







引言
我叫李庆旺,是Cisco Webex的一名软件工程师,同时也是Apache DolphinScheduler(以下简称DS)的Committer。

在过去的两年里,公司基于Apache DolphinScheduler进行了多项持续改进和创新,以更好地适应我们的业务需求。本文将介绍这些改进的具体内容,以及我们对社区的贡献。
主要包括以下五个部分:
- 我们的系统架构
- 在业务上遇到的挑战以及解决方案
- 探讨在安全性方面所做的优化和关键指标
- 我们对社区的贡献
- 遇到的有趣技术问题。
公司及项目背景
首先,跟大家简要介绍一下我们公司。Cisco Webex是一家专注于开发和销售在线会议产品的软件公司,这些产品包括Meeting、Calling、ContactCenter等。

我们团队设计并搭建了一个大数据平台,为上述产品的数据接入和处理提供支持。以Webex Meeting产品为例,Webex会议会生成各种指标。当会议进行时,客户端和服务器会向我们的Kafka集群发送指标和日志。
外部和内部客户依赖这些指标来优化会议体验或生成相关报告。
我们的愿景是打造一个能够服务于内部和外部客户的大数据平台,通过消除数据孤岛,实现所有基础设施的整合,并且该平台需要能够适应公共云和现有私有数据中心的架构。
由于思科网讯是一家全球协作服务提供商,我们的客户跨越多个时区和大洲,因此我们在全球拥有许多数据中心。这些数据中心包括本地自我管理的数据中心 Webex DC,同时最近两年,我们也支持了亚马逊云管理的集群。
调度选型
三年前,我们选择了Apache DolphinScheduler作为我们的工作流数据处理引擎,原因是它的功能强大、设计优雅且易于扩展。我们最初使用的版本是2.0.3,之后升级到了3.1.1。
感兴趣的朋友可以参考公众号的文章
- 使用 Apache DolphinScheduler 构建和部署大数据平台,将任务提交至 AWS 的实践经验:https://mp.weixin.qq.com/s/Md5C84kZLA_H4pdfzLmxbw
- 杭州思科对 Apache DolphinScheduler Alert 模块的改造:https://mp.weixin.qq.com/s/cyGs1MHnlxhLBl0mumJBdg
- Apache DolphinScheduler2.0升级3.0版本方案:https://mp.weixin.qq.com/s/tZMEatdnQibX7ifxp67DTQ
技术架构
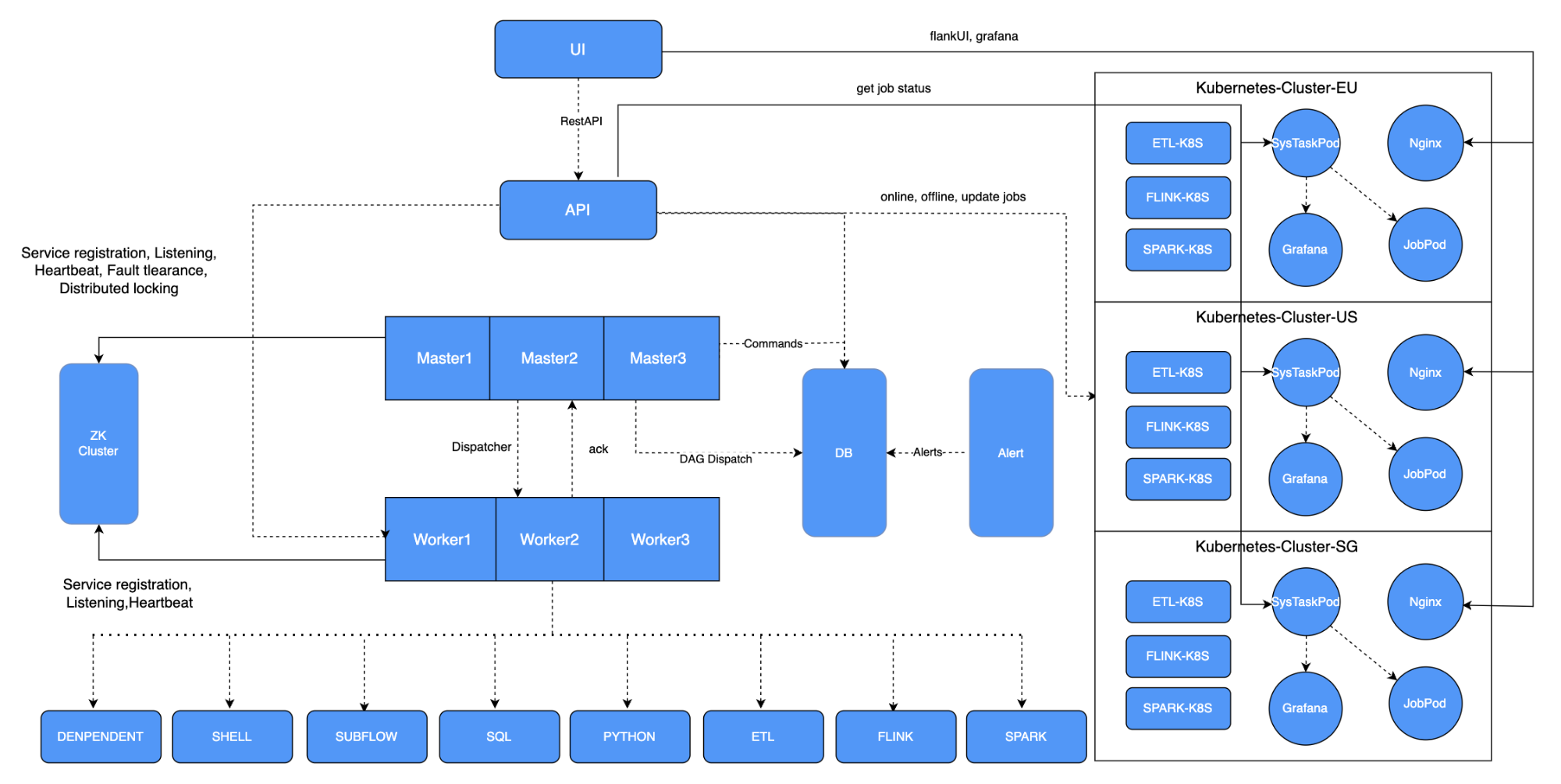
以上是两年前的架构图,基于社区版本,我们做了一些适应性的改动。
由于平台部署在K
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











