







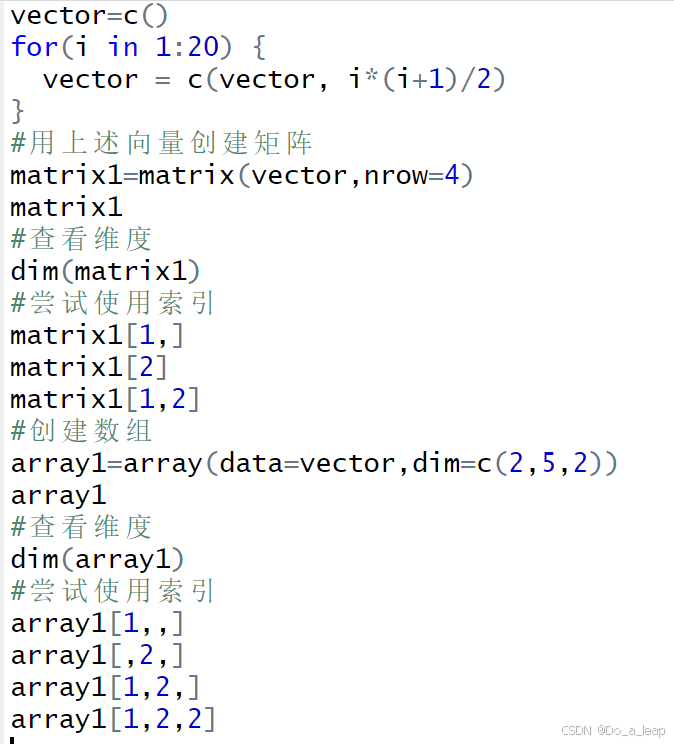
| 1.(1)第n个三角形数表示为n*(n+1)/2,创建一个包含前20个三角形数的序列。R有一个内置函数letters,它包含小写的罗马字母。使用前20个英文字母来给你刚刚创建的向量命名,选择命名为元音的三角数。 (2)用上面向量的值分别创建一个4*5的矩阵,2*5*2的数组,尝试维度、索引函数; (3)diag函数有几种用途,其中之一是以输入向量作为对角线来创建一个方阵,使用序列10到0创建一个11*11的矩阵; (4)将1, 2, · · · , 20 构成4 × 5 的矩阵,其中矩阵A是按列输入,矩阵B是按行输入,矩阵C由A的前3行和前3列构成,矩阵D由矩阵B的各列构成,但不含第3列。 (5)设x=(1,3,5,7,9)T,构造5×3矩阵X,其中第1列全为1,第2列为向量x,第3列的元素为x2,并给矩阵的3列命名,分别是const,x,x^2. (1)代码:
结果:
最后输出的向量最后一个为NA是因为没有命名为u的数字,所以为空 (2)代码:
结果: 矩阵:
查看矩阵维度:
尝试对矩阵进行索引:
数组:
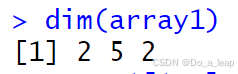
查看数组维度:
尝试对数组进行索引:
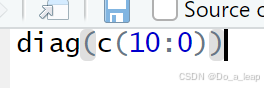
(3)代码:
结果:
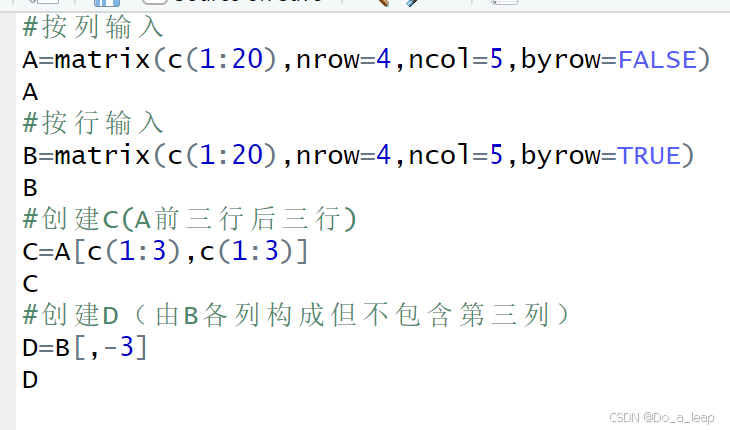
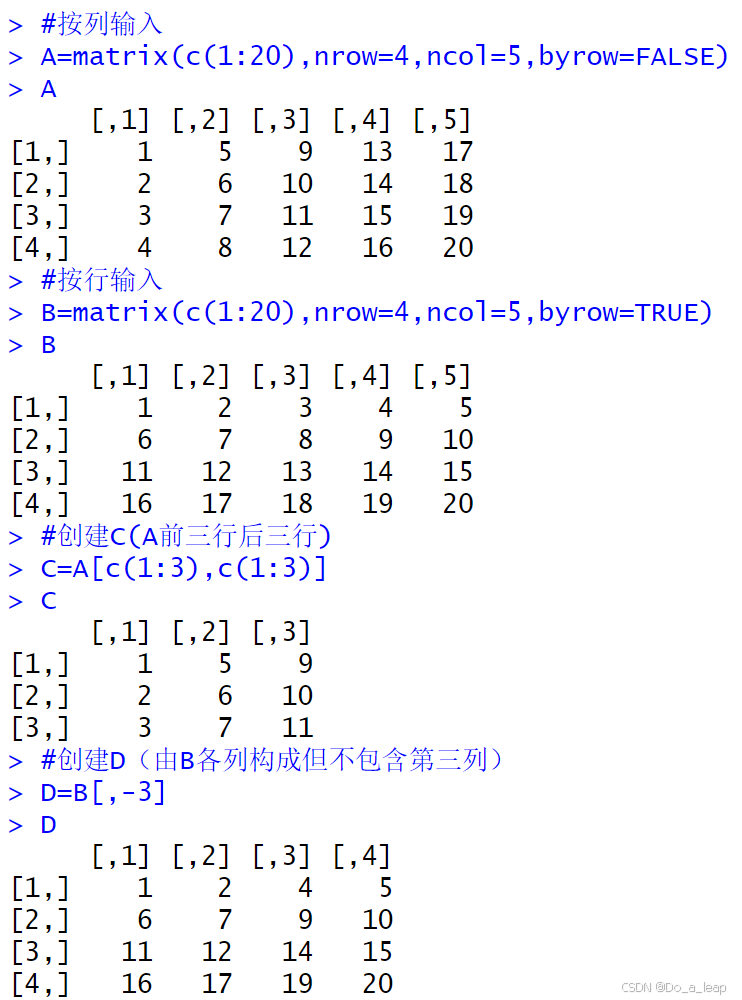
(4)代码:
结果:
(5)代码:
结果:
命名后的矩阵X
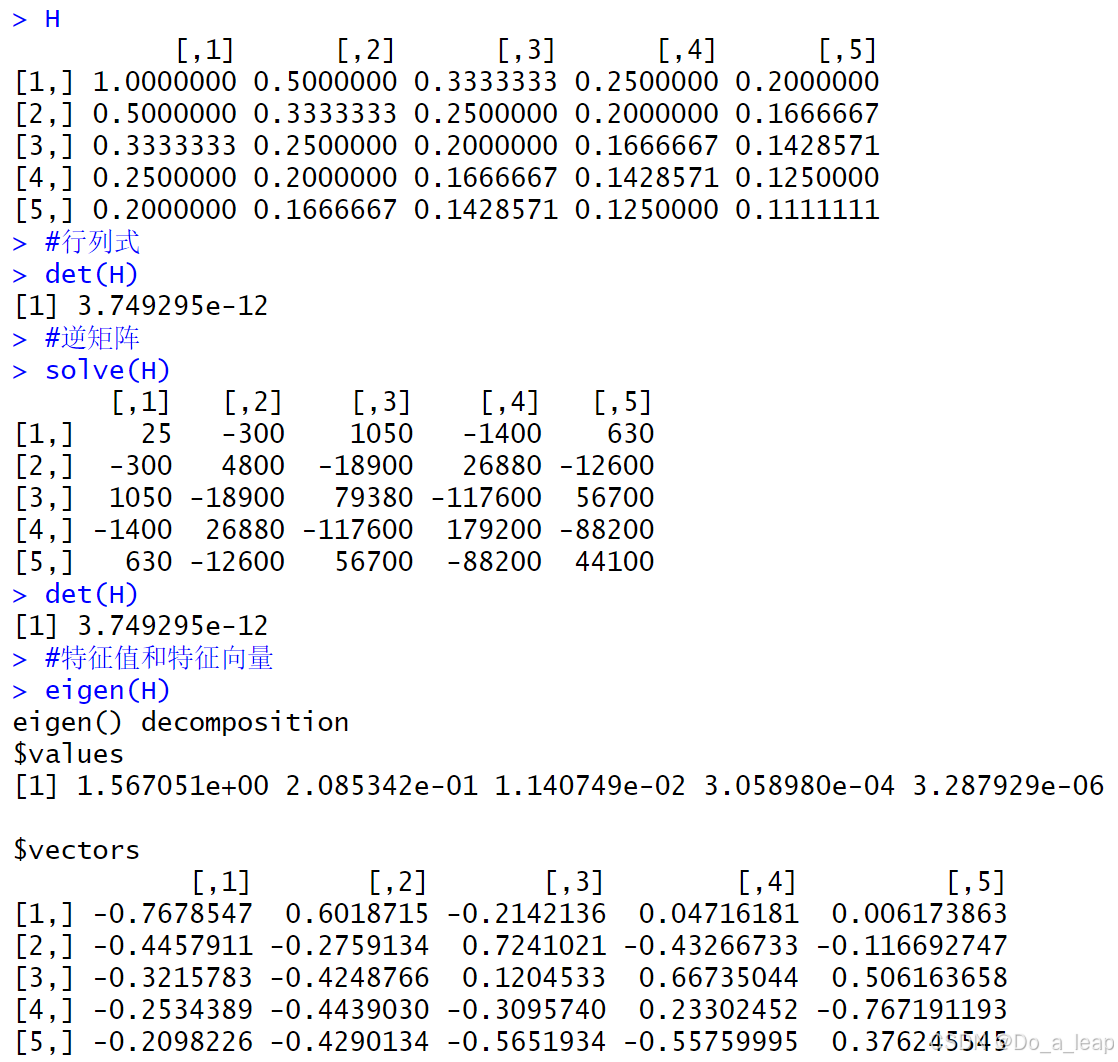
H = (hij)n×n, hij= 1/(i+j-1), i, j=1,2,...,n (2) 求H的逆矩阵; (3) 求H的行列式、特征值和特征向量。 代码:
结果: (1)
其中values是特征值,vectors是特征向量
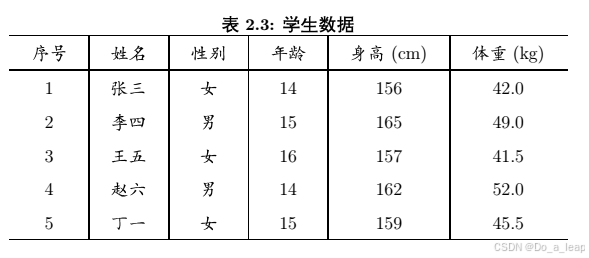
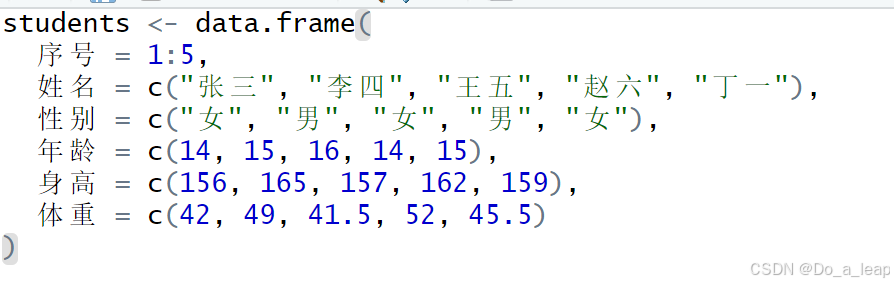
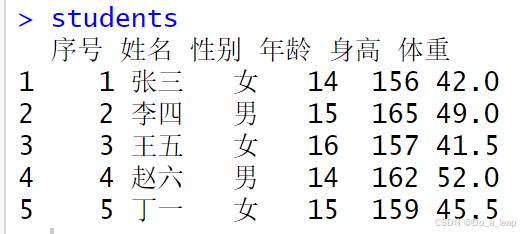
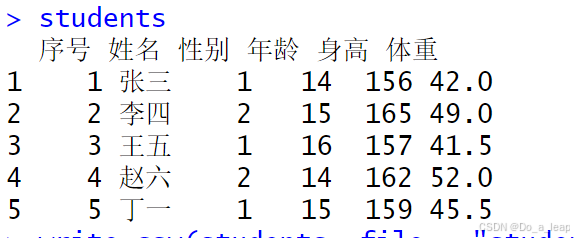
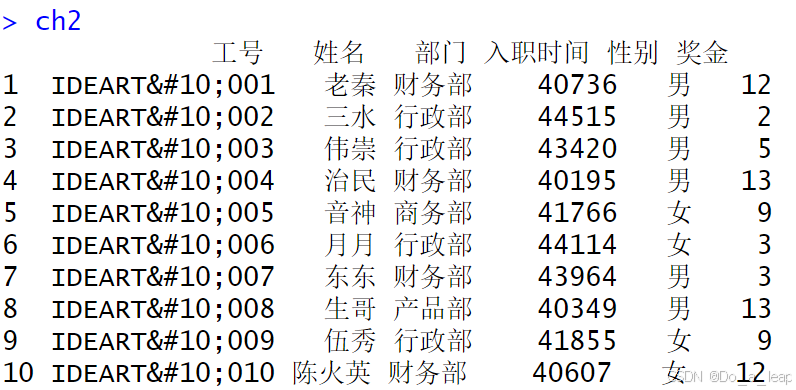
(1)用数据框的形式输入数据; (2)索引所有女生的年龄、身高和体重数据; (3)分别使用attach()/detach()和with()函数画身高和体重的散点图; (4)给出性别和年龄的列联表; (5)将性别设置为因子,女用1表示,男用2表示; (6)用write.csv()将上表的数据写成一个纯文本文件,存放在当前工作目录下,再用函数read.table()读入该文件。 (1)用数据框的形式输入数据; 代码:
结果:
(2)索引所有女生的年龄、身高和体重数据; 代码:
结果:
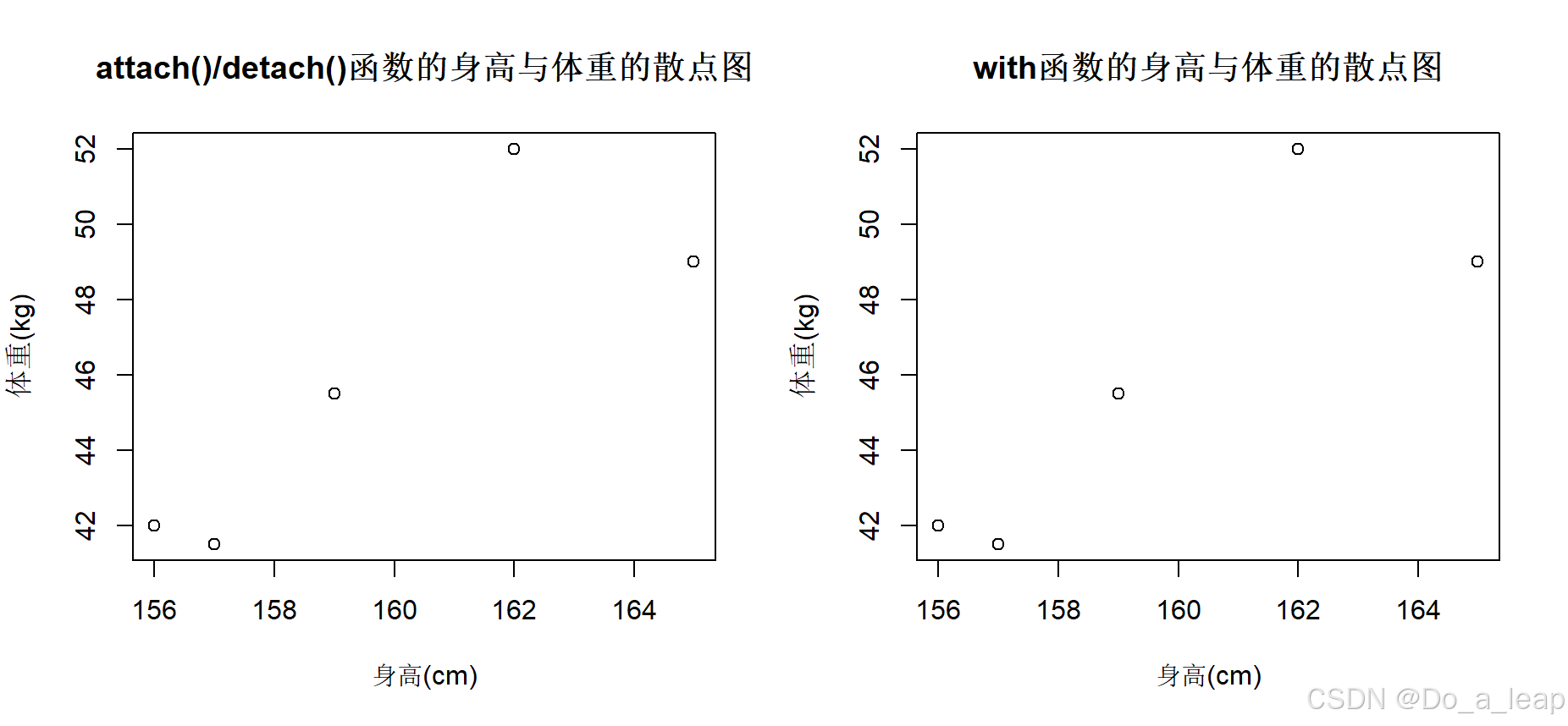
(3)分别使用attach()/detach()和with()函数画身高和体重的散点图; 代码:
(4)给出性别和年龄的列联表; 代码: 结果:
(5)将性别设置为因子,女用1表示,男用2表示; 代码:
结果:
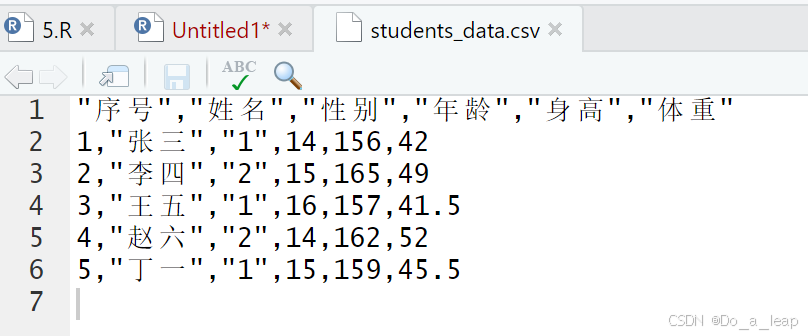
(6)用write.csv()将上表的数据写成一个纯文本文件,存放在当前工作目录下,再用函数read.table()读入该文件。 代码:
读取文件后的数据结果:
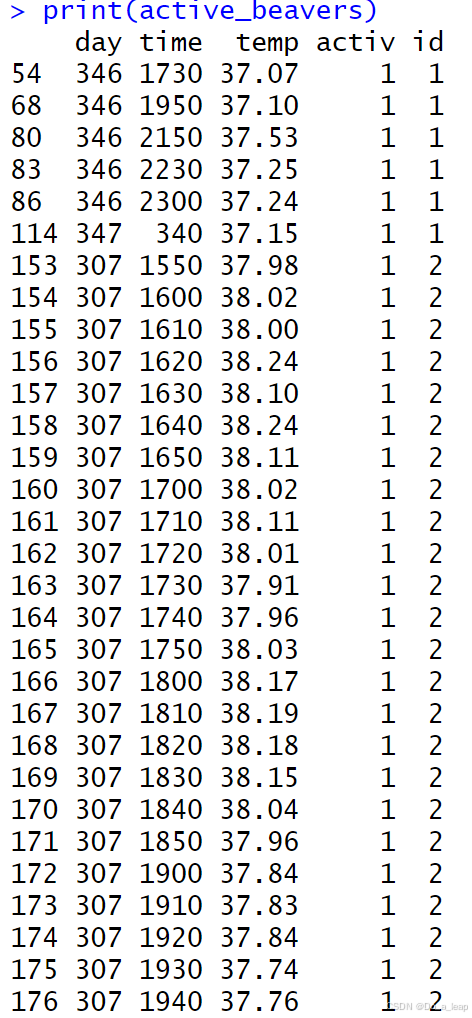
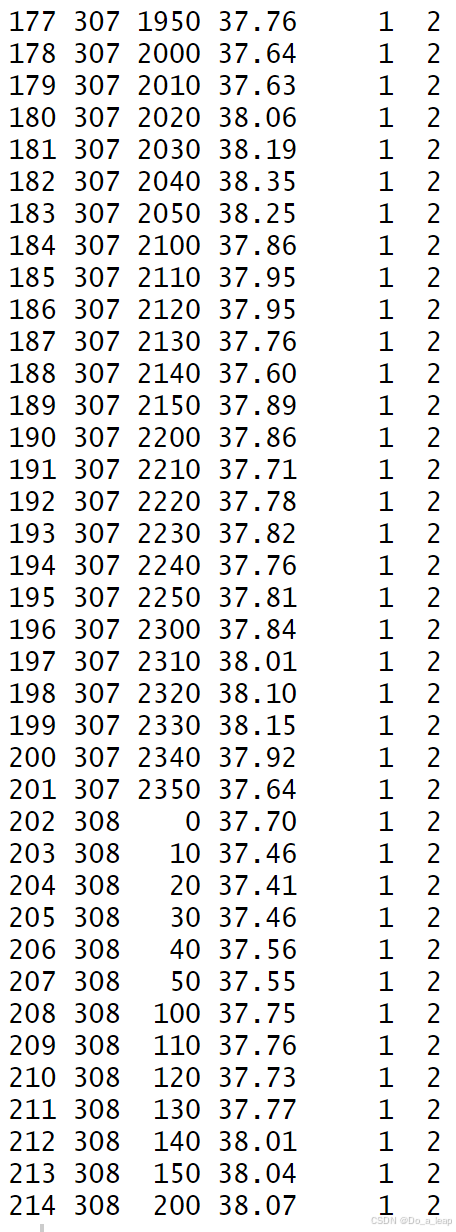
beaver1和beaver2数据集包含两个海狸的体温数据。为beaver1数据集添加一列名为id的列,其值全为1,为beaver2添加一个id列,值全为2. 垂直拼接两个数据框,并且找到所有活跃着的海狸的子集。 (1)代码:
结果:
(2)问题一:鸢尾花 代码:
结果:
问题二:海狸 代码:
结果: 活跃着的海狸
代码:
结果:
(2)将其中的变量“部门”、“性别”定义为因子,并统计频数信息; 代码:
结果:
(3)使用tapply函数计算各部门的平均奖金。 代码:
结果:
|








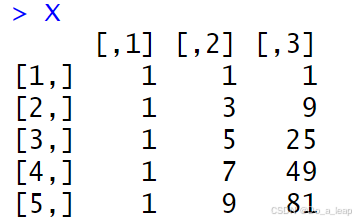





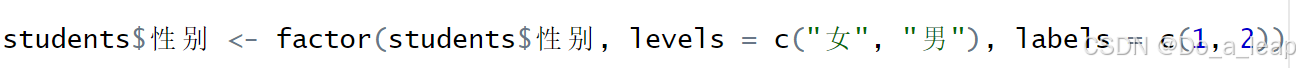






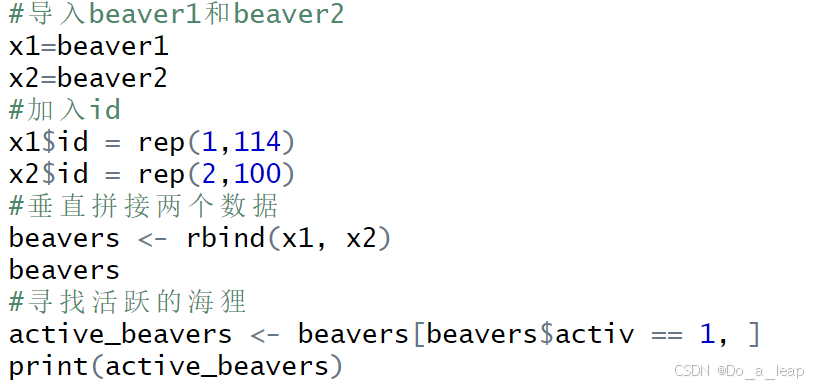






















评论

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言
查看更多评论
添加红包








