






一, WEB框架介绍
Web应用程序处理流程

Web框架程序的意义
- 用于搭建Web应用程序
- 免去不同Web应用相同代码部分的重复
Web应用程序的本质
- 接收并解析HTTP请求,获取具体的请求信息
- 处理本次HTTP请求,即完成本次请求的业务逻辑处理
- 构造并返回处理结果——HTTP响应
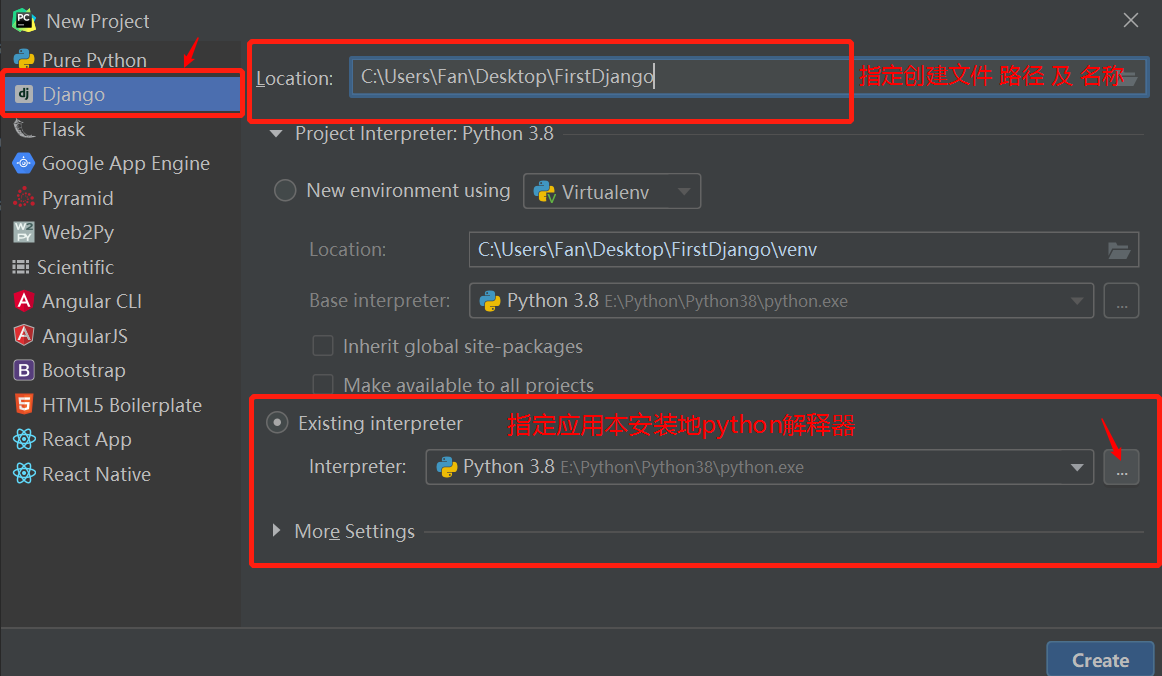
如何搭建项目(project)程序
- 项目的组建
- 项目的配置
- 路由定义
- 视图函数定义
数据库
模板
表单
admin
二,Django框架介绍
简介:Django,发音为[`dʒæŋɡəʊ],是用python语言写的开源web开发框架,并遵循MVC设计。
特点:
1) 重量级框架
对比Flask框架,Django原生提供了众多的功能组件,让开发更简便快速。
1)提供项目工程管理的自动化脚本工具( 脚手架工具 )
2)数据库ORM支持(对象关系映射,英语:Object Relational Mapping)
3)模板
4)表单
5)Admin管理站点
6)文件管理
7)认证权限
8)session机制
9)缓存
2)MVC模式(model-view-control) ——模型-视图-控制
有一种程序设计模式叫MVC, 其核心思想是分工、解耦,让不同的代码块之间降低耦合,增强代码的可扩展性和可移植性,实现向后兼容。
MVC的全拼为Model-View-Controller,最早由TrygveReenskaug在1978年提出,是施乐帕罗奥多研究中心(Xerox PARC)在20世纪80年代为程序语言Smalltalk发明的一种软件设计模式,是为了将传统的输入(input)、处理(processing)、输出(output)任务运用到图形化用户交互模型中而设计的。
随着标准输入输出设备的出现,开发人员只需要将精力集中在业务逻辑的分析与实现上。
后来被推荐为Oracle旗下Sun公司Java EE平台的设计模式,并且受到越来越多的使用ColdFusion和PHP的开发者的欢迎。
现在虽然不再使用原来的分工方式,但是这种分工的思想被沿用下来,广泛应用于软件工程中,是一种典型并且应用广泛的软件架构模式。
后来,MVC的思想被应用在了Web开发方面,被称为Web MVC框架。
3)MVC模式说明

M全拼为Model,主要封装对数据库层的访问,对数据库中的数据进行增、删、改、查操作。
V全拼为View,用于封装结果,生成页面展示的html内容。
C全拼为Controller,用于接收请求,处理业务逻辑,与Model和View交互,返回结果。
4)Django使用的程序设计模式——MVT(model-template-view): 模型-模板-视图

M全拼为Model,与MVC中的M功能相同,负责和数据库交互,进行数据处理。
V全拼为View,与MVC中的C功能相同,接收请求,进行业务处理,返回应答。
T全拼为Template,与MVC中的V功能相同,负责封装构造要返回的html。
注:MVC 与 MVT 模式差异
差异就在于黑线黑箭头标识出来的部分!!,具体差异不是很多,叫法和代码不同, 思路相同.
步骤一,创建 Django 项目
—— 应用集成开发环境(IDE:Integrated Development Environment): PyCharm
- cd /root/PycharmProjects/untitled/FirstDjango/ # 从命令行 cd 到您要存储代码的目录,然后运行以下命令:
- django-admin startproject BookManage # 创建项目 BookManage
创建项目 BookManage 生成的各个文件的作用 (重要):
settings.py 是项目的整体配置文件。
urls.py 是项目的URL配置文件。
wsgi.py 是项目与WSGI兼容的Web服务器入口。
manage.py 是项目管理文件,通过它管理项目。
步骤二,应用的 创建 和 使用
一,创建并配置 子应用
- python3 manage.py startapp bookApp # 添加项目的子应用 bookApp
创建 子应用bookApp 生成的中各个文件的作用(重要):
admin.py 文件跟网站的后台管理站点配置相关。
apps.py 文件用于配置当前子应用的相关信息。
migrations 目录用于存放数据库迁移历史文件。
models.py 文件用户保存数据库模型类。
tests.py 文件用于开发测试用例,编写单元测试。
views.py 文件用于编写Web应用视图。
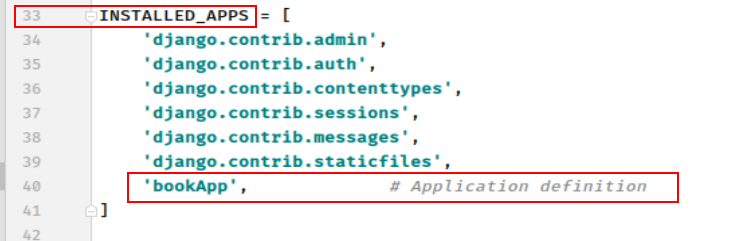
二,配置子应用 —— 创建出来的子应用目录文件虽然被放到了工程项目目录中,但是django工程并不能立即直接使用该子应用,需要注册安装后才能使用。
1)添加 子应用 bookApp 到 FirstDjango/ BookManage/settings 中
配置子应用信息也被称为: 注册安装一个子应用,即, 将子应用的配置信息文件apps.py中的Config类添加到INSTALLED_APPS列表中。
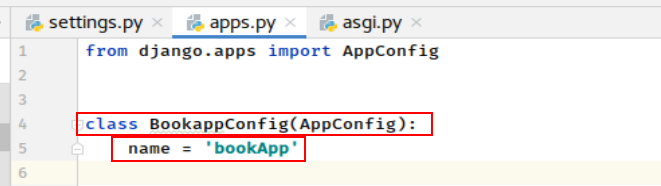
将创建的 bookApp 子应用中apps.py文件的信息( bookApp.apps.BookappConfig(AppConfig)), 添加到INSTALLED_APPS中, 如图所示:
三,创建视图 —— Django也用视图来编写Web应用的业务逻辑,且定义在子应用的 views.py 中的。
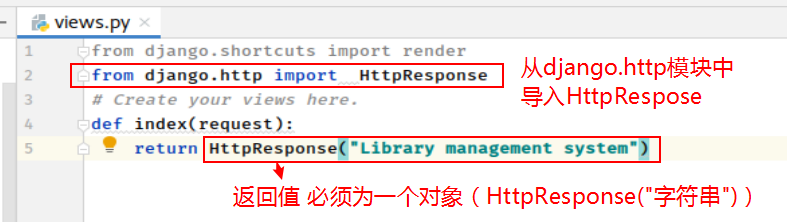
编辑 bookApp/views.py文件
- from django.http import HttpResponse # 从django.http模块中导入HttpRespose
- def index(request):
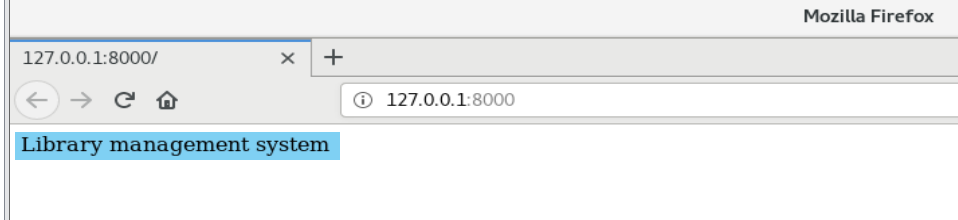
return HttpResponse("Library management system")
备注:
- 视图函数的第一个传入参数必须定义,用于接收Django构造的包含了请求数据的HttpReqeust对象,通常名为request。
- 视图函数的返回值必须为一个响应对象,不能像Flask一样直接返回一个字符串,可以将要返回的字符串数据放到一个HTTPResponse对象中。
四,定义路由URL
1) 在 子应用bookApp 中新建一个 urls.py文件 用于保存该应用的路由。
2) 在bookApp/urls.py文件中定义路由信息。
-
from django.conf.urls import url # 从urls模块中导入url
-
from . import views # 从当前目录导入我们的视图模块views
当用户访问 bookApp 应用的主页时,执行 视图函数 index ,反向根据名称获取 url地址
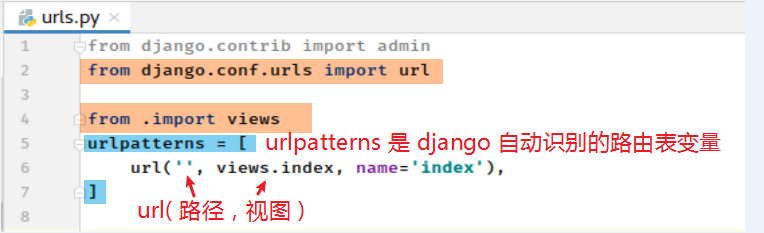
备注:每个路由信息都要由 url( )函数构造 !
3)根据配置文件 BookManage/settings 可知路由查找的主文件是 BookManage/urls.py , 因此在该文件
添加 子应用路由数据:

附:
include( )函数: 允许引用其他 URLconfs 。
url( ) 函数介绍
Django url() 可以接收四个参数,分别是两个必选参数: regex 、 view 和 两个可选参数:kwargs 、 name 。
regex : 正则表达式,与之匹配的 URL 会执行对应的第二个参数 view。
view : 用于执行与正则表达式匹配的 URL 请求。
kwargs : 视图使用的字典类型的参数。
name : 用来反向获取 URL。
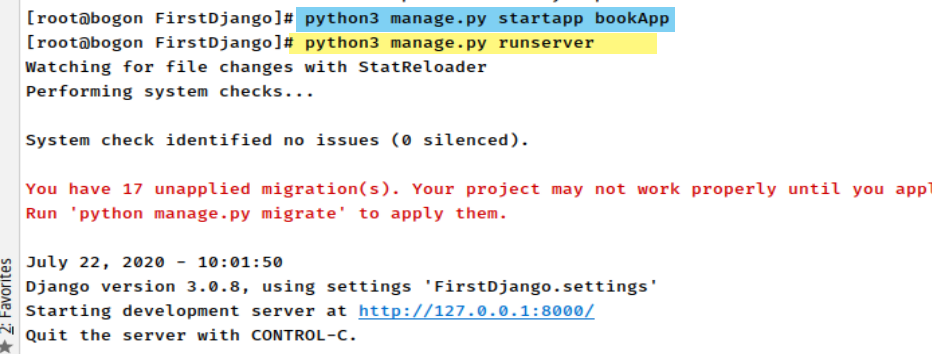
启动测试:
- python3 manage.py runserver
步骤三: 项目的数据库模型
0)创建数据库 BookManage
- mysqladmin -u root -p *** create BookManage charset=utf8; # root用户,可以使用 mysqladmin 命令来创建数据库
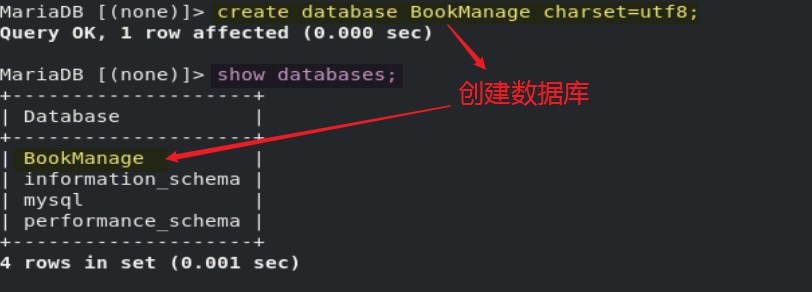
1) 连接 MySQL 数据库配置
在 BookManage/settings.py 文件中,通过DATABASES项进行数据库设置:
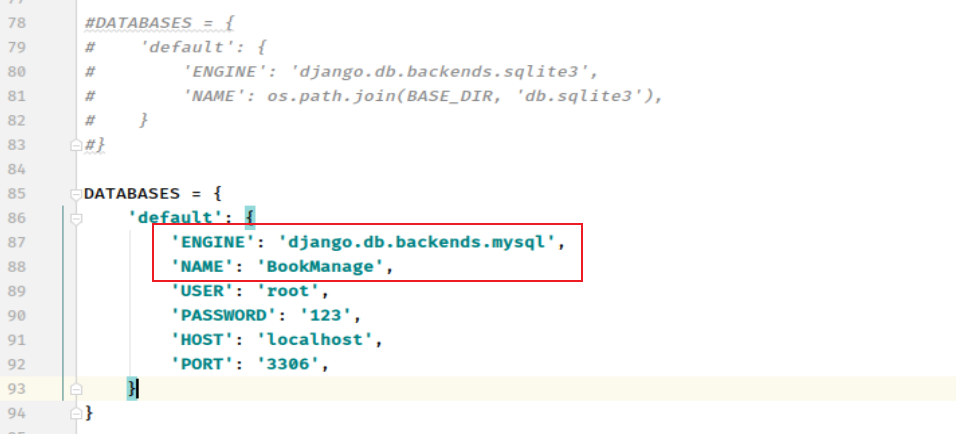
备注:其中 ENGINE设置 为数据库后端使用。内置数据库后端有:
'django.db.backends.postgresql'
'django.db.backends.mysql'
'django.db.backends.sqlite3' # SQLITE 为默认数据库
'django.db.backends.oracle'
Django 使用 MySQL 数据库需要安装 PyMySQL 以及 mysql-client
2)创建数据库模型 —— bookApp/models.py文件 中定义数据库信息
本示例完成“图书-英雄”信息的维护,需要存储两种数据:图书、英雄 (图书-英雄的关系为一对多)
图书表结构设计: 表名: Book
- 图书名称: title
- 图书发布时间: pub_date
英雄表结构设计: 表名: Hero
- 英雄姓名: name
- 英雄性别: gender
- 英雄简介: hcontent
- 所属图书: hbook
3)生成数据库表
- 激活模型:编辑 settings.py 文件,将应用加入到 INSTALLED_APPS 中
- 生成迁移文件:根据模型类生成 sql 语句
https://github.com/lvah/FirstDjango # 教学 GitHab 仓库链接 ,查看每一步骤的创建、添加、更改、删除 !!
创建数据库
1. pip install mysqlclient -i https://pypi.douban.com/simple
2. python manage.py migrate
3. python manage.py createsuperuser
4. python manage.py runserver
GitHub账号注册:
官方网站:https://github.com/
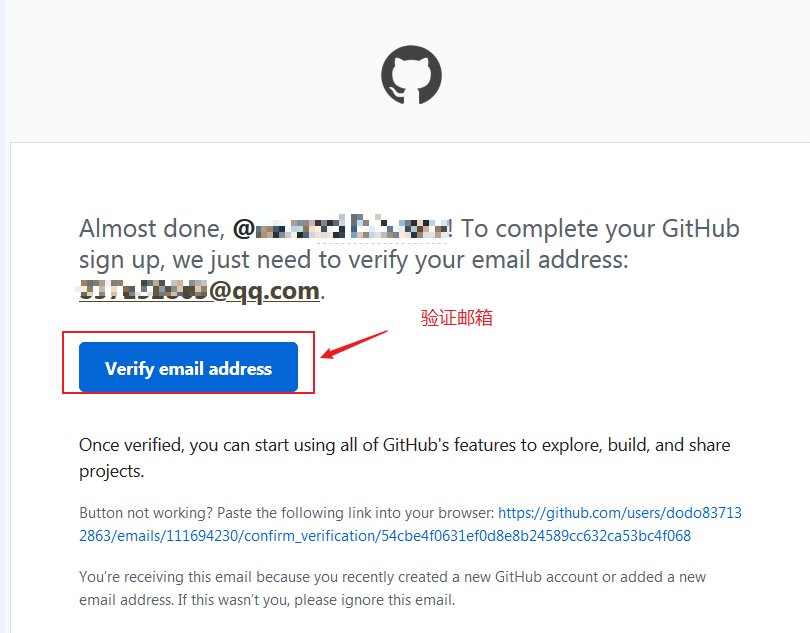
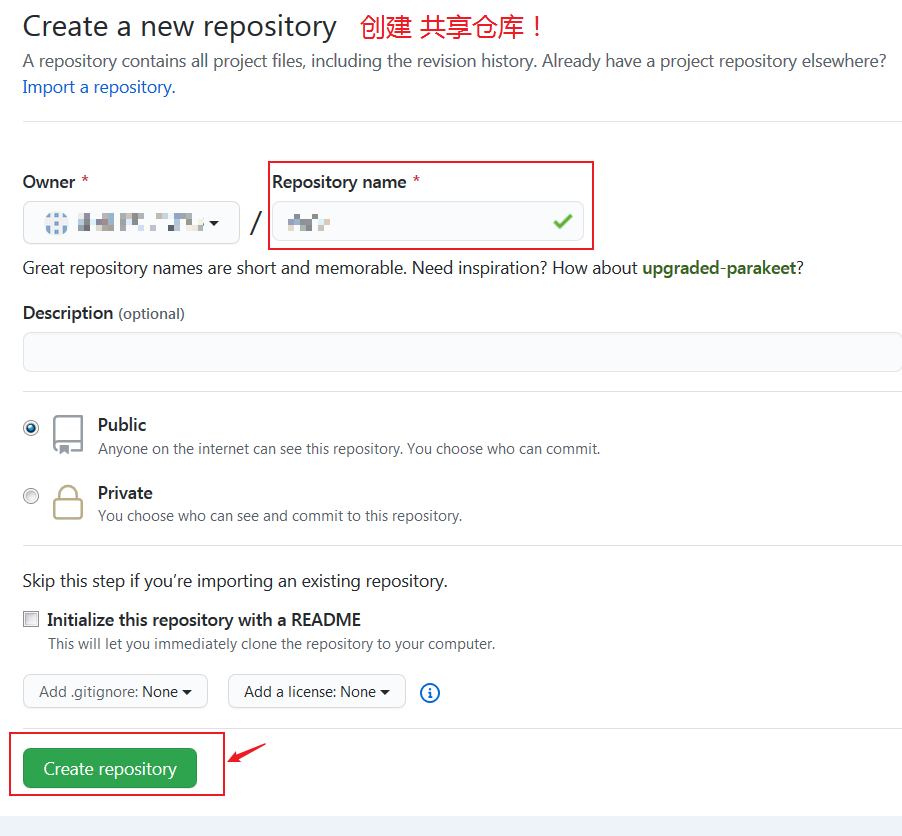
GitHub注册引导流程注释:
- Please verify your email address # 请确认您的电子邮件地址
- Before you can contribute on GitHub, we need you to verify your email address. # 在您可以在GitHub上投稿之前,我们需要您验证您的电子邮件地址。
- An email containing verification instructions was sent to ########@qq.com. #一封包含验证说明的电子邮件发送到########@qq.com。
- Start a new project # 开始一个新项目
- Start a new repository or bring over an existing repository to keep contributing to it. # 启动一个新的存储库或引入一个现有的存储库,以继续对其进行贡献。
- Initialize this repository with a README # 使用自述文件初始化此存储库
[root@bogon FirstDjango]# pwd # 工作区在 Pycharm 中查看
/root/PycharmProjects/untitled/FirstDjango
- dnf install git -y # 在Linux上是有yum安装Git
- git config --global user.name "dodo837132863" # 用户配置
- git config --global user.email "837132863@qq.com"
- cd /root/PycharmProjects/untitled/FirstDjango #进入项目目录
- git init
- git add *
- git commit -m "First"
- git log
- git remote add origin https://github.com/dodo837132863/dodo.git
- git push -u origin master
- vim README.md
- git commit -m "Second"
- git log
- git push -u origin master
7.21~23 周内作业
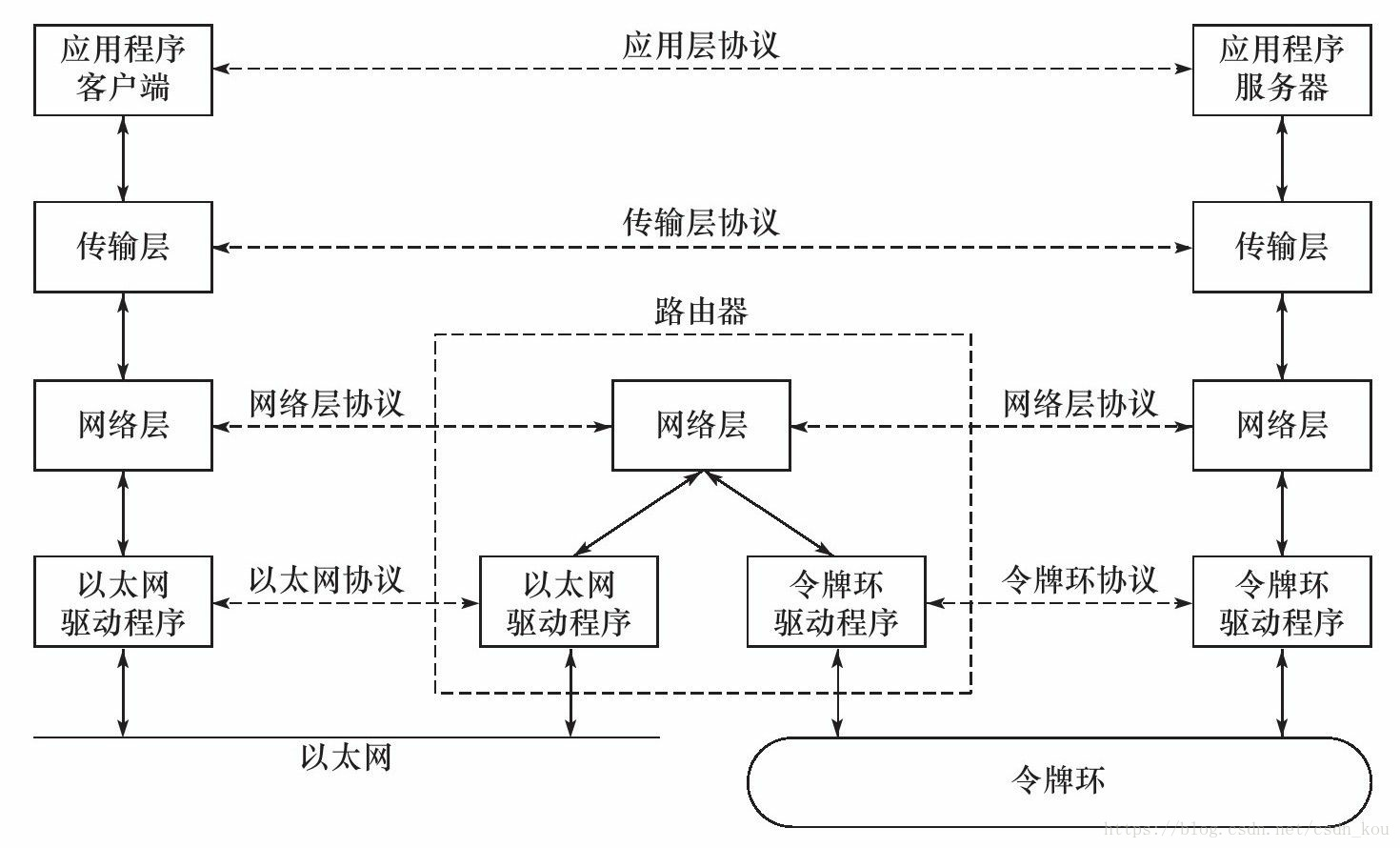
1. TCP/IP四层协议模型
TCP/IP协议族体系结构以及主要协议:
简介说明:TCP/IP协议族是一个四层协议系统,自底而上分别是数据链路层、网络层、传输层和应用层。每一层完成不同
的功能,且通过若干协议来实现,上层协议使用下层协议提供的服务。
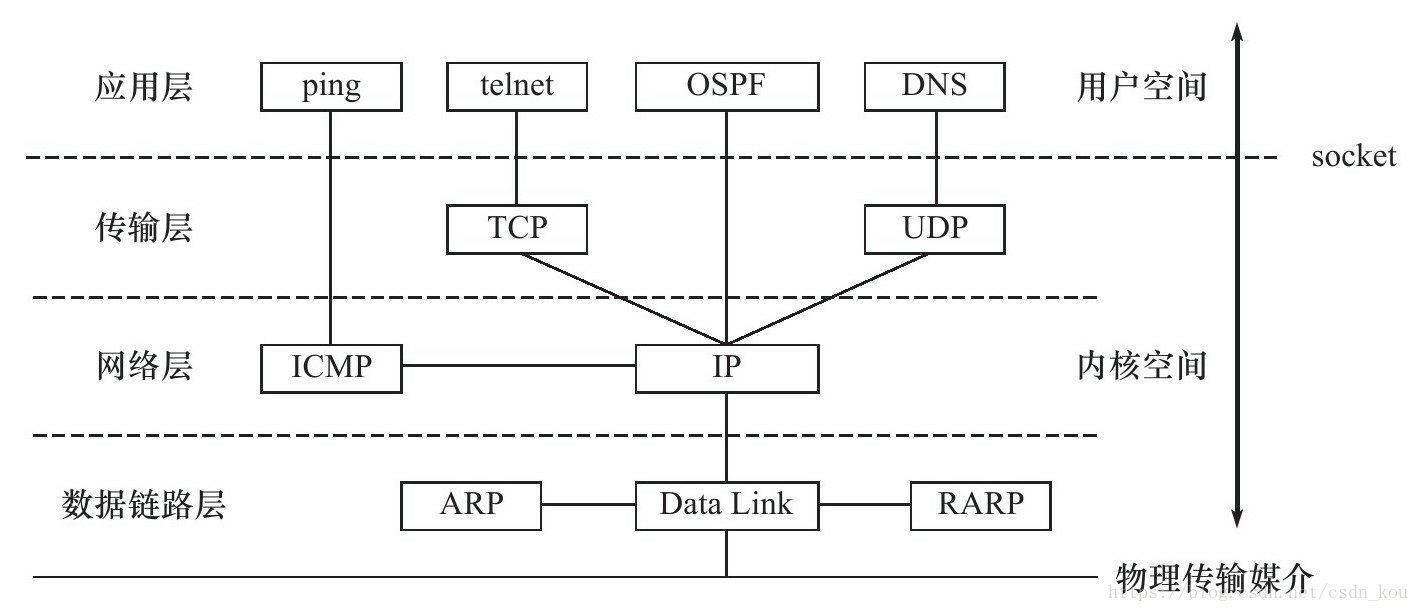
数据链路层 —— 数据链路层实现了网卡接口的网络驱动程序,以处理数据在物理媒介(比如以太网、令牌环等)上的传输。
数据链路层常用的协议:
- ARP协议(Address Resolve Protocol,地址解析协议):基本功能就是通过目标设备的IP地址,查询目标设备的MAC地址,以保证通信的顺利进行。
- RARP协议(ReverseAddress Resolve Protocol,逆地址解析协议):允许局域网的物理机器从网关服务器的 ARP 表或者缓存上请求其 IP 地址。
网络层 —— 网络层实现数据包的选路和转发。
网络层常用的协议是IP协议:
- IP(Internet Protocol,因特网协议):IP协议提供不可靠、无连接的传送服务。IP协议的主要功能有:无连接数据报传输、数据报路由选择和差错控制。 # IP协议是 网络层最核心的协议
- ICMP协议(Internet Control Message Protocol,因特网控制报文协议):是组播路由器用来维护组播组成员信息的协议,运行于主机和和组播路由器之间。IGMP 信息封装在IP报文中,其IP的协议号为2。
传输层 —— 传输层为两台主机上的应用程序提供端到端(end to end)的通信。与网络层使用的逐跳通信方式不同,传输层只关心通信的起始端和目的端,而不在乎数据包的中转过程。
传输层的常用协议:
- TCP协议(Transmission Control Protocol,传输控制协议):为应用层提供可靠的、面向连接的和基于流(stream)的服务。。
- UDP协议(User Datagram Protocol,用户数据报协议):则与TCP协议完全相反,它为应用层提供不可靠、无连接和基于数据报的服务。
应用层 —— 应用层负责处理应用程序的逻辑。
传输层的常用协议:
- Telnet 协议:是Internet远程登陆服务的标准协议和主要方式。为用户提供了在本地计算机上完成远程主机工作的能力。在终端使用者的电脑上使用telnet程序,用它连接到服务器。
- SSH 协议:安全外壳协议,为建立在应用层和传输层基础上的安全协议。SSH 是目前较可靠,专为远程登录会话和其他网络服务提供安全性的协议。
- HTTP 协议:超文本传输协议,基于TCP,是用于从WWW服务器传输超文本到本地浏览器的传输协议。它可以使浏览器更加高效,使网络传输减少。
- FTP 协议:文件传输协议,用于Internet上的控制文件的双向传输。同时也是一个应用程序。
- NFS 协议:网络文件系统,是FreeBSD支持的文件系统中的一种,允许网络中的计算机之间通过TCP/IP网络共享资源。
- SMTP 协议:简单邮件传输协议,是一组用于由源地址到目的地址传送邮件的规则,由它来控制信件的中转方式。
- SNMP 协议:简单网络管理协议,由一组网络管理的标准组成,包含一个应用层协议、数据库模型和一组资源对象。
备注:ping是应用程序,而不是协议!,前面说过它利用ICMP报文检测网络连接,是调试网络环境的必备工具。
2. TCP三次握手,四次分手,以及为什么?
基础知识详细认识 TCP协议 —— TCP全称是传输控制协议,其是面向连接的,可靠的,基于字节流的传输层通信协议。
相比与UDP(用户数据报协议)而言,具有以下几个特点:
- TCP协议是面向连接的。基于TCP协议,客户端和服务端要想传输数据,两者之间要先建立一个连接,然后客户端再跨该链接与服务端交换数据,最终终止连接。
- TCP提供可靠性。当TCP的一端向另一端传输数据之后,要求收到数据的一端必须要返回一个确认,如果没有收到这个确认,那么发送端会自动重传数据病等待更长时间,数次失败之后才会放弃(4-10分钟)。TCP提供的是可靠传输,但并不保证数据一定会被对方给接收到。如果多次重传都失败的话,TCP就会放弃重传并通知用户。
- TCP会给传输数据中的每一个字节关联一个序列号对所发送的数据进行排序。这样可以接受到的数据和发送的数据顺序保持一致并会包含重复数据。
- TCP提供流量控制。TCP总是会告诉对方任何时刻它一次能接受多少字节的数据(通告窗口),从而确保发送端发送的数据不会使接受缓冲区溢出。通告窗口随时会发生改变,当接收到了新的数据,通告窗口减少,当应用程序从缓冲区读取新的数据时,通告窗口会增大。
- TCP是面向全双工的。一个给定连接的应用在任何时刻既可以接收数据也可以发送数据。
疑问一,传递过程中出现的几个字符(SYN,ACK,FIN,seq,ack)各代表什么意思
- SYN,ACK,FIN存放在TCP的标志位,一共有6个字符,这里就介绍这三个:
- SYN:代表请求创建连接,所以在三次握手中前两次要SYN=1,表示这两次用于建立连接,至于第三次什么用,在疑问三里解答。
- FIN:表示请求关闭连接,在四次分手时,我们发现FIN发了两遍。这是因为TCP的连接是双向的,所以一次FIN只能关闭一个方向。
- ACK:代表确认接受,从上面可以发现,不管是三次握手还是四次分手,在回应的时候都会加上ACK=1,表示消息接收到了,并且在建立连接以后的发送数据时,都需加上ACK=1,来表示数据接收成功。
- seq:序列号,什么意思呢?当发送一个数据时,数据是被拆成多个数据包来发送,序列号就是对每个数据包进行编号,这样接受方才能对数据包进行再次拼接。
- 初始序列号是随机生成的,这样不一样的数据拆包解包就不会连接错了。(例如:两个数据都被拆成1,2,3和一个数据是1,2,3一个是101,102,103,很明显后者不会连接错误)
- ack:这个代表下一个数据包的编号,这也就是为什么第二请求时,ack是seq+1
三次握手过程解析 (每个箭头代表一次握手!)
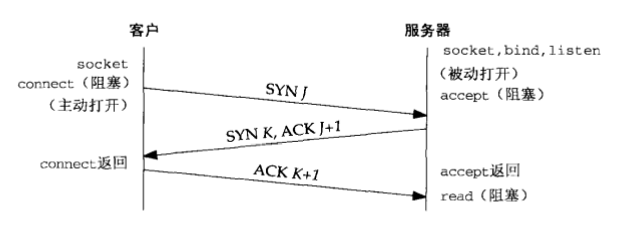
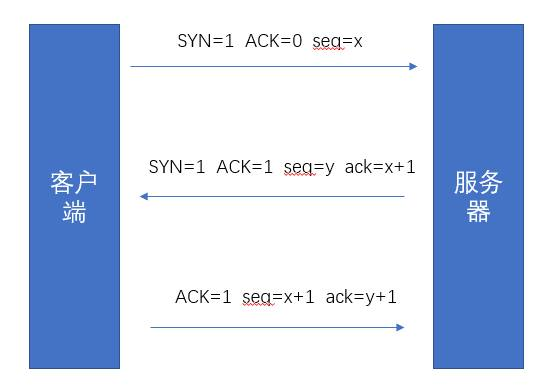
- 第一次握手:client发送一个SYN(J)包给server,然后等待server的ACK回复,进入SYN-SENT状态。p.s: SYN为synchronize的缩写,ACK为acknowledgment的缩写。
- 第二次握手:server接收到SYN(seq=J)包后就返回一个ACK(J+1)包以及一个自己的SYN(K)包,然后等待client的ACK回复,server进入SYN-RECIVED状态。
- 第三次握手:client接收到server发回的ACK(J+1)包后,进入ESTABLISHED状态。然后根据server发来的SYN(K)包,返回给等待中的server一个ACK(K+1)包。等待中的server收到ACK回复,也把自己的状态设置为ESTABLISHED。到此TCP三次握手完成,client与server可以正常进行通信了。
在创建连接时,
1.客户端首先要SYN=1,表示要创建连接,
2.服务端接收到后,要告诉客户端:我接受到了!所以加个ACK=1,就变成了ACK=1,SYN=1
3.理论上这时就创建连接成功了,但是要防止一个意外(见疑问三),所以客户端要再发一个消息给服务端确认一下,这时只需要ACK=1就行了。
三次握手完成!
我为什么没有在上面的过程中,加入seq和ack呢?就如我对这两个关键字的解释的一样,这两个是数据拆分和组装必备元素,所以所有的请求都需要这两个元素,只要明白了作用,就可以自己举一反三。
关于握手和分手,主要还是SYN,FIN,ACK的变化,这才是重点!
疑问,每次发送请求时为什么ack要+1?
关于seq和ack关键字的解释中已经说明了。
疑问,为什么需要三次握手,两次握手不行吗?
答1:为了保证服务端能收接受到客户端的信息并能做出正确的应答而进行前两次(第一次和第二次)握手,为了保证客户端能够接收到服务端的信息并能做出正确的应答而进行后两次(第二次和第三次)握手。
答2:这个问题的本质是, 信道不可靠, 但是通信双发需要就某个问题达成一致. 而要解决这个问题, 无论你在消息中包含什么信息, 三次通信是理论上的最小值. 所以三次握手不是TCP本身的要求, 而是为了满足"在不可靠信道上可靠地传输信息"这一需求所导致的. 请注意这里的本质需求,信道不可靠, 数据传输要可靠.
答3:三次握手的作用是为了解决网络中延迟的重复分组。
可能出现的问题:如果一个连接请求在网络中跑的慢,超时了,这时客户端会从发请求,但是这个跑的慢的请求最后还是跑到了,然后服务端就接收了两个连接请求,然后全部回应就会创建两个连接,浪费资源!
如果加了第三次客户端确认,客户端在接受到一个服务端连接确认请求后,后面再接收到的连接确认请求就可以抛弃不管了。
TCP 四次分手过程解析:
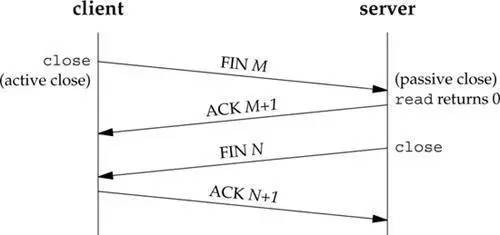
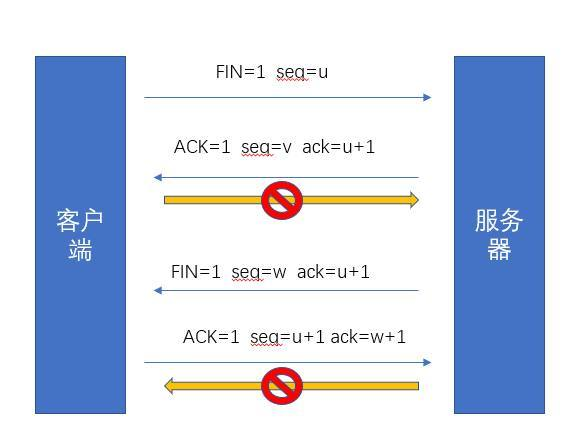
- 第一次分手:client发送一个FIN(M)包,此时client进入FIN-WAIT-1状态,这表明client已经没有数据要发送了。
- 第二次分手:server收到了client发来的FIN(M)包后,向client发回一个ACK(M+1)包,此时server进入CLOSE-WAIT状态,client进入FIN-WAIT-2状态。
- 第三次分手:server向client发送FIN(N)包,请求关闭连接,同时server进入LAST-ACK状态。
- 第四次分手:client收到server发送的FIN(N)包,进入TIME-WAIT状态。向server发送ACK(N+1)包,server收到client的ACK(N+1)包以后,进入CLOSE状态;client等待一段时间还没有得到回复后判断server已正式关闭,进入CLOSE状态。
1.首先客户端请求关闭客户端到服务端方向的连接,这时客户端就要发送一个FIN=1,表示要关闭一个方向的连接(见上面四次分手的图)
2.服务端接收到后是需要确认一下的,所以返回了一个ACK=1
3.这时只关闭了一个方向,另一个方向也需要关闭,所以服务端也向客户端发了一个FIN=1 ACK=1
4.客户端接收到后发送ACK=1,表示接受成功
四次分手完成!
疑问,为什么需要四次分手?
TCP是双向的,所以需要在两个方向分别关闭,每个方向的关闭又需要请求和确认,所以一共就4次。
3. HTTP的请求方式GET和POST有什么区别?
-
GET在浏览器回退时是无害的,而POST会再次提交请求。
-
GET产生的URL地址可以被Bookmark,而POST不可以。
-
GET请求会被浏览器主动cache,而POST不会,除非手动设置。
-
GET请求只能进行url编码,而POST支持多种编码方式。
-
GET请求参数会被完整保留在浏览器历史记录里,而POST中的参数不会被保留。
-
GET请求在URL中传送的参数是有长度限制的,而POST么有。
-
对参数的数据类型,GET只接受ASCII字符,而POST没有限制。
-
GET比POST更不安全,因为参数直接暴露在URL上,所以不能用来传递敏感信息。
-
GET参数通过URL传递,POST放在Request body中。
4. Django框架,Flask框架和Tornado框架各有什么优缺点?为什么你的项目会选择使用Django框架?
一、Django
主要特点是大而全,集成了很多组件,例如: Models Admin Form 等等, 不管你用得到用不到,反正它全都有,属于全能型框架
优点:
- 大和全(重量级框架)
- 自带orm,template,view
- 需要的功能也可以去找第三方的app
- 注重高效开发
- 全自动化的管理后台(只需要使用起ORM,做简单的定义,就能自动生成数据库结构,全功能的管理后台)
- session功能
缺点:
- template不怎么好用(来自自身的缺点)
- 数据库用nosql不方便(来自自身的缺点)
- 如果功能不多,容易臃肿
主要特点是原生异步非阻塞,在IO密集型应用和多任务处理上占据绝对性的优势,属于专注型框架
优点:
- 少而精(轻量级框架)
- 注重性能优越,速度快
- 解决高并发(请求处理是基于回调的非阻塞调用)
- 异步非阻塞
- websockets 长连接
- 内嵌了HTTP服务器
- 单线程的异步网络程序,默认启动时根据CPU数量运行多个实例;利用CPU多核的优势
- 自定义模块
缺点:
- 模板和数据库部分有很多第三方的模块可供选择,这样不利于封装为一个功能模块
主要特点小而轻,原生组件几乎为0, 三方提供的组件请参考Django 非常全面,属于短小精悍型框架
优点:
- 简单,Flask的路由以及路由函数由修饰器设定,开发人员不需要借助其他文件匹配;
- 配置灵活,有多种方法配置,不同环境的配置也非常方便;环境部署简单,Flask运行不需要借助其他任何软件,只需要安装了Python的IDE,在命令行运行即可。只需要在Python中导入相应包即可满足所有需求;
- 入门简单,通过官方指南便可以清楚的了解Flask的运行流程;
- 低耦合,Flask可以兼容多种数据库、模板。
缺点:
- 对于大型网站开发,需要设计路由映射的规则,否则导致代码混乱
5. 什么是ORM?有什么优势?
对象关系映射(Object Relational Mapping,简称ORM):是通过使用描述对象和数据库之间映射的元数据,将面向对象语言程序中的对象自动持久化到关系数据库中。本质上就是将数据从一种形式转换到另外一种形式。
- 隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来。 # 核心 优势
- ORM使我们构造固化数据结构变得简单易行。在ORM之前,我们需要将我们的对象模型转化为一条一条的SQL语句,通过直连或是DB helper在关系数据库构造我们的数据库体系。而现在,基本上所有的ORM框架都提供了通过对象模型构造关系数据库结构的功能。
6.migrations和migrate指令有什么区别?分别做了什么?
- migrations根据检测到的模型创建新的迁移。迁移的作用,更多的是将数据库的操作,以文件的形式记录下来,方便以后检查、调用、重做等等。
- migrate 使数据库状态与当前模型集和迁移集同步。说白了,就是将对数据库的更改,主要是数据表设计的更改,在数据库中真实执行。例如,新建、修改、删除数据表,新增、修改、删除某数据表内的字段等。
7. Django的请求生命周期是什么?

1、请求生命周期
-
- wsgi, 他就是socket服务端,用于接收用户请求并将请求进行初次封装,然后将请求交给web框架(Flask、Django)
-
- 中间件,帮助我们对请求进行校验或在请求对象中添加其他相关数据,例如:csrf、request.session
-
- 路由匹配
-
- 视图函数,在视图函数中进行业务逻辑的处理,可能涉及到:orm、templates => 渲染
-
- 中间件,对响应的数据进行处理。
-
- wsgi,将响应的内容发送给浏览器。
2、什么wsgi
wsgi:web服务网关接口
3、视图
- FBV
url - 函数
- CBV
url - view
FBV(function base view)与CBV(class base view)本质是一样的,只是fbv基于函数,cbv基于类。只不过fbv较cbv往后多执行了几步。
4、rest-framework
rest-framework从dispatch方法开始介入,执行完视图,如果有rest-framework组件,就执行rest-framework。
5、restfui规范
8.cookie和session的区别和用法。
1. 由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是Session.典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。这个Session是保存在服务端的,有一个唯一标识。在服务端保存Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑Session的转移,在大型的网站,一般会有专门的Session服务器集群,用来保存用户会话,这个时候 Session 信息都是放在内存的,使用一些缓存服务比如Memcached之类的来放 Session。
2. 思考一下服务端如何识别特定的客户?这个时候Cookie就登场了。每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie 来实现Session跟踪的,第一次创建Session的时候,服务端会在HTTP协议中告诉客户端,需要在 Cookie 里面记录一个Session ID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。有人问,如果客户端的浏览器禁用了 Cookie 怎么办?一般这种情况下,会使用一种叫做URL重写的技术来进行会话跟踪,即每次HTTP交互,URL后面都会被附加上一个诸如 sid=xxxxx 这样的参数,服务端据此来识别用户。
3. Cookie其实还可以用在一些方便用户的场景下,设想你某次登陆过一个网站,下次登录的时候不想再次输入账号了,怎么办?这个信息可以写到Cookie里面,访问网站的时候,网站页面的脚本可以读取这个信息,就自动帮你把用户名给填了,能够方便一下用户。这也是Cookie名称的由来,给用户的一点甜头。
所以,总结一下:
Session是在服务端保存的一个数据结构,用来跟踪用户的状态,这个数据可以保存在集群、数据库、文件中;
Cookie是客户端保存用户信息的一种机制,用来记录用户的一些信息,也是实现Session的一种方式。
9. 快速排序算法。
快速排序是对冒泡排序的一种改进,是由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
快排的主要步骤(升序排列):
第一步:先确立一个基准,也就是说,第一趟排序下来,左边的元素都比基准元素小,右边的都比基准元素大(当然这是在升序排列的情况下,降序反之)。一般都选取最后一个或者第一个元素,即temp=a[0]或者temp=a[N-1]。
i=left(左边第一个元素的下标),j=right(最后一个元素的下标。)
第二步:先从右往左(j--),遇到第一个比temp还要小的元素(即a[j]<=temp),就停止查找,把两个元素值交换。a[i]=a[j]
第三步:从左往右(i++),遇到第一个比temp大的元素(即a[i]>=temp),就停止查找,把两个元素值交换.a[j]=a[i]。
第四步:分成了两个区,继续使用这个方法,直到分出来的去只有一个元素为止。
就拿a[]={5,2,7,1,8,4,9,3,6,10}这组数来举例。
第一步:temp=a[0]=5;i=0,j=9;
第二步:j--查找,当j=7时,a[j]<=temp,则a[i]=a[j],a[j]=temp,数组变为{3,2,7,1,8,4,9,5,6,10}。
然后i++查找,i=2时,a[i]>=temp,则a[j]=a[i],a[i]=temp。数组变为{3,2,5,1,8,4,9,7,6,10}。
然后在开始重复第二步的动作,直到i=j时停止。
第三步:这时的数组为:1 2 3 4 5 8 9 7 6 10。这时i=4,分为两个区间【0~3】和【5~9】重复第一步和第二步。就可以了。
最后输出结果:1 2 3 4 5 6 7 8 9 10。
//Quicksort
#include<stdio.h>
#include<string.h>
void display(int a[],int len)
{
int i=0;
for(i=0;i<len;i++)
printf("%d ",a[i]);
printf("\n");
}
void sort(int a[],int left,int right)
{
int i=left,j=right;
int temp=a[i];
if(left>=right)//如果左右下标不对,直接返回 。
return;
while(i!=j)
{
/*先从右往左,当遇到第一个小于temp的值得时候
跳出循环。a[i]赋值为a[j],这里的a[i]=temp=a[left];*/
while(i<j&&a[j]>=temp)
j--;
if(i<j)
a[i]=a[j];
/*在从左往右,当遇到第一个大于temp的时候,跳出循环
a[j]赋值为a[i]*/
while(i<j&&a[i]<=temp)
i++;
if(i<j)
a[j]=a[i];
}
a[i]=temp;//然后把中间的值换为temp.然后放区,再次循环。
sort(a,left,i-1);
sort(a,i+1,right);
}
int main()
{
int a[]={5,2,7,1,8,4,9,3,6,10},len;
len=sizeof(a)/sizeof(int);
sort(a,0,len-1);
display(a,len);
return 0;
}















 885
885











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









