







【1】HashSet:底层数据结构是哈希表。 HashSet是如何保证元素的唯一性的呢?
是通过两个方法,hashCode和equals来完成。
如果元素的hashCode值相同,才会判断equals是否为true.
如果元素的hashCode值不同,不会调用equals.
注意,对于判断元素是否存在,以及删除操作,依赖的方法是元素的hashCode和equals方法。HashSet
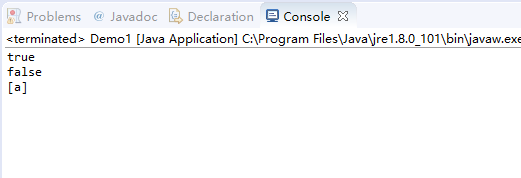
public class Demo1 {
public static void main(String[] args) {
HashSet<String> hs = new HashSet<>(); //创建HashSet对象
boolean b1 = hs.add("a");
boolean b2 = hs.add("a"); //当存储不成功的时候,返回false
System.out.println(b1);
System.out.println(b2);
System.out.println(hs); //HashSet中有重写toString方法
}
}输出
存储自定义对象时,一定要保证元素唯一性
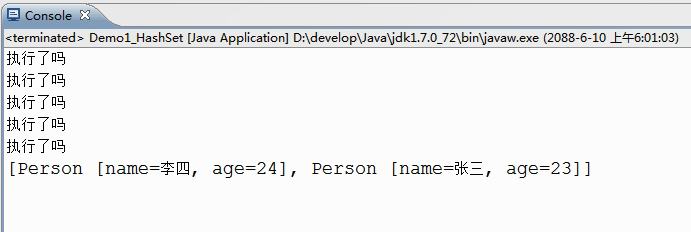
public class Demo1_HashSet {
/**
* @param args
* 往hashSet集合中存入自定对象,姓名和年龄相同为同一个人,重复元素
*/
public static void main(String[] args) {
//demo1();
HashSet<Person> hs = new HashSet<>();
hs.add(new Person("张三", 23));
hs.add(new Person("张三", 23));
hs.add(new Person("李四", 24));
hs.add(new Person("李四", 24));
hs.add(new Person("李四", 24));
hs.add(new Person("李四", 24));
System.out.println(hs);
}public class Person implements Comparable<Person> {
private String name;
private int age;
public Person() {
super();
}
public Person(String name, int age) {
super();
this.name = name;
this.age = age;
}
@Override
public String toString() {
return "Person [name=" + name + ", age=" + age + "]";
}
/*@Override
public boolean equals(Object obj) {
System.out.println("执行了吗");
Person p = (Person)obj;
return this.name.equals(p.name) && this.age == p.age;
}
@Override
public int hashCode() { //几个对象都是new出来的,如果不改写hashCode方法,他们的hash值都不等. 改写hashCode方法最好让不同的元素hash值不同
final int NUM = 31;
return name.hashCode() * NUM + age; //name.hashCode() 相同名字返回的hashcode才相同
}
HashSet原理
* 我们使用Set集合都是需要去掉重复元素的, 如果在存储的时候逐个equals()比较, 效率较低,哈希算法提高了去重复的效率, 降低了使用equals()方法的次数
* 当HashSet调用add()方法存储对象的时候, 先调用对象的hashCode()方法得到一个哈希值, 然后在集合中查找是否有哈希值相同的对象
* 如果没有哈希值相同的对象就直接存入集合
* 如果有哈希值相同的对象, 就和哈希值相同的对象逐个进行equals()比较,比较结果为false就存入, true则不存
* 2.将自定义类的对象存入HashSet去重复
* 类中必须重写hashCode()和equals()方法
* hashCode(): 属性相同的对象返回值必须相同, 属性不同的返回值尽量不同(提高效率)
* equals(): 属性相同返回true, 属性不同返回false,返回false的时候存储
小练习:需求:编写一个程序,获取10个1至20的随机数,要求随机数不能重复。并把最终的随机数输出到控制台。
import java.util.HashSet;
import java.util.Random;
public class Test1 {
/**
* * A:案例演示
* 需求:编写一个程序,获取10个1至20的随机数,要求随机数不能重复。并把最终的随机数输出到控制台。
*
* 分析:
* 1,有Random类创建随机数对象
* 2,需要存储10个随机数,而且不能重复,所以我们用HashSet集合
* 3,如果HashSet的size是小于10就可以不断的存储,如果大于等于10就停止存储
* 4,通过Random类中的nextInt(n)方法获取1到20之间的随机数,并将这些随机数存储在HashSet集合中
* 5,遍历HashSet
*/
public static void main(String[] args) {
//1,有Random类创建随机数对象
Random r = new Random();
//2,需要存储10个随机数,而且不能重复,所以我们用HashSet集合
HashSet<Integer> hs = new HashSet<>();
//3,如果HashSet的size是小于10就可以不断的存储,如果大于等于10就停止存储
while(hs.size() < 10) {
//4,通过Random类中的nextInt(n)方法获取1到20之间的随机数,并将这些随机数存储在HashSet集合中
hs.add(r.nextInt(20) + 1);
}
// 5,遍历HashSet
for (Integer integer : hs) {
System.out.println(integer);
}
}
}
LinkedHashSet
LinkedHashMap/LinkedHashSet 顾名思义,就是在Hash的实现上添加了Linked的支持。对于HashMap/HashSet的每个节点上通过一个链表串联起来,这样就可以保证确定的顺序。对于希望有常量复杂度的高效存取性能要求,同时有要求排序的情况下,现在可以直接使用LinkedHashMap/Set了。
对于LinkedHashMap还有一点特别注意,LinkedHashMap支持两种排序:插入顺序、访问顺序。前者是指按照插入时的顺序排序,后者是指按照最旧使用到最近使用的顺序。即如果在一个LinkedHashMap中有5个节点,现在的顺序是e1, e2, e3, e4, e5. 如果是使用顺序的话,现在访问了一次e2, 那么e2节点将移至链表的尾部。现在顺序变为:e1, e3, e4, e5, e2.
public class Demo2_LinkedHashSet {
/**
* @param args
* LinkedHashSet
* 底层是链表实现的,是set集合中唯一一个能保证怎么存就怎么取的集合对象
* 因为是HashSet的子类,所以也是保证元素唯一的,与HashSet的原理一样
*/
public static void main(String[] args) {
LinkedHashSet<String> lhs = new LinkedHashSet<>();
lhs.add("a");
lhs.add("a");
lhs.add("a");
lhs.add("a");
lhs.add("b");
lhs.add("c");
lhs.add("d");
System.out.println(lhs);
}
}输出:abcd
小练习
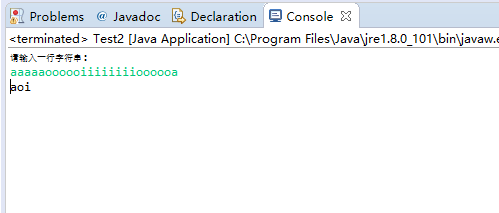
使用Scanner从键盘读取一行输入,去掉其中重复字符, 有序打印出不同的那些字符
import java.util.LinkedHashSet;
import java.util.Scanner;
public class Test2 {
/**
* * 使用Scanner从键盘读取一行输入,去掉其中重复字符, 打印出不同的那些字符
* aaaabbbcccddd
*
* 分析:
* 1,创建Scanner对象
* 2,创建LinkedHashSet对象,将字符存储,去掉重复,有序输出
* 3,将字符串转换为字符数组,获取每一个字符存储在HashSet集合中,自动去除重复
* 4,遍历HashSet,打印每一个字符
*/
public static void main(String[] args) {
//1,创建Scanner对象
Scanner sc = new Scanner(System.in);
System.out.println("请输入一行字符串:");
//2,创建LinkedHashSet对象,将字符存储,去掉重复
LinkedHashSet<Character> hs = new LinkedHashSet<>();
//3,将字符串转换为字符数组,获取每一个字符存储在HashSet集合中,自动去除重复
String line = sc.nextLine();
char[] arr = line.toCharArray();
for (char c : arr) { //遍历字符数组
hs.add(c);
}
//4,遍历HashSet,打印每一个字符
for(Character ch : hs) {
System.out.print(ch);
}
}
}
TreeSet
TreeSet可以对Set集合中的元素进行排序。 底层数据结构是二叉树
保证元素唯一性的依据是 comparaTo方法return 0.
例:
public static void main(String[] args) {
TreeSet<Integer> ts = new TreeSet<>();
ts.add(3);
ts.add(1);
ts.add(1);
ts.add(2);
ts.add(2);
ts.add(3);
ts.add(3);
System.out.println(ts);
}
输出: 按照数值大小比较 [1.2.3]
TreeSet自定义存储
从上例可以看出,TreeSet在存储数值时是按数值大小排序,那么对自定义对象进行存储的时候,按照什么方法比较呢?
TreeSet底层是依照 comparaTo方法比较的,我们想比较自定义对象的话,就要Override comparaTo方法
comparaTo返回负数

comparaTo返回正数

import java.util.Comparator;
import java.util.TreeSet;
import com.heiam.bean.Person;
public class Demo3_TreeSet {
/**
* @param args
* TreeSet集合是用来对象元素进行排序的,同样他也可以保证元素的唯一
* 当compareTo方法返回0的时候集合中只有一个元素
* 当compareTo方法返回正数的时候集合会怎么存就怎么取
* 当compareTo方法返回负数的时候集合会倒序存储
*/
public static void main(String[] args) {
TreeSet<Person> ts = new TreeSet<>();
ts.add(new Person("张三", 23));
ts.add(new Person("李四", 13));
ts.add(new Person("周七", 13));
ts.add(new Person("王五", 43));
ts.add(new Person("赵六", 33));
System.out.println(ts);
} /*@Override
//按照年龄排序
public int compareTo(Person o) {
int num = this.age - o.age; //年龄是比较的主要条件
return num == 0 ? this.name.compareTo(o.name) : num;//姓名是比较的次要条件
}*/
/*@Override
//按照姓名排序
public int compareTo(Person o) {
int num = this.name.compareTo(o.name); //姓名是主要条件
return num == 0 ? this.age - o.age : num; //年龄是次要条件
}*/TreeSet原理
TreeSet是用来排序的, 可以指定一个顺序, 对象存入之后会按照指定的顺序排列
使用方式
a.自然顺序(Comparable)
* TreeSet类的add()方法中会把存入的对象提升为Comparable类型
* 调用对象的compareTo()方法和集合中的对象比较
* 根据compareTo()方法返回的结果进行存储
b.比较器顺序(Comparator)
* 创建TreeSet的时候可以制定 一个Comparator
* 如果传入了Comparator的子类对象, 那么TreeSet就会按照比较器中的顺序排序
* add()方法内部会自动调用Comparator接口中compare()方法排序
* 调用的对象是compare方法的第一个参数,集合中的对象是compare方法的第二个参数
c.两种方式的区别
* TreeSet构造函数什么都不传, 默认按照类中Comparable的顺序(没有就报错ClassCastException)
* TreeSet如果传入Comparator, 就优先按照Comparator
Comparetor方式排序
TreeSet排序的第一种方式:让元素自身具备比较性。元素需要实现Comparable接口,覆盖comparaTo方法。
TreeSet的第二种排序方式。当元素自身不具备比较性时,或者具备的比较性不是所需要的。这时就需要让集合自身具备比较性。在集合初始化时,就具备比较方式。
例子
student类
public class Student implements Comparable
{
private String name;
private int age;
Student(String name,int age)
{
this.name = name;
this.age = age;
}
public int compareTo(Object obj) //重写compareTo方法,按年龄排序
{
if(!(obj instanceof Student))
throw new RuntimeException("不是学生对象");
Student s = (Student)obj;
if(this.age>s.age)
return 1;
if(this.age == s.age)
{
return this.name.compareTo(s.name);
}
return -1;
}
public String getName()
{
return name;
}
public int getAge()
{
return age;
}
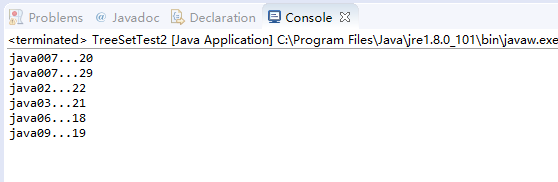
}public class TreeSetTest2
{
public static void main(String[] args)
{
TreeSet ts = new TreeSet(new MyCompare()); //加new MyCompare() 就是按名字排名,不加就按年龄排名。
ts.add(new Student("java02",22));
ts.add(new Student("java03",21));
ts.add(new Student("java007",20));
ts.add(new Student("java09",19));
ts.add(new Student("java06",18));
ts.add(new Student("java007",29));
Iterator it = ts.iterator();
while(it.hasNext())
{
Student stu = (Student)it.next();
System.out.println(stu.getName()+"..."+stu.getAge());
}
}
}MyCompare
public class MyCompare implements Comparator //实现Comparator接口 按名字排序
{
public int compare(Object o1,Object o2)
{
Student s1 = (Student)o1;
Student s2 = (Student)o2;
int num = s1.getName().compareTo(s2.getName());
if(num==0)
{
if(s1.getAge()>s2.getAge())
return 1;
if(s2.getAge()==s2.getAge())
return 0;
return -1;
}
return num;
}
}















 781
781

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









