







观察数据
这个项目给的数据是txt格式,没有列名,视频中介绍依次是用户ID、消费时间、购买数量、消费总金额
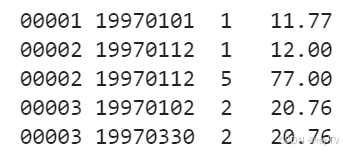
数据处理
一.导入需要的库
这里新增的是datetime用来转换数据类型,style.use更改绘图风格
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from datetime import datetime
plt.rcParams['font.sans-serif'] = 'SimHei'
%matplotlib inline
plt.style.use('ggplot') # 更改绘图风格二.导入数据
txt文件用read_table函数导入,而且由于没有列名,自己定义,分别是user_id、order_dt、order_products、order_amount
观察数据会发现第一列与第二列间有一个空格,第二列与第三列间有两个空格,第三列与第四列间有三个空格,所以分隔符sep是\s,+代表任意个\s
# 导入数据,这里是txt文件,而且没有首行
columns = ['user_id','order_dt','order_products','order_amount']
df = pd.read_table('CDNOW_master.txt',names=columns,sep='\s+') # sep='\s+'代表匹配任意个空格
df.head()
# 通过观察前五行能发现:
# 1.order_dt代表时间,后续需要修改格式,日期格式需转换
# 2.存在一个用户一天购买多次行为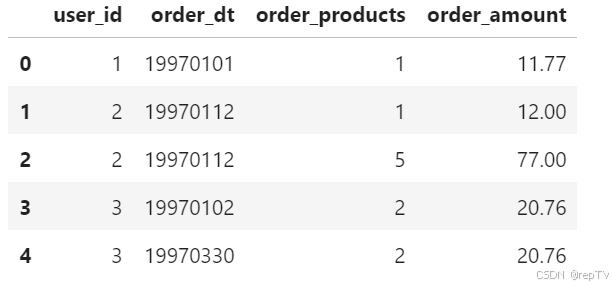
三.数据预处理
df.describe()
# 结论:
# 1.用户平均每笔订单买2.4个商品,标准差为2.3,波动正常,75%分位时为3,也就是绝大多数每单购买量在2-3单
# 2.购买金额看出大部分消费金额在中小额,30-45左右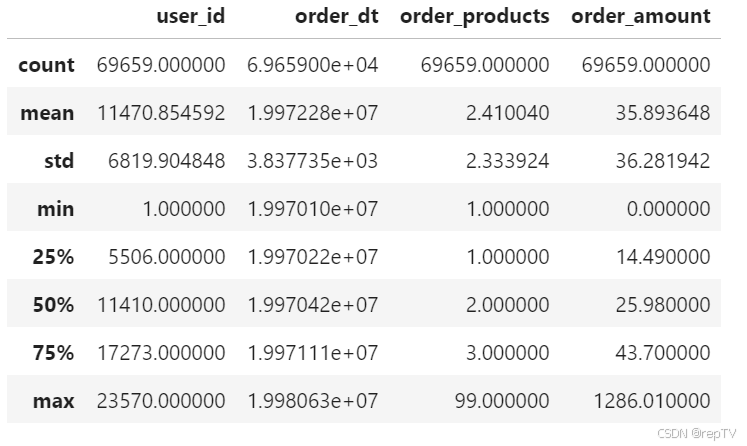
df.info()
# 可以看出数据比较干净,没有空值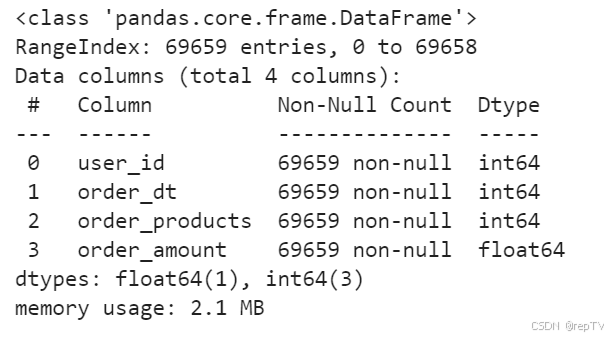
由上图可以看出日期列是int类型,所以要进行转化,format是告诉to_datetime函数要处理的数据是什么样的,在此基础上又新增了一列将日期精度转化为月(即每个月不论是几号都转化成当月1号)【为什么不能直接取出月份呢?因为这里有97年和98年的数据,只取月份会不知道是哪一年的,这样转化最好】
# 数据预处理
# 转换日期类型
df['order_date'] = pd.to_datetime(df['order_dt'],format='%Y%m%d')
# format参数:按照指定的格式去匹配要转换的数据列
# %Y:四位数的年份1989 %m:两位数的月份08 %d两位数的天数13
# %y:两位数的年份89 %h:两位数的小时13 %M:两位数的分钟13 %s:两位数的秒13
# 将order_date转化为精度为月的数据列,这里的作用后续会讲到
df['month'] = df['order_date'].astype('datetime64[M]') # [M]:控制转化后的精度
df.head()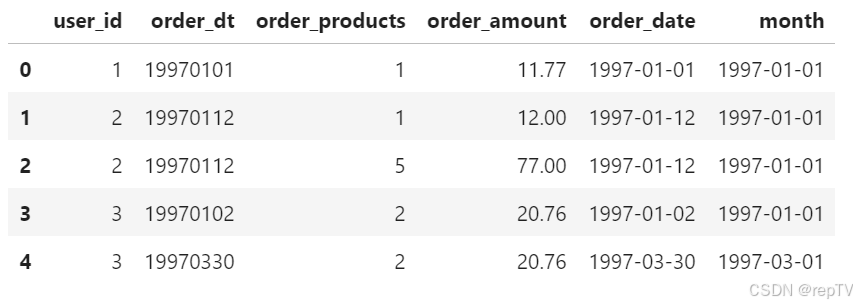
用户整体消费趋势分析(按月份)
整体消费趋势分析就是按月份分组,购买数量和消费金额简单sum求和就行,消费次数用count函数计数,一行数据代表一次消费。
消费人数这里先对user_id应用apply进行去重,这时是一个series对象,直接求长度就是消费人数了
# 用户整体消费趋势分析(按月份)
# 按月份统计产品购买数量、消费金额、消费次数、消费人数
# 这里画四个子图
plt.figure(figsize=(20,15)) # 单位为英寸
# 每月购买数量
plt.subplot(221)
df.groupby('month')['order_products'].sum().plot() # 默认折线图
# 消费金额
plt.subplot(222)
df.groupby('month')['order_amount'].sum().plot()
# 消费次数
plt.subplot(223)
df.groupby('month')['user_id'].count().plot()
# 消费人数(对user_id进行去重,这时是一个series对象,所以len就是个数)
plt.subplot(224)
df.groupby('month')['user_id'].apply(lambda x:len(x.drop_duplicates())).plot()
# 分析结果:
# 1.图一看出,97年前三个月销量很高,后销量稳定,呈现稍微下降趋势
# 2.图二看出,97年前三个月消费金额很高,后较稳定,稍微呈现下降趋势,原因:1.可能公司加大营销力度2.跟月份有关,春节前后,但是98年又没什么变化,可能不是
# 3.图三,前三月10000左右,后续2500左右
# 4.图四,前三月人数在8000-10000左右,后续2000左右
# 总结:所有数据显示,97年前三月数据异常,后续常态化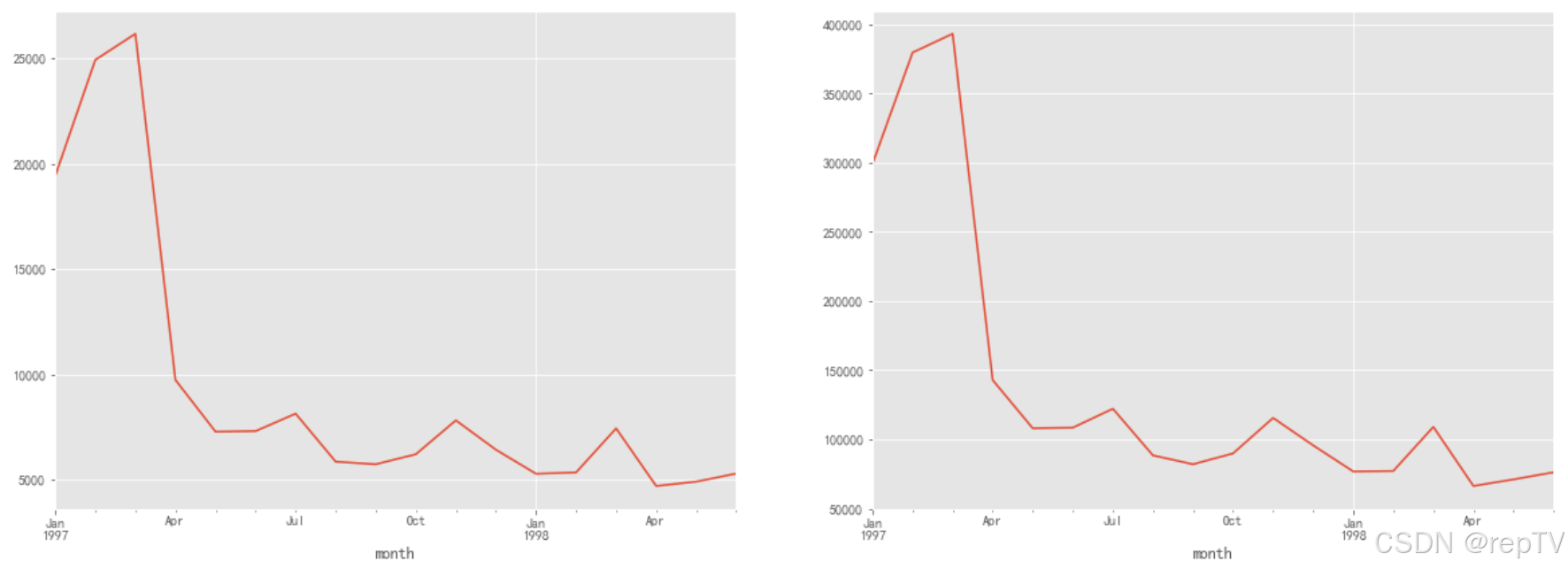
用户个体消费分析
一.用户消费金额、产品数量描述统计
消费金额和购买的产品数量都是sum求和计算,可以放在一起做,根据user_id分组,求出每个用户的数据
# 1.用户消费金额、消费次数(产品数量)描述统计
user_group = df.groupby('user_id').sum()
user_group.describe()
# 从表中看出每个用户平均买7个商品,但是75%分位数为7,说明剩下25%的用户一定买的远远大于7个,才将平均值拉到7
# 从表中看出每个用户平均消费金额为106,同样75%分位数才是106,平均值大于中位数,属于右偏严重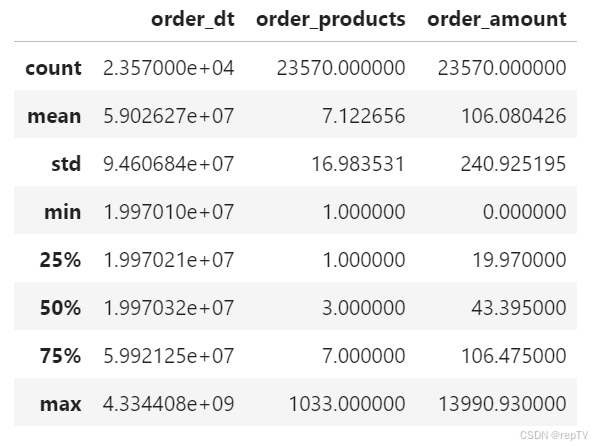
这里画散点图,指定哪个是x轴,哪个是y轴
# 绘制每个用户产品购买数量和消费金额散点图
user_group.plot(kind= 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









