






第二版主要讲的是关于百万级大数据的一些注意事项方面,若觉得作者写的不好或者不足的地方欢迎评论私信。注:”以下项目皆为过时的老项目,不存在泄密等乱七八槽的情况“
Mysql的分表操作:
1.为什么要分表?
当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,我想有可能会死在那儿了。分表的目的就在于此,减小数据库的负担,缩短查询时间。
根据个人经验,mysql执行一个sql的过程如下:
1,接收到sql;
2,把sql放到排队队列中 ;
3,执行sql;
4,返回执行结果。
在这个执行过程中最花时间在什么地方呢?第一,是排队等待的时间,第二,sql的执行时间。其实这二个是一回事,等待的同时,肯定有sql在执行。所以我们要缩短sql的执行时间。
mysql中有一种机制是表锁定和行锁定,为什么要出现这种机制,是为了保证数据的完整性,我举个例子来说吧,如果有二个sql都要修改同一张表的同一条数据,这个时候怎么办呢,是不是二个sql都可以同时修改这条数据呢?很显然mysql对这种情况的处理是,一种是表锁定(myisam存储引擎),一个是行锁定(innodb存储引擎)。
表锁定表示你们都不能对这张表进行操作,必须等我对表操作完才行。行锁定也一样,别的sql必须等我对这条数据操作完了,才能对这条数据进行操作。如果数据太多,一次执行的时间太长,等待的时间就越长,这也是我们为什么要分表的原因
2.解决方案:
一.主从复制架构
单库单表下越来越不满足需求,此时我们先考虑进行读写分离。我们将数据库的写操作和读操作进行分离, 使用多个从库副本(Slaver)负责读,使用主库(Master)负责写, 从库从主库同步更新数据,保持数据一致。
这在一定程度上可以解决问题,但是用户超级多的时候,比如几个亿用户,此时写操作会越来越多,一个主库(Master)不能满足要求了,那就把主库拆分,这时候为了保证数据的一致性就要开始进行同步,此时会带来一系列问题:
(1)写操作拓展起来比较困难,因为要保证多个主库的数据一致性。
(2)复制延时:意思是同步带来的时间消耗。
(3)锁表率上升:读写分离,命中率少,锁表的概率提升。
(4)表变大,缓存率下降:此时缓存率一旦下降,带来的就是时间上的消耗。
注意,此时主从复制还是单库单表,只不过复制了很多份并进行同步。
主从复制架构随着用户量的增加、访问量的增加、数据量的增加依然会带来大量的问题,那就要考虑换一种解决思路。比如,分库分表。
二.分库分表
不管是分库还是分表,都有两种切分方式:水平切分和垂直切分。下面我们分别看看如何切分。
1、分表
(1)垂直分表
表中的字段较多,一般将不常用的、 数据较大、长度较长的拆分到“扩展表“。一般情况加表的字段可能有几百列,此时是按照字段进行数竖直切。注意垂直分是列多的情况。
例如:
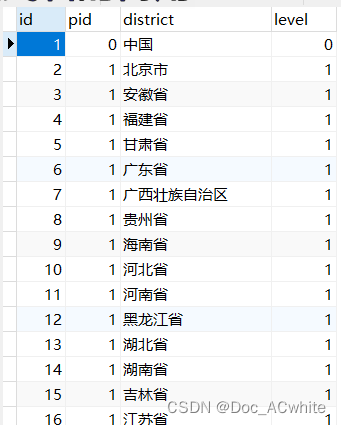
下图就是作者从以前停用的项目下扒下来的一张省市区表
一般来说来说省市区的三级分类属于不常用,而且数据量还较为大的,因此我们通常使用垂直分表给他取出来,另建其为扩展表
(2)水平分表
单表的数据量太大。按照某种规则(RANGE,HASH取模等),切分到多张表里面去。 但是这些表还是在同一个库中,所以库级别的数据库操作还是有IO瓶颈。这种情况是不建议使用的,因为数据量是逐渐增加的,当数据量增加到一定的程度还需要再进行切分。比较麻烦。
例如:
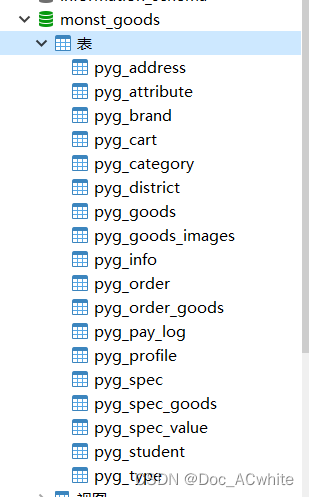
下图就是作者从以前停用的项目下扒下来的一张关联表
这里是一张购物车表:如果所有用户的购物车数据挤在一张表中,很容易导致表的崩溃以及数据的流失

2、分库
(1)垂直分库
一个数据库的表太多。此时就会按照一定业务逻辑进行垂直切,比如用户相关的表放在一个数据库里,订单相关的表放在一个数据库里。注意此时不同的数据库应该存放在不同的服务器上,此时磁盘空间、内存、TPS等等都会得到解决。
例如:
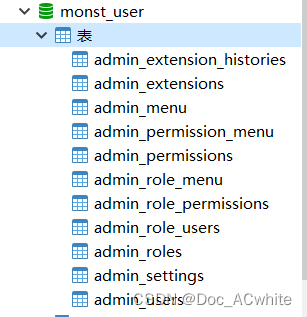
下图
可以清晰的看到登录及权限操作和主项目操作都是分隔开来的
(2)水平分库
水平分库理论上切分起来是比较麻烦的,它是指将单张表的数据切分到多个服务器上去,每个服务器具有相应的库与表,只是表中数据集合不同。 水平分库分表能够有效的缓解单机和单库的性能瓶颈和压力,突破IO、连接数、硬件资源等的瓶颈。
例如:
下图boss服务器负责处理的是医疗项目中套餐模块
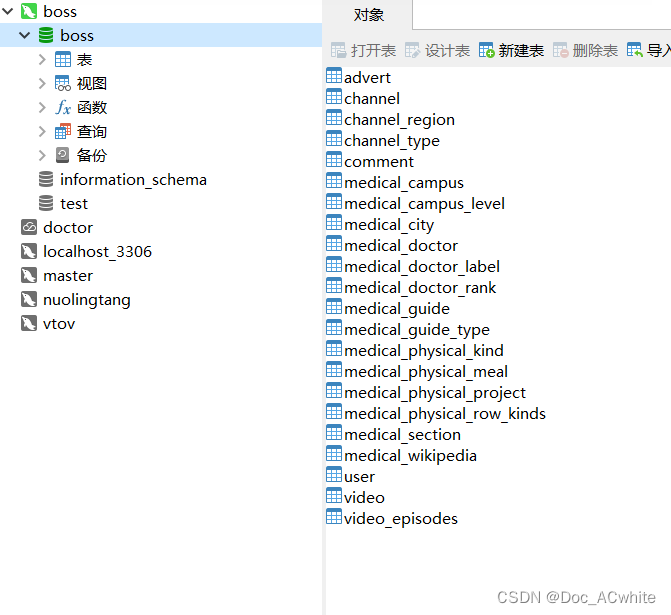
doctor服务器负责处理的是医疗项目中的登录 模块
3.做mysql集群,例如:利用mysql cluster ,mysql proxy,mysql replication,drdb等等
集群也可以起到分表的作用,同样可以为一个数据库减轻负担,说白了就是减少sql排队队列中的sql的数量,举个例子:有10个sql请求,如果放在一个数据库服务器的排队队列中,他要等很长时间,如果把这10个sql请求,分配到5个数据库服务器的排队队列中,一个数据库服务器的队列中只有2个,这样等待时间是不是大大的缩短了呢?这已经很明显了。所以我把它列到了分表的范围以内
2.分表查询
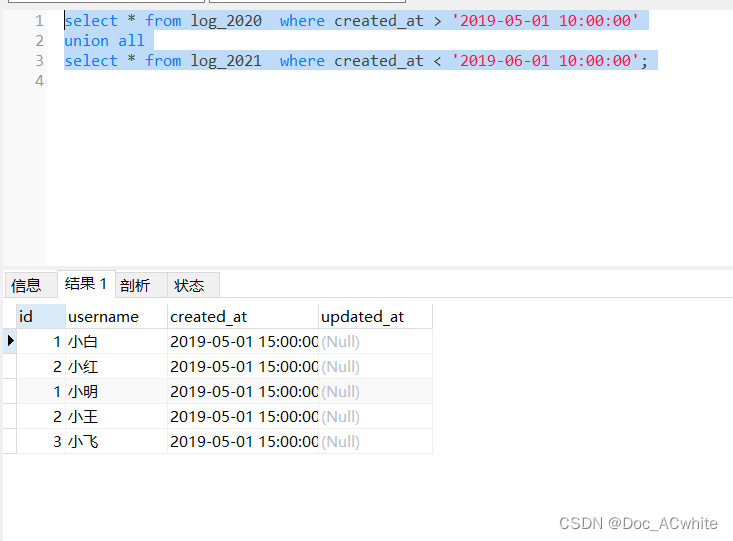
分表查询可以用union或者union all进行查询
union和union all都是将两个结果集合 合并在一起
select * from log_2020 where created_at > '2019-05-01 10:00:00'
union all
select * from log_2021 where created_at < '2019-06-01 10:00:00';
3.跨库查询
相同服务器进行跨库查询
select (...) from [dbname].[table_name];
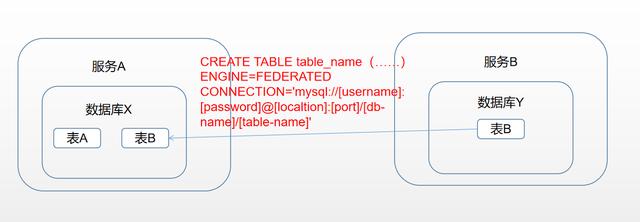
不同服务的跨库查询,直接通过数据名加表明是无法进行关联的,这里需要用到MySQL数据库中的federated引擎。具体过程如下:
需求:服务A上的数据库X的表A需要关联服务B上的数据库Y中的表B,查询需要的数据;
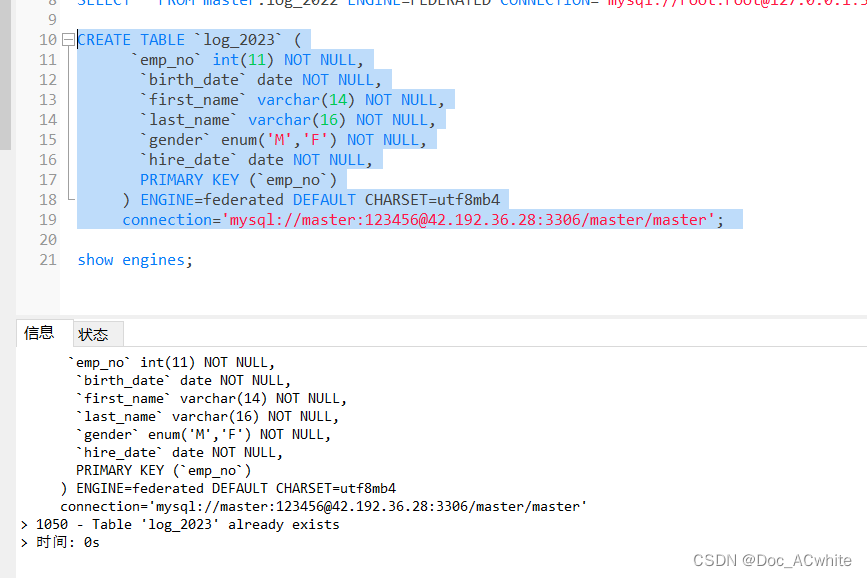
1、先查看MySQL数据库是否安装了FEDERATED引擎,通过命令show engines;如下图:
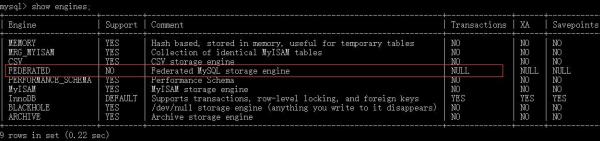
服务器Linux开启federated引擎:如上图所示,MySQL安装了FEDERATED引擎,但Support是No,表示没有启用,去my.cnf文件末加上1行FEDERATED,重启MySQL即可。若没有找到FEDERATED引擎,则需要去安装了。
windows开启federated引擎详情:MySQL开启federated引擎实现数据库表映射 - 水狼一族 - 博客园 (cnblogs.com)
2、在服务A上的数据库X中创建一个表B,语句如下:
CREATE TABLE table_name(……)ENGINE=FEDERATED CONNECTION='mysql://[username]:[password]@[localtion]:[port]/[db-name]/[table-name]'说明:通过FEDERATED引擎创建的表只是在本地有表定义文件,数据文件则存在于远程数据库中,通过这个引擎可以实现远程数据访问功能。换句话说,这种建表方式会在服务A上的数据库X中创建了一个表结构文件(即服务B上的数据库Y的B表的表结构文件),表的索引、数据等文件还在服务B上的数据库Y中,相当于一种快捷方式,方便关联。
3、在服务A上的数据库X中直接进行A表与B表关联,就可以查询出需要的数据了。
这种方式有以下几点是需要注意的:1)、该跨库查询方式不支持事务,最好别使用事务。2)、不能修改表结构。3)、MySQL使用这种跨库查询方式,远程数据库目前仅支持MySQL,其他数据库不支持。4)、表结构必须和目标数据库表完全一致。
Mysql高可用解决方案
方案一:共享存储
一般共享存储采用比较多的是 SAN/NAS 方案。
方案二:操作系统实时数据块复制
这个方案的典型场景是 DRBD,DRBD架构(MySQL+DRBD+Heartbeat)
方案三:主从复制架构
主从复制(一主多从)
MMM架构(双主多从)
MHA架构(多主多从)
方案四:数据库高可用架构
这种方式比较经典的案例包括 MGR(MySQL Group Replication)和 Galera 等,最近业内也有一些类似的尝试,如使用一致性协议算法,自研高可用数据库的架构等。
1.MGR(MySQL Group Replication,MySQL官方开发的一个实现MySQL高可用集群的一个工具。第一个GA版本正式发布于MySQL5.7.17中)
2.Galera
其它方案:MySQL Cluster和PXC
MySQL Cluster(ndb存储引擎,比较复杂,业界并没有大规模使用)
PXC(Percona XtraDB Cluster)
如何选择合适的Mysql集群架构?
MHA看业务规模和需求选择
mysql官方的Mysql Cluster。比较复杂,团队有人、资源充足,可以考虑尝试,貌似用的人不多。
小团队或资源不足或小项目直接建议阿里云、腾讯云
二、部分常见方案的简介
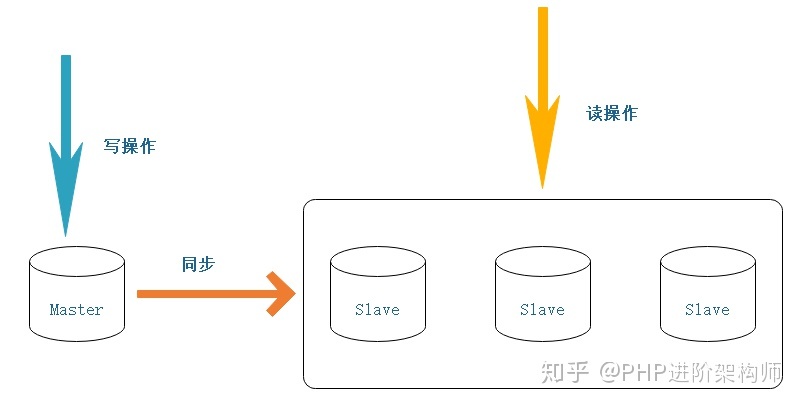
1.Mysql主从架构
2.MHA 架构(Master High Availability Manager and Toolsfor MySQL)
MHA(Master High Availability Manager and Toolsfor MySQL)目前在Mysql高可用方面是一个相对成熟的解决方案。它是日本的一位MySQL专家采用Perl语言编写的一个脚本管理工具,该工具仅适用于MySQLReplication 环境,目的在于维持Master主库的高可用性。
MHA是基于标准的MySQL复制(异步/半同步)。
MHA是由管理节点(MHA Manager)和数据节点(MHA Node)两部分组成。
MHA Manager可以单独部署在一台独立机器,也可以部署在一台slave上。

3.MMM 架构(Master-Master replication manager for Mysql)
MMM,全称为Master-Master replication manager for Mysql,是一套支持双主故障切换和双主日常管理的脚本程序,MMM使用Perl语言开发。主要用来监控和管理MySQL Master-Master(双)复制。特别适合DBA做维护等需要主从复制的场景,通过双主架构避免了重复搭建从库的麻烦。虽然叫做双主复制,但是业务上同一时刻只允许对一个主进行写入,另一台备选主上提供部分读服务,以加速在主主切换时备选主的预热。
(MMM好像不靠谱,据说不稳定,但还是有人在用)
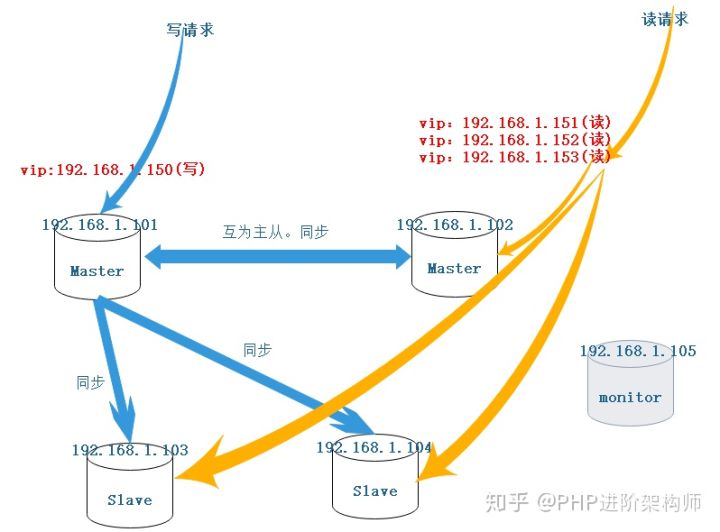
MMM优缺点
优点:高可用性,扩展性好,出现故障自动切换,对于主主同步,在同一时间只提供一台数据库写操作,保证的数据的一致性。
缺点:Monitor节点是单点,可以结合Keepalived实现高可用。
4.DRBD 架构(MySQL+DRBD+Heartbeat)
官网:https://www.linbit.com/en/drbd-community/drbd-download/
三、读写分离解决方案
- 客户端解决方案(应用层):TDDL、 Sharding-Jdbc (常用shardding-jdbc)
- 中间件解决方案(代理层):mysql proxy、mycat、altas (常用mycat)
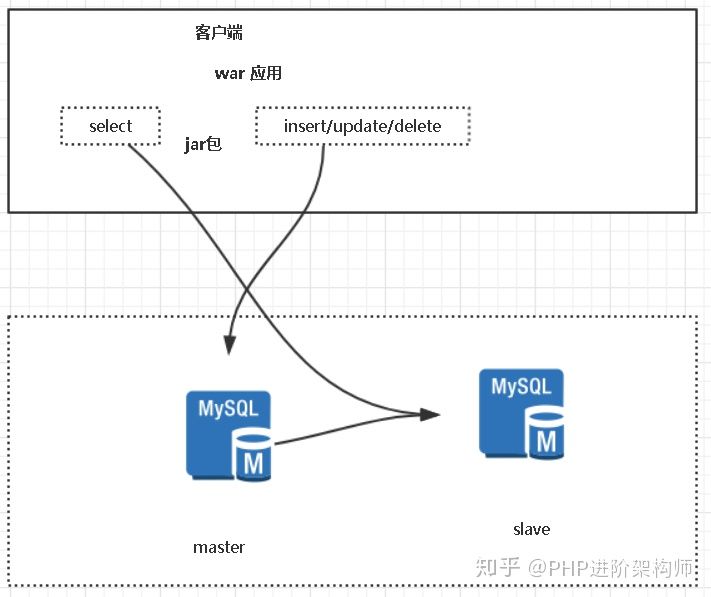
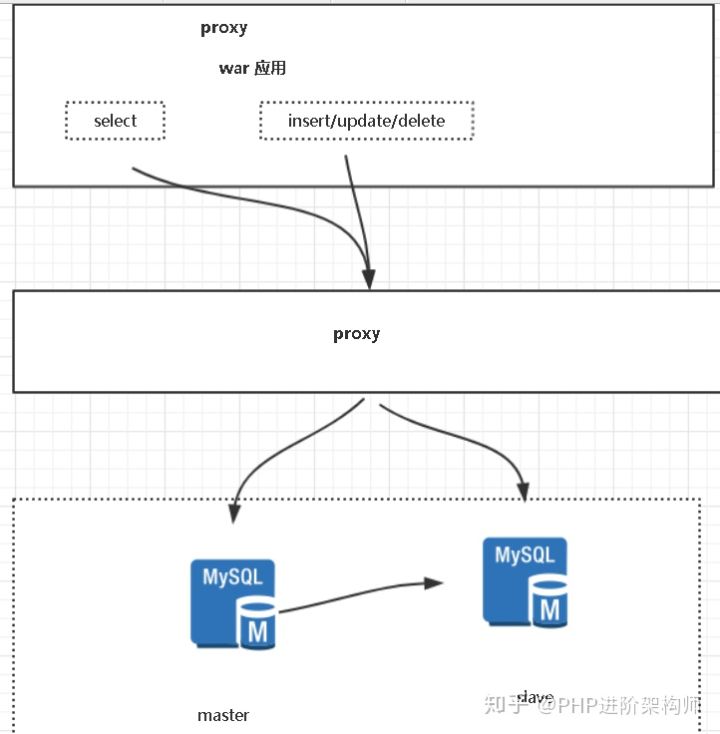
客户端解决方案的特点:
优点:
1、程序自动完成,数据源方便管理
2、不需要维护,因为没用中间件
3、理论支持任何数据库 (sql标准)
缺点:
1、增加了开发成本、代码有入侵
2、不能做到动态增加数据源
3、程序员开发完成,运维参与不了。
中间件解决方案的特点:
优点:
1、数据增加了都程序没用任何影响
2、应用层(程序)不需要管数据库方面的事情
3、增加数据源不需要重启程序
缺点:
1、程序依赖中间件,导致切换数据库变的困难
2、增加了proxy 性能下降
3、增加了维护工作、高可用问题。
MYSQL笛卡尔积
1、什么是迪卡尔积?
笛卡尔积是迪卡尔这个人发现了,所以取名叫迪卡尔积,这个现象就是多个表进行关联查询的就会产生迪卡尔积
2、笛卡尔积使用场景
如果需要操作两表或者两个以上的表关联查询的时候,就需要使用笛卡尔积
例如,A={a,b}, B={0,1,2},则
A×B={(a, 0), (a, 1), (a, 2), (b, 0), (b, 1), (b, 2)}
B×A={(0, a), (0, b), (1, a), (1, b), (2, a), (2, b)}
以上A×B和B×A的结果就可以叫做两个集合相乘的‘笛卡尔积’。
从以上的数据分析我们可以得出以下两点结论:
两个集合相乘,不满足交换率,既 A×B ≠ B×A。
A集合和B集合相乘,包含了集合A中元素和集合B中元素相结合的所有的可能性。既两个集合相乘得到的新集合的元素个数是 A集合的元素个数 × B集合的元素个数。
数据库表连接数据行匹配时所遵循的算法就是以上提到的笛卡尔积,表与表之间的连接可以看成是在做乘法运算。
比如现在数据库中有两张表,student表和 student_subject表,如下所示:
我们执行以下的sql语句,只是纯粹的进行表连接。
SELECT * from student JOIN student_subject;
SELECT * from student_subject JOIN student;
执行结果:
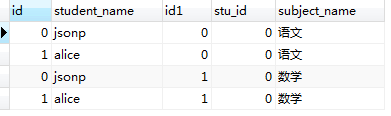
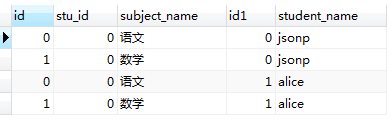
因此,有一个显而易见的SQL优化的方案是,当两张表的数据量比较大,又需要连接查询时,应该使用 FROM table1 JOIN table2 ON xxx的语法,避免使用FROM table1,table2 WHERE xxx的语法,因为后者会在内存中先生成一张数据量比较大的笛卡尔积表,增加了内存的开销。















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









