







跳表的结构
🚀跳表就是一个链表,与普通链表不同之处在于它存储的数据是有序的,更重要的一点是每个结点的高度是不固定的,高度不固定是指某个结点内部的next指针有多个,有的直线下一个结点,有的指向下下个结点,有的指向后面的某个结点。

🚀将有序链表改造成跳表的思考过程:
- 每相邻两个结点就升高一层,增加一个指针,让指针指向下下个结点。例如我们在查找链表最后一个数据时只需要遍历n / 2数量的结点即可。

- 以此类推,我们也可以在每相邻高度为2的两个结点继续增高一层,增加一个指针,让指针指向下下下个结点。以此类推,每相邻高度为3的两个结点,每相邻高度为n的两个结点…,最终得到的结构就是高度为n + 1的结点数量是高度为n的结点数量的一半,并且都是均匀分布的,那么搜索的效率就达到了O(lgN)的级别(每次淘汰剩余数据的一半,类似于平衡二叉树)。
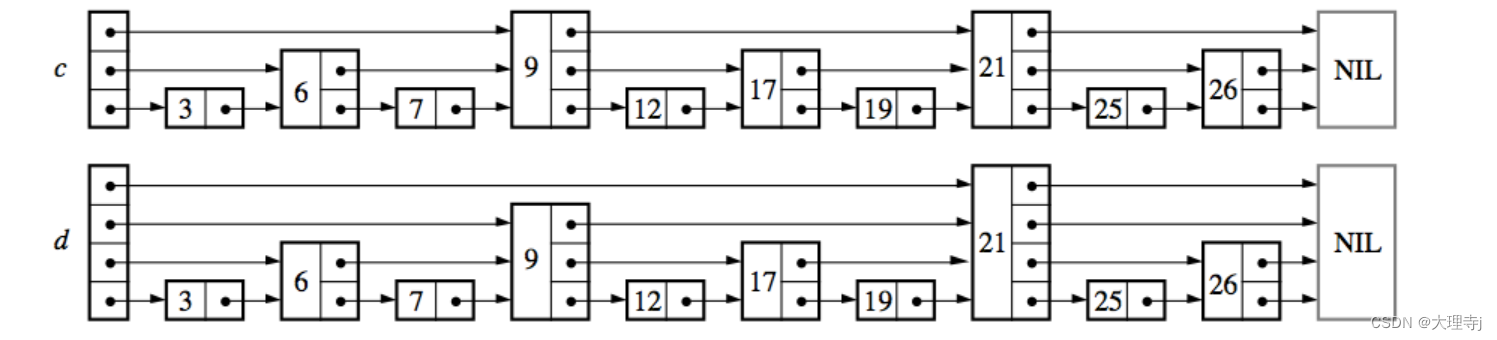
- 但是,如果结点都是均匀分布的话,会带来很大的麻烦,就是当我们插入或者删除一个数据的时候,其就会影响到周围结点的高度。当插入或者删除一个数据的时候就要对其周围结点的高度做出调整,这对效率的消耗是很大的。解决的方法是每次新插入的结点的高度是随机的,让这个结点与其周围结点的高度没有关联。

- 还有一个问题就是,结点高度是怎么随机的?难道就真的随机吗?一个结点的高度为1,再插入一个结点的高度为10000,显然这是很不合理的。所以,跳表的结构中结点的高度是有一个上限的,随机出来的高度是在1-某个最值之间的。
结点随机高度的算法

首先,引入两个变量概率p和结点高度的最大值MaxLevel,上面这个算法的意思就是随机高度的初始值为1,random()均匀的随机产生一个[0,1)的数rand,如果rand小于p并且当前的level是小于MaxLevel的,那么level就自增一。
这就说明:
产生高度为1的结点的概率就是(1-p)
产生高度为2的结点的概率就是p * (1-p)
产生高度为3的结点的概率就是p * p * (1-p)
以此类推,产生高度为n的结点的概率就是p^(n - 1) * (1-p)
所以,产生高度越高的结点的概率是越小的。
产生结点高度的数学期望: 1*(1-p) + 2p * (1-p) + 3p * p * (1-p) + … + n*p^(n - 1) * (1-p) = 1/(1-p)
可见,如果p取1/4那么跳表结点的平均高度就是1.33,如果p取0.5的话跳表结点的平均高度就是2。
🚀那么,MaxLevel和p的值取多少合适呢?
在Redis中使用的跳表的MaxLevel取值为32,p的取值为0.25,可以作为一个参考。
跳表的性能分析
🚀如果跳表的所有结点是严格均匀分布的,那么很容易就能算出其查找效率是O(lgN),但是跳表的结点高度是随机的,结点的排布也是任意的,那么他的查找效率又是多少呢?O(lgN)
由于精确的计算出跳表的时间复杂度是较为复杂的,如果想要了解计算跳表效率的问题可以去看下跳表的作者William Pugh大佬的论文《Skip lists: a probabilistic alternative to balanced trees》
代码实现
struct SkiplistNode {
int _val;
std::vector<SkiplistNode*> _next;
SkiplistNode(int val, int n) :_val(val) {
_next.resize(n, nullptr);
}
};
class Skiplist {
using node = SkiplistNode;
private:
node* _head = nullptr;
double _p = 0.25; //概率
int _max_level = 32; //最大层数
public:
Skiplist() {
_head = new SkiplistNode(-1, 1);
srand((size_t)time(nullptr));
}
//查找的原理就是,将target与下一结点的val进行对比,
//如果target大于下一节点的val值,那么cur指针就往右跳,
//如果小于下一节点的val值,或者下一节点为nullptr,那么就往下跳。
bool search(int target) {
int level = _head->_next.size() - 1;
node* cur = _head;
while (true) {
if (cur->_next[level] && target > cur->_next[level]->_val) {
//target大于这一层的下一结点的val
//往右跳
cur = cur->_next[level];
}
else if (nullptr == cur->_next[level] || target < cur->_next[level]->_val) {
//target小于这一层的下一节点的val
//往下跳
if ((--level) < 0) { break; }
}
else {
//找到了target
return true;
}
}
return false;
}
void add(int num) {
int n = GetRandomLevel();
node* newnode = new node(num, n);
if (n > _head->_next.size()) {
//如果新插入的结点层数大于head结点的层数
//head结点next数组扩容到level层
_head->_next.resize(n, nullptr);
}
std::vector<node*> prev = FindPrev(num);
//将新节点链接入跳表
for (int i = 0; i < n; ++i) {
newnode->_next[i] = prev[i]->_next[i];
prev[i]->_next[i] = newnode;
}
}
bool erase(int num) {
if (false == search(num)) { return false; }
std::vector<node*> prev = FindPrev(num);
//进行删除结点
node* del = prev[0]->_next[0];
for (int i = 0; i < del->_next.size(); ++i) {
prev[i]->_next[i] = del->_next[i];
}
delete del;
return true;
}
private:
//随机
int GetRandomLevel() {
int level = 1;
while (rand() <= RAND_MAX * _p && level < _max_level) {
level++;
}
return level;
}
//无论是插入还是删除某个结点,都要找到这一结点在更层上的前一结点。
std::vector<node*> FindPrev(int num) {
node* cur = _head;
int level = _head->_next.size() - 1;
std::vector<node*> prev(level + 1, _head);
//使用prev数组记录新插入结点每一层的先序结点
while (true) {
if (cur->_next[level] && num > cur->_next[level]->_val) {
//target大于这一层的下一结点的val
//往右跳
cur = cur->_next[level];
}
else if (nullptr == cur->_next[level] || num <= cur->_next[level]->_val) {
//target小于这一层的下一节点的val
//往下跳
//往下跳之前要先将先序结点记录到prev中
prev[level] = cur;
if ((--level) < 0) { break; }
}
}
return prev;
}
};
与AVL树/红黑树/哈希表的对比
🚀跳表与红黑树和AVL树相比,树形结构的增加和删除都是比较复杂的,而跳表的增删改查和遍历都是非常简单的。另外在性能方面,树形结构的搜索时间复杂度为O(lgN),跳表的时间复杂度也是O(lgN),但是AVL树个红黑树的搜索效率是十分稳定的,对于跳表而言得是在大量数据下时间复杂度是逼近O(lgN)的。在空间开销上p=0.25时跳表的平均高度为1.33也就是在存储有效数据外,还另外需要1.33个空间来存指针,但是AVL树和红黑树都采取三叉链的结构(存储左右孩子和父节点的指针),可见在空间开销上跳表也是更省空间的。
🚀在复杂度方面跳表一定是比哈希表更简单的。在性能方面,哈希表的搜索效率为O(1),在极端场景哈希冲突增加但是可以通过将挂链表改成挂红黑树的方式来解决,另外哈希表在扩容的时候也是有性能消耗的,但是在效率方面大概率是不如哈希表的。在空间开销上哈希表除了存储有效数据外还要存取指针和表结构,空间开销上是大于跳表的。
🚀总之,跳表在性能方面是中规中矩的与AVL树/红黑树/哈希表相比,但是跳表突出的特点就是实现简单,空间开销小。
















 900
900











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











