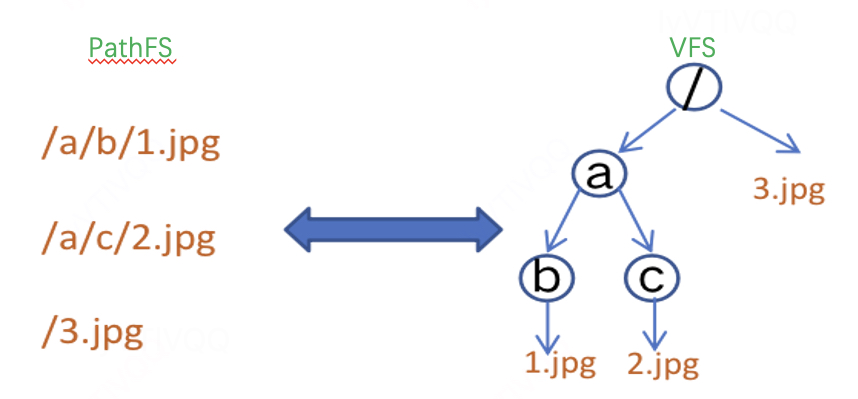
我们看下对路径VFS层和绝对路径的PathFS层区别,如下所示:
A、多协议融合写
无论使用任何协议,我们解析完协议后,都会得到inode、offset、data三个信息。具体流程如下图所示:
B、多协议融合读
读也是如此,无论使用任何协议,我们解析完协议后,都会得到inode、offset、data三个信息,具体操作如下图所示:
3、OFS链路优化
相比探索的组合方案,我们直接跳过GIFT中间所有层调用,直接把数据块写入存储引擎中,提高性能,降低链路调用的延迟,
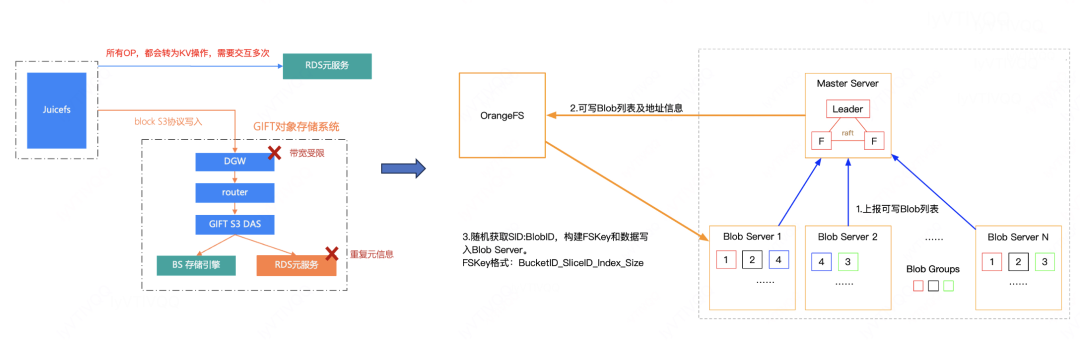
4、MDS元服务
MDS元服务存储服务主要提供元信息、配置信息存储服务。主要包含ROOT SERVER、Meta Server、PD等子系统。具体如下图所示:
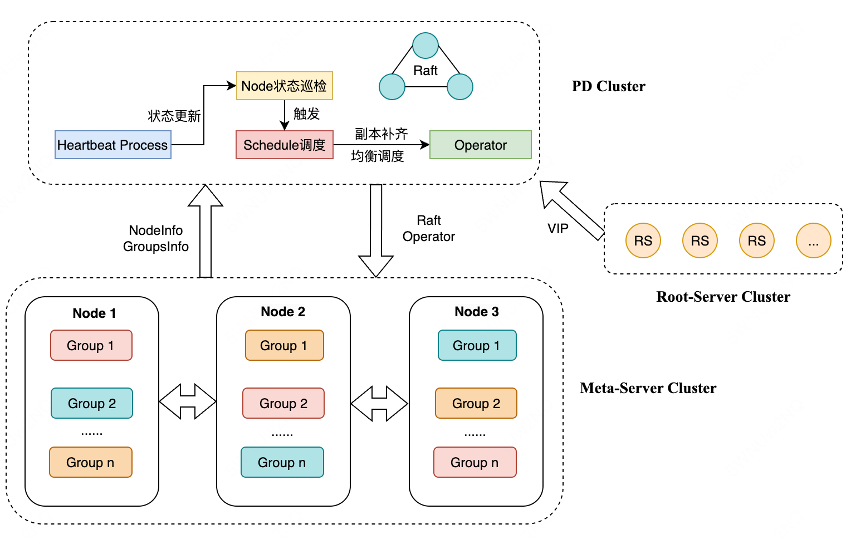
Root Server:是个无状态服务,提供中心化的配置管理服务、快速存储组件扩容配置、变更自动执行,包括:QPS、BPS、开关、桶/卷的信息、多租户信息等管理。
Meta Server:元数据存储服务,提供元数据存储和目录树服务。
每个桶/卷 一组或多组 MS服务集群提供服务,每组 3+1 模式,保证快速恢复,减少毛刺。
本地引擎通过MULTI-RAFT、RocksDB进行数据一致性数据存储。
支持内存目录树和 inode cache提高S3或HDFS性能。
内存事务保证并发正确性。
PD Server:提供统一的Raft管控和调度服务,支持自动副本补齐、热点均衡、平滑升级等能力。
A、MDS元服务结构
我们的MDS元服务结构,一个用户可以申请多个桶或卷,每个卷或桶是由一组RAFT或多组RAFT提供服务(子目录分区),如下图所示:
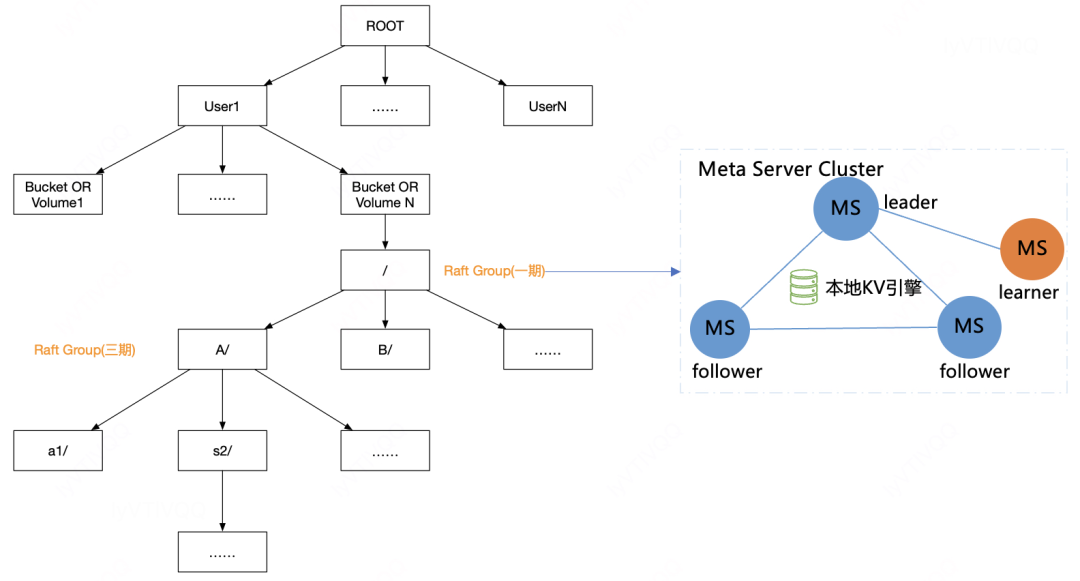
一期,不同桶或卷一组raft group支持,但只能Leader读写。
二期,我们支持桶或卷一组raft group支持,支持全部节点读写。
三期,我们支持桶或卷的子目录分区,也就是一个目录级别raft group的读写
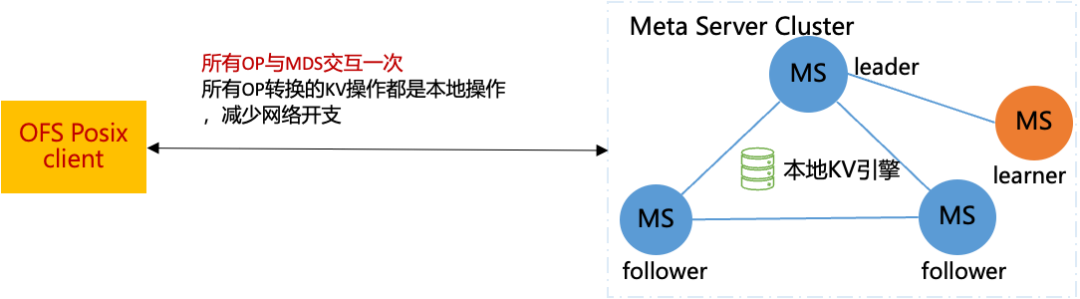
B、降低MDS延迟
我们客户端或S3或HDFS服务的操作只需要和MDS交互一次,所有的操作转换为本地KV操作,减少网络多次交互的开支。
5、POSIX客户端
OFS Posix是基于 fuse 的文件系统客户端,完全兼容Posix协议,具体如下图所示:
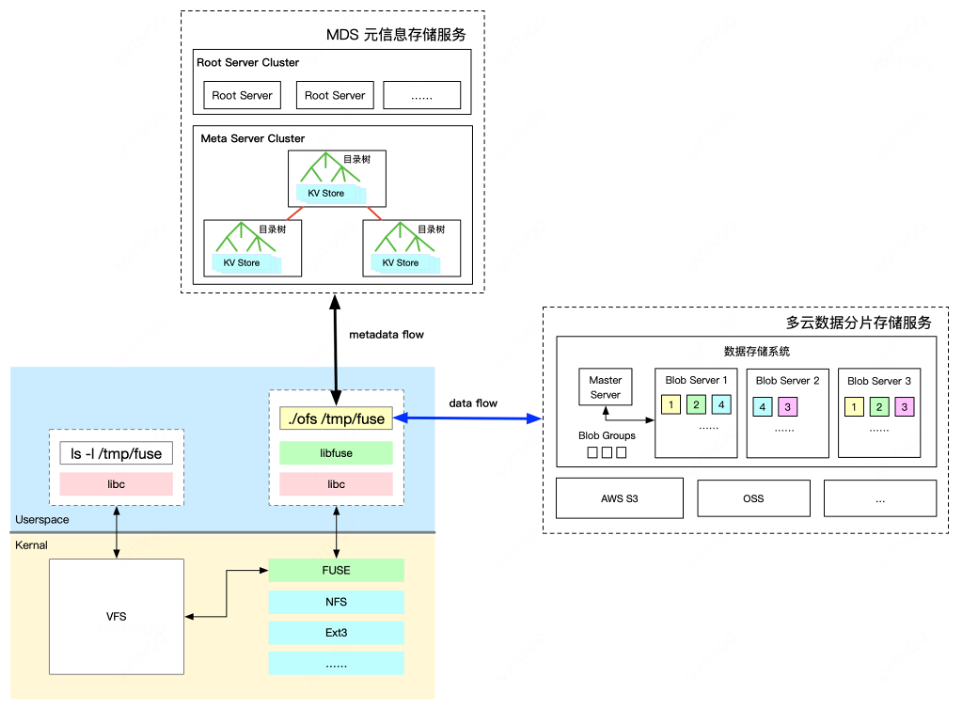
接收与处理 FUSE 的操作请求,与MDS Cluster 交互实现文件元信息的增删改查及管控操作, 与自建IDC的BS数据存储引擎或公有云OSS/S3/COS等系统交互实现文件分片数据的增删改查。
支持卷级的QoS,包括:带宽、QPS、黑洞等能力。
支持元信息缓存和数据缓存以提高性能。
支持秒级热升级能力,解决K8S紧急BUG或新功能无感上线问题。
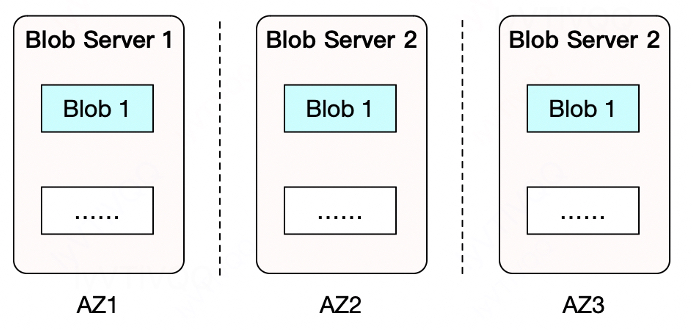
6、数据冗余
多副本系统在单AZ部署下,只要集群失效了,那么数据全部不可用。
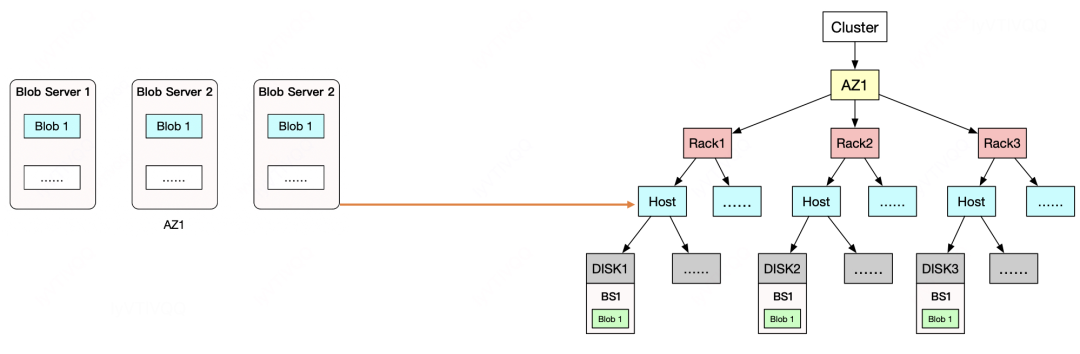
多副本的3AZ部署模式最多可容忍2个AZ挂掉。
3.3 最终落地和收益
GIFT和OFS非结构化存储技术已覆盖全公司所有业务,其中OFS快速成长,已接入几十PB,包含机器学习、大数据、金融、国际化等业务。OFS具体架构如下图所示:
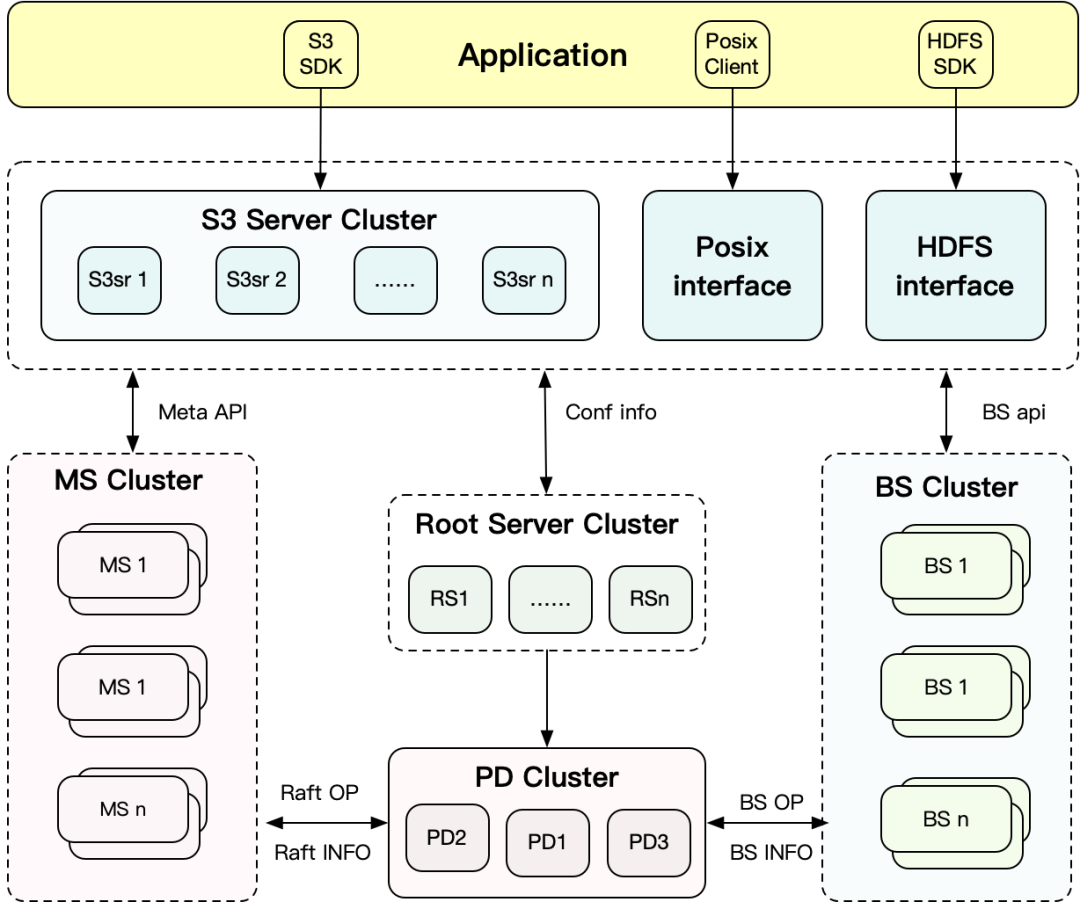
支持无损多协议融合,包括:POSIX、S3、HDFS等多存储语义。
支持多租户,集群支持千亿级文件存储,单桶/卷支持最高百亿级别文件存储。
自研MDS,支持 MultiRaft、内存事务、动态调度等技术。
支持OFS POSIX客户端秒级热升级技术
支持多公有云架构技术
支持全新的QOS能力,包括:黑洞,超时、异步写等特性。
支持回收站能力。
支持数据内容加密、压缩等能力。
踩坑之旅
在机器学习训练的过程中,随着用户规模、数据量持续增长,不同阶段也踩了很多的坑。
第一阶段,初步接入机器学习训练,数据量PB级别,小文件很多,MDS元服务便成为瓶颈,主要从低延迟、正确性、扩展性、稳定性 4个方面来看看踩坑实践。
第二阶段,机器学习训练持续铺量,数据量数10PB级别,大小文件都有,文件系统客户端吞吐便成为瓶颈,主要从高吞吐、读写解耦、Client数量多3个方面来看看踩坑实践。
第三阶段,已经有一定规模,数据量近百PB级别,使用团队比较多,主要从权限隔离、收站两个方面来看看如何支持多团队高效协作。
4.1 MDS元服务
1、低延迟
研发测试完成,接了一些试点小流量,机器学习训练场景准备小规模放量,业务经常反馈训练抖动和读取慢,元数据整体延迟更是抖到秒级别,CPU内存、Meta延迟等电话报警不断,苦不堪言。训练也要求元数据延迟要小于10ms,所以我们通过Profile、性能压测、Micro Benchmark等一些工具进行了全链路性能分析和优化,发现问题比较多。
比如:Goroutine数10W太多,核心Goroutine得不到调度;Raft Propose仅仅入队列延迟高到100ms,Raft写入完成需要 300ms,Golang Runtime消耗整机CPU 45%等。
链路上:最开始Client一个OP会和MDS做多个RPC;优化为一个OP一次RPC,产生的读写KV都在本地执行,精简链路。
架构上:最开始GRPC收到请求之后,每个请求都占用一个Goroutine。10W 只读请求会有10W Goroutine 并发读KV;写请求并发Propose,串行Commit日志,串行Apply,Apply的时候执行OP,由于Apply串行执行OP,而且每个OP大小不一,有读有写,一个OP慢,那么整体Apply就慢,进而导致Raft Propose整体延迟升高。优化为队列+线程池模型,同时Raft Apply串行执行OP ---> Raft Apply 直接保存OP KV 结果,在Propose前并发执行OP。
网络上:GRPC换成TCP,队列+ Async Batch收发包,相同QPS情况下,CPU降低一半。
Raft上:在其串行本质的基础上通过Batch+Pipeline提升吞吐降低延迟。
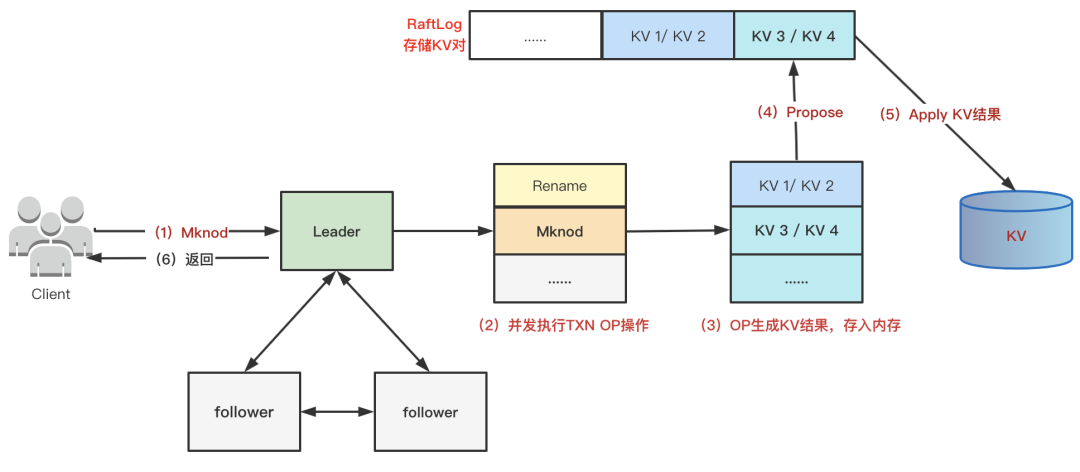
2、正确性
延迟高问题解决之后,接踵而来的是数据读错,目录结构乱了。并发不一致、Read一次EIO、脏数据都会导致训练了几天的任务中断作废,需要重跑。
比如并发的 /a 目录下创建文件和删除 /a 目录,最开始的时候OP是串行执行的,不太用考虑并发问题,现在并发执行OP了,有可能出现在进去 /a 目录里面之后,创建文件的同时把目录删除了, 就可能会出现 在给用户反馈创建文件成功之后,用户看不到这个文件,成为孤儿节点。
有4种方案解决并发问题:
方案一:全串行,不可取延迟高
方案二:像CpehFS那样对文件目录等加读写锁,实现难度高,易出错。
方案三:像支持客户端分布式事务,但延迟高,难度大。
方案四:实现单机服务端乐观事务。我们最终支持单机服务端内存事务 + Write 串行。即对于冲突比较高的POSIX Write和S3 Put操作,同个文件通过Hash到同一个队列的方式串行执行。
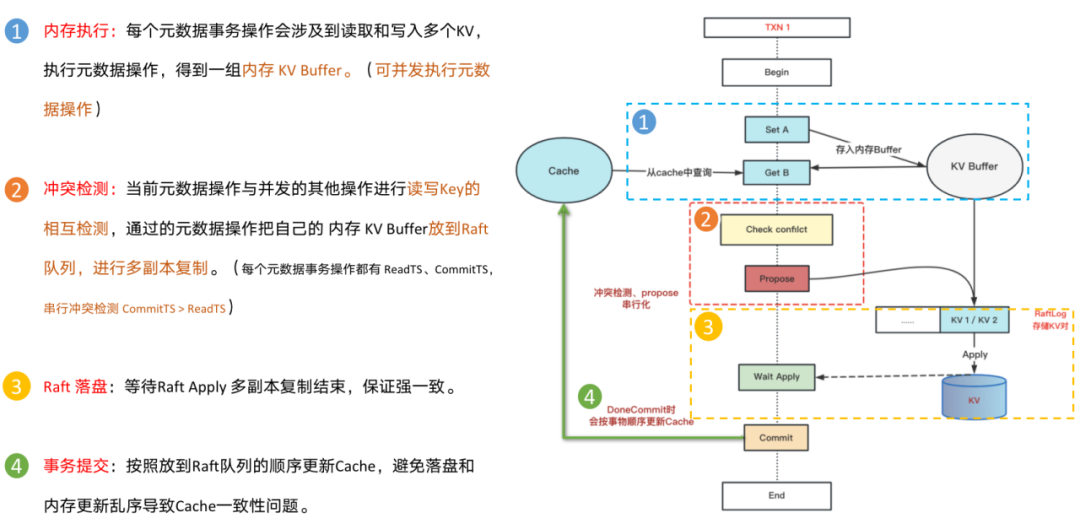
内存事务分4步:
第一:并发内存执行,每个Txn OP操作都会涉及读写多个KV,执行Txn OP,内存得到一组待更新的KV buf。
第二:串行冲突检测,每个Txn在开始的时候有一个ReadTs,提交的时候有一个CommitTS,当前的Txn和其他正在提交的Txn进行读写Key的重叠判断。
第三:Raft落盘:等待Raft apply多副本复制结束。
第四:更新Cache:保证KV落盘的数据和更新Cache的顺序是一致的。
3、扩展性
有了一点规模之后,大约几个PB的量,延迟高问题又出现了,线上训练有个Volume 30W qps 的Read,导致Leader机器CPU掉底,延迟飙升到秒级别。因为读写都在Leader,即使我们有2个Follower 和 1个Learner,也是一台机器在抗,一台有难,3台围观。
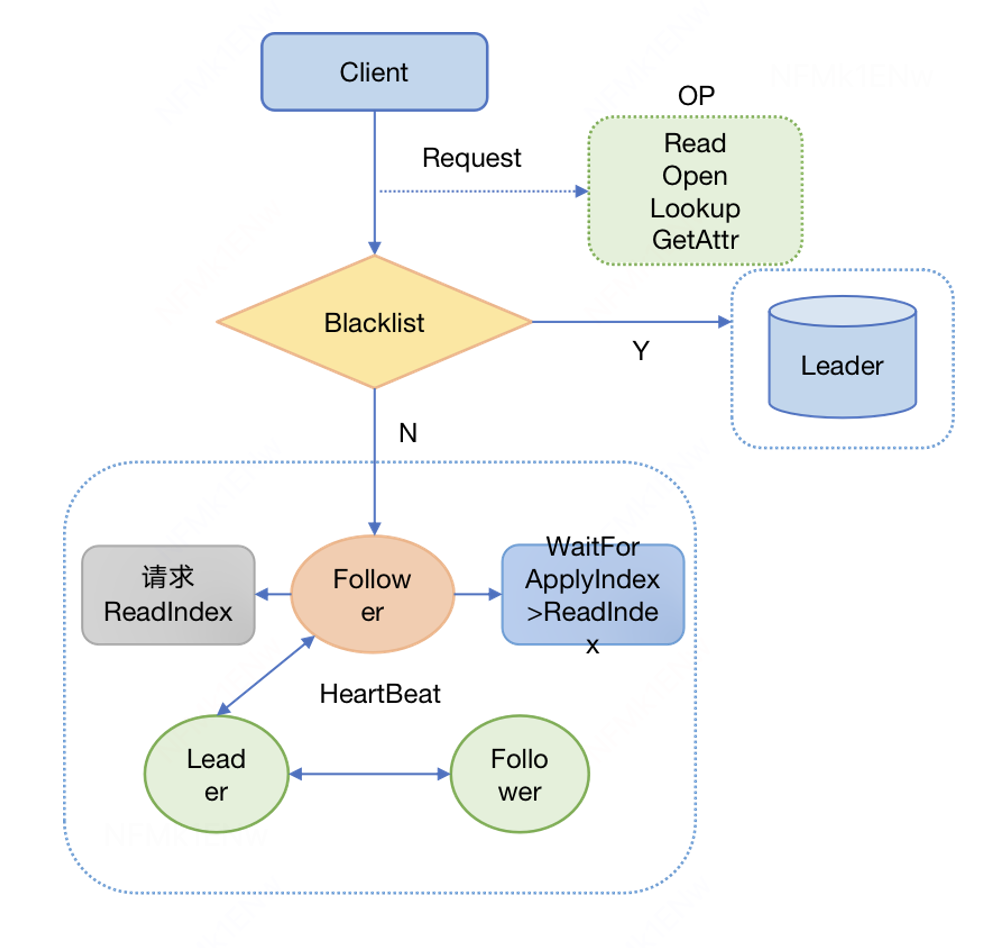
迫切的需要其他节点也提供读的能力,我们支持了OP粒度的Follower Read,可以通过扩充Learner来提供读能力。
实现上,Follower读的时候,会先从Leader拿取CommitIndex作为自己的ReadIndex,然后等待自己的ApplyIndex >= ReadIndex的时候,就可以提供线性一致性读。
服务端:
支持ReadIndex线性一致性读,以及Cache一致性。
支持Follower和Leader的LogIndexGap来动态开关Follower Read。
客户端:
管理多个节点的TCP连接池,有黑名单、重连等机制。
管控侧:
单节点和Volume粒度动态开关Follower Read。
运维侧:
1 Leader + 2 Follower + 1 Learner。
扩容Learner来提升读能力。
4、稳定性
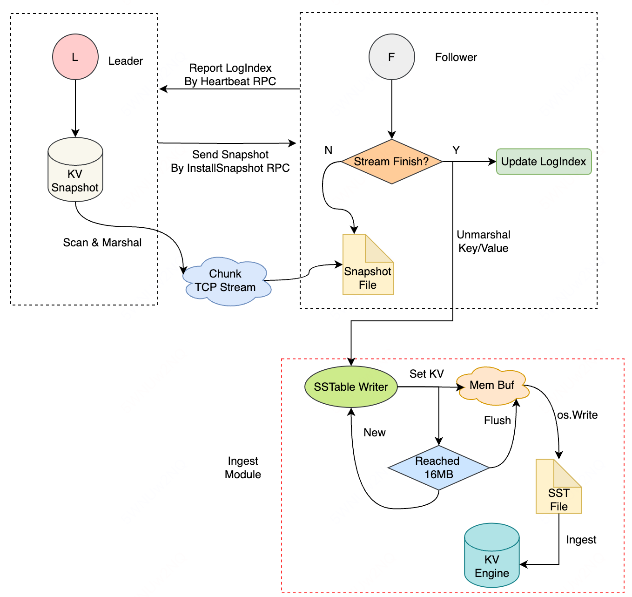
有天线上磁盘容量90%报警,部分Follower 写入失败,对线上倒是没有影响,排查发现,是因为Leader持续不断地给Follower 发送快照,导致Follower 磁盘爆满。
Leader给Follower恢复数据是先恢复存量快照,再恢复增量Log;当时单组Raft写入8k/s,Leader给Follower发快照的过程中,由于写入量大,Leader的Raft Log就做Compaction了,Leader发完快照准备发增量Log数据的时候,发现之前的增量Log数据已经被Compaction变成快照了,于是又会开始发送快照,循环往复,进而死循环,导致一直发快照。
同时也暴露了不少问题:
第一:最开始是KV粒度恢复数据的。改成了Ingest SStable的方式恢复数据。
第二:Log Compaction阈值配置很死板,不太好明确配置多少,跟写入量有关系。所以快照恢复期间暂停Log Compaction,同时带有超时,防止无限发快照。
第三:Follower恢复时触发Leader限流,因为Leader不感知Follower Recover状态,所以需要感知Follower状态,隔离限流影响,避免影响正常Propose。
第四:MultiRaft共用资源池,一个Volume有问题,影响到全局的Volume。所以支持了Busy和Slow队列,有问题的Volume放进Busy队列,延迟高的OP就放进Slow队列。
5、高效Meta
回过头来看,有两个高效的元数据设计也帮我们少踩了很多坑。
第一是高效Rename:
POSIX/HDFS的文件结构是一个目录树结构,以父目录ID+文件名相对路径作为Key。
S3是一个扁平KV结构,以绝对路径作为Key。
绝对路径缺点在于Rename开销大,但是S3路径解析高效。
相对路径Rename快,但是解析S3绝对路径的时候需要层层解析,所以我们支持了目录树缓存。整体采用相对路径。
第二是高效Readdir:
文件结构类元数据主要有Dentry和Attr,Dentry是目录结构信息,Attr是文件元信息。每个文件都有Dentry和Attr。文件系统硬链接只是文件名字不一样,即Dentry不一样,但是Attr是一样的。
Readdir大多数都需要把Dentry和Attr都列出来,没有硬链接的话,完全可以把Dentry和Attr合并成一张表存储,一次Scan KV就可以。那有硬链接的时候,如何高效兼顾硬链接以及Readdir呢?
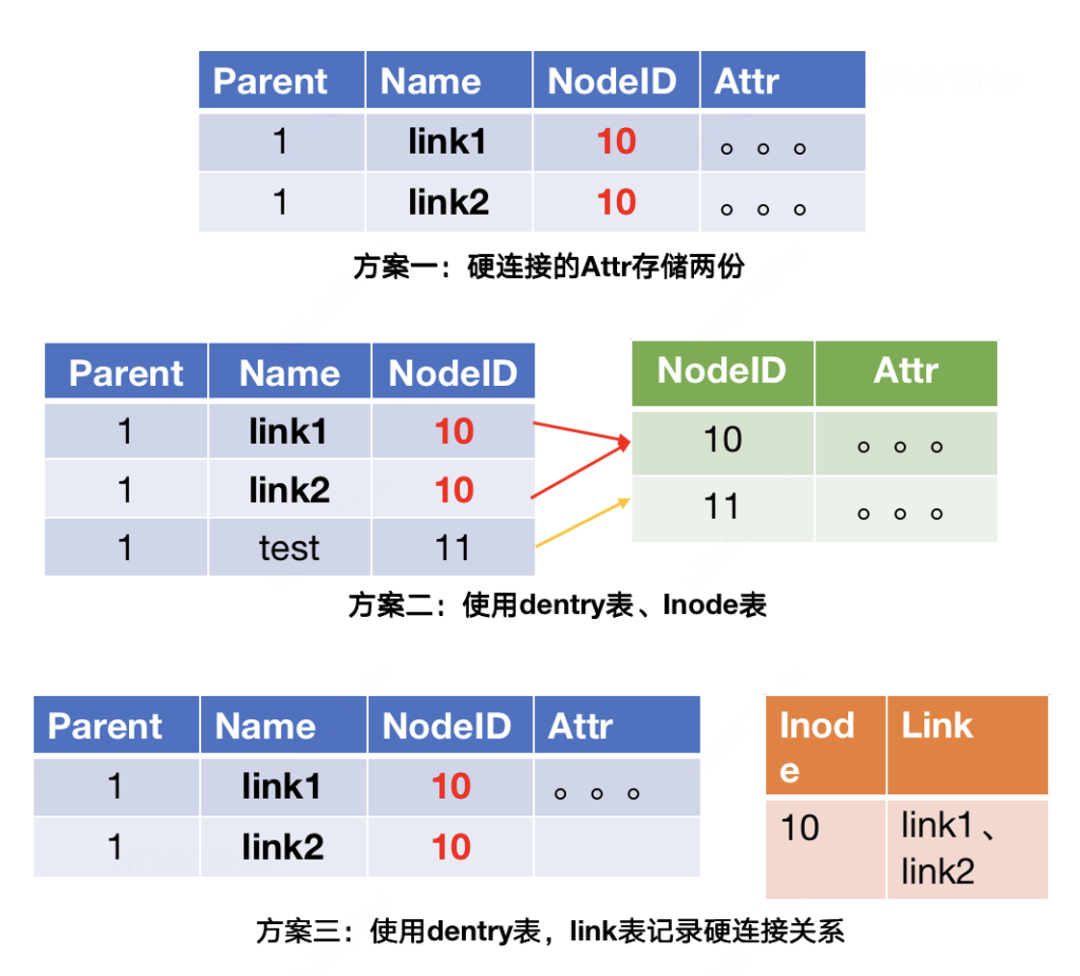
方案一:一张表存储Dentry和Attr,存储多份,有几个硬链接就有几份。
方案二:Dentry和Attr分开,硬链接都在Dentry,共用的一个Attr在Attr表。结构比较清晰,但是Readdir的时候,需要一次 Scan Dentry + N次点查 Attr,性能差。
方案三:Dentry和Attr合并存储,Link表记录硬链接信息。Readdir 一次 Scan Dentry即可,缺点是实现比较复杂,查询硬链接需要两次,先查Link表再查Attr表。
线上使用硬链接的场景很少,所以采用方案三,达到即支持硬链接,又可以一次Scan 高效Readdir的目的。
4.2 POSIX客户端
1、高吞吐
OrangeFS POSIX挂盘训练提供元数据和数据的缓存能力,尽量Cache住所有的元数据和大部分数据,最大化吞吐,整体可以体统数十GB/s的带宽,高效的支持机器学习训练。

2、读写解耦
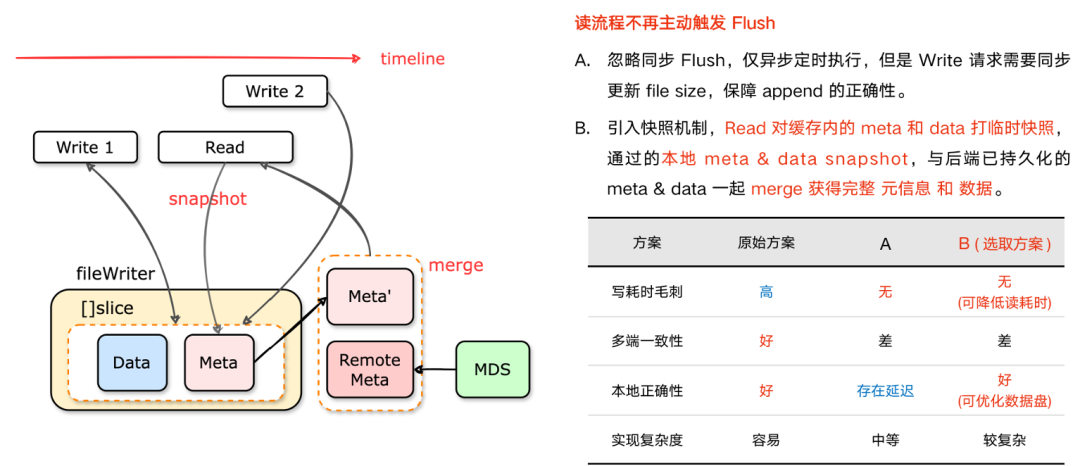
线上有用户反馈对同一个文件边写边读的时候,读写都会发生卡顿,影响正常使用。分析之后是因为目前读写使用同一把锁,而且读的时候会先把写到内存缓存Buf的数据主动Flush到远端存储,数据可见,才读取元数据,进而读取数据。也即读写会加锁等待刷数据,锁里面有IO流,自然就很卡顿。
所以需要像文件系统的PageCache那样,做到读写解耦,互不影响,所以我们支持了轻量级内存快照。
3、热升级
随着OrangeFS POSIX文件系统在线上的铺量,已经达到了数万个POSIX Client,对于版本管理也提出了新的要求,需要支持热升级,避免版本管理导致的业务IO中断。
线上运行态版本众多,收敛版本需求强烈。
客户端升级流程复杂,用户侧的影响大。
Client 数量巨大,急需解决 可维护性 的问题。
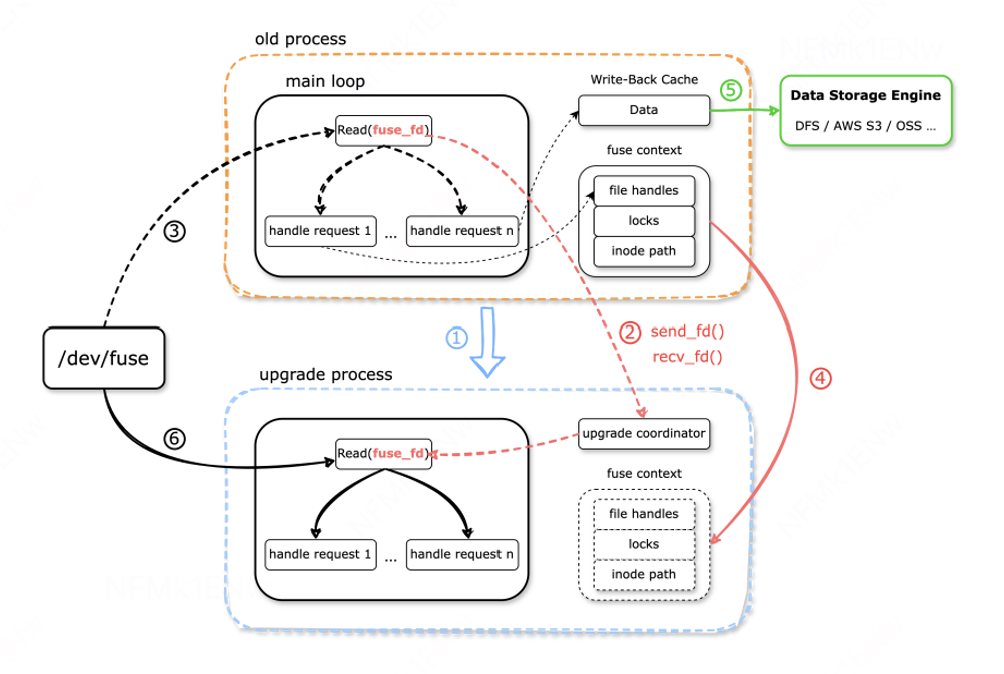
OrangeFS-POSIX热升级 流程步骤:
老进程 Exec拉起新进程,准备热升级。
老进程 向 新进程发送 fuse 设备fd。
老进程 停止接收/dec/fuse请求,并等待Inflight请求完成。
老进程 向 新进程 发送 上下文。
老进程 Flush缓存数据后退出。
完成热升级,新进程接管所有请求。
多团队协作
1、OFS权限隔离
机器学习训练通常是多个团队共享同一个Volume,生产团队生产数据,消费团队训练,以及数据是有时效性的,过期之后就没用可以删除了。
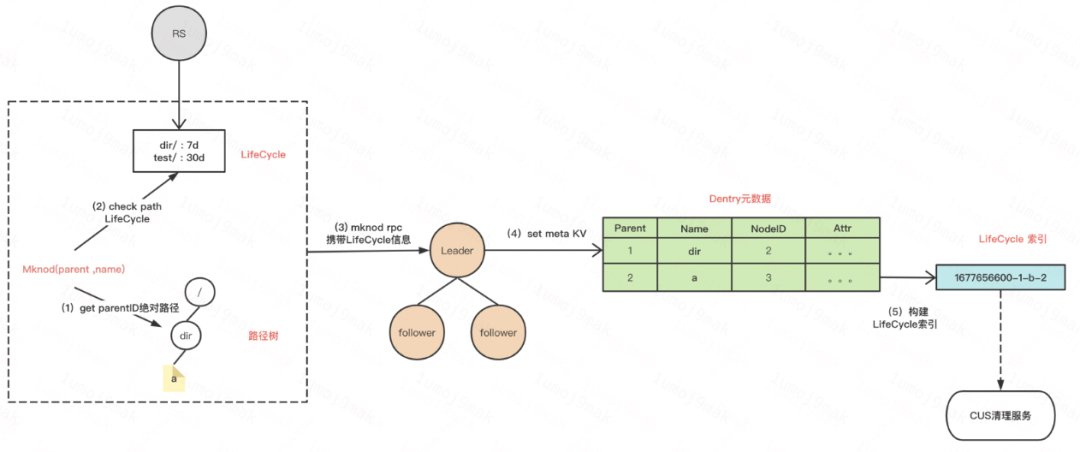
我们支持子目录TTL能力,自动删除过期文件,在界面配置即可。实现方式有两种:一种是定期扫描,一种是建立索引。考虑到定期扫描元数据开销大,所以我们在创建文件的时候同时根据创建时间戳构建KV索引,CUS清理服务后台扫描时间戳索引清理过期文件,提高稳定性且体验好。
OFS支持S3 Lifecycle规则并且做了拓展,整体基于Lifecycle来管理子目录需求。
TTL文件过期删除:支持子目录级别的过期数据删除。比如机器学习训练在界面上 配置 /user/didi/ 30天之后自动删除数据。
Readonly:支持Bucket/Volume粒度的只读,以及子目录粒度只读。比如训练通过S3接口在某个子目录生产完数据之后,设置只读。
权限管理:S3 AK/SK 认证、POSIX、Mknod、Read、Write OP粒度管控。
2、OFS回收站
那么误删除的数据可以恢复吗?其实是可以的,删除的文件会被放到回收站。OFS有隐藏的系统目录,Trash目录就是存放用户删除的文件,expire目录存放TTL过期的文件,提供回收站的能力,这些都是元数据操作,不涉及数据操作,回收站默认保留7天,过期之后,CUS并发的删除数据和元数据。
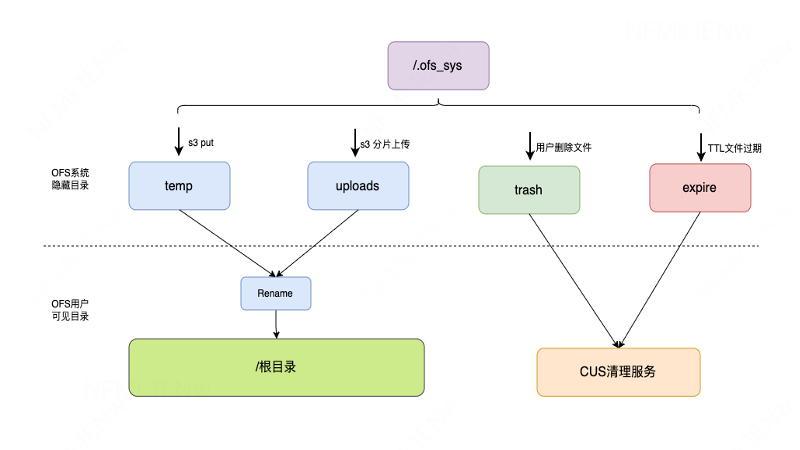
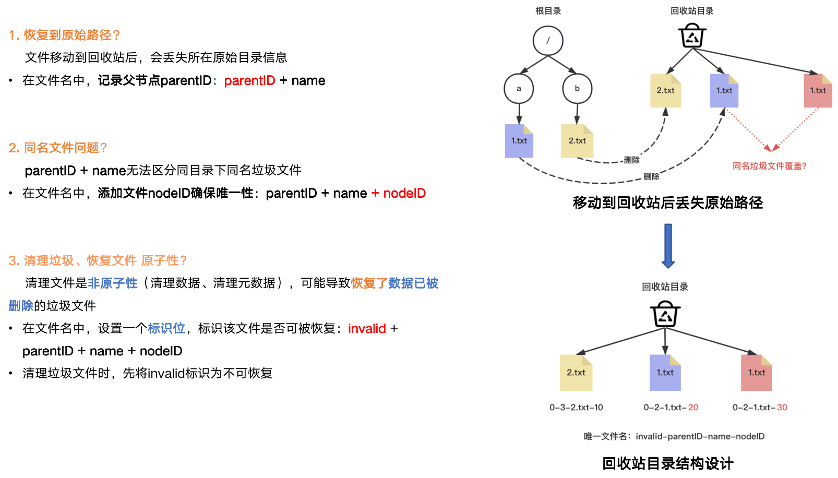
回收站怎么做呢?回收站的文件目录结构分两种:一种是扁平KV结构,一种是目录树结构。考虑到实现的复杂度,我们支持扁平KV结构,会带来三个问题:
第一:会丢失原始目录信息,所以垃圾文件名通过记录父节点ID + 自己文件名可以恢复到原始路径。
第二:无法区分同目录下同名垃圾文件,所以垃圾文件名还需要记录自身Inode号。
第三:清理垃圾文件的同时恢复该文件,导致数据不完整。清理文件是非原子操作(先删数据再删元数据),但恢复只操作元数据,可能导致被恢复的垃圾文件 数据被CUS清理删除了。所以需要加上invalid标识,清理时标记不可恢复。
所以最终回收站文件名字包含 invalid-parentID-name-nodeID四部分组成。
恢复好用吗?其实是不好用的,最开始需要遍历回收站,帮用户一个文件一个文件的恢复,费时费力,非常痛苦;之后支持了子目录录递归恢复、可以恢复根目录下某个时间点之前的所有文件,已帮助用户恢复数百万个文件,真正的帮助到多个团队协作。

相关内容此前已进行直播,欢迎关注「滴滴技术视频号」查看相关回放,有听有看,不容错过!公众号回复0829,可获取PPT课件材料。
















 207
207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









