









Gitee仓库:boost库搜索引擎
0. 前言
市面上有很多搜索引擎例如Google、百度、360等,这些都是特别大的项目。
对于个人学习我们可以写一个站内搜索,这个搜索的内容更加垂直,数据量更小,例如C++的文档The C++ Resources Network
Google搜索显示内容:
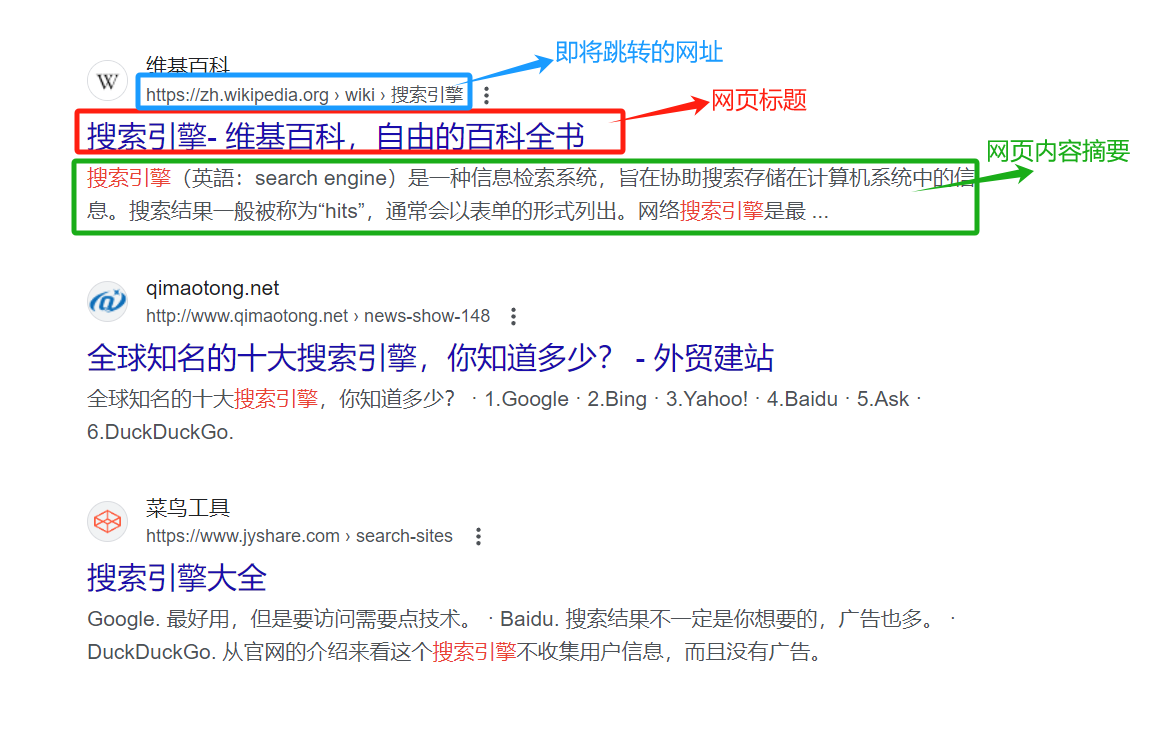
1. 搜索引擎原理
客户端使用浏览器搜索向服务器发起请求(GET方法上传)。
服务器上面有一个搜索的服务软件,在搜索之前,它要在全网抓取网页(爬虫)。
将网页抓下来之后:
- 去标签和数据清理
- 建立索引
之后这个搜索的软件检索索引得到相关的html,拼接多个网页的title、description、url,构建出一个新的网页返回给客户端
2. 技术栈和项目环境
技术栈:
-
后端:
C/C++、C++11、STL、boost准标准库、Jsoncpp、cppjieba、cpp-http
-
前端(选学):
html5、css、JavaScript、jQuery、Ajax
项目环境:
- Centos 7云服务器、VS Code、 gcc(g++)、Makefile
3. 正排索引和倒排索引
比如说我们有2个文档:
- 文档1:我好喜欢睡觉啊,因为睡觉很舒服呀
- 文档2:你喜欢睡觉吗?喜欢和谁一起睡觉啊
3.1 正排索引
正排索引中每个文档都有唯一标识符,然后就是从文档ID找到文档内容
| 文档ID | 文档内容 |
|---|---|
| 1 | 我好喜欢睡觉啊,因为睡觉很舒服噢 |
| 2 | 你喜欢睡觉吗?喜欢和谁一起睡觉啊 |
3.2 倒排索引
倒排索引则是文档分词,通过整理不重复的各个关键字来找到文档ID
有些停止词在分词的时候一般不考虑,搜索引擎
stopwords大全:https://github.com/goto456/stopwords
| 关键字 | 文档ID,weight(权重) |
|---|---|
| 睡觉 | 文档1、文档2 |
| 舒服 | 文档1 |
| 喜欢 | 文档1、文档2 |
| 一起 | 文档2 |
总的来说,正排索引适用于需要快速访问整个文档内容的场景,而倒排索引则适用于需要快速检索包含特定词项的文档的场景。两者常常结合使用,在信息检索系统中发挥各自的优势。
3.3 模拟查找
查找:喜欢 -> 倒排索引查找 -> 提取文档1、文档2 -> 正排索引 -> 找到文档内容 -> 文档内容摘要(title、desc、url) -> 构建响应结果
4. 获取数据源
进入boost官网:Boost C++ Libraries,然后下载文档:
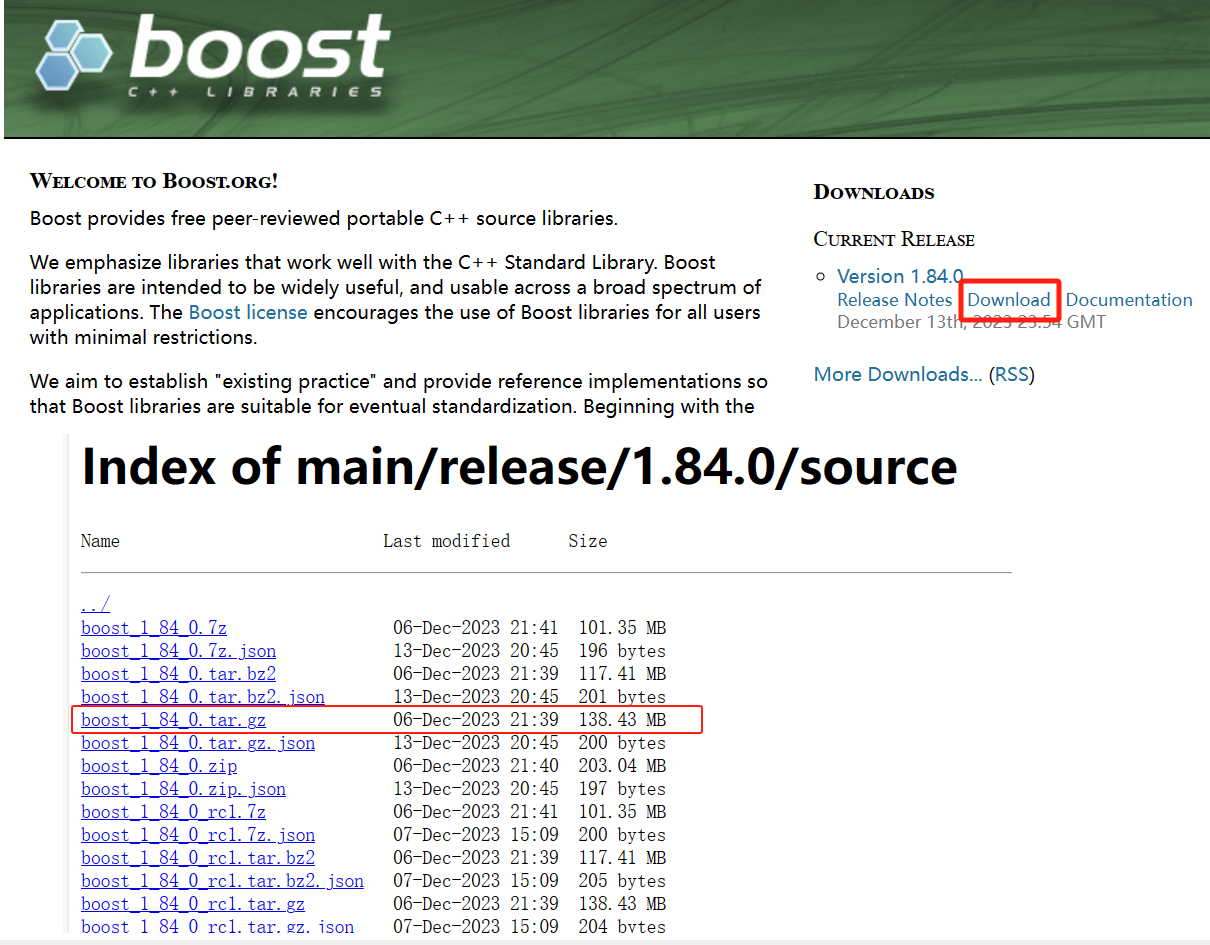
下载完毕之后传入服务器
rz -E
传入之后解压:
tar xzf boost_1_84_0.tar.gz
这些html文件就是我们的数据源了,我们只需要这里面的内容,所以将这里面的内容拷贝到要存放数据源的文件夹当中。
5. 数据清洗
html中用的<>就是标签,一般都是成对出现,所以我们要将这些内容给去掉,留下里面正文的内容
ls -Rl | grep -E '*.html' | wc -l

这里查看到差不多有8500个文档,我们的目标就是要将这八千多个文档的标签全部去掉,然后保存到一个文件中。
5.1 保存路径
bool EnumFiles(const std::string &src_path, std::vector<std::string> *files_list)
{
namespace fs = boost::filesystem;
fs::path root_path(src_path);
//判断路径是否存在
if(!fs::exists(root_path))
{
std::cerr << src_path << " not exists..." << std::endl;
return false;
}
//空迭代器,判断递归是否结束
fs::recursive_directory_iterator end;
for(fs::recursive_directory_iterator iter(root_path); iter!=end; iter++)
{
//判断是否为普通文件,html都是普通文件
if(!fs::is_regular_file(*iter))
{
continue;
}
//判断后缀
if(iter->path().extension() != ".html")
{
continue;
}
//保存获取到的文件路径
//std::cout << iter->path().string() << std::endl;
//保存路径
files_list->push_back(iter->path().string());
}
return true;
}
我们这里先将路径保存下来,方便后续的读取
这里需要用到
boost库的文件操作,需要提前安装boost库boost库安装:
sudo yum install -y boost-devel
5.2 解析文件
首先将文件的内容读取上来,然后根据读取的内容对标题、内容进行提取,最后构造出对应的url
bool ParseHtml(const std::vector<std::string> &files_list, std::vector<DocInfo_t> *results)
{
for(const std::string &file : files_list)
{
//读取文件内容
std::string result;
if(!ns_util::FileUtil::ReadFile(file, &result))
{
continue;
}
DocInfo_t doc;
//解析文件,提取标题
if(!ParseTitle(result, &doc.title))
{
continue;
}
//解析文件,提取内容
if(!ParseContent(result, &doc.content))
{
continue;
}
//解析路径,构建url
if(!ParseUrl(file, &doc.url))
{
continue;
}
//解析完毕
//results->push_back(doc); //直接拷贝, 效率较低
results->push_back(std::move(doc));
//Debug
//ShowDoc(doc);
}
return true;
}
提取标题
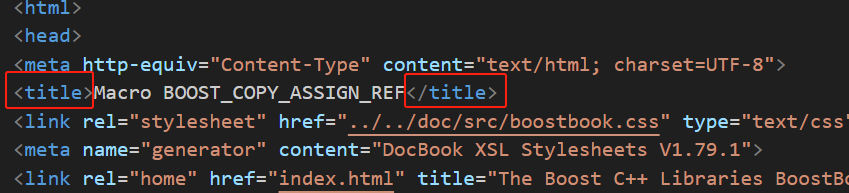
标题的标签是<title>内容</title>,需要拿到中间的内容,string中的find方法,找到的是起始位置,也就是<,所以截取的起始位置,还需要加上"<title>"的长度
static bool ParseTitle(const std::string &file, std::string *title)
{
size_t begin = file.find("<title>");
if(begin == std::string::npos)
return false;
size_t end = file.find("</title>");
if(end == std::string::npos)
return false;
begin += std::string("<title>").size();
if(begin > end)
return false;
*title = file.substr(begin, end - begin);
return true;
}
提取内容
提取内容并不是拿取html网页的内容,而是要去掉标签,也就是去除<>里面的内容去掉
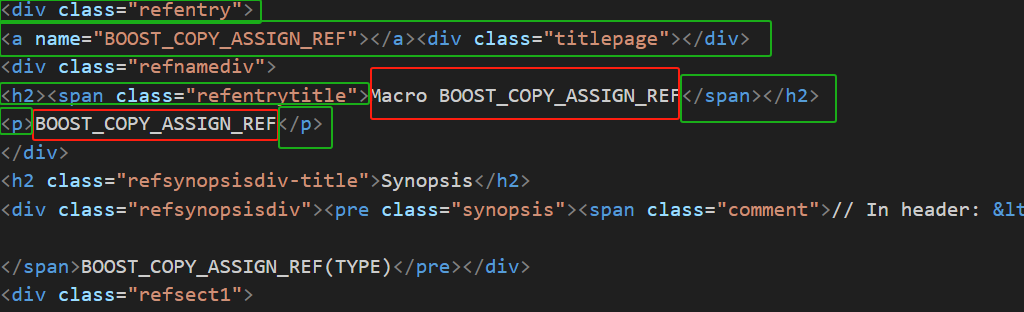
这里采用简易的状态机来进行判断:
static bool ParseContent(const std::string &file, std::string *content)
{
//简易状态机
enum status
{
LABEL,
CONTENT
};
status s = LABEL; //起始肯定是遇到标签
for(char c : file)
{
switch (s)
{
case LABEL:
if(c == '>') s = CONTENT;
break;
case CONTENT:
if(c == '<') s = LABEL;
else
{
if(c == '\n') c = ' ';
content->push_back(c);
}
break;
default:
break;
}
}
return true;
}
起始状态肯定是遇到标签<,所以将状态机的其状态设为标签状态
当遇到>就表明状态结束,此时我们将状态设置为CONTENT,但是也可能下一个又是标签,所以还行进行判断,当遇到<,就表明新的状态又开始了。
这里没有保留原文件中的
\n,因为之后\n用于文本的分隔符
构造url
boost库的官网文档,和我们获取的数据源是有对应的路径关系的
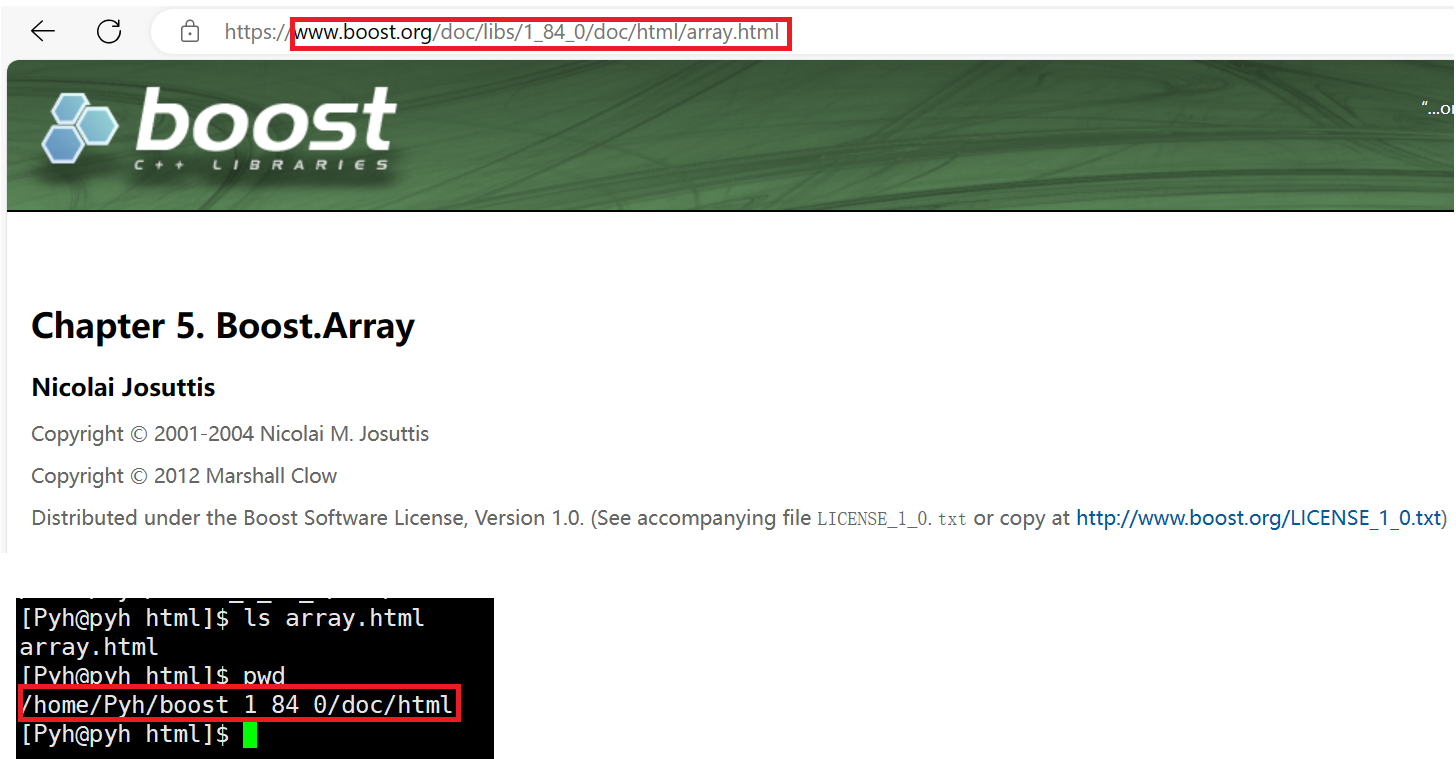
而我们将html文件放到data/input当中,所以相当官网的路径+我们的文档路径访问到指定的文档
url_head:https://www.boost.org/doc/libs/1_84_0/doc/html(切记,带上前缀https://,踩bug之谈)我们的路径为
data/input/array.html,但是我们并不需要~~/data/input~~
url_tail:array.html
url=url_head + url + tail这样拼接起来就是指定文档的网址了
5.4 保存内容
文档之间如何区分:
文档和文档之间可以用\3区分,例如:
AAAAAAA\3BBBBBB\3CCCCCC
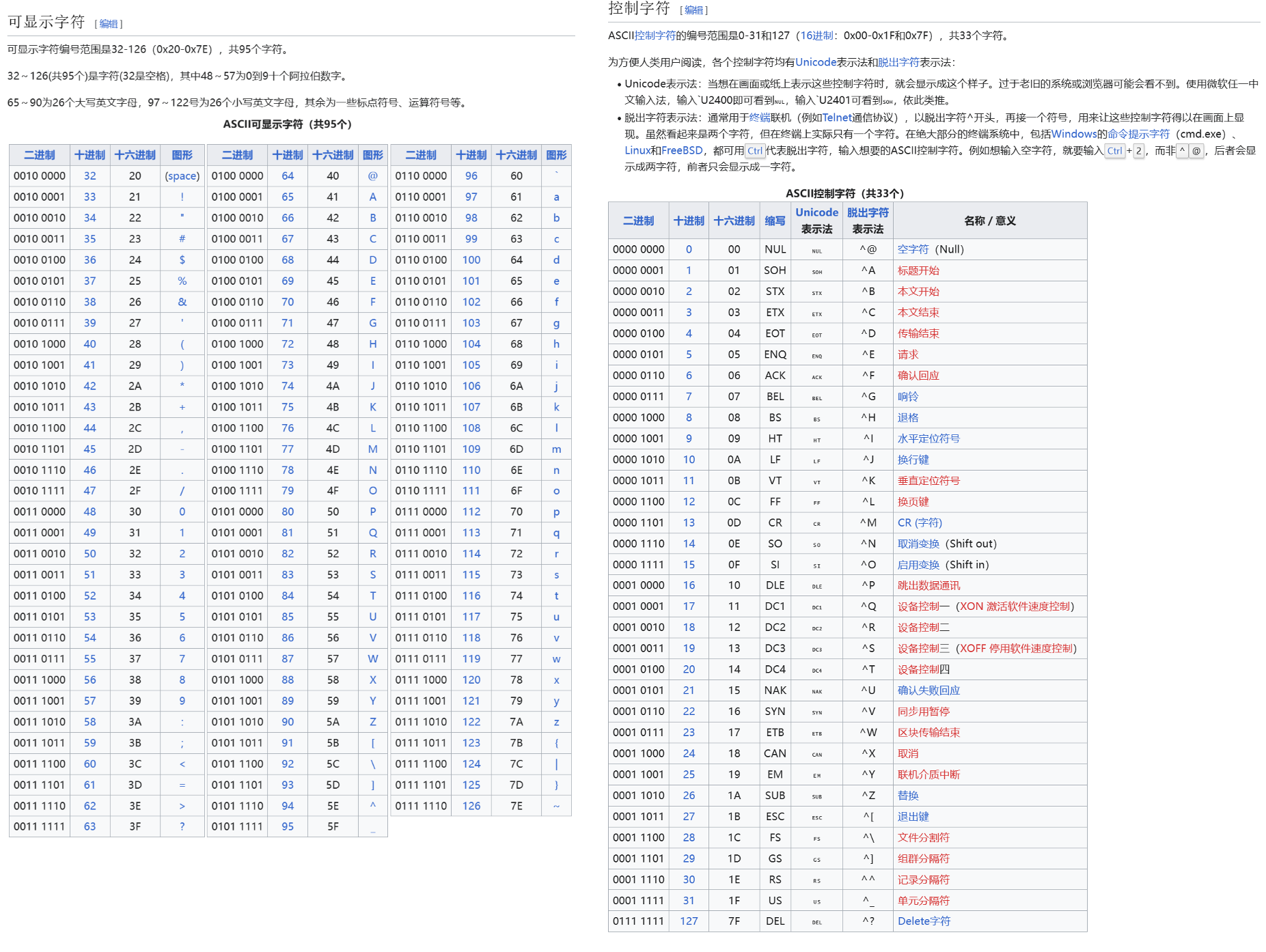
为什么是
\3?文档当中能够显示的字符,一般都是属于打印字符;而像
\3这样的叫做控制字符,是不显示的,就不会污染我们清洗之后的文档
但是getline函数,是以行读取的内容,所以我们可以采用\3来作为title、content、url的分隔符,而\n作为文档的分隔符,即:title\3content\3url\3\n\...,这样会方便之后的文件读取
bool SaveHtml(const std::vector<DocInfo_t> &results, const std::string &output)
{
std::ofstream out(output, std::ios::out | std::ios::binary);
if(!out.is_open())
{
std::cerr << "open " << output << " error..." << std::endl;
return false;
}
//写入
for(auto &item : results)
{
std::string out_str;
out_str += item.title;
out_str += SEP;
out_str += item.content;
out_str += SEP;
out_str += item.url;
out_str += '\n';
out.write(out_str.c_str(), out_str.size());
}
out.close();
return true;
}
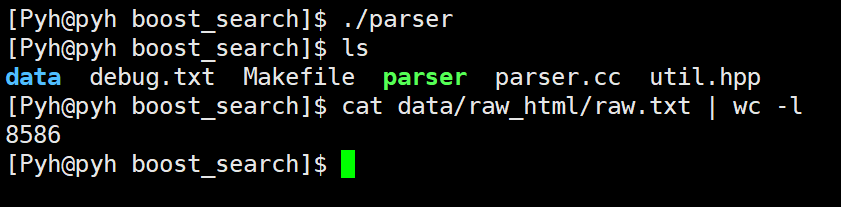
运行之后得到的内容和从官网获取的文档内容数量一样:
6. 建立索引
建立正排索引是要将文档的内容读取之后放到数组当中,而建立倒排是需要在正排之后,根据正排之后的文档再建立。
struct DocInfo
{
std::string title;
std::string content;
std::string url;
uint64_t doc_id; //文档id
};
struct InvertedElem
{
uint64_t doc_id;
std::string word;
int weight;
};
typedef std::vector<InvertedElem> InvertedList; //倒排拉链
class Index
{
public:
Index()
{}
~Index()
{}
public:
//根据文档id找文档内容
DocInfo* GetForwardIndex(const uint64_t &id)
{
//...
return nullptr;
}
//根据关键字找倒排拉链
InvertedList* GetInvertedList(const std::string &word)
{
//...
return nullptr;
}
//根据parse之后的数据,建立正排倒排索引
bool BuildIndex(const std::string &input)
{
//...
return true;
}
private:
std::vector<DocInfo> forward_index; //数组的下标就是天然的文档id
std::unordered_map<std::string, InvertedList> inverted_index; //一个关键字对应一组(个)倒排元素
};
6.1 建立正排索引
DocInfo *BuildForwardIndex(const std::string &line)
{
//1. 切割字符串
std::vector<std::string> results;
const std::string sep = "\3"; //内容分隔符
ns_util::StringUtil::SplitString(line, &results, sep);
if(results.size() != 3)
return nullptr;
//2.填充内容
DocInfo doc;
doc.title = results[0];
doc.content = results[1];
doc.url = results[2];
doc.doc_id = forward_index.size(); //当时的大小就是 文档id
//3. 插入正排
forward_index.push_back(std::move(doc));
return &forward_index.back();
}
切分字符串采用
boost库的split函数:class StringUtil { public: static void SplitString(const std::string &target, std::vector<std::string> *ret, const std::string &sep) { boost::split(*ret, target, boost::is_any_of(sep), boost::token_compress_on); } };
*ret:目标容器的指针,这个容器用于存储分割后的子串。target:需要分割的源字符串。boost::is_any_of(sep):指定的分隔符,可以是单个字符、字符串或者字符范围。boost::token_compress_on:表示开启压缩模式。开启后,连续的分隔符将被视为一个分隔符,并且不会产生空字符串。
6.2 建立倒排索引
原理:
一个文档里面的
title和content是包含很多词的,需要将这些词进行分词,根据这些内容形成倒排拉链这里就需要将词和文档标题/内容中出现次数进行关联,采用
unordered_map
jieba库:
获取cppjieba:GitHub - yanyiwu/cppjieba: "结巴"中文分词的C++版本,然后克隆到服务器
git clone https://github.com/yanyiwu/cppjieba.git
demo代码:
#include "cppjieba/Jieba.hpp"
const char* const DICT_PATH = "../dict/jieba.dict.utf8";
const char* const HMM_PATH = "../dict/hmm_model.utf8";
const char* const USER_DICT_PATH = "../dict/user.dict.utf8";
const char* const IDF_PATH = "../dict/idf.utf8";
const char* const STOP_WORD_PATH = "../dict/stop_words.utf8";
这些就是词库,就是根据这些词库进行分词

我们稍后要用,肯定不是在这个库文件里面创建文件使用,所以我们需要建立软连接让程序能找到词库,然后它包含的头文件还要包含Jieba.hpp,也是需要建立软链接的
不了解的查看此篇文章:Linux软硬链接
这里还有一个小坑:
我们编译的会报错,说缺少
limonp/Logging.hpp,我们需要手动拷贝limonp这个目录到cppjieba/include当中
bool BuildInvertedIndex(const DocInfo &doc)
{
struct word_cnt
{
int title_cnt;
int content_cnt;
word_cnt()
:title_cnt(0),content_cnt(0)
{}
};
std::unordered_map<std::string, word_cnt> word_map; //暂存词频映射表
std::vector<std::string> title_words;
std::vector<std::string> content_words;
ns_util::JiebaUtil::CutString(doc.title, &title_words, STOP_WORD_FLAG); //标题分词
ns_util::JiebaUtil::CutString(doc.content, &content_words, STOP_WORD_FLAG); //内容分词
//统计标题词频
for(std::string s : title_words)
{
word_map[s].title_cnt++;
}
//统计内容词频
for(std::string s : content_words)
{
word_map[s].content_cnt++;
}
#define X 10
#define Y 1
//构建倒排索引
for(auto &word_pair : word_map)
{
InvertedElem item;
item.doc_id = doc.doc_id;
item.word = word_pair.first;
item.weight = word_pair.second.title_cnt * X + word_pair.second.content_cnt * Y; //标题出现权重更高
//inverted_index[word_pair.first].push_back(std::move(item));
InvertedList &invertedlist = inverted_index[word_pair.first];
invertedlist.push_back(std::move(item));
}
return true;
}
6.3 构建索引
bool BuildIndex(const std::string &input)
{
std::ifstream in(input, std::ios::in | std::ios::binary);
if(!in.is_open())
{
ns_log::log(Fatal, "%s open error", input.c_str());
//std::cerr << input << "open error..." << std::endl;
return false;
}
std::string line;
int cnt = 0;
int len = lable.size();
while(std::getline(in, line))
{
//建立正排
DocInfo *doc = BuildForwardIndex(line);
if(doc == nullptr)
{
ns_log::log(Warning, "build %s error", line.c_str());
//std::cerr << "build " << line << " error" << std::endl;
continue;
}
//建立倒排
BuildInvertedIndex(*doc);
cnt++;
ns_log::log(Info, "build document %d", cnt);
// std::cout << "build doc: " << cnt << "..." << std::endl;
}
ns_log::log(Info, "total document %d ...", cnt);
return true;
}
建立索引的本质是将去标签化的数据加载到内存当中,这个体积是很大的,而且索引只有一份,所以构建成单例模式
class Index { //... private: Index() {} Index(const Index&) = delete;//拷贝构造去掉 Index& operator=(const Index&) = delete; //赋值语句去掉 static Index *instance; //单例 static std::mutex mtx; public: ~Index() {} public: static Index* GetInstance() { if (nullptr == instance) { mtx.lock(); if (nullptr == instance) { instance = new Index(); } mtx.unlock(); } return instance; } //... }; Index* Index::instance = nullptr; std::mutex Index::mtx; //构造函数
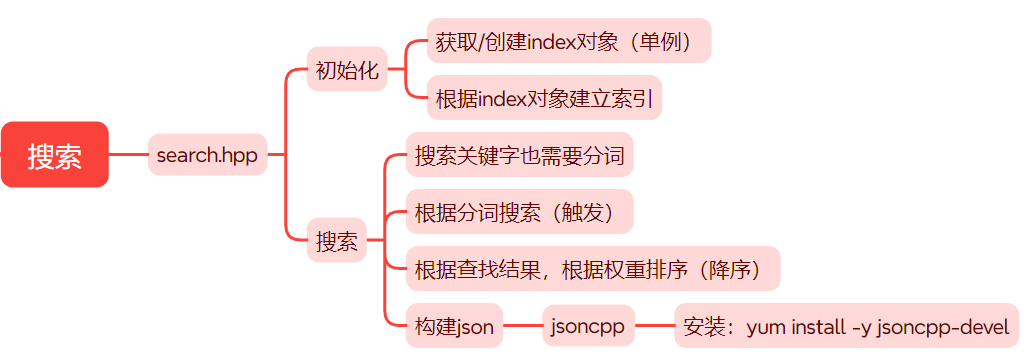
7. 搜索
搜索服务思维导图:
#pragma once
#include<algorithm>
#include<unordered_map>
#include<jsoncpp/json/json.h>
#include"index.hpp"
#include"util.hpp"
#include"Log.hpp"
namespace ns_searcher
{
struct InvertedElemPrint{
uint64_t doc_id;
int weight;
std::vector<std::string> words;
InvertedElemPrint()
:doc_id(0),weight(0)
{}
};
class Searcher
{
public:
Searcher()
{}
~Searcher()
{}
private:
std::string GetAbstract(const std::string &content, const std::string &word)
{
// 往前找50字节,往后找100字节 直接硬编码
size_t prev_pos = 50;
size_t next_pos = 100;
//size_t pos = content.find(word);
// if (pos == std::string::npos)
// return "Not Found";
auto it = std::search(content.begin(), content.end(), word.begin(), word.end(), [](int x, int y){
return std::tolower(x) == std::tolower(y);
});
if(it == content.end()) return "Not Found1";
size_t pos = std::distance(content.begin(), it);
size_t start = 0; // 默认起始位置为begin
size_t end = content.size() - 1; // 结束位置为end
if (pos > start + prev_pos)
start = pos - prev_pos; // 用加法,防止无符号溢出
if (pos + next_pos < end)
end = pos + next_pos;
if (start >= end)
return "Not Found2";
return content.substr(start, end - start)+ "...";
}
public:
void InitSearcher(const std::string &input)
{
//获取index对象
index = ns_index::Index::GetInstance();
//std::cout << "get instance" << std::endl;
ns_log::log(Info, "Get instance success");
//建立索引
index->BuildIndex(input);
//std::cout << "build index success" << std::endl;
ns_log::log(Info, "build index success");
}
//keyword:搜索关键字 json_string:返回给用户浏览器的搜索结果(序列化)
void Search(const std::string &keyword, std::string *json_string)
{
//对关键字进行分词
std::vector<std::string> words;
ns_util::JiebaUtil::CutString(keyword, &words, 1);
//触发,根据关键字分词进行查找
//ns_index::InvertedList inverted_list_all;
std::vector<InvertedElemPrint> inverted_list_all;
std::unordered_map<uint16_t, InvertedElemPrint> tokens_map;
for(std::string s : words)
{
boost::to_lower(s); //忽略大小写(转小写)
//先倒排,再正排
//倒排
ns_index::InvertedList *inverted_list = index->GetInvertedList(s);
if(inverted_list == nullptr)
{
continue;
}
//inverted_list_all.insert(inverted_list_all.end(), inverted_list->begin(), inverted_list->end());
for(const auto &elem : *inverted_list)
{
auto &item = tokens_map[elem.doc_id]; //去重
item.doc_id = elem.doc_id; //去重之后赋值
item.weight += elem.weight; //累加权重值
item.words.push_back(elem.word);
}
for(const auto &e : tokens_map)
{
inverted_list_all.push_back(std::move(e.second));
}
//排序
// std::sort(inverted_list_all.begin(), inverted_list_all.end(),
// [](const ns_index::InvertedElem &e1, const ns_index::InvertedElem &e2){
// return e1.weight > e2.weight;
// });
std::sort(inverted_list_all.begin(),inverted_list_all.end(),
[](const InvertedElemPrint &e1, const InvertedElemPrint &e2){
return e1.weight > e2.weight;
});
//正排
Json::Value root;
for(auto &e : inverted_list_all)
{
ns_index::DocInfo *doc = index->GetForwardIndex(e.doc_id);
if(doc == nullptr)
{
continue;
}
Json::Value item;
item["title"] = doc->title;
//item["abstract"] = doc->content;
item["content"] = GetAbstract(doc->content, e.words[0]);
item["url"] = doc->url;
//debug
//item["id"] = (int)e.doc_id; //json自动转换int -> string
//item["weight"] = e.weight;
root.append(item);
//
}
//序列化
Json::StyledWriter writer;
*json_string = writer.write(root);
}
}
private:
ns_index::Index *index;
};
}
8. 服务端
使用第三方网络库cpp-httplib,这个库需要使用较新的编译器:
-
安装
scl源:sudo yum install centos-release-scl scl-utils-build -
更新gcc/g++:
sudo yum install -y devtoolset-7gcc devtoolset-7-gcc-c++
安装好之后的路径:
这里用的时候要启动,使用指令:
scl enable devtoolset-7 bash但是这个只是每次会话有效,如果想每次启动都有效,可以将上面的指令加入
.bash_profile配置文件
#include"cpp-httplib/httplib.h"
#include"search.hpp"
#include"Log.hpp"
const std::string root_path = "./wwwroot";
const std::string input = "data/raw_html/raw.txt";
int main()
{
ns_searcher::Searcher search;
search.InitSearcher(input);
httplib::Server svr;
svr.set_base_dir(root_path.c_str());
svr.Get("/s", [&search](const httplib::Request &req, httplib::Response &rsp)
{
//rsp.set_content("hello httplib", "text/plain; charset=utf-8");
if(!req.has_param("word"))
{
rsp.set_content("please enter keyword!", "text/plain; charset=utf-8");
return;
}
std::string word = req.get_param_value("word");
//std::cout << "user is searching: " << word << std::endl;
ns_log::log(Info, "User search content is \"%s\"", word.c_str());
std::string json_str;
search.Search(word, &json_str);
rsp.set_content(json_str, "application/json");
});
ns_log::log(Info, "server start success");
svr.listen("0.0.0.0", 8080);
return 0;
}
9. 服务部署
nohup ./http_server > log/log.txt 2>&1 &
将服务后台运行部署,如果要要查看,可以直接看log/log.txt,也可以tail -f log/log.txt
默认设置了去掉暂停词,第一次启动可能会较慢,如果不想去掉暂停词,可以将
STOP_WORD_FLAG设置为0















 335
335











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











