






 本文探讨了如何使用rsyslog模块和模板统一不同来源的日志格式,以便于日志分析。通过定义模板,实现了日志内容的重新组合和关键信息的提取,简化了Logstash中的grok解析过程。示例中详细展示了针对nginx日志的处理,以及如何在Logstash中利用ruby过滤器进一步转换日志格式,提高了日志处理的效率和准确性。
本文探讨了如何使用rsyslog模块和模板统一不同来源的日志格式,以便于日志分析。通过定义模板,实现了日志内容的重新组合和关键信息的提取,简化了Logstash中的grok解析过程。示例中详细展示了针对nginx日志的处理,以及如何在Logstash中利用ruby过滤器进一步转换日志格式,提高了日志处理的效率和准确性。
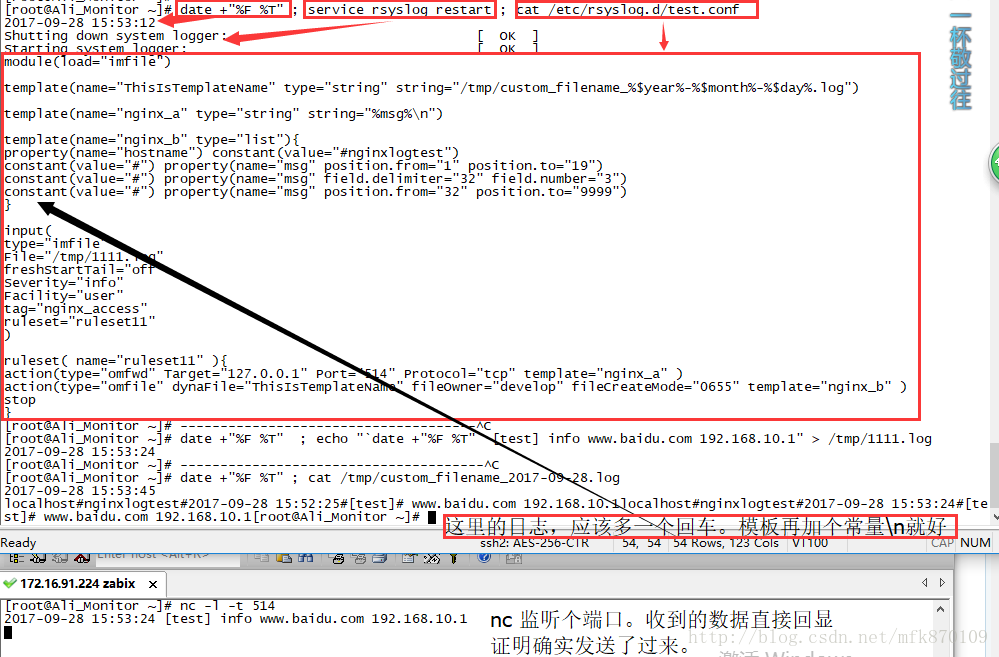
# vi /etc/rsyslog.d/test.conf
module(load="imfile")
module(load="omfile")
#使用到什么模块,加载
template(name="ThisIsTemplateName" type="string" string="/tmp/custom_filename_%$year%-%$month%-%$day%.log")
#定义一个模板。首先是模板名字。模板的类型2种:1是字符型string,2是列表型list 。 最后是omfile 将处理好的事件(一条日志)输出到哪个文本中。变量rsyslog 内置的。
template(name="nginx_a" type="string" string="%msg%\n")
#再定义一个模板。第三个参数调用变量,%msg% 就是rsyslog 读取到的一条日志(事件)。
#就算是tomcat之类的日志,如果你rsyslog用了多行规则,那么多行合并后就是一条日志(事件)嘛。
template(name="nginx_b" type="list"){
property(name="hostname") constant(value="#nginxlogtest")
constant(value="#") property(name="msg" position.from="1" position.to="19")
constant(value="#") property(name="msg" field.delimiter="32" field.number="3")
constant(value="#") property(name="msg" position.from="32" position.to="9999")
}
#定义第三个模板,这就是列表型的模板。property 这个应该是变量的意思。constant这个是常量。
#举例,如果一条完整的日志是括号中的内容【2017-09-28 10:36:21 [test] info www.baidu.com 192.168.10.1】
#property(name="hostname") 这个就是linux命令hostname得出的值。取到主机名。。。假如是nginx-server
#constant(value="#nginxlogtest") 常量嘛。就是双引号之内的值。
#第三行property,msg 就是这一条日志,这里不用%号,position.from position.to 就是从第几 到 第几 个字符。2017-09-28 10:36:21 包括空格,19个。
#第四行property,field.delimiter 字面意思:字段(域) 间隔符。msg这条日志,以ascii码32 ,就是空格,为间隔符,第三个字段(域)。就是 [test]
#第五行property,日志中的info 这个给跳过掉了,从第32个字符开始起算,也不知道日志会有多长,直接9999 , 长度随便写。
###最后### 这就是在拼接一条新的日志(事件),会拼接成如下,以#号分隔开的新内容:
nginx-server#nginxlogtest#2017-09-28 10:36:21#[test]#www.baidu.com 192.168.10.1
特别说明一下,nginx日志是可以自定义生成的格式的。所以第三个模板再好的不太合适了。而以nginx也有个$hostname的变量,生成日志就自带了hostname。而$host变量则记录访问的域名(主机头)
信息相当丰富。完全可以一条日志,就定位到是哪一台机器,哪一个域名的访问状况。第二种模板就可以了。而我们不就是想要看到一条日志,就可以轻易定位到某某个日志文件中去。
对于非nginx的其他日志,第三个模板就相当合适。而且,重做成#做间隔符,在logstash 中就不需要写蛋疼的grok。要简单很多。
input(
type="imfile" #使用的是infile模块,下边的参数,都是这个模块的参数。
File="/tmp/1.log" #采集哪个文本
startmsg.regex="^2017" #多行匹配,遇到2017开头的行,包括它之后,所有非2017开头的行,合并成一行。合并时的间隔,是\n 。 可以通过tcpdump抓包,a行跟b行合并后,中间是\n。
startmsg.regex="^\\[" ##双斜杠!!! 就是中括号开头。多写个例子,可不是说让你同时写二个。
readTimeout="60" #多行匹配超时设置。新的2017开头的日志进来,上一条合并才会结束,结束了就进入rsyslog其他操作最后输出。设置超时,不然有可能等一辈子。
freshStartTail="off" #看到Tail 这个就知道了。Tail是从最后读,off关闭,就是从文本开头读取。当然,要第一次读这个文本,这个才有效,读过的,都有记录状态文件。
addMetadata="on" #开启元数据,就是第三个模版那里,还可以加一个变量,就是读取的文本 的绝对路径。用不到不写。
Severity="info"
Facility="user"
tag="nginx_access"
ruleset="ruleset11" #调用ruleset
)
##多行参数用不到可以不要写上。
ruleset( name="ruleset11" ){
action(type="omfwd" Target="10.116.1.1" Port="514" Protocol="tcp" template="nginx_a" )
action(type="omfile" dynaFile="ThisIsTemplateName" fileOwner="develop" fileCreateMode="0655" template="nginx_b" )
stop
}
#最后部分,ruleset 就是处理步骤顺序。。通常只需要一个action就行。
#第2行action,omfwd 模块,是内置模块。就是不体现在模块列表里.so 字眼。但实际确实有这个模块功能。。nginx_a模板中无对事件进行修改,读取到什么就发送什么。过通tcp发送到。。。
#第3行action。dynaFile 是动态文件名,在第一个模板里,设置了以日期为变量。如果静态,参数就是file="/tmp/xx.txt",nginx_b模板中已重新拼接过。输出就是新的格式了。
#一条日志,一份发送出去,一份保留在本地。2份还处理成不一样的内容。
#如果日志中有字符需要处理替换。比如第2个action里的事件,需要把aaa替换成bbb。则在第2个action的前一行插入:
set $.replaced_msg = replace($msg, "aaa", "bbb");
#设置一个新的变量,必需以. 开头 。。$msg 是读取到的原始文本。$.replaced_msg是做过替换后的新变量。。上边的2个模板中的msg都要跟着换成.replaced_msg,nginx_a模板不需要改。
因为第一个action 并没要求进行替换。
#不能对msg直接进行修改。好像有哪个模块可以。忘了 。。反正file模块不行。
-------------------------------------------------------------------------------------------------------------
各家公司的日志,就算是nginx 也是各种不同。何况还有业务服务产生的日志。这格式就更没谁了。
而通过第三个模板这样重新拼接一次后,将格式统一成间隔符的形式。。而在logstash 进行字段解析的时候,就不必写grok了。grok的正则,差一个空格就出错了。
比如,nginx 的XFF变量,有时是多个IP的。。用grok 也是麻烦。下面是重新生成的日志。在Logstash这么写配置:
nginx-server#nginxlogtest#2017-09-28 10:36:21#[test]#www.baidu.com 192.168.10.1
input { tcp { port => 514 type => nginx_xx_log } } ## 这是开放个端口,好让rsyslog发送过来。
filter {
if [type] == " nginx_xx_log" {
ruby {
init => "@kname = ['hostname','log_name','log_time','status ','new_msg']" #定义新的各个字段名。
code => "new_event = LogStash::Event.new(Hash[@kname.zip(event['message'].split('#'))]); new_event.remove('@timestamp');event.append(new_event)"
remove_field => ["message","@version","host"]
}
##code => 这一句,只需要改间隔符是什么。我也不懂ruby,照抄还不会。 上边这个是基于ELK2.X版本的,5.X略有区别。看下面
filter {
if [type] == " nginx_xx_log" {
ruby {
init => "@kname = ['hostname','log_name','log_time','status ','new_msg']"
code => "new_event = LogStash::Event.new(Hash[@kname.zip(event.get('message').split('#'))]); new_event.remove('@timestamp');event.append(new_event)"
remove_field => ["message","@version","host"]
}

















 2205
2205

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









