






一、背景
大数据服务是数据平台建设的基座,随着B站业务的快速发展,其大数据的规模和复杂度也突飞猛进,技术的追求也同样不会有止境。
B站一站式大数据集群管理平台(BMR),在千呼万唤中孕育而生。本文简单介绍BMR的由来、面临的主要矛盾以及如何在变化中求得生存与发展。
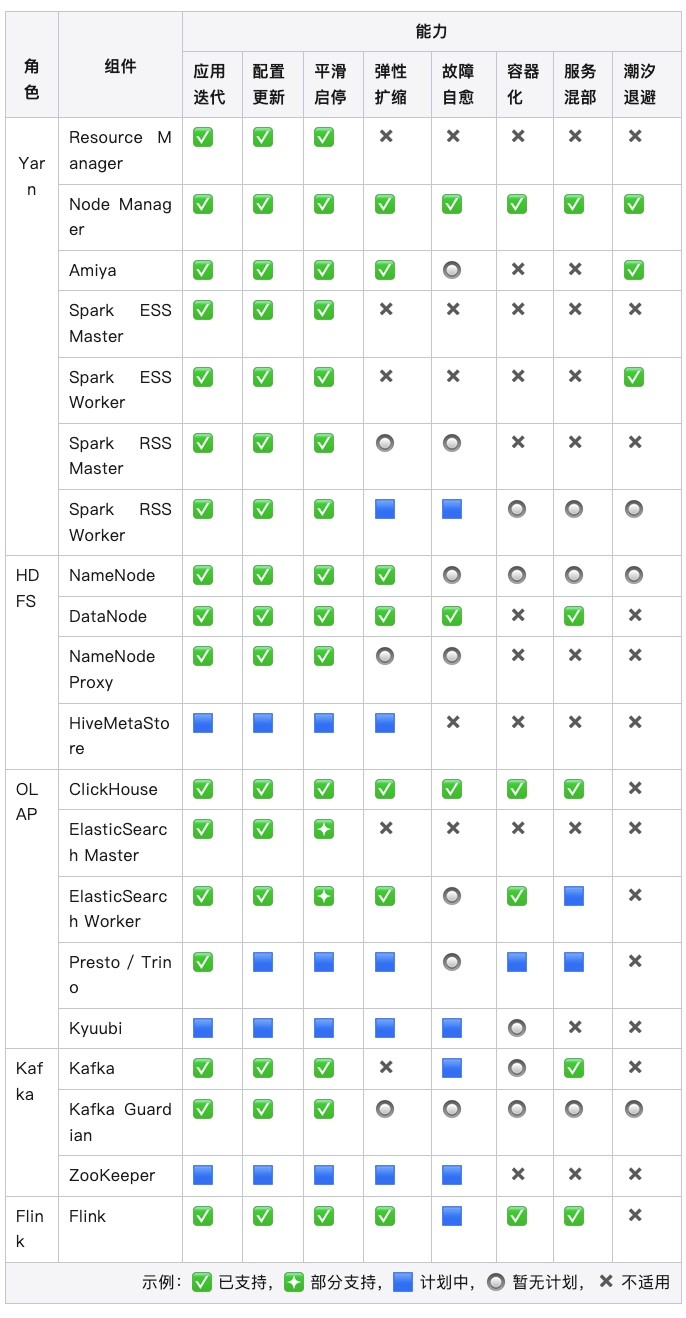
下图是截至2024年6月初,统计到B站大数据的服务规模:
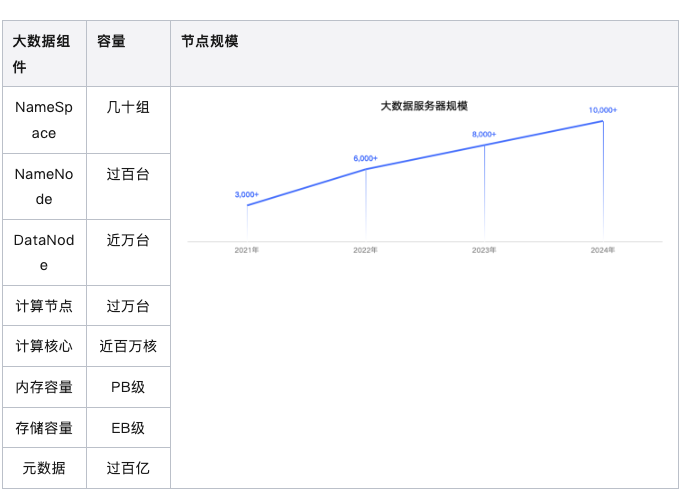
大数据所需承载的业务种类愈加繁多,为更好地承接业务场景的诉求,同时提升稳定性要求,我们大数据集群管理平台的建设,经历了以下主要几个阶段:
阶段一(求生存)
聚焦系统环境标准化、服务配置标准化,清扫野蛮成长过程中非标生产留下的债务(层出不穷的奇怪问题)。
快速和花样地迭代姿势,满足业务高速发展诉求。将各服务的安装包、配置纳入版本管理,服务状态有效透出,完成状态管理和分享。同时打通在线业务的门禁管理,快速迭代过程中不失稳定性考量。
(标准化工作嵌入迭代发布、配置发布、灰度发布中,同时支持常用的新增节点、快速部署、节点上下线等能力。管理上支持机器分组、打标、自定义流程、异构配置管理等)
阶段二(追温饱)
- 建设元仓,打通服务间数据互通,实现问题的快速诊断。
- 场景化建设,如:机房迁移所需的大批量、持续性项目,故障自愈能力等。
- 提升覆盖面,边缘场景或非高频变更场景。如:Yarn队列管理、Lable变更、主从切换、HDFS数据迁移、HMS元数据管理等。
阶段三(奔小康)
拥抱云原生,拓展容器化管理能力。更好利用在业务内和业务间的资源,实现降本增效。服务混部、潮汐退避 火力全开,追求更高的利用率的同时降低IT成本支出。
建设容量管理,完善服务的异常预警、风险预测、故障自愈,进一步完善集群自动化运维体系,进一步追赶业务对大数据赋能的预期。
阶段四(共富裕)
强化可观测能力,数据更接近业务视角,自上而下清晰对齐、指引方向。
化被动为主动,从异常监控到故障自愈,再从故障自愈走向故障预测。
极致追求服务质量,度量服务质量、死磕服务质量。
二、面临的挑战
接下来,我将在大数据平台化过程中遇到的典型问题和解决思路分享如下。
2.1、节点一致性问题
在元数据未闭环联动的情况下,一致性无法得到保障。B站的大数据集群当前仍以物理机为主,正在逐步容器化的阶段。大数据服务组件繁多,叠加多版本、混合部署、部分容器化等诸多因素,让元数据一致性的保障工作更加复杂。在完全平台之前,还存在脚本甚至人工操作,状态的变更无法有效闭环。节点遗漏和信息错误的情况时有发生,轻则服务器未有效利用,重则集群服务存在多个版本,留下稳定性隐患甚至直接影响业务生产。
不断完善覆盖面和使用场景的同时,一些重要的且短时间未实现数据闭环的场景,BMR在‘智能运维’模块的‘巡检’能力,去兜底去发现未知原因产生的脏数据或不一致的问题,让风险尽早被发现、被干预、被解决。
2.2、标准规范的制定和实施
集群标准,需要结合历史和当前情况来制定,并非设计而来。且实施过程,需要考虑兼容、迁移的能力和资源、实施周期等因素。过程中要根据集群支持的业务特点、环境、版本进行划分,如:实时集群、离线集群(2.8版本和3.2版本)等, 线上存在多个生产集群。在前期组件服务的部署规范和配置文件的标准化不足,存在同一集群内同一组件在不同节点部署环境都存在差异情况。在平衡标准化和差异化的过程中,‘小步快跑’地进行标准化的制定、试运行、修正、公示,技术项的标准最终固化到平台功能中。
2.3、规模化的管理
当“量变引发质变”和“不必过度设计”遇到“业务飞速发展”时,及时调整管理策略满足业务发展需求,极具挑战。
大数据玩的就是数据,硬盘少不了。当前我们的大数据集群磁盘数量在十万量级。每天磁盘正常故障超10块, BMR在‘智能运维’模块集成了‘硬盘故障自愈’的能力,打通各个平台的数据和流程,实现业务无感式的换盘。还有操作系统层面的内核管理与升级,在面临节点数量多、需要无感/无故障的管理,都会对平台提出更高的要求。
而且在机房资源紧张的情况下,会涉及集群迁移甚至机房迁移的工作。如何不停机实现迁移,BMR上也都做了适配。
2.4、提升迭代效率
单纯提效不难,难的是在复杂场景中保证稳定的前提下。
生产不能停,迭代要继续,规模同时要满足发展需要。BMR在建设迭代能力的同时,通过元数据的管理监测资源容量。本着尽可能地避免问题、尽早地暴露问题的原则,集群资源做了分层、隔离以保安全,迭代过程也必备了‘灰度’、‘快速回滚’、‘异常探测’以便快速发现和快速解决问题。
同时多集群、多组件、多角色的‘变更冲突’需要加以限制,变更信息的‘透明化’和‘快速回滚’利于故障快速诊断与恢复。跨团队协作中,复用在线业务平台的通知与协同能力,实现消息的精确触达和快速应急响应。
2.5、削峰填谷
降本增效大背景的今天,资源有效利用也不是新话题。大数据业务和在线业务有着天然的资源错峰潜质,BMR当然不会放过。我们已在2023年实现大数据业务与在线业务的资源潮汐退避,大数据业务白天出让资源给在线业务使用,在线业务夜间归还的同时也出让冗余的资源给到大数据,实现‘削峰填谷’和‘资源共赢’。
三、平台实践

秉着先解放双手再系统闭环然后贴进业务的思路,BMR(大数据管理平台)逐步拆招解招。
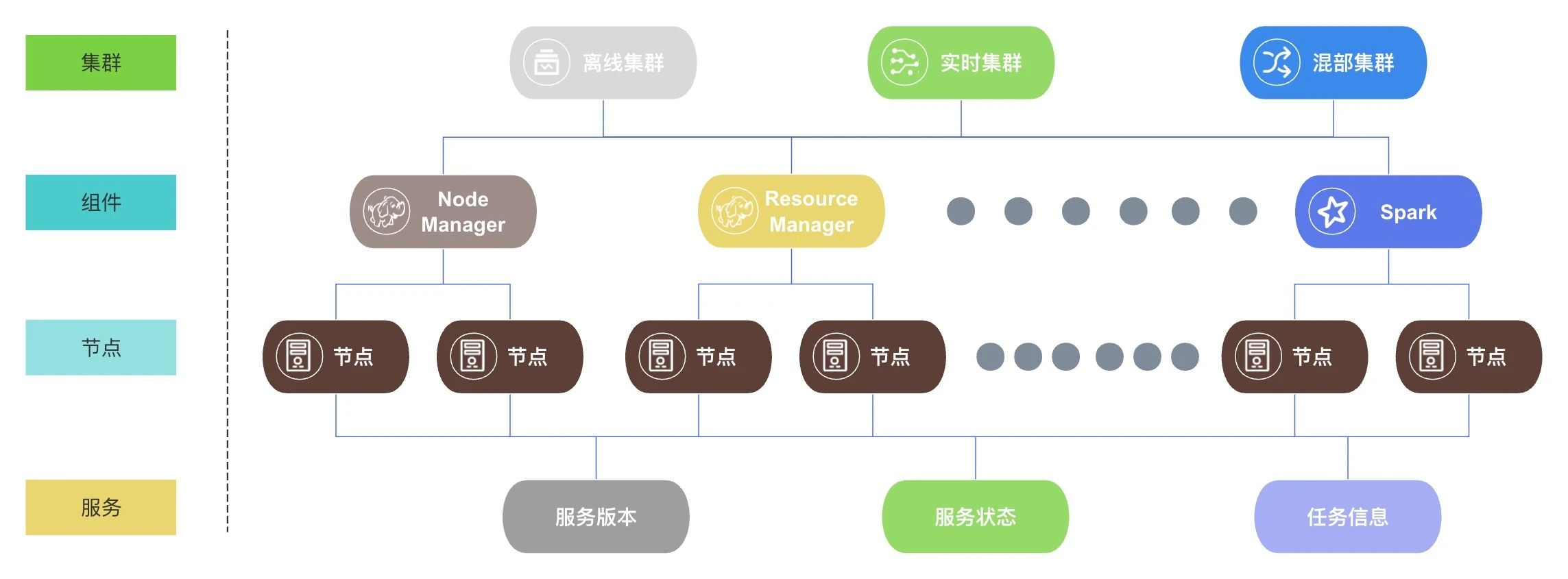
系统整体架构如下图所示,BMR主要由集群大盘、集群管理、组件管理、变更管控和资源管理功能模块构成。
底层复用公司的‘Job任务’平台,使用 DolphinScheduler 做逻辑调度。 业务数据和逻辑集中在‘元数据’、‘配置中心’、‘主机管理’和‘发布服务’四大模块中,对用户由‘集群大盘’、‘集群管理’、‘组件管理’、‘变更管控’和‘资源管理’来呈现。
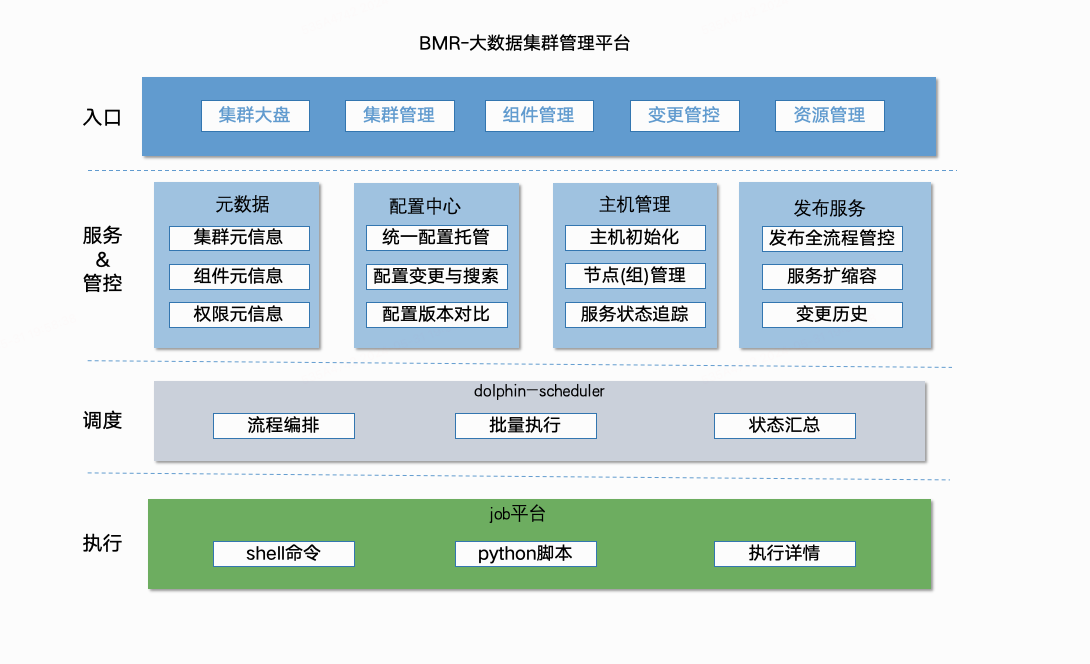
产品层本着‘一站式’的思想, 在操作集群管理时, 用户只需选择发布的组件、对应的主机节点, 及发布策略, 即可快捷完成变更操作。把复杂的逻辑和后端留给BMR,让用户只关心他需要关心的。
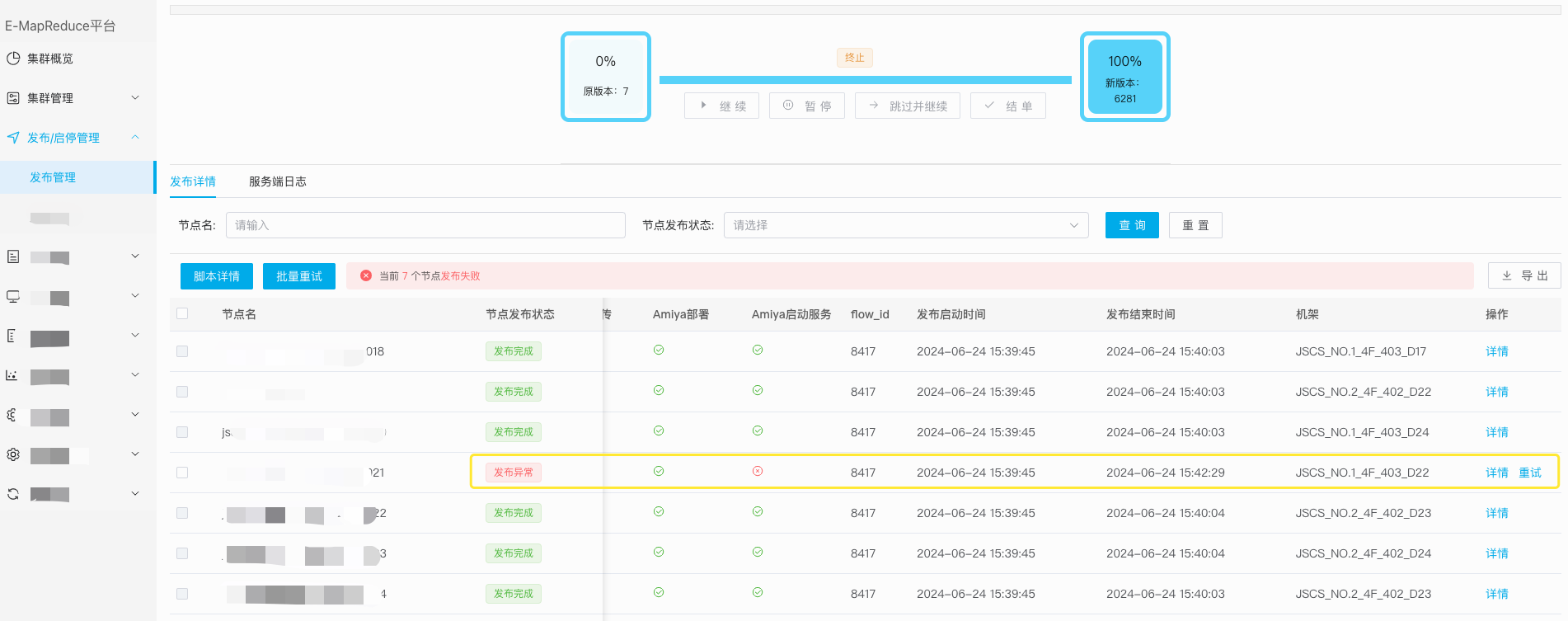
为更好适配不同组件和用户的使用需求,变更流程设计整体分为节点选择策略(分批执行)、执行前置操作、调度执行、执行后置操作几个核心操作,流程示意图如下: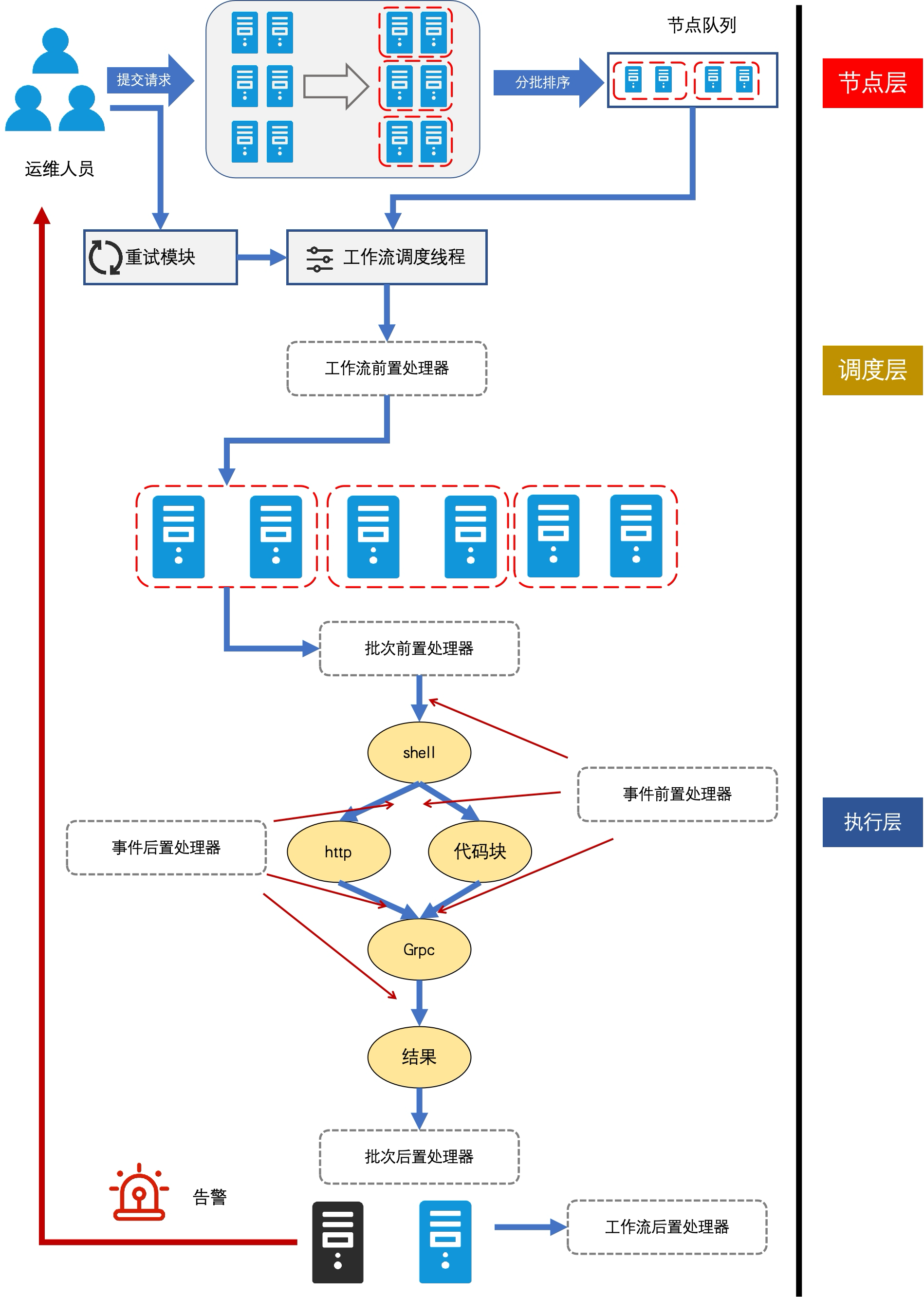
3.1、集群管理
为适配不同业务、不同规模、不同网络环境、不同用途的部署方式,同时考虑到开发周期和成本。底层功能模块尽可能的通用、可复用,上层应用区分用户视角和管理视角。用户视角仅显示有权限的集群,更多展示查看、监控类的实例。管理视角则可以快速新增创建并部署集群。当前我们已经支持了如 HDFS、Spark、Flink、ClickHouse、Kafka等集群管理能力。
3.2、组件管理
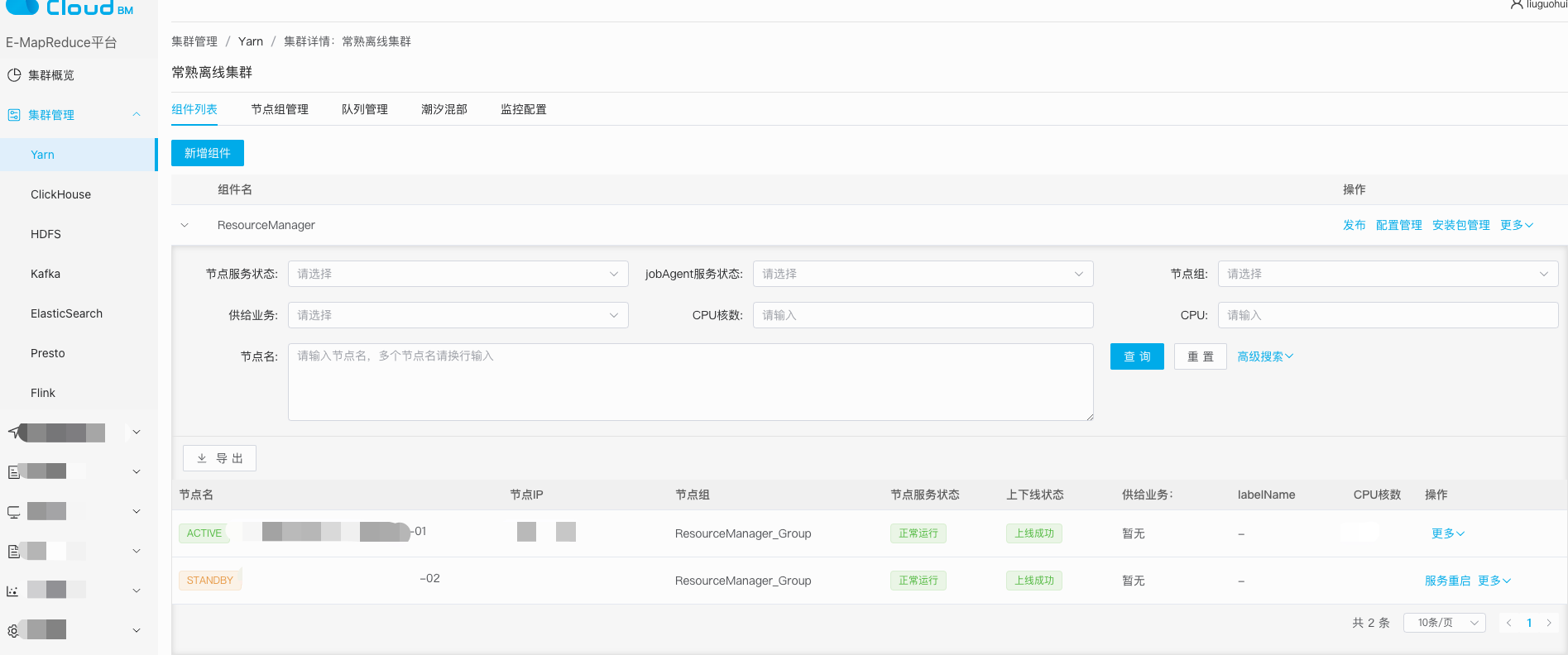
- 3.2.1、支持新增组件,查看组件部署的节点及组件服务的运行状态
在组件管理视角,我们优先支持了组件的‘增/删/改’及‘状态监控’的功能。这里的难点是不同集群部署的组件服务, 对应配置存在差异。为更好支持差异化管理诉求,集群管理平台支持不同集群组件的自定义添加、组件变更管理及对应配置等管理需求。
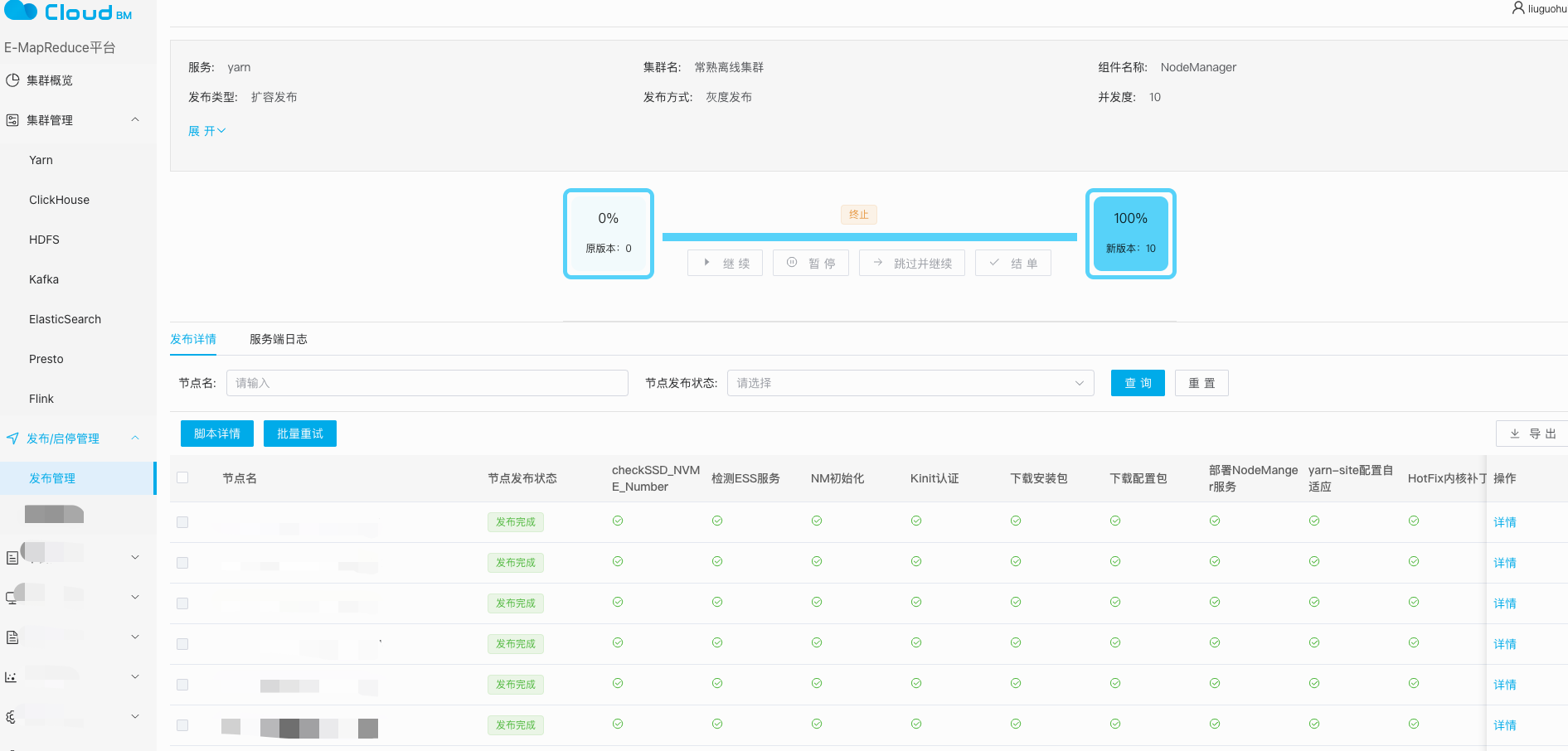
- 3.2.2、支持组件服务的扩容、迭代、缩容等发布操作
组件的‘扩缩容’和‘迭代变更’基础能力具备后,上层即可包装成各种应用需求。同时提供变更可视化,也支持发布策略定制。比如:
并发度设置: 一次同时变更多少台节点,当前并发度最高限制200,避免一次同时变更过多,对线上任务造成影响。
容错度设置: 变更过程中失败节点数到达容错度后,发布操作自动暂停,及时告警通知发布者,并人工介入检查,是否存在风险。
发布暂停、继续、跳过错误并继续等发布控制等。
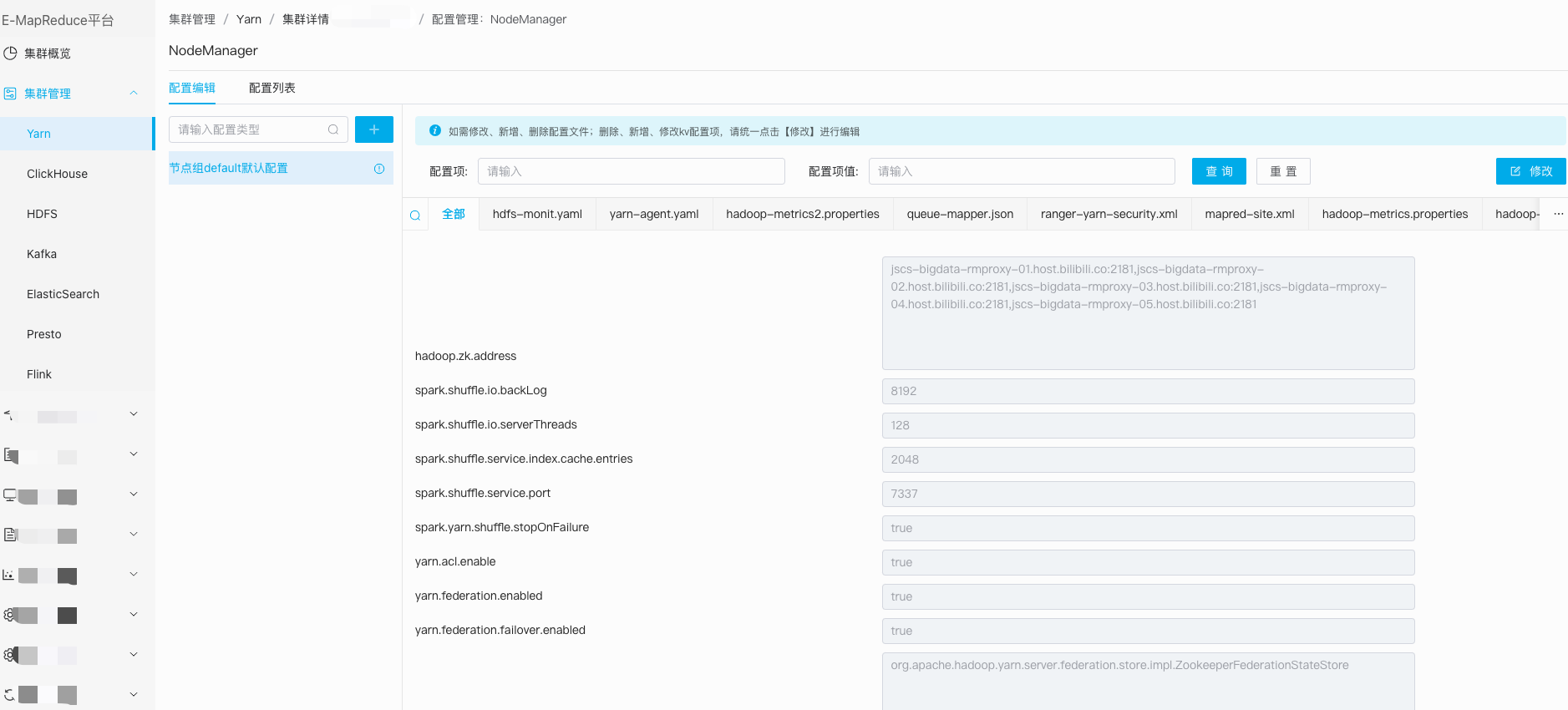
- 3.2.3、组件配置管理
最早的配置文件,多数是在git上管理,本地文本编辑。容易出现导致文件格式、配置项错误等问题。也出现过集群部分运行时配置和磁盘上对应配置不一致问题,和线上节点配置版本无联动,给问题定位排查带来风险和困难。
BMR的配置管理,支持版本快照功能,可按照配置项快速检索,同时在修改保存时有合法性检查,周期性巡检集群节点磁盘上配置的版本和服务运行生效版本不一致的预警。
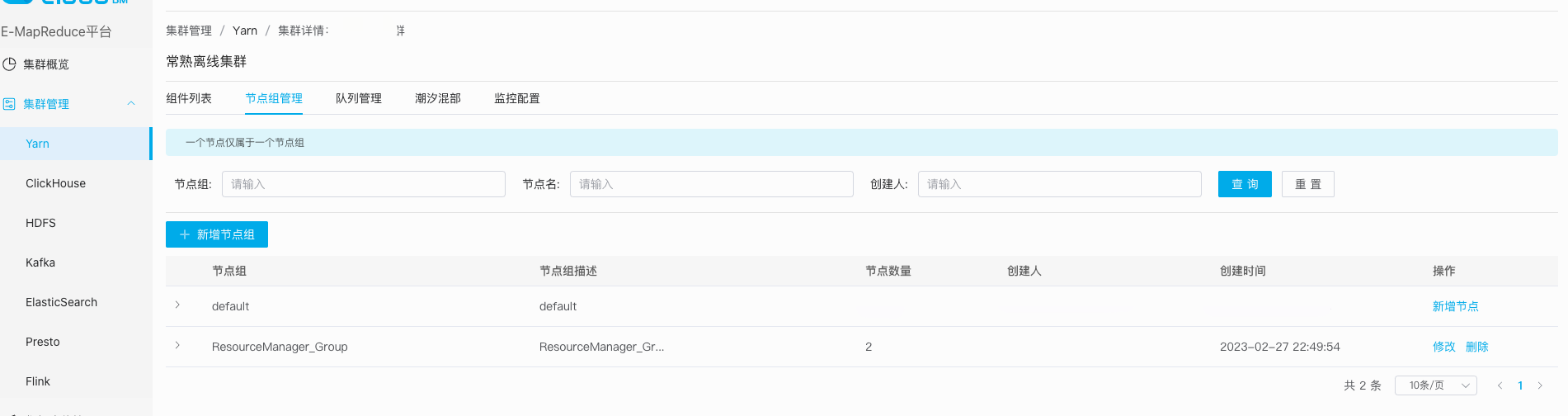
3.3、节点管理
不同角度和不同场景,也有对节点管理的需求。特别在差异化管理和问题诊断的场景,以及未闭环场景下的使用。
如:适配硬件配置差异而产生的应用配置差异、不同队列使用不同配置、不同服务使用不同版本,同时也支持管理查看节点服务运行情况, 服务版本部署监控状态等。
3.4、队列管理
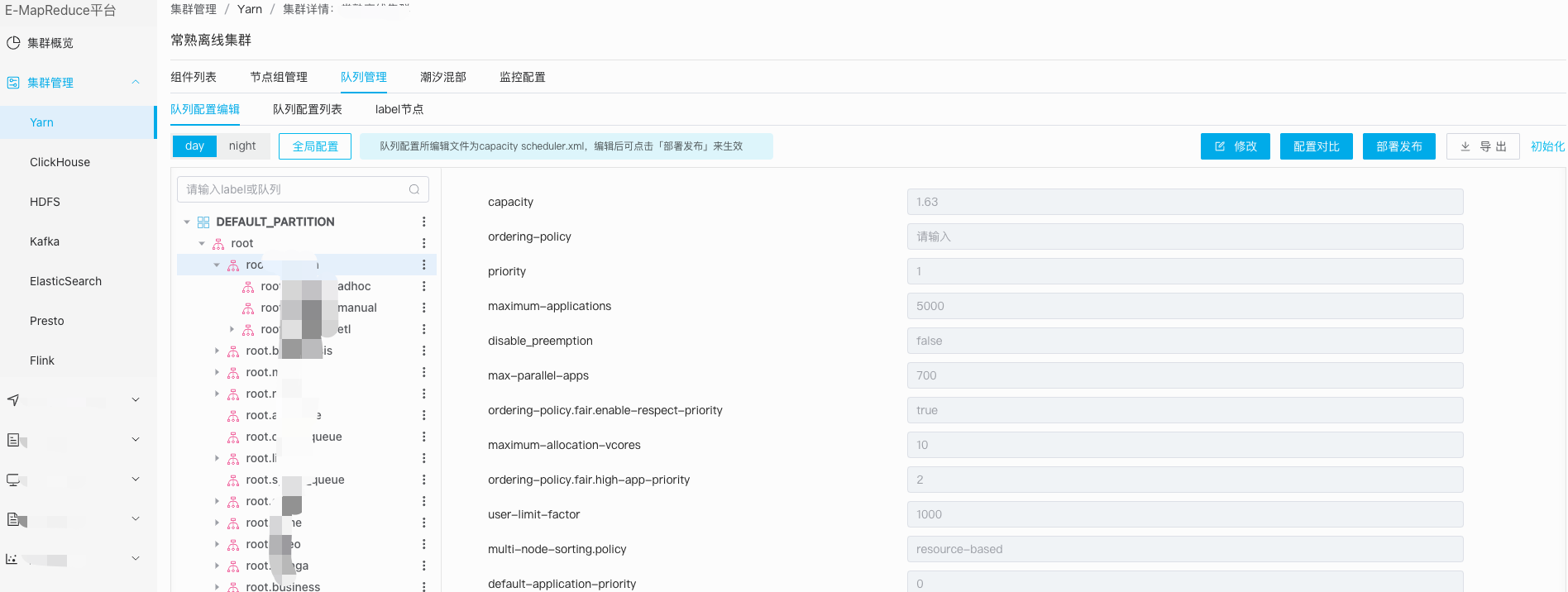
线上Yarn资源调度采用Capacity模式,集群根据不同部门、任务优先级等规则会划分多个队列资源, 前期通过文本编辑的形式对配置进行修改调整,存在编辑繁琐、易出错等问题。BMR为此提供了Yarn队列的在线可视化编辑能力, 支持新增、删减队列、同时会对队列资源的capactiy百分比合法性校验, 也支持队列配置项调整对全局或部分队列生效等快捷操作。如图示意:
四、技术方案
通过大数据集群管理平台化的建设,解决我们遇到的迭代效率、稳定性等问题,主要围绕集群管理、节点管理、服务管理、组件管理、节点运行任务等几个维度进行建设,整体逻辑关系如下:
当前线上存在多套大数据集群,每套集群都存在多个组件,在平台落地的过程中。面对上述提及的问题和挑战,我能通过组件工作量管理来应对。
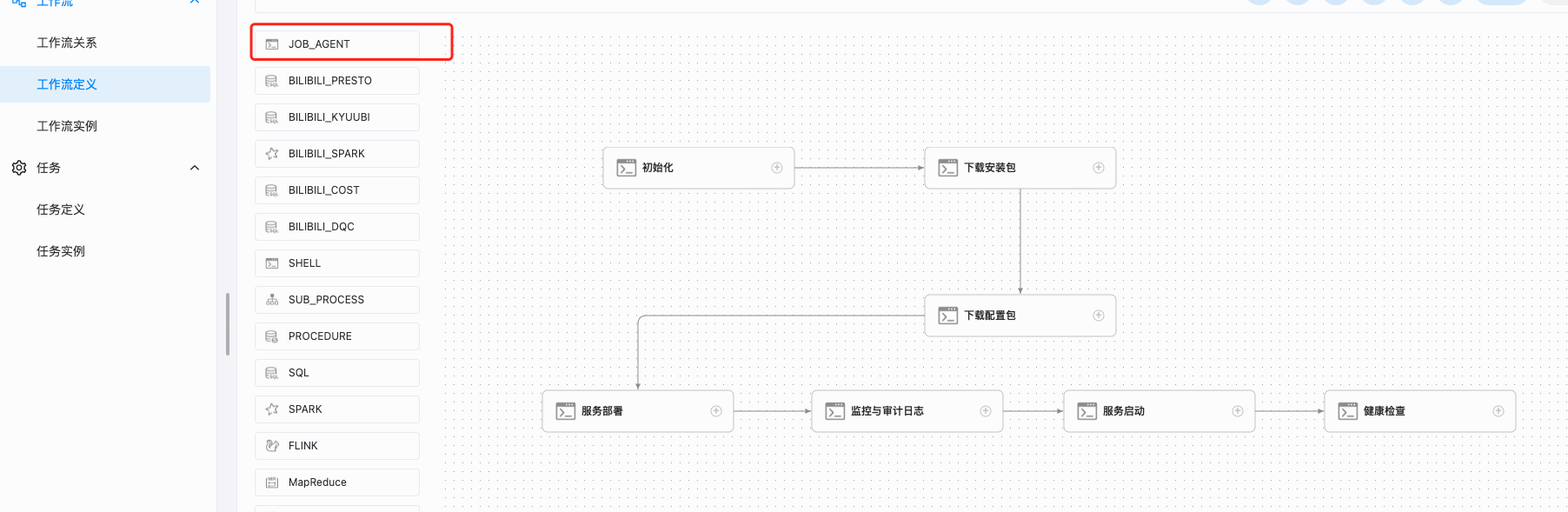
4.1、组件流程管控
大数据集群平台不同组件管理的核心差异点,在于其变更执行流程差异,基于此我们构建了组件工作流的管理模块,同时支持不同组件的执行流程可视化配置管理,基于Apache DolphinScheduler框架进行了二次开发, 利用其流程DAG可视化编辑能力,扩展了TaskPlugin适配我们的集群组件变更管理的业务场景。
4.2、变更影响可控
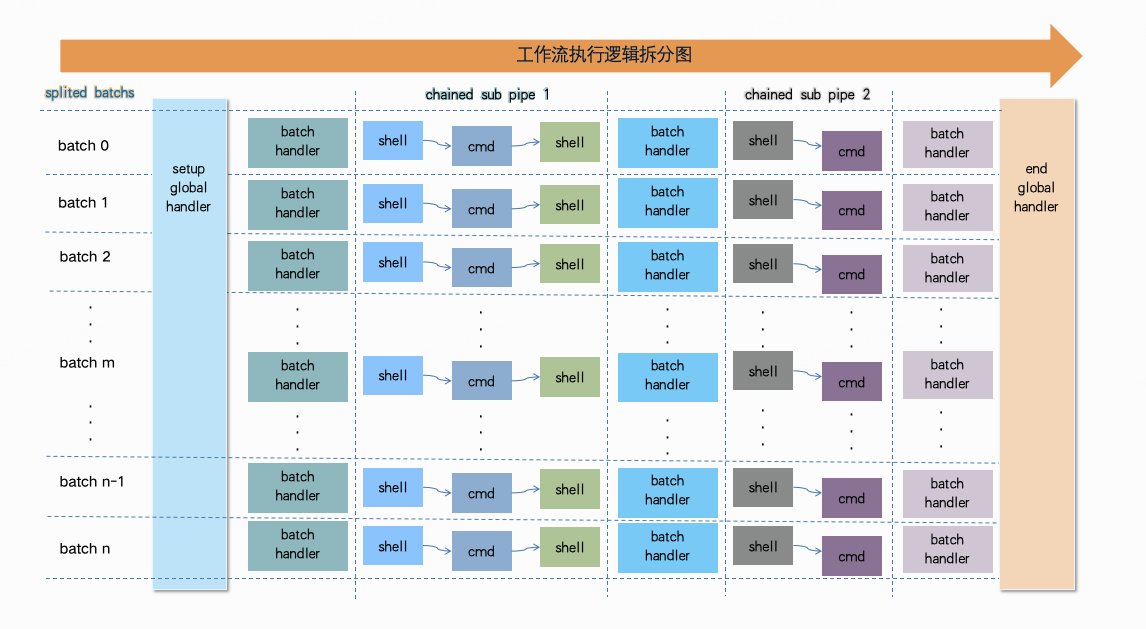
为了保证变更平稳可控, 减少因为变更带来的集群线上任务稳定性问题, 支持以下变更策略:
按批次灰度,可根据组件变更影响差异 ,支持自定义每批次变更节点数量, 当前每批次上限200节点。
批次之间有序执行,并相互隔离,出现异常仅影响本批次。
4.3、异常节点容错
容错策略
异常重试
工作流程执行时, 支持过滤异常错误节点
支持批次内异常跳过, 继续执行下一批次
4.4、跨组件依赖和全局变更
以DataNode节点缩容场景为例,DN涉及数据迁移问题,整个下线流程相对比较繁琐, 如机房搬迁场景使用Fast Decommission方式快速迁移数据、 节点故障维修场景 通过Decommission方式迁移数据等,整体执行流程如下图所示:
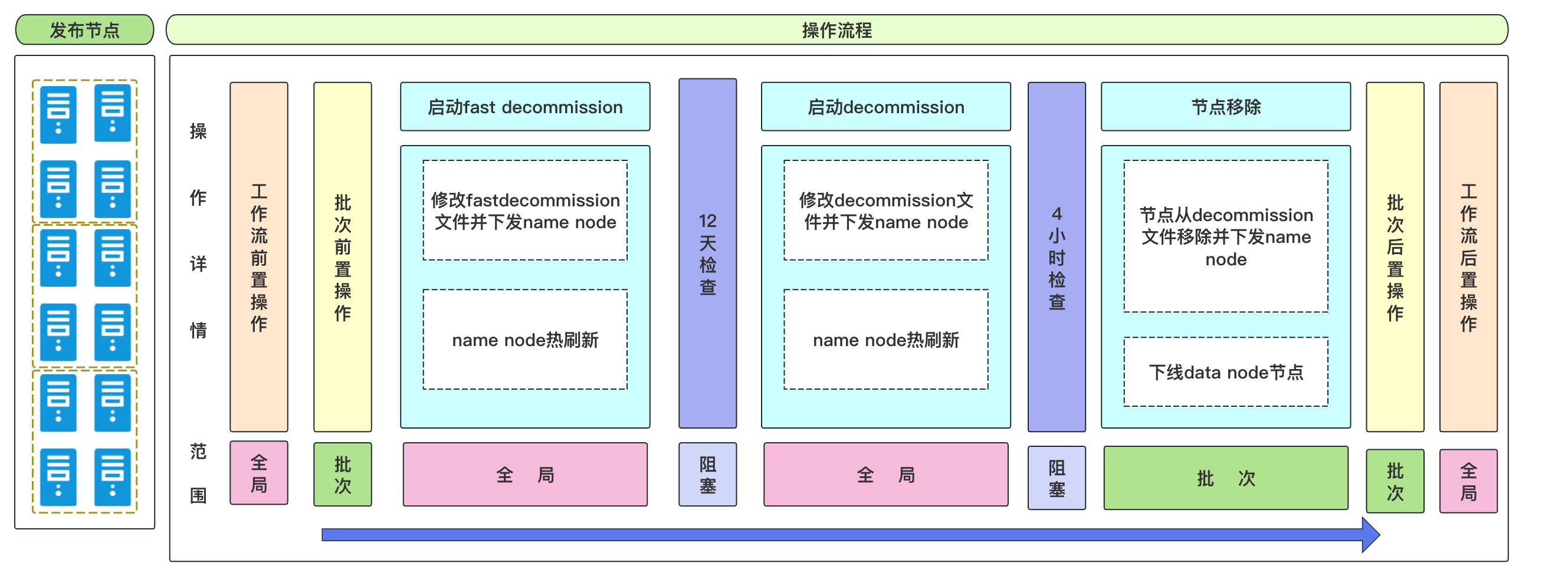
在DataNode下线流程中,同时涉及DataNode、NameNode组件的变更。缩容操作步骤中存在全局变更(NameNode节点级别)、部分变更(DN节点即便)、阻塞等待等互斥操作。
针对这种复杂变更场景, 通过支持DN下线流程嵌套子流程,来操作不同的变更对象。通过子流程方式我们可以对所需的依赖组件同时进行变更, 可方便快捷进行操作。
五、未来规划
降本:深化资源利用率提升,进一步榨取运算资源。
提效:增加故障自愈和故障预测的覆盖面,降低风险的同时减少人力投入。
稳定性:大数据组件众多,继续提升覆盖率,将标准化和迭代可控坚持到底。
稳定性:把控容量的可观测性,将功能之外风险拒之门外。
服务质量:建立服务质量管理体系,指引技术改进与服务质量提升。
-End-
作者丨国辉
本文由 白鲸开源科技 提供发布支持!
















 813
813

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











