







slava是作者参与的一个github开源项目,项目的主要的工作是用Go语言构建一个高性能、K-V云数据库。 slava项目的连接
slava是一个K-V云数据库,本文作者将实现slava的内存数据库,链接: 源代码
slava的底层数据库是一个k-v存储库,如何实现一个高并发安全的k-v存储库呢?
经过与组员和作者的思考有三个思路:
(1)最容易想到的思路就是,普通的map+读写锁的方式,读写锁是一种写优先锁,可能会造成读操作阻塞,这样的方式在高并发场景中会造成锁资源的竞争问题,性能较差。
(2)有的组员提出采用sync.Map,这是Go自带的线程安全的map。对于sync.Map的详细剖析,可以看作者的另一篇blog, sync.Map的详细分析。
但是经过作者的思考和分析,sync.Map时Go语言自带的线程安全的map,但是它适用于读多追加少的场景,不适用于大量追加的场景,在追加的时候在read map中查找不到数据的时候,会进行加锁对dirty map进行操作,并进行提升和重构。但是,在 dirty map 刚被提升后,将 read map 复制到新的 dirty map中,在存在大量的数据的情况下复制操作会阻塞所有的协程极大的影响性能。
(3)最终作者通过对比和分析,决定采用将一个map切分成若干个小的map,采用分段map,并采用分段锁的机制。将key值分散到若干个map中,在对某个小的map进行并发的读写的操作的时候,加上读写锁,只会阻塞当前的一个map,并不影响其他的map。同理,在map进行扩容操作的时候,只会在加锁的时候阻塞当前的map,其他的map不受影响。后续开发的事实中证明该方法具有较高的性能,能够应对高并发场景。
1.定义一个k-v存储的底层接口Dict
首先定义了一个Dict接口,该接口中包含了底层k-v存储库需要实现的函数。定义一个接口的目的是,在实现的时候可以根据需要选择不一样数据结构进行实现,比如普通的map、sync.Map,分段map等,方便后续项目的更新迭代。
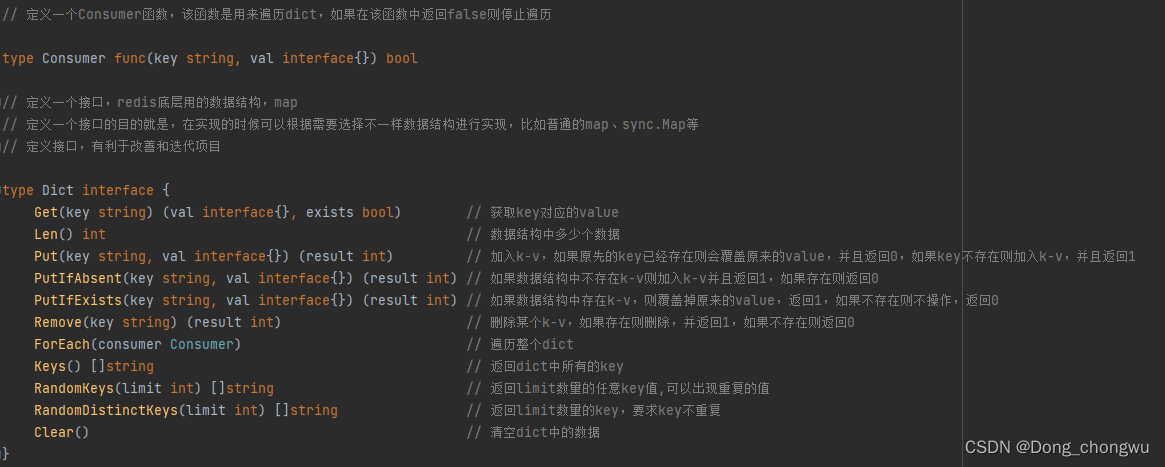
2.分段map实现Dict接口,并发的k-v存储库

定义了一种数据结构ConcurrentDict,里面包含一个table数组,该数组指向的是一个shard结构体,该结构体中是一个普通的map和一个读写锁。这表明table数组是多个map的集合,每个map中有自带有读写锁。 除此之外,count字段表示的是整个k-v存储库中含有的数据量,shardCout表示的是该存储库中含有多少个map。
3.对concurrentDict进行初始化
// 计算需要多个map
func computeCapacity(param int) (size int) {
if param <= 16 {
return 16
}
n := param - 1
n |= n >> 1
n |= n >> 2
n |= n >> 4
n |= n >> 8
n |= n >> 16
if n < 0 {
return math.MaxInt32
}
return n + 1
}
// 初始化ConcurrentDict
func MakeConcurrent(param int) *ConcurrentDict {
shardCount := computeCapacity(param)
table := make([]*shard, shardCount)
for i := 0; i < shardCount; i++ {
table[i] = &shard{m: make(map[string]interface{})}
}
cd := &ConcurrentDict{
table: table,
count: 0,
shardCount: shardCount,
}
return cd
}
4.设置哈希函数,哈希算法选择
// Prime32 = uint32(16777619)
func fnv32(key string) uint32 {
hash := uint32(2166136261)
for i := 0; i < len(key); i++ {
hash *= Prime32
hash ^= uint32(key[i])
}
return hash
}
5.定位到某个map并且拿到map对应的shard
// 定位到某个shard中
func (dict *ConcurrentDict) spread(hashCode uint32) uint32 {
if dict == nil {
panic("dict is nil")
}
tableSize := uint32(len(dict.table))
return (tableSize - 1) & hashCode
}
// 获得对应的shard,也就是拿到相应的map
func (dict *ConcurrentDict) getShard(index uint32) *shard {
if dict == nil {
panic("dict is nil")
}
return dict.table[index]
}
6.实现Dict接口,实现k-v存储库的功能函数
// 获取key的value
func (dict *ConcurrentDict) Get(key string) (val interface{}, exists bool) {
if dict == nil {
panic("dict is nil")
}
// 先计算该key的哈希值
hashCode := fnv32(key)
// 定位到某个shard
index := dict.spread(hashCode)
// 找到相应的shard
sh := dict.getShard(index)
// 对map进行读取的时候加读锁
sh.mutex.RLock()
// 解锁
defer sh.mutex.RUnlock()
// 获取数据
val, exists = sh.m[key]
return
}
// 返回k-v存储库中的数据量大小
func (dict *ConcurrentDict) Len() int {
if dict == nil {
panic("dict is nil")
}
return int(atomic.LoadInt32(&dict.count))
}
// 往dict中加入数据
func (dict *ConcurrentDict) Put(key string, val interface{}) (result int) {
if dict == nil {
panic("dict is nil")
}
// 先获得key的哈希值
hashCode := fnv32(key)
// 获取shard的index
index := dict.spread(hashCode)
// 获得对应的shard
sh := dict.getShard(index)
// 加锁,写锁
sh.mutex.Lock()
// 解锁
defer sh.mutex.Unlock()
// 判断是否存在key值
if _, ok := sh.m[key]; ok {
sh.m[key] = val
return 0
}
sh.m[key] = val
// 不存在的话,先让dict中的数据++
atomic.AddInt32(&dict.count, 1)
return 1
}
// 不存在的时候添加,如果不存在添加后返回1,如果存在则返回0
func (dict *ConcurrentDict) PutIfAbsent(key string, val interface{}) (result int) {
if dict == nil {
panic("dict is nil")
}
hashcode := fnv32(key)
index := dict.spread(hashcode)
sh := dict.getShard(index)
sh.mutex.Lock()
defer sh.mutex.Unlock()
if _, ok := sh.m[key]; ok {
return 0
}
sh.m[key] = val
atomic.AddInt32(&dict.count, 1)
return 1
}
// 存在的时候修改,存在则修改并返回1
func (dict *ConcurrentDict) PutIfExists(key string, val interface{}) (result int) {
if dict == nil {
panic("dict is nil")
}
hashCode := fnv32(key)
index := dict.spread(hashCode)
sh := dict.getShard(index)
sh.mutex.Lock()
defer sh.mutex.Unlock()
if _, ok := sh.m[key]; ok {
sh.m[key] = val
return 1
}
return 0
}
// 删除节点
func (dict *ConcurrentDict) Remove(key string) (result int) {
if dict == nil {
panic("dict is nil")
}
hashCode := fnv32(key)
index := dict.spread(hashCode)
sh := dict.getShard(index)
sh.mutex.Lock()
defer sh.mutex.Unlock()
if _, ok := sh.m[key]; ok {
delete(sh.m, key)
atomic.AddInt32(&dict.count, -1)
return 1
}
return 0
}
// 遍历节点
func (dict *ConcurrentDict) ForEach(consumer Consumer) {
if dict == nil {
panic("dict is nil")
}
for _, s := range dict.table {
s.mutex.RLock()
for key, value := range s.m {
b := consumer(key, value)
if !b {
break
}
}
s.mutex.RUnlock()
}
}
// 返回所有的key
func (dict *ConcurrentDict) Keys() []string {
if dict == nil {
panic("dict is nil")
}
i := 0
keys := make([]string, dict.Len())
dict.ForEach(func(key string, val interface{}) bool {
//keys[i] = key
//i++
// 采用下面的代码的原因主要是为了应对并发问题
// 在初始化keys数组后,可能会有新的key加入到dict中
if i < len(keys) {
keys[i] = key
i++
} else {
keys = append(keys, key)
}
return true
})
return keys
}
// 设置一个函数,随机从shard里面去一个key出来
func (s *shard) RamdomKeyFromShard() string {
s.mutex.RLock()
defer s.mutex.RUnlock()
for key := range s.m {
return key
}
return ""
}
// 随机从dict中取limit个keys,可能会包含重复值
// 随机数的取法上做了变化,允许选择相同的shard
// 采用
func (dict *ConcurrentDict) RandomKeys(limit int) []string {
if dict == nil {
panic("dict is nil")
}
// 结果
result := make([]string, limit)
// 一共含有多少个shard
shardCount := dict.shardCount
// 添加随机种子
nR := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < limit; {
// 获取shard,可能获取到的shard是没有任何元素的,下面需要进一步判断
sh := dict.getShard(uint32(nR.Intn(shardCount)))
// 如果shard没有初始化
if sh == nil {
continue
}
key := sh.RamdomKeyFromShard()
// 选到的shard里面可能是什么都没有存储有的,所以key可能为”“
// 如果key为空则不进行i++,继续选择随机数,然后继续随机生成shard,进行取值
if key != "" {
result[i] = key
i++
}
}
return result
}
// 随机获取limit个key值,保证key不能重复
func (dict *ConcurrentDict) RandomDistinctKeys(limit int) []string {
if dict == nil {
panic("dict is nil")
}
if limit >= dict.Len() {
return dict.Keys()
}
result := make([]string, limit)
// 定义一个map,用来存储已经拿出来的key
existKeyMap := make(map[string]struct{}, limit)
// 产生随机不重复的数字
nR := rand.New(rand.NewSource(time.Now().UnixNano()))
for i := 0; i < limit; {
sh := dict.getShard(uint32(nR.Intn(dict.shardCount)))
// 如果sh==nil跳过
if sh == nil {
continue
}
// 随机生成一个key
key := sh.RamdomKeyFromShard()
// 判断key的值
if key != "" {
if _, exist := existKeyMap[key]; !exist { // 如果当前的key没有在map中则添加,说明没有遍历过该key
existKeyMap[key] = struct{}{}
result[i] = key
i++
}
}
}
return result
}
// 清空dict,则直接新建一个dict即可,旧的dict让GC回收
func (dict *ConcurrentDict) Clear() {
*dict = *MakeConcurrent(dict.shardCount)
}
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









