






Hadoop课设蔬菜统计
题目要求
蔬菜统计
根据“蔬菜.txt”的数据,利用Hadoop平台,实现价格统计与可视化显示。
要求:通过MapReduce分析列表中的蔬菜数据。
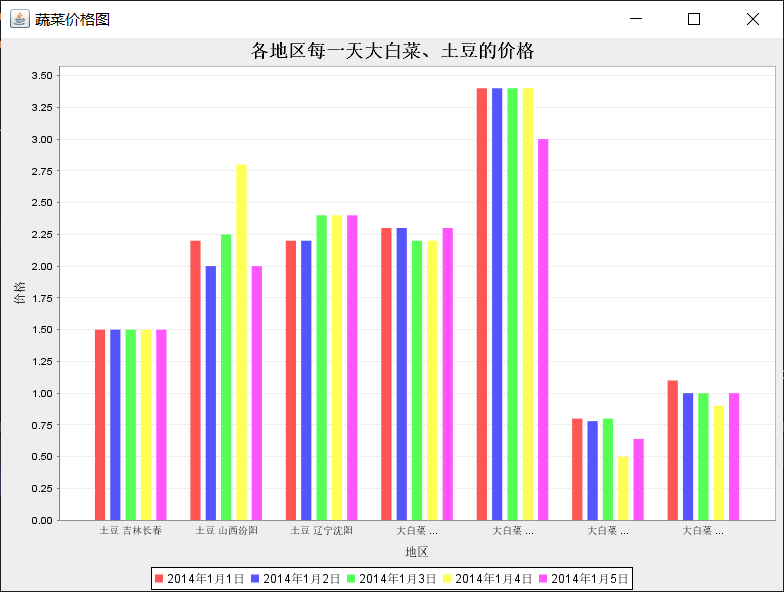
(1)统计各地区每一天大白菜、土豆的价格(柱状图)
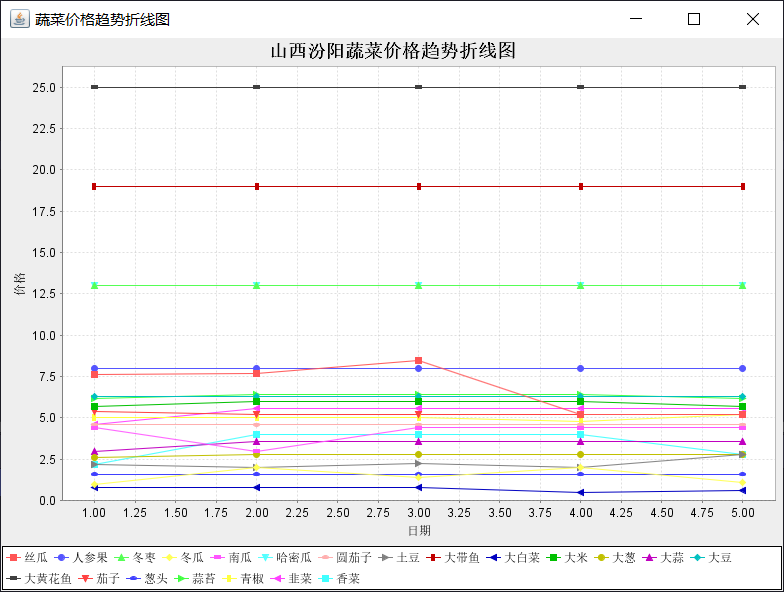
(2)选取一个城市,统计各个蔬菜价格变化曲线(折线图)
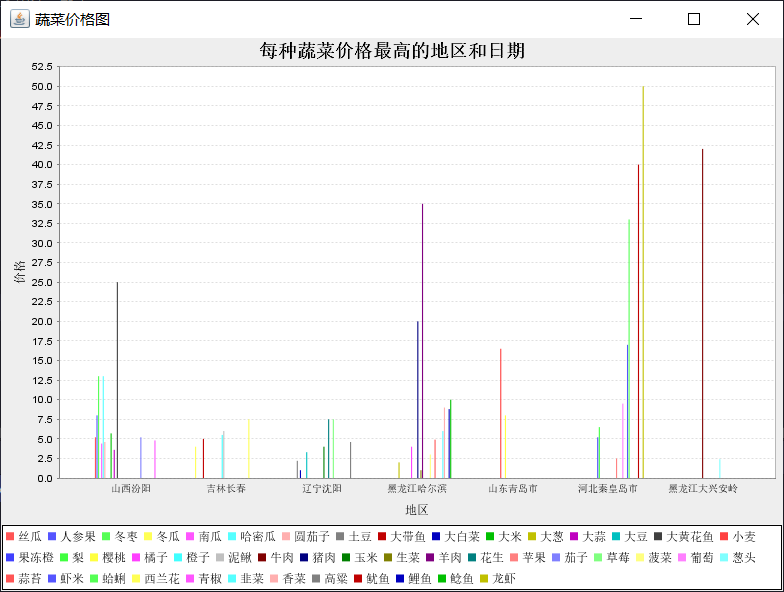
(3)统计每种蔬菜价格最高的地区和日期 (柱状图)
(4)加载Hbase、Hive等软件,并说明
API
(1)map:按列表进行分片分区
(2)reduce:按照要求进行统计
题目分析
-
可以将整体分为三部分:
- 数据分析与清理 理解数据格式
- map reduce作业
- 数据可视化
-
前置准备:我使用的是idea+maven框架 配置Hadoop2.8.3版本(推荐2x 不推荐3x)
-
上传数据文件
-
环境配置这里不过多赘述,大家随便搜都能找到很好的配置教程
-
导入的Maven依赖 pom.xml
这是我调整过很多次最终导入成功的依赖,如果不成功可以多刷新几次,或者可以换一换版本号,hadoop版本和依赖的版本有时需要一致
-
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>java_Hadoop</groupId>
<artifactId>Design_Hadoop</artifactId>
<version>1.0-SNAPSHOT</version>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.8.3</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.3</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>2.3.5</version>
</dependency>
<dependency>
<groupId>org.apache.hive</groupId>
<artifactId>hive-exec</artifactId>
<version>3.1.2</version>
</dependency>
<dependency>
<groupId>org.jfree.chart</groupId>
<artifactId>com.springsource.org.jfree.chart</artifactId>
<version>1.0.9</version>
</dependency>
<dependency>
<groupId>org.jfree</groupId>
<artifactId>com.springsource.org.jfree</artifactId>
<version>1.0.12</version>
</dependency>
<dependency>
<groupId>javax.servlet</groupId>
<artifactId>com.springsource.javax.servlet</artifactId>
<version>2.4.0</version>
<scope>provided</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-jar-plugin</artifactId>
<version>3.1.0</version>
<configuration>
<archive>
<manifest>
<addClasspath>true</addClasspath>
<classpathPrefix>lib/</classpathPrefix>
<mainClass>org.coursedesign2.VPriceTrendAnalysis</mainClass>
</manifest>
<manifestEntries>
<Class-Path>.</Class-Path>
</manifestEntries>
</archive>
<excludes>
<exclude>META-INF/*.SF</exclude>
<exclude>META-INF/*.DSA</exclude>
<exclude>META-INF/*.RSA</exclude>
</excludes>
</configuration>
</plugin>
</plugins>
</build>
<properties>
<maven.compiler.source>9</maven.compiler.source>
<maven.compiler.target>9</maven.compiler.target>
</properties>
</project>
- 可视化的部分我选择的是java的jfree类库,我觉得也可以使用Python绘图(题目里也没有指定)
代码部分
目录结构
问题一:
主程序入口类
package org.coursedesign1;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class VegetablePriceAnalysis {
public static void main(String[] args) throws Exception {
// 创建 Hadoop 配置对象
Configuration conf = new Configuration();
// 获取 Job 实例
Job job = Job.getInstance(conf, "VegetablePriceAnalysis");
// 设置作业的 JAR 文件,这里使用当前类作为 JAR 文件的引用
job.setJarByClass(VegetablePriceAnalysis.class);
// 设置 Mapper 类
job.setMapperClass(VegetablePriceMapper.class);
// 设置 Reducer 类
job.setReducerClass(VegetablePriceReducer.class);
// 设置作业输出的键和值的类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
// 硬编码作业的输入路径
FileInputFormat.setInputPaths(job, new Path("D:\\idea-workspace\\HadoopPracticum\\input"));
// 硬编码作业的输出路径
FileOutputFormat.setOutputPath(job, new Path("D:\\idea-workspace\\HadoopPracticum\\output1"));
// 提交作业
job.submit();
// 等待作业完成,并根据作业的成功与否退出程序
boolean completed = job.waitForCompletion(true);
System.exit(completed ? 0 : 1);
}
}
Map类
package org.coursedesign1;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class VegetablePriceMapper extends Mapper<LongWritable, Text, Text, Text> {//输入键和值都是 Text 类型,输出键和值也都是 Text 类型
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split("\\s+");//一个或多个空格作为分隔符来分割字符串,得到数据数组 data
// 跳过标题行(序号为1)
if (key.get() == 1) {
return;
}
//只处理包含"大白菜"或"土豆"的数据行
if(!data[1].equals("大白菜") && !data[1].equals("土豆"))
return;
//数据列从0开始,选取1和89作为键(蔬菜、省城),循环获取的价格作为值
for(int i=2; i<=6; i++){
context.write(new Text(data[1]+" " + data[8]+data[9]),new Text(data[i]));
}
}
}
Reduce类
package org.coursedesign1;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class VegetablePriceReducer extends Reducer<Text, Text, Text, Text> {//输入输出键和值都是Text类型
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for(Text val : values){
sb.append(val.toString());
sb.append(" ");
}
context.write(key, new Text(sb.toString()));
}
}
可视化
package org.showchart;
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartPanel;
import org.jfree.chart.JFreeChart;
import org.jfree.chart.plot.PlotOrientation;
import org.jfree.data.category.DefaultCategoryDataset;
import javax.swing.*;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class VegetablePriceChart extends JFrame {
public VegetablePriceChart() {
super("蔬菜价格图");
DefaultCategoryDataset dataset = new DefaultCategoryDataset();
// 读取数据文件
try (BufferedReader reader = new BufferedReader(new FileReader("D:\\idea-workspace\\HadoopPracticum\\output1\\part-r-00000"))) {
String line;
while ((line = reader.readLine()) != null) {
String[] parts = line.split("\\s+");
String vegetable = parts[0];
String city = parts[1];
for (int i = 2; i < parts.length; i++) {
double price = Double.parseDouble(parts[i]);
String date = "2014年1月" + (i - 1) + "日";
dataset.addValue(price, date, vegetable + " " + city);
}
}
} catch (IOException e) {
e.printStackTrace();
}
// 创建图表
JFreeChart barChart = ChartFactory.createBarChart(
"各地区每一天大白菜、土豆的价格",
"地区",
"价格",
dataset,
PlotOrientation.VERTICAL,
true, true, false);
// 创建图表面板并添加到窗口
ChartPanel chartPanel = new ChartPanel(barChart);
setContentPane(chartPanel);
}
public static void main(String[] args) {
SwingUtilities.invokeLater(() -> {
VegetablePriceChart example = new VegetablePriceChart();
example.setSize(800, 600);
example.setLocationRelativeTo(null);
example.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
example.setVisible(true);
});
}
}
 ](https://imgse.com/i/pkIz3Nj)
](https://imgse.com/i/pkIz3Nj)
问题二:
主程序入口类
package org.coursedesign2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class VPriceTrendAnalysis {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Vegetable Price Trend for Selected City");
job.setJarByClass(VPriceTrendAnalysis.class);
job.setMapperClass(VPriceTrendMapper.class);
job.setReducerClass(VPriceTrendReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:\\idea-workspace\\HadoopPracticum\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\idea-workspace\\HadoopPracticum\\output2"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Map类
package org.coursedesign2;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.*;
import org.apache.hadoop.mapreduce.*;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class VPriceTrendAnalysis {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "Vegetable Price Trend for Selected City");
job.setJarByClass(VPriceTrendAnalysis.class);
job.setMapperClass(VPriceTrendMapper.class);
job.setReducerClass(VPriceTrendReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Text.class);
FileInputFormat.setInputPaths(job, new Path("D:\\idea-workspace\\HadoopPracticum\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\idea-workspace\\HadoopPracticum\\output2"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Reduce类
package org.coursedesign2;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class VPriceTrendReducer extends Reducer<Text, Text, Text,Text> {
public void reduce(Text key, Iterable<Text> values, Context context) throws IOException, InterruptedException {
StringBuilder sb = new StringBuilder();
for(Text val : values){
sb.append(val.toString());
sb.append(" ");
}
context.write(key, new Text(sb.toString()));
}
}
可视化
package org.showchart;
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartPanel;
import org.jfree.chart.JFreeChart;
import org.jfree.chart.plot.PlotOrientation;
import org.jfree.chart.plot.XYPlot;
import org.jfree.chart.renderer.xy.XYLineAndShapeRenderer;
import org.jfree.data.xy.XYSeries;
import org.jfree.data.xy.XYSeriesCollection;
import javax.swing.*;
import java.awt.*;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class VPriceTrendLineChart extends JFrame {
public VPriceTrendLineChart() {
super("蔬菜价格趋势折线图");
XYSeriesCollection dataset = new XYSeriesCollection();
// 读取数据文件
try (BufferedReader reader = new BufferedReader(new FileReader("D:\\idea-workspace\\HadoopPracticum\\output2\\part-r-00000"))) {
String line;
while ((line = reader.readLine()) != null) {
String[] parts = line.split("\\s+");
String vegetable = parts[0];
XYSeries series = new XYSeries(vegetable);
for (int i = 1; i < parts.length; i++) {
double price = Double.parseDouble(parts[i]);
series.add(i, price);
}
dataset.addSeries(series);
}
} catch (IOException e) {
e.printStackTrace();
}
// 创建图表
JFreeChart lineChart = ChartFactory.createXYLineChart(
"山西汾阳蔬菜价格趋势折线图",
"日期",
"价格",
dataset,
PlotOrientation.VERTICAL,
true, true, false);
// 自定义渲染器以显示数据点
XYPlot plot = lineChart.getXYPlot();
XYLineAndShapeRenderer renderer = new XYLineAndShapeRenderer();
for (int i = 0; i < dataset.getSeriesCount(); i++) {
renderer.setSeriesShapesVisible(i, true);
renderer.setSeriesShapesFilled(i, true);
}
plot.setRenderer(renderer);
// 设置日期轴标签
plot.getDomainAxis().setLabel("日期");
plot.getDomainAxis().setTickLabelsVisible(true);
plot.getDomainAxis().setTickLabelFont(new Font("SansSerif", Font.PLAIN, 12));
plot.getDomainAxis().setTickLabelPaint(Color.BLACK);
// 设置价格轴标签
plot.getRangeAxis().setLabel("价格");
plot.getRangeAxis().setTickLabelsVisible(true);
plot.getRangeAxis().setTickLabelFont(new Font("SansSerif", Font.PLAIN, 12));
plot.getRangeAxis().setTickLabelPaint(Color.BLACK);
// 创建图表面板并添加到窗口
ChartPanel chartPanel = new ChartPanel(lineChart);
setContentPane(chartPanel);
}
public static void main(String[] args) {
SwingUtilities.invokeLater(() -> {
VPriceTrendLineChart example = new VPriceTrendLineChart();
example.setSize(800, 600);
example.setLocationRelativeTo(null);
example.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
example.setVisible(true);
});
}
}
问题三:
主程序入口类
package org.coursedesign3;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class VegetableMaxpStatistics {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
Job job = new Job(conf, "Vegetable Highest Price");
job.setJarByClass(VegetableMaxpStatistics.class);
job.setMapperClass(VegetableMaxpMapper.class);
job.setReducerClass(VegetableMaxpReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(Date_City_Price.class);
FileInputFormat.setInputPaths(job, new Path("D:\\idea-workspace\\HadoopPracticum\\input"));
FileOutputFormat.setOutputPath(job, new Path("D:\\idea-workspace\\HadoopPracticum\\output3"));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
}
Map类
package org.coursedesign3;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class VegetableMaxpMapper extends Mapper<LongWritable, Text, Text, Date_City_Price> {
private String[] dates;
private String marketName;
private String province;
private String city;
@Override
protected void setup(Context context) throws IOException, InterruptedException {
// 读取日期行,假设第一行是标题行,第二行是日期行
Text value = new Text("2014年1月1日\t2014年1月2日\t2014年1月3日\t2014年1月4日\t2014年1月5日");
String[] headerData = value.toString().split("\t");
dates = new String[headerData.length];
System.arraycopy(headerData, 0, dates, 0, headerData.length);
}
public void map(LongWritable key, Text value, Context context) throws IOException, InterruptedException {
String line = value.toString();
String[] data = line.split("\\s+");
// 跳过标题行(序号为1)
if (key.get() == 1) {
return;
}
// 读取批发市场名称、省份和城市信息
marketName = data[7];
province = data[8];
city = data[9];
// 第1列是蔬菜名称
String vegetableName = data[1];
// 第2到第6列是价格数据
for (int i = 2; i <= 6; i++) {
// String priceStr = data[i].trim();
String priceStr = data[i];
if (!priceStr.isEmpty()) {
try {
float price = Float.parseFloat(priceStr);
// 构造键为蔬菜名称、日期、批发市场名称、省份和城市的组合
// Text outKey = new Text(vegetableName + "\t" + dates[i-2] + "\t" + marketName + "\t" + province + "\t" + city);
Text outKey = new Text(vegetableName);
Date_City_Price outValue = new Date_City_Price(dates[i-2],province+city,price);
context.write(outKey, outValue);
} catch (NumberFormatException nfe) {
System.err.println("Error parsing price for " + vegetableName + ": " + priceStr);
}
}
}
}
}
自定义类
package org.coursedesign3;
import org.apache.hadoop.io.WritableComparable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
public class Date_City_Price implements WritableComparable<Date_City_Price> {
// 存储日期,城市,价格
String date;
String city;
float price;
public Date_City_Price(String date, String city, float price) {
this.date = date;
this.city = city;
this.price = price;
}
public Date_City_Price() {
this.date = "";
this.city = "";
this.price = 0.0f;
}
@Override
public int compareTo(Date_City_Price o) {
return Float.compare(price,o.price);
}
@Override
public void write(DataOutput dataOutput) throws IOException {
dataOutput.writeUTF(date);
dataOutput.writeUTF(city);
dataOutput.writeUTF(String.valueOf(price));
}
@Override
public void readFields(DataInput dataInput) throws IOException {
date = dataInput.readUTF();
city = dataInput.readUTF();
price = Float.parseFloat(dataInput.readUTF());
}
public String getMes(){
return date + " " + city + " " + price;
}
}
Reduce类
package org.coursedesign3;
import org.apache.hadoop.io.FloatWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
public class VegetableMaxpReducer extends Reducer<Text, Date_City_Price, Text, Text> {
private Text maxKey = new Text();
private FloatWritable maxValue = new FloatWritable();
public void reduce(Text key, Iterable<Date_City_Price> values, Context context) throws IOException, InterruptedException {
float maxPrice = Float.MIN_VALUE;
Date_City_Price temp = null;
for (Date_City_Price val : values) {
if (val.price > maxPrice) {
maxPrice = val.price;
temp = val;
}
}
// 设置键为蔬菜名称和日期,值为最高价格
// maxKey.set(key);
// maxValue.set(maxPrice);
context.write(key, new Text(temp.getMes()));
}
}
可视化
package org.showchart;
import org.jfree.chart.ChartFactory;
import org.jfree.chart.ChartPanel;
import org.jfree.chart.JFreeChart;
import org.jfree.chart.plot.PlotOrientation;
import org.jfree.data.category.DefaultCategoryDataset;
import javax.swing.*;
import java.io.BufferedReader;
import java.io.FileReader;
import java.io.IOException;
public class VegetableMaxpChart extends JFrame {
public VegetableMaxpChart(String title) {
super(title);
// 创建数据集
DefaultCategoryDataset dataset = createDataset();
// 创建柱状图
JFreeChart barChart = ChartFactory.createBarChart(
"每种蔬菜价格最高的地区和日期",
"地区",
"价格",
dataset,
PlotOrientation.VERTICAL,
true, true, false);
// 将图表放入面板
ChartPanel chartPanel = new ChartPanel(barChart);
chartPanel.setPreferredSize(new java.awt.Dimension(800, 600));
setContentPane(chartPanel);
}
private DefaultCategoryDataset createDataset() {
DefaultCategoryDataset dataset = new DefaultCategoryDataset();
try (BufferedReader br = new BufferedReader(new FileReader("D:\\idea-workspace\\HadoopPracticum\\output3\\part-r-00000"))) {
String line;
while ((line = br.readLine()) != null) {
String[] parts = line.split("\\s+");
String vegetable = parts[0];
String date = parts[1];
String city = parts[2];
double price = Double.parseDouble(parts[3]);
dataset.addValue(price, vegetable, city);
}
} catch (IOException e) {
e.printStackTrace();
}
return dataset;
}
public static void main(String[] args) {
SwingUtilities.invokeLater(() -> {
VegetableMaxpChart example = new VegetableMaxpChart("蔬菜价格图");
example.setSize(800, 600);
example.setLocationRelativeTo(null);
example.setDefaultCloseOperation(WindowConstants.EXIT_ON_CLOSE);
example.setVisible(true);
});
}
}
特别说明:问题三的情况比较特殊,Map到Reduce阶段要同时携带多种数据项,不能丢失信息,但也不可全作为键,因此更改了值的类型,自定义Date_City_Price类作为outValue的类型
打包Jar包
有很多种方式,我选取了最直观的一种,也是搜索一下就可以模仿操作了
构建 --> 构建工件 --> 选择jar包 --> 构建
Hadoop启动
启动命令行窗口 输入命令start-all.cmd
成功后会出现四个窗口namen,datanode,namemanager和resourcemanager
输入jps查看当前进程
问题处理
已解决
-
数据的分割格式一定要自己查看,多个空格和一个tab识别的是不一样的
-
log4j.properties日志报错
在resources目录下创建一个 log4j.properties的文件,在里面写如下内容即可解决
log4j.rootLogger=INFO, stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d %p [%c] - %m%n
log4j.appender.logfile=org.apache.log4j.FileAppender
log4j.appender.logfile.File=target/spring.log
log4j.appender.logfile.layout=org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern=%d %p [%c] - %m%n
- 刚启动hadoop一堆节点什么的时候,不要马上运行代码,因为刚开启的时候默认打开了安全模式,过一会就自动关闭了
未解决
- log4j捆绑问题,由于这里面写了三个问题,造成个多个捆绑。网上有解决办法,但是我不想解决了(摆烂)
- 只能使用硬编码路径,不能在类的编辑配置中直接输入路径实参。感觉是我的maven依赖有点问题,导致我的jar包输出每次路径都是固定的,三个问题只能输出一个问题的结果
- 在HDFS上运行的时候,由于jar包存在Kerberos认证、授权以及加密传输的特点,出现了签名验证失败,导致我只能禁用签名验证(不推荐):作为临时解决方案,但这会降低安全性
如有解决办法可在评论区讨论交流;博主也是自学的,如有错误请批评指正~
求源码、可视化图片、实验报告、ppt请私聊(其实源码也该给的都给了)















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









