






 点亮 ⭐️ Star · 照亮开源之路
点亮 ⭐️ Star · 照亮开源之路
GitHub:https://github.com/apache/dolphinscheduler

//
在 ApacheCon Asia 2022 上,思科网讯(Cisco Webex) 技术经理 刘丁政 分享了关于 Apache DolphinScheduler 与 Kubernetes 结合进行大数据处理。让我们探索一下思科网讯在 Apache DolphinScheduler 上构建各种功能背后的故事,以及他们是如何使用 Apache DolphinScheduler 上部署Kubernetes 处理公司大数据业务的。
本主题讨论了三个主题:
商业背景
基于 DolphinScheduler 构建的功能的架构和实现
社区贡献
1
业务背景
为什么要在 DolphinScheduler 上构建功能?
首先,我简单介绍一下思科网讯的产品组合。

旧金山思科网讯是一家开发和销售在线会议、视频会议、云呼叫服务和联络中心作为服务应用程序的软件公司。
我的团队设计并搭建了大数据平台,服务于上述组合产品的数据注入和工作负载的数据处理。我们以 Webex 会议产品为例,Webex 会议会生成各种指标,当召开会议时,客户端和服务器都会向我们的 Kafka 集群发送大量指标和日志。外部和内部客户都依赖这些指标来优化他们的会议体验或生成报告。
此外,我们可以提供一个问题诊断页面,这个页面依赖于 ETL 作业和数据处理作业的结果。在我们的生产环境中,每天都有大量的 Flink、Spark 和各种 ETL 作业在运行,包括批处理和实时任务。
01
思科网讯数据岛—改造前
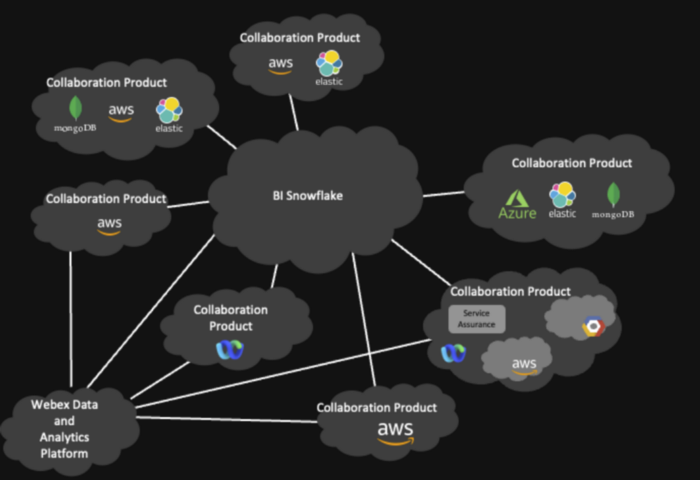
由于思科网讯是一家全球协作服务提供商,我们的客户跨越多个时区和大洲,因此我们在全球拥有许多数据中心。这些数据中心包括本地自我管理的数据中心和由亚马逊和谷歌等云提供商管理的集群。过去,我们会使用镜像将所有全球数据中心数据集中到美国的一个集中式 Kafka 集群中,并从那里开始数据处理和数据整合。
近年来,我们在全球范围内建立了多个集群来进行数据本地化。数据模型从包含来自世界各地的所有数据的集中式集群,变成了包含本地生成数据的各个数据中心。
我们的下一代数据平台想解决的另一个问题是数据孤岛问题。思科网讯有许多不同类型的服务在很多不同的基础设施上运行,例如自维护数据中心、AWS 和 GCP。基本上,每个产品都有自己的数据注入和数据平台实现。
此外,我们的数据存储格式很多样,例如 HDFS 集群、私有 Snowflake、Google 云存储、Azure Blob 存储等。
在基础设施方面,我们有亚马逊网络服务、Azure、谷歌云,还有一个自维护的网络持续中心,同样的业务也有自己的数据中心。事实上,我们没有单一的数据来源。所以当客户要求提供数据时,我们很难保证不同系统之间的一致性。
02
思科网讯数据岛—改造后
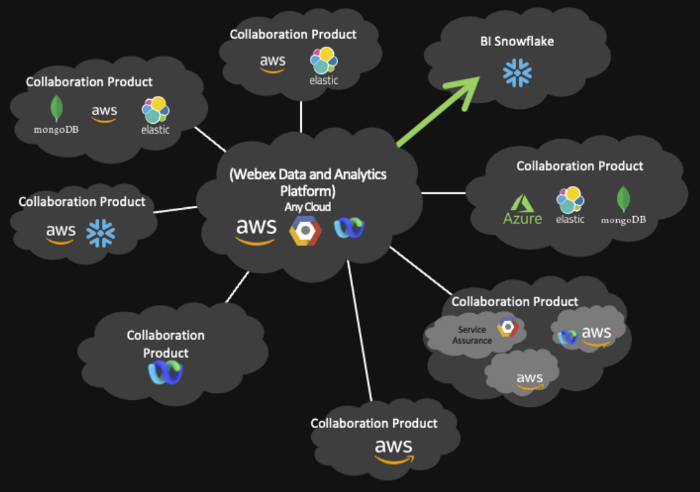
我们的愿景是打造一个数据平台,它能够服务每一个内部和外部客户,让我们可以从统一架构、数据存储和数据注入技术中消除数据孤岛,所有基础设施都整合在我们下一步的边界内。这个数据平台还得能够适配架构中的任何公共云和现有的私有数据中心。
2
基于DolphinScheduler构建
功能的架构和实现
我们想要将 DolphinScheduler 打造成为所有思科网讯产品的下一代数据平台,但当时 DolphinScheduler 开源版本中缺少了某些功能。所以我们决定自己实现这些缺失的功能。
对于 Kubernetes 服务,我们构建了一个 Rancher(大牧场),并在私有数据中心内维护 Kubernetes 集群。对于公有云,我们使用 Amazon Elastic Kubernetes 服务和 Google Kubernetes Engine 来管理容器服务,以便在 AWS 和 GCP 中运行和扩展 Kubernetes 应用程序。
数据存储解决方案也将被统一。目前,我们使用 Apache Pinot 进行 OLAP,使用 Apache Iceberg 进行数据存储。
把 Kubernetes 作为计算集群,我们可以将计算集群和存储集群分开。
对于私有数据中心,我们在 HDFS 之上使用 Iceberg,并从 CDH Hadoop 过渡到一个开源的 Hadoop 集群。
对于公有云,由于 Iceberg 是一种灵活的表格格式,所以我们可以将其用作对象存储。
但说起来容易做起来难。你可能会问,DolphinScheduler 只是一个分布式调度框架,你怎么能解决所有这些问题呢?
我们的下一代的平台覆盖范围更广,不仅包括作业调度这个我今天要谈的主要话题,它还包括数据血缘和元数据管理、数据治理和数据日常集成。但这些我们今天暂且不论。
因此,当我们今年早些时候开始构建这个下一代大数据平台时,我们调研了各种不同的工作流数据处理引擎,包括 Airflow、Argo 等,但我们最终选择了 DolphinScheduler,因为它优雅且易于扩展。
01
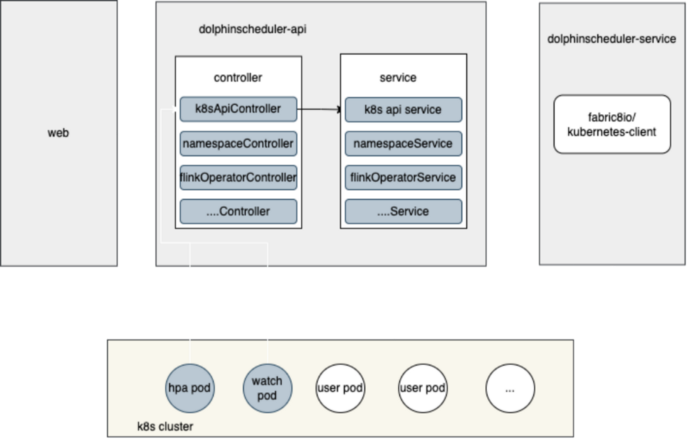
DolphinScheduler与k8S集成
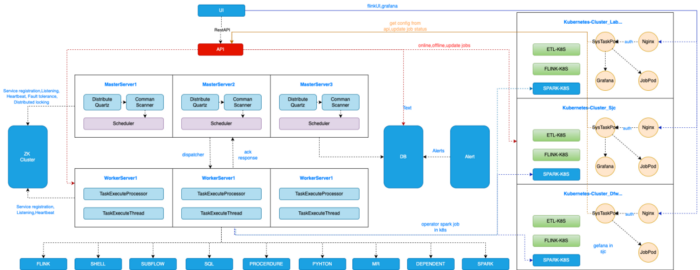
如架构图所示,左边部分是 DolphinScheduler 的特性。DolphinScheduler 使用 Zookeeper 的多个 master 和 worker 来保证高可用性。不同的任务类型在这些 worker 上运行。我们所有的数据处理作业,例如 Flink 和 Sparks 过去运行在多个不同的 Yarn 集群上。我们有一个用于批量 Spark 作业和 Flink 作业的 CDH 集群,多个 Flink 作业运行在不同的 Flink 集群上。在 2021 年,我们决定构建一个 Kubernetes 集群来替代 Yarn 集群,原因如下。
使用 Kubernetes 让我们的日常操作更加顺畅和轻松。在 DevOps 原则中,我们既是应用程序开发人员,也是我们开发的所有应用程序和数据处理作业的运营者。在构建数据管道和数据平台功能之后,我的团队还完成了用于部署这些应用程序和管道的 CI/CD 管道,并构建了一个基于指标和分析的监控平台。如果我们想创建指标条件,即使使用自动化脚本,通常也需要 1 到 2 天的时间来进行基础设施配置和服务构建。但如果我们使用 Kubernetes 的 Prometheus Operator,2 分钟就能搞定。
加入 Kubernetes 的第二个原因是它允许我们在其中部署各种容器化服务。Yarn 支持各种基于 JVM 的作业,例如 Flink、Spark 作业和批处理作业,以及实时作业。只要在容器中,Kubernetes 支持的作业类型会更多。Prometheus 和 Redis 也可以在同一个集群中运行。Kubernetes 的混合开发特性让我们省去了大量的运维工作。我们曾经将数据平台部署为专用的 VMS。现在,我们为所有数据处理作业安装了这个带有 Prometheus Operator 的独立监控集群。截至目前,作为监控组件的所有服务都被整合在一个 Kubernetes 集群中。此外,CI/CD 管道更加容易维护,因为一切都在 Kubernetes 中。
因为我们所有的数据处理作业都在 Kubernetes 集群上运行,所以我们扩展了 DolphinScheduler 的功能,并将大部分功能回馈给了社区。
例如,我们把 Flink、Spark 和 Kubernetes 功能与 DolphinScheduler 集成起来。
我们把数据处理工任务分为批处理和实时两类。
对于实时任务,我们得出了一个结论,80% 的实时作业就是某种简单的数据提取、转换和加载。但是其中有很多,例如把原始数据注入到数据仓库 ODS 层的情况就比较复杂了。原始数据注入管道占用了大量的资源。通常,这些管道的逻辑非常简单,典型的逻辑是从某个 Kafka 端口提取数据,根据字段值或正则表达式做一些过滤逻辑,然后提取所有需要的字段,并将数据下沉到数据湖中。
我们没有为这种简单的管道逐个编写 Flink 作业,而是开发了一个轻量级的数据处理引擎,可以使用 K8s HPA 指标自动扩展。创建这样的作业也很简单。当使用 DolphinScheduler 的前端和框架时,我们可以通过简单的拖放来生成数据处理管道。
02
多集群 ETL 作业管理

我们平台用户的一个典型用例是在多个集群上部署相同的作业,配置略有不同,表明不同的数据中心。每个作业中的数据处理逻辑都是相同的,唯一的区别是每个不同数据中心之间的源集群、主题名称和接收器连接。
为了最大限度地减少部署工作,我们通过概括通用处理逻辑并替换每个集群所需的配置,来一件开发多个集群功能。我们使用一个集中的 DolphinScheduler 来作为所有数据处理作业的作业调度平台,运行不同的数据中心。集中式的 DolphinScheduler 可靠性提高是通过其他数据中心的 DolphinScheduler 实例实现的。当用户向不同集群提交新作业时,DolphinScheduler 会根据用户选择将使用示例和文件分发到目标集群,然后运行作业。运行作业的资源在 DolphinScheduler 上进行管理,这意味着我们可以为不同 Kubernetes 集群上的每个 Namespace 设置 CPU 内存限制。
我们还将 Pagerduty 和 Webex teams 作为插件添加到 DolphinScheduler,因为这是两个我们在发生错误时跟踪实例的常用工具。
通常,用户希望触发 Pagerduty 实例并一起向 Webex teams发送消息,因此我们更改了很多规则,支持一次配置触发多个插件。Alert 模块中的这两个功能我们同样也贡献给了社区。
03
Kubernetes 多集群管理
让我们看一下多集群资源管理功能。
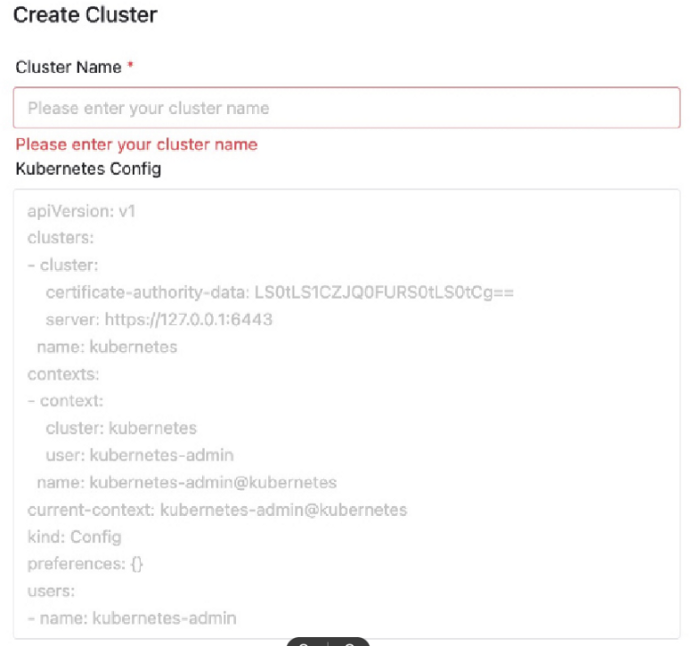
我们在世界各地的私有数据中心或 AWS 等公共云中构建了许多 Kubernetes 计算集群。为了使 DolphinScheduler 能够为所有这些数据中心提交和管理作业,我们首先在 DolphinScheduler 上实现了这个命名空间和集群管理功能。
使用 Terraform 或 Kubeadm 创建新集群时,用户将导出此集群所需的配置。例如,认证和集群名称。然后把它复制粘贴到 DolphinScheduler 的客户管理页面,就可以添加一个新集群。基本上,作业提交和管理是使用集成到 DolphinScheduler 中的 Kubernetes 客户端完成的。导入集群后,我们就可以为每个用户组创建 Namespace。
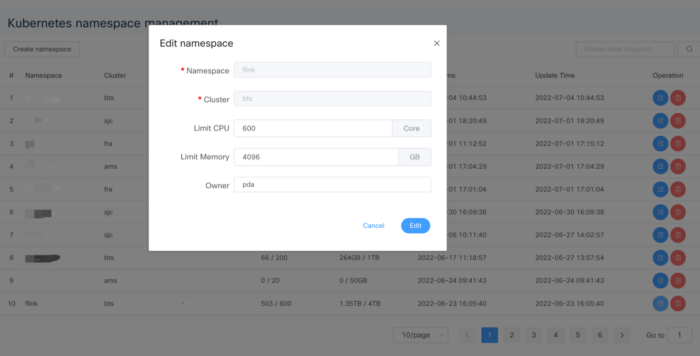
04
Kubernetes 多集群 Namespace 管理
Namespace 与 DolphinScheduler 项目相关联,这意味着该项目的资源限制与其 CPU 内存设置绑定。
05
思科网讯数据驻留
我们有这么多数据中心需要管理,更高的可靠性是客户的关键诉求之一。
对于私有中心,我们有一个备份 Kubernetes,用于生成高可靠性数据。如果 Kubernetes 集群由于某种原因出现故障,我们可以无缝切换到备份集群。我们的一些业务采用主动策略来保证所有的数据处理作业同时运行在主集群和备份集群上。主动策略对资源的消耗翻倍,且仅适用于延迟敏感和任务关键型的业务。我们的大多数业务在待机模式下处于非活跃状态,因此备份集群数据只会填充一次原始中心字段。这种方法还需要一定的恢复时间,来下沉两个主集群和备份集群之间的数据,但消耗的资源更少。
对于 AWS 托管的集群,AWS 在每个区域为 HA 提供三个可用区。这种方法与我们的私有数据中心方法或多或少相同,不同之处在于 AWS 提供了一个额外的 AZ 以获得更好的 HA。
06
简单的 ETL 管道
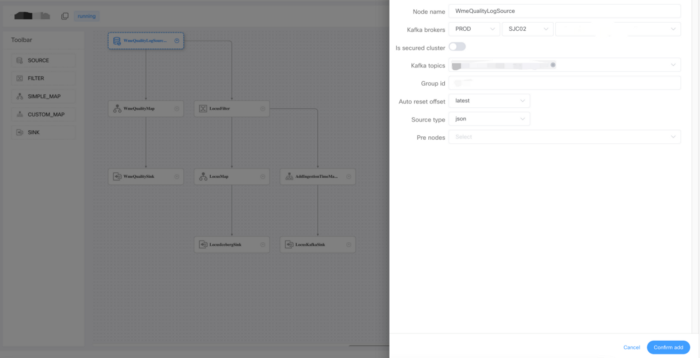
简单的 ETL 管道
对于没有复杂竞争逻辑的简单处理作业,我们在 DolphinScheduler 上开发了一个拖放式的管道生成框架。
用户可以通过在画布上拖放来生成复杂的实时数据处理管道。通过配置预定义的源过滤器映射和同步运算符,用户无需编写任何代码。值得注意的是,我们将元数据集成到数据中心以供源 和 map operators 使用。因此,当用户选择他们想要处理的主题时,看到的列表中的作业是来自数据中心中的 API 数据的。用户无需在接口上键入名称和 Kafka 集群配置字符串,而是从数据中心自动获取。在 map operators 中,用户可以为每个字段定义不同类型的函数。
字段列表也来自数据中心。假设一个主题的输入字段包含 1,000 个字段,就像传统的管道定义工具一样,通过简单的一键全选,就可以在我们的框架中完成这项工作。
07
UDF 管理
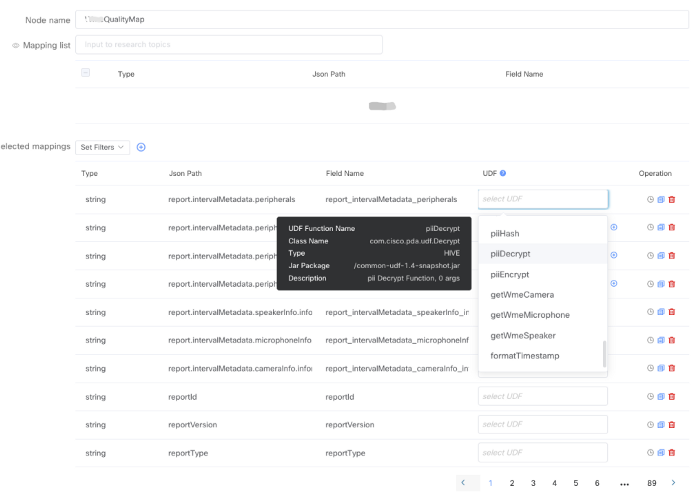
简单的 ETL 管道 - UDF 管理
UDF 的创建和管理是完全自动化的,用户只需要在 Java 或 Scala 片段中提供 UDF 逻辑。
然后我完成剩下的工作,包括 UDF 打包、维护以及注册到不同的 Kubernetes 引擎。该框架还提供了大量用于故障排除的指标。在这些指标中,我们定义了公式,以便通过 HPA 自动、熟练地进行数据处理。
08
自动缩放
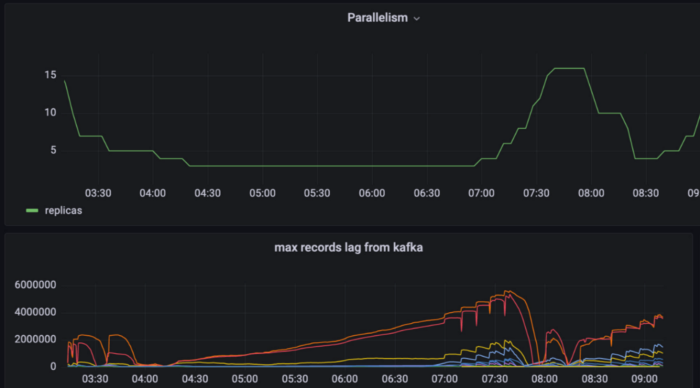
自动缩放
从指标中可以看出,我们数据处理端口的并行度将与上游 Kafka 的数据量相匹配。这种自动扩展的功能为我们节省了大量资源。
为了在接口上获得最准确和最新的作业和并行度状态,我们基于 Kubernetes API,以长期伺服型 Pod 的形式实现了这个监控功能。
假设,某个作业从两部分缩小到一部分时,监控部分将更新该作业的数据库表、并行度和字段。此外,当作业启动一个字段时,监控报告会捕捉这些变化,并更新数据库中的相应记录中。
09
Kubernetes 上的 Flink 作业
因此,我们还在 DolphinScheduler 中基于 Kubernetes 功能构建了 Flink 作业。有些人可能会感到困惑,因为 DolphinScheduler 在工作流中已经有 Flink 任务端口。这是因为 DolphinScheduler 中的 Flink 任务仅适用于 Yarn,但我们打算在 Kubernetes 集群上运行所有作业。我们通过在当前 DolphinScheduler 架构中添加与 Kubernetes 相关的 API 来实现 Flink 作业运行到 Kubernetes 上。
我们还比较了原生 Flink on Kubernetes 模式和 Kubernetes operator for Flink on Kubernetes 后端两种方式。Kubernetes operator 是最灵活的方式,我们不必为每个作业都创建镜像,也是许多作业在 Kubernetes 集群上运行的最具认知性的方式。
Kubernetes 上的 Flink 作业
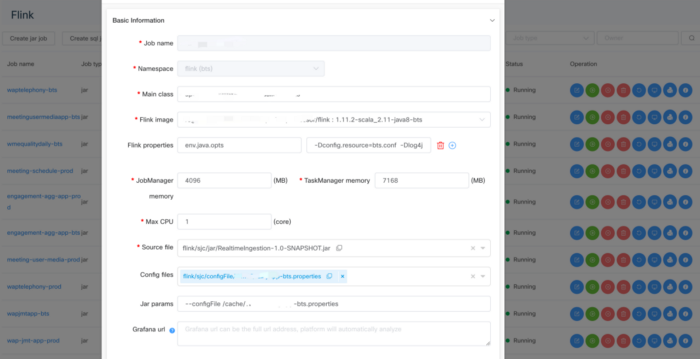
Flink Jar 作业支持
在作业接口上,用户可以提交 jar 格式或纯 SQL 格式的 Flink 作业。
Flink SQL 作业支持
对于 SQL 作业,我们将 SQL 脚本打包成 Jar 格式,然后遵循与 jar 格式文件相同的提交逻辑。我们还为这两种格式提供了大量预定义的指标。用户可以添加他们自定义的指标和语法,并创建他们自己的业务警报规则。
时间范围缩放
我们还支持所有 Flink 作业的时间缩放功能。用户可以为不同的时间段定义不同的并行度。对于我们的大多数产品来说,数据量流入的规律类似,数据搜索量在中国时间晚上 8:00 到早上 8 点最大,因为我们的大多数客户是欧洲和北美的企业用户。所以在这些高峰时段,用户可以为自己的作业设置比较高的并行度,这样就不会有背压,最新的日志也能及时处理。在非高峰时段,数据量通常是高峰时段的 1/3。
基本上,我们可以根据用户的配置缩小并行度。引入这种机制后,我们在非高峰时段节省了数千个 CPU 成本。通常,所有的批处理作业都在非高峰时段运行,使用的是从 Flink 作业时间范围缩放和 ETL 作业 HPA 中节省的资源。
节省这些资源还减少了我们在 Kubernetes 集群中添加的服务,与没有扩展的旧解决方案相比,总的运营成本也大幅降低。所有 Flink 作业的状态和并行度也由一个长时间运行的端口监控,同样遵循我之前提到的设计原则。
10
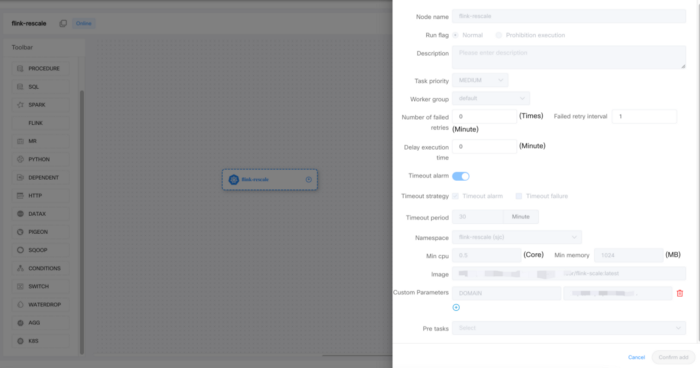
Kubernetes 批处理作业
Kubernetes 批处理作业
实时作业就数到这里。接下来看一下批处理作业。现在,Kubernetes 作业的用例是在 Kubernetes 集群上运行一次连续的镜像,或者在每天的预定时间运行一次。在这种情况下,DolphinScheduler worker 只是用来提交 Kubernetes 作业,并报告运行状态。容器中用户代码的额外执行在 Kubernetes 集群中进行。因此,计算密集型任务将占用大量 CPU 和内存资源。
DolphinScheduler 目前并不支持所有类型的任务。就像在 Kubernetes 上运行的任何其他任务或作业一样,我们也对 Kubernetes 批处理作业 Namespace 进行了集成。用户可以选择他们希望批处理作业写入日志的 Namespace。我们还实现了 Namespace 访问控制,用户只能查看分配给他们的 Namespace,因为每个 Namespace 都有 CPU 和内存使用的上限。批处理作业可以更好地实现资源管理和关联。
11
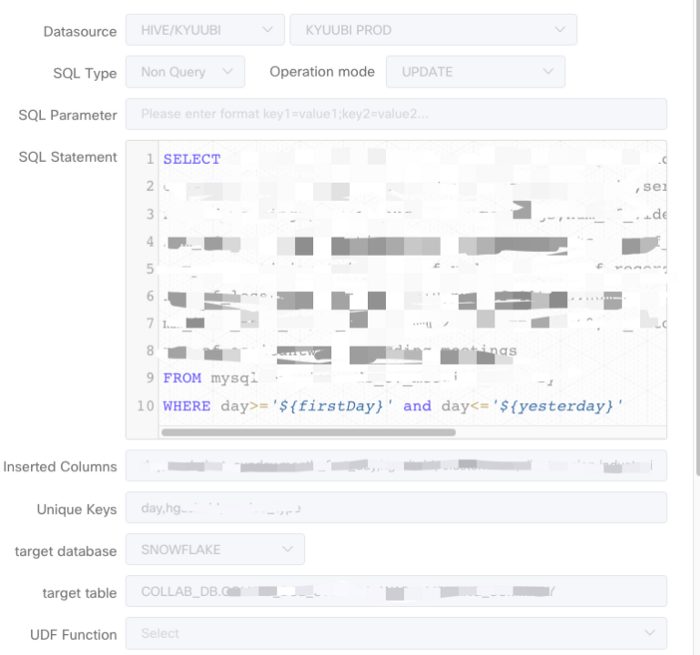
SQL 任务自定义
SQL 任务自定义
我们还在 SQL 任务定制方面做了一些工作。SQL 任务在 DolphinScheduler 中创建任务类型。这里的用例是使用 Apache Kube 以循环格式运行 ETL 作业。这些 ETL 作业通常以批处理方式出现。SQL 由其客户提供,而数据源通常是我们的数据湖。
关于资源数据的工作繁多,而将资源数据推送到 Snowflake 和 Iceberg 占了我们 90% 的使用用例。
SQL 任务支持 Snowflake
我们对 SQL 任务的第一个定制化改进是在任务 UI 上添加了 sink 选择。用户很容易 sink 到数据存储的 UI 位置。
Snowflake Spark connector 的 Upsert 功能
第二个定制化改进是关于 Spark center for Snowflake,因为我们要支持多个 Snowflake,所以我们在第二个版本中为数据源实现了这个 Spark Snowflake 目录。我们还在 Snowflake connector 中实现了 upsert 语法,支持更新用例。这两个功能,我们同样也贡献给了 Snowflake 和 Spark 社区。
3
社区贡献总结
总结一下我们为社区所做的贡献吧。我这次分享中所提到的所有功能现在都已经在我们的生产环境中运行了。其中大部分功能我们都贡献给了社区,希望可以度对其他用户有所帮助。
首先,我们向社区贡献了 Kubernetes Namespace 管理的前端 UI、后端服务以及多个 Kubernetes 集群管理功能。此功能是 Kubernetes 和 DolphinScheduler 集成其他工作的基石。
此外,我们还向社区贡献了 Kubernetes 批处理任务。现在用户可以据此创建一个包含 Kubernetes 批处理的工作流。
在报警插件方面,我们在警报模块中添加了 PagerDuty 和 Webex teams。此外,我们还修复了 DolphinScheduler 3 的 LDAP 登录功能。
这就是我今天分享的全部内容,希望你喜欢。

最后非常欢迎大家加入 DolphinScheduler 大家庭,融入开源世界!
我们鼓励任何形式的参与社区,最终成为 Committer 或 PPMC,如:
将遇到的问题通过 GitHub 上 issue 的形式反馈出来。
回答别人遇到的 issue 问题。
帮助完善文档。
帮助项目增加测试用例。
为代码添加注释。
提交修复 Bug 或者 Feature 的 PR。
发表应用案例实践、调度流程分析或者与调度相关的技术文章。
帮助推广 DolphinScheduler,参与技术大会或者 meetup 的分享等。
欢迎加入贡献的队伍,加入开源从提交第一个 PR 开始。
比如添加代码注释或找到带有 ”easy to fix” 标记或一些非常简单的 issue(拼写错误等) 等等,先通过第一个简单的 PR 熟悉提交流程。
注:贡献不仅仅限于 PR 哈,对促进项目发展的都是贡献。
相信参与 DolphinScheduler,一定会让您从开源中受益!
参与贡献
随着国内开源的迅猛崛起,Apache DolphinScheduler 社区迎来蓬勃发展,为了做更好用、易用的调度,真诚欢迎热爱开源的伙伴加入到开源社区中来,为中国开源崛起献上一份自己的力量,让本土开源走向全球。

参与 DolphinScheduler 社区有非常多的参与贡献的方式,包括:

贡献第一个PR(文档、代码) 我们也希望是简单的,第一个PR用于熟悉提交的流程和社区协作以及感受社区的友好度。
社区汇总了以下适合新手的问题列表:https://github.com/apache/dolphinscheduler/issues/5689
非新手问题列表:https://github.com/apache/dolphinscheduler/issues?q=is%3Aopen+is%3Aissue+label%3A%22volunteer+wanted%22
如何参与贡献链接:https://dolphinscheduler.apache.org/zh-cn/community/development/contribute.html
来吧,DolphinScheduler开源社区需要您的参与,为中国开源崛起添砖加瓦吧,哪怕只是小小的一块瓦,汇聚起来的力量也是巨大的。
参与开源可以近距离与各路高手切磋,迅速提升自己的技能,如果您想参与贡献,我们有个贡献者种子孵化群,可以添加社区小助手微信(Leonard-ds) ,手把手教会您( 贡献者不分水平高低,有问必答,关键是有一颗愿意贡献的心 )。
添加小助手微信时请说明想参与贡献。
来吧,开源社区非常期待您的参与。
< 🐬🐬 >
更多精彩推荐
☞Apache DolphinScheduler PMC:我在社区里如何玩转开源?
☞ApacheCon Asia 2022 精彩回顾 | DolphinScheduler 在联想作为统一调度中心的落地实践
☞国民乳业巨头伊利如何基于 DolphinScheduler 开辟企业数字化转型“蹊径”?
☞示例讲解 | Apache DolphinScheduler 简单任务定义及复杂的跨节点传参
☞2022 世界人工智能大会|小海豚将亮相人工智能与开源技术先锋论坛!
☞名额已排到10月 | Apache DolphinScheduler Meetup分享嘉宾继续火热招募中
我知道你在看哟!















 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











