







Doc2X:智能公式编辑与解析
支持从 PDF 中提取并编辑复杂公式,同时转化为 Word 或 Latex,精准高效,为科研工作提速。
Doc2X: Smart Formula Editing and Parsing
Extract and edit complex formulas from PDFs with conversion to Word or LaTeX. Accurate and efficient for research workflows.
👉 立即体验 Doc2X | Try Doc2X Now
原文链接: https://arxiv.org/pdf/2402.18933
Modality-Agnostic Structural Image Representation Learning for Deformable Multi-Modality Medical Image Registration
模态无关的结构图像表示学习用于可变形多模态医学图像配准
Tony C. W. Mok 1 , 2 ∗ {\operatorname{Mok}}^{1,2 * } Mok1,2∗ Zi L i 1 , 2 ∗ {\mathrm{ {Li}}}^{1,2 * } Li1,2∗ Yunhao B a i 1 {\mathrm{ {Bai}}}^{1}\; Bai1 Jianpeng Z h a n g 1 , 2 , 4 {\mathrm{ {Zhang}}}^{1,2,4}\; Zhang1,2,4 Wei L i u 1 , 2 {\mathrm{ {Liu}}}^{1,2} Liu1,2
Tony C. W. Mok 1 , 2 ∗ {\operatorname{Mok}}^{1,2 * } Mok1,2∗ Zi L i 1 , 2 ∗ {\mathrm{ {Li}}}^{1,2 * } Li1,2∗ Yunhao B a i 1 {\mathrm{ {Bai}}}^{1}\; Bai1 Jianpeng Z h a n g 1 , 2 , 4 {\mathrm{ {Zhang}}}^{1,2,4}\; Zhang1,2,4 Wei L i u 1 , 2 {\mathrm{ {Liu}}}^{1,2} Liu1,2
Yan-Jie Zhou 1 , 2 , 4 {}^{1,2,4}\; 1,2,4 Ke Yan 1 , 2 {}^{1,2} 1,2
Yan-Jie Zhou 1 , 2 , 4 {}^{1,2,4}\; 1,2,4 Ke Yan 1 , 2 {}^{1,2} 1,2
1 DAMO Academy, Alibaba Group
1 达摩学院,阿里巴巴集团
2 Hupan Lab, 310023, Hangzhou, China
2 湖畔实验室,310023,杭州,中国
3 {}^{3} 3 Shengjing Hospital of China Medical University,China
3 {}^{3} 3 中国医科大学盛京医院,中国
4 {}^{4} 4 College of Computer Science and Technology,Zhejiang University,China
4 {}^{4} 4 浙江大学计算机科学与技术学院,中国
cwmokab@connect.ust.hk
Abstract
摘要
Establishing dense anatomical correspondence across distinct imaging modalities is a foundational yet challenging procedure for numerous medical image analysis studies and image-guided radiotherapy. Existing multi-modality image registration algorithms rely on statistical-based similarity measures or local structural image representations. However, the former is sensitive to locally varying noise, while the latter is not discriminative enough to cope with complex anatomical structures in multimodal scans, causing ambiguity in determining the anatomical correspondence across scans with different modalities. In this paper, we propose a modality-agnostic structural representation learning method, which leverages Deep Neighbourhood Self-similarity (DNS) and anatomy-aware contrastive learning to learn discriminative and contrast-invariance deep structural image representations (DSIR) without the need for anatomical delineations or pre-aligned training images. We evaluate our method on multiphase CT, abdomen MR-CT, and brain MR T1w-T2w registration. Comprehensive results demonstrate that our method is superior to the conventional local structural representation and statistical-based similarity measures in terms of discriminability and accuracy.
在不同成像模态之间建立密集的解剖对应关系是众多医学图像分析研究和图像引导放疗的基础性但具有挑战性的过程。现有的多模态图像配准算法依赖于基于统计的相似性度量或局部结构图像表示。然而,前者对局部变化的噪声敏感,而后者在应对多模态扫描中的复杂解剖结构时不够具有区分性,导致在不同模态的扫描之间确定解剖对应关系时产生歧义。本文提出了一种模态无关的结构表示学习方法,该方法利用深度邻域自相似性(DNS)和解剖感知对比学习来学习具有区分性和对比不变性的深度结构图像表示(DSIR),无需解剖划分或预对齐的训练图像。我们在多相CT、腹部MR-CT和脑部MR T1w-T2w配准上评估了我们的方法。全面的结果表明,我们的方法在区分性和准确性方面优于传统的局部结构表示和基于统计的相似性度量。
1. Introduction
1. 引言
Determining anatomical correspondence between multimodal data is crucial for medical image analysis and clinical applications, including diagnostic settings [33], surgical planning [ 1 , 57 ] \left\lbrack {1,{57}}\right\rbrack [1,57] and post-operative evaluation [39]. As a vital component for modern medical image analysis studies and image-guided interventions, deformable multimodal registration aims to establish the dense anatomical correspondence between multimodal scans and fuse information from multimodal scans, e.g., propagating anatomical or tumour delineation for image-guided radiotherapy [30]. Since different imaging modalities provide valuable complementary visual cues and diagnosis information of the patient, precise anatomical alignment between multimodal scans benefits the radiological observation and the
确定多模态数据之间的解剖对应关系对于医学图像分析和临床应用至关重要,包括诊断设置 [33]、手术规划 [ 1 , 57 ] \left\lbrack {1,{57}}\right\rbrack [1,57] 和术后评估 [39]。作为现代医学图像分析研究和图像引导干预的重要组成部分,变形多模态配准旨在建立多模态扫描之间的密集解剖对应关系,并融合来自多模态扫描的信息,例如,为图像引导放疗传播解剖或肿瘤轮廓 [30]。由于不同的成像模态提供了有价值的互补视觉线索和患者的诊断信息,因此多模态扫描之间的精确解剖对齐有利于放射学观察和后续的计算机化分析。
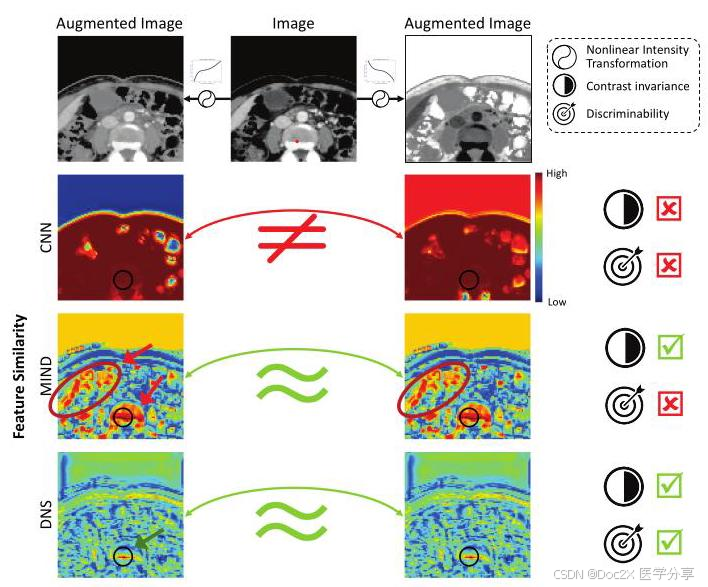
Figure 1. Visualization of feature similarity between the marked feature vector (red dot) of the image and all feature vectors of augmented images using the convolutional neural network without pertaining (CNN), Modality Independent Neighbourhood Descriptor (MIND), and our proposed Deep Neighbourhood Self-similarity (DNS). Our method captures the contrast invariant and high discriminability structural representation of the image, reducing the ambiguity in matching the anatomical correspondence between multimodal images.
图1. 使用卷积神经网络(CNN)、模态独立邻域描述符(MIND)和我们提出的深度邻域自相似性(DNS)可视化图像的标记特征向量(红点)与所有增强图像的特征向量之间的特征相似性。我们的方法捕捉了图像的对比不变性和高可区分性的结构表示,减少了在多模态图像之间匹配解剖对应关系时的模糊性。
*Contributed equally.
*贡献相同。
subsequent downstream computerized analyses. However, finding anatomical correspondences between homologous points in multimodal images is notoriously challenging due to the complex appearance changes across modalities. For instance, in multiphase abdomen computed tomography (CT) scans, the soft tissues can be deformed due to gravity, body motion, and other muscle contractions, resulting in an unavoidable large non-linear misalignment between subsequent imaging scans. Moreover, anatomical structures and tumours in multiphase CT scans show heterogeneous intensity distribution across different multiphase contrast-enhanced CT scans due to the intravenously injected contrast agent during the multiphase CT imaging.
然而,由于模态之间复杂的外观变化,在多模态图像中找到同源点之间的解剖对应关系是非常具有挑战性的。例如,在多相腹部计算机断层扫描(CT)中,软组织可能由于重力、身体运动和其他肌肉收缩而变形,导致后续成像扫描之间不可避免地出现大规模非线性错位。此外,由于在多相CT成像过程中静脉注射的对比剂,多相CT扫描中的解剖结构和肿瘤在不同的多相增强CT扫描中显示出异质的强度分布。
Despite there being vast research studies [ 7 , 11 , 23 , 28 \lbrack 7,{11},{23},{28} [7,11,23,28 , 29 , 35 , 39 , 50 ] {29},{35},{39},{50}\rbrack 29,35,39,50] on deformable image registration,most of these are focused on the mono-modal registration settings and rely on intensity-based similarity metrics, i.e., normalized cross-correlation (NCC) and mean squared error (MSE), which are not applicable to the multimodal registration. Recently, several methods have proposed to learn an inter-domain similarity metric using supervised learning with pre-aligned training images [14, 25, 44]. However, the perfectly aligned images and the ideal ground truth deformations are often absent in multimodal medical images, which limits the applicability of these methods.
尽管在可变形图像配准方面有大量研究 [ 7 , 11 , 23 , 28 \lbrack 7,{11},{23},{28} [7,11,23,28 , 29 , 35 , 39 , 50 ] {29},{35},{39},{50}\rbrack 29,35,39,50] ,但大多数研究集中在单模态配准设置上,并依赖于基于强度的相似性度量,即归一化互相关 (NCC) 和均方误差 (MSE),这些方法不适用于多模态配准。最近,一些方法提出使用监督学习与预对齐的训练图像来学习跨域相似性度量 [14, 25, 44]。然而,在多模态医学图像中,完美对齐的图像和理想的真实变形往往缺失,这限制了这些方法的适用性。
Historically, a pioneering work of Maes et al. [32] uses mutual information (MI) [55] to perform rigid multimodal registration. Nevertheless, for deformable multimodal registration, many disadvantages have been identified when using the MI-based similarity measures [45]. Specifically, MI-based similarity measures are sensitive to locally varying noise distribution but not sensitive to the subtle anatomical and vascular structures due to the statistical nature of MI.
历史上,Maes 等人 [32] 的开创性工作使用互信息 (MI) [55] 来执行刚性多模态配准。然而,在可变形多模态配准中,使用基于 MI 的相似性度量时发现了许多缺点 [45]。具体而言,基于 MI 的相似性度量对局部变化的噪声分布敏感,但对微妙的解剖和血管结构不敏感,这是由于 MI 的统计性质。
As an alternative to directly assessing similarity or MI on the original images, structural image representation approaches have gained great interest for deformable multimodal registration. By computing the intermediate structural image representation independent of the underlying image acquisition, well-established monomodal optimization techniques can be employed to address the multimodal registration problem. A prominent example is the Modality-Independent Neighbourhood Descriptor [17], which is motivated by image self-similarity [48] and able to capture the internal geometric layouts of local self-similarities within images. Yet, such local feature descriptors are not expressive and discriminative enough to cope with complex anatomical structures in abdomen CT, exhibiting many local optima, as shown in Fig. 13. Therefore, it is often jointly used with a dedicated optimization strategy or requires robustness initialization.
作为直接评估原始图像上的相似性或 MI 的替代方法,结构图像表示方法在可变形多模态配准中引起了极大关注。通过计算与基础图像采集无关的中间结构图像表示,可以采用成熟的单模态优化技术来解决多模态配准问题。一个显著的例子是模态独立邻域描述符 [17],它受到图像自相似性 [48] 的启发,能
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









