







hdfs小文件使用fsimage分析实例
1 小文件来源分析
1.1 数据主要来源:
- 滴漏数据(Trickling data) - 数据是以小批量的形式进行增量抽取会导致小文件的产生,那只能事后定期使用一些额外的作业去合并这些小文件。
- 大量的map或者reduce任务 - 大量map或者reduce任务的MapReduce作业或Hive查询很多文件,比如Map-Only的作业有多少个map就会生成多少个文件,如果是Map-Reduce作业则有多少个reduce就会生成多少个文件。
- 过度分区的表 - 比如一个Hive表有太多分区,每个分区下只有几个文件甚至只有一个小文件,这时考虑降低分区的粒度比如从按照天分区改为按照月份分区。
- 上述情况的组合 - 如果上面三种情况组合出现,会加剧小文件问题。比如过度分区的Hive表,每个分区下都是很多个小文件而不是大文件。
对比到我们的业务 大约就是一下场景:
实时计算引擎的中间结果
日志文件
maoreduce的多个reduce产生的多个文件
上报数据多个文件
2 处理方案
2.1 实时计算任务
可以考虑将任务中缓存文件及数据状态使用第三方外部存储,如redis等 存储任务的中间状态,减少对hdfs的读写和文件生成(非常的不靠谱,直接忽略)
2.2 hive做优化,小文件做合并:

2.2.1 已有数据
可以考虑HAR 文件,或把文件合并成一个文件。在重新load进hive中
SET hive.merge.mapfiles = true;
SET hive.merge.mapredfiles = true;
SET hive.merge.size.per.task = 256000000;
SET hive.merge.smallfiles.avgsize = 134217728;
SET hive.exec.compress.output = true;
SET parquet.compression = snappy;
INSERT OVERWRITE TABLE db_name.table_name
SELECT *
FROM db_name.table_name;
这个方法其实就是使用Hive作业从一个表或分区中读取数据然后重新覆盖写入到相同的路径下。必须为合并文件的Hive作业指定一些类似上面章节提到的一些参数,以控制写入HDFS的文件的数量和大小。
合并一个非分区表的小文件方法:
SET mapreduce.job.reduces = <table_size_MB/256>;
SET hive.exec.compress.output = true;
SET parquet.compression = snappy;
INSERT OVERWRITE TABLE db_name.table_name
SELECT *
FROM db_name.table_name
SORT BY 1;
合并一个表分区的小文件:
SET mapreduce.job.reduces = <table_size_MB/256>;
SET hive.exec.compress.output = true;
SET parquet.compression = snappy;
INSERT OVERWRITE TABLE db_name.table_name
PARTITION (part_col = '<part_value>')
SELECT col1, col2, ..., coln
FROM db_name.table_name
WHERE part_col = '<part_value>'
SORT BY 1;
合并一个范围内的表分区的小文件:
SET hive.merge.mapfiles = true;
SET hive.merge.mapredfiles = true;
SET hive.merge.size.per.task = 256000000;
SET hive.merge.smallfiles.avgsize = 134217728;
SET hive.exec.compress.output = true;
SET parquet.compression = snappy;
SET hive.exec.dynamic.partition.mode = nonstrict;
SET hive.exec.dynamic.partition = true;
INSERT OVERWRITE TABLE db_name.table_name
PARTITION (part_col)
SELECT col1, col2, ..., coln, part_col
FROM db_name.table_name
WHERE part_col BETWEEN '<part_value1>' AND '<part_value2>';
2.2.2 新接入数据做数据合并后在load进hive
新表dwd层及以后可以通过设置这些参数。
Hive会在本身的SQL作业执行完毕后会单独起一个MapReduce任务来合并输出的小文件。
但这个设置仅对Hive创建的文件生效,比如使用Sqoop导数到Hive表,或者直接抽数到HDFS等,该方法都不会起作用。
2.2.3 mapreduce 定义规范
定义文件输出个数大小,定义reduce数量,减少输出文件数
3fsimage 离线分析hdfs内容
fsimage文件是NameNode中关于元数据的镜像,一般称为检查点,它是在NameNode启动时对整个文件系统的快照。包括mr操作中 都会对edit以及fsimage做操作修改,可以说fsimage就是整个hdfs的目录清单,通过对其进行分析,可以分析出hdfs上小文件的分布情况
3.1创建hive表 存储元数据,做分析用
CREATE TABLE fsimage_info_csv(
path string,
replication int,
modificationtime string,
accesstime string,
preferredblocksize bigint,
blockscount int,
filesize bigint,
nsquota string,
dsquota string,
permission string,
username string,
groupname string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
WITH SERDEPROPERTIES (
'field.delim'=',',
'serialization.format'=',')
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://Direction_Wind/apps/hive/warehouse/Direction_Wind.db/fsimage_info_csv';
3.2 处理fsimage文件
3.2.1获取fsimage文件:
hdfs dfsadmin -fetchImage /data
3.2.2从2进制文件解析:
hdfs oiv -i /data/fsimage_0000000003621277730 -t /temp/dir -o /data/fs_distribution -p Delimited -delimiter “,”(-t使用临时文件处理中间数据 不加的话全部使用内存 容易OOM)
(hdfs oiv -p FileDistribution -i fsimage_0000000003621277730 -o fs_distribution )
3.2.3加载进hive中
hdfs dfs -put /data/fs_distribution hdfs://Direction_Wind/apps/hive/warehouse/Direction_Wind.db/fsimage_info_csv/
Hive : MSCK REPAIR TABLE fsimage_info_csv;
3.2.4 统计文件整体情况
hdfs oiv -p FileDistribution -i fsimage_0000000003621277730 -o fs_distribution
当前文件总体状况(3.21)
totalFiles = 64324882
totalDirectories = 3895729
totalBlocks = 62179776
totalSpace = 331986259384110
maxFileSize = 269556045187
3.2.5 一级目录一级目录差查看谁下 的小文件多
SELECT
dir_path ,
COUNT(*) AS small_file_num
FROM
( SELECT
relative_size,
dir_path
FROM
( SELECT
(
CASE filesize < 4194304
WHEN TRUE
THEN 'small'
ELSE 'large'
END) AS relative_size,
concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2], '/'
,split(PATH,'\/')[3], '/',split(PATH,'\/')[4], '/', split(
PATH,'\/')[5]) AS dir_path
FROM
Direction_Wind.fsimage_info_csv
WHERE
permission not LIKE 'd%'
) t1
WHERE
relative_size='small') t2
GROUP BY
dir_path desc
ORDER BY
small_file_num
limit 1000
表数据量多大 中途用了多种拆分方式 分散做统计
from (
select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` ,floor(rand() * 8) as part from fsimage_info_csv
) t
insert into fsimage_info_csv_pt1 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 0
insert into fsimage_info_csv_pt2 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 1
insert into fsimage_info_csv_pt3 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 2
insert into fsimage_info_csv_pt4 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 3
insert into fsimage_info_csv_pt5 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 4
insert into fsimage_info_csv_pt6 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 5
insert into fsimage_info_csv_pt7 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 6
insert into fsimage_info_csv_pt8 select `path`,`replication`,`modificationtime`,`accesstime`,`preferredblocksize`,`blockscount`,`filesize`,`nsquota`,`dsquota`,`permission`,`username`,`groupname` where part = 7
insert overwrite table fsimage_info_csv_partition2 partition(pt)
select *
, concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]) as pt
from fsimage_info_csv;
3.2.5.1查找1级目录的 文件结果:

3.2.5.2查找2级目录的文件数量:
select dir_path,countn from (
select dir_path,sum(countn) as countn
from (
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt1
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt2
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt3
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt4
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt5
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt6
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt7
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
union all
SELECT
dir_path
,count(*) as countn
from (
select concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2]
) as dir_path
FROM
Direction_Wind.fsimage_info_csv_pt8
where concat('/',split(PATH,'\/')[1], '/',split(PATH,'\/')[2] ) != '/apps/hive'
) t1
group by dir_path
) unionp
group by dir_path
) orderp
order by countn desc
limit 30
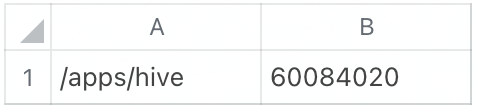
不包含hive的结果:

3.2.5.3查找3级目录的的 文件大小小于4mb的文件数量:
这一步就是在sql上增加一个 filesize 大小的where条件
不包含hive排序结果:

3.2.5.4 hive下查找4级目录的的文件结果 文件小于4mb的数量:

3.2.5.5 hive下查找5级目录的的文件结果 文件小于4mb的数量:

4 处理历史文件中hive小文件并跳过大文件的方案
使用Hive来压缩表中小文件的一个缺点是,如果表中既包含小文件又包含大文件,则必须将这些大小文件一起处理然后重新写入磁盘。如上一节所述,也即没有办法只处理表中的小文件,而保持大文件不变。
FileCrusher使用MapReduce作业来合并一个或多个目录中的小文件,而不会动大文件。它支持以下文件格式的表:
- TEXTFILE
- SEQUENCEFILE
- AVRO
- PARQUET
它还可以压缩合并后的文件,不管这些文件以前是否被压缩,从而减少占用的存储空间。默认情况下FileCrusher使用Snappy压缩输出数据。
FileCrusher不依赖于Hive,而且处理数据时不会以Hive表为单位,它直接工作在HDFS数据之上。一般需要将需要合并的目录信息以及存储的文件格式作为输入参数传递给它。
为了简化使用FileCrusher压缩Hive表,我们创建了一个“包装脚本”(wrapper script)来将Hive表的相关参数正确解析后传递给FileCrusher。
crush_partition.sh脚本将表名(也可以是分区)作为参数,并执行以下任务:
- 在合并之前收集有关表/分区的统计信息
- 计算传递给FileCrusher所需的信息
- 使用必要参数执行FileCrusher
- 在Impala中刷新表元数据,以便Impala可以查看合并后的文件
- 合并后搜集统计信息
- 提供合并前和合并后的摘要信息,并列出原始文件备份的目录位置
当FileCrusher运行时,它会将符合压缩条件的文件合并压缩为更大的文件,然后使用合并后的文件替换原始的小文件。合并后的文件格式为:
“crushed_file--<some_numbers>”
原始文件不会被删除,它们会被移动的备份目录,备份目录的路径会在作业执行完毕后打印到终端。原始文件的绝对路径在备份目录中保持不变,因此,如果需要回滚,则很容易找出你想要拷贝回去的目录地址。例如,如果原始小文件的目录为:
/user/hive/warehouse/prod.db/user_transactions/000000_1/user/hive/warehouse/prod.db/user_transactions/000000_2
合并后会成为一个文件:
/user/hive/warehouse/prod.db/user_transactions/crushed_file-20161118102300-0-0
原始文件我们会移动到备份目录,而且它之前的原始路径我们依旧会保留:
/user/admin/filecrush_backup/user/hive/warehouse/prod.db/user_transactions/000000_1/user/admin/filecrush_backup/user/hive/warehouse/prod.db/user_transactions/000000_2
本文提到的crush_partition.sh github全路径为:
https://github.com/asdaraujo/filecrush/tree/master/bin
脚本的方法如下所示:
Syntax: crush_partition.sh <db_name> <table_name> <partition_spec> [compression] [threshold] [max_reduces]
具体参数解释如下:
db_name - (必须)表所存储的数据库名
table_name -(必须)需要合并的表名
partition_spec -(必须)需要合并的分区参数,有效值为:
- “all” – 合并非分区表,或者合并分区表的所有分区内的文件
- 指定分区参数,参数必须用引号引起来,例如:
- “year=2010,state=‘CA’”
- “pt_date=‘2016-01-01’”
compression -(可选,默认Snappy)合并后的文件写入的压缩格式,有效值为:snappy, none (for no compression), gzip, bzip2 and deflate。
threshold -(可选,默认0.5)符合文件合并条件的相对于HDFS block size的百分比阈值,必须是 (0, 1] 范围内的值。默认的0.5的意思是小于或等于HDFS block size的文件会被合并,大于50%的则会保持不变。
max_reduces -(可选,默认200)FileCrusher会被分配的最大reduce数,这个限制是为了避免在合并非常大的表时分配太多任务而占用太多资源。所以我们可以使用这个参数来平衡合并文件的速度以及它在Hadoop集群上造成的开销。

















 167
167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











