







'''爬厦门大学招生标题和日期'''
import requests
from lxml import etree
import pandas as pd
def download(url):
'''
下载页面
Parameters
----------
url : str
要下载的页面对应的url
Returns
-------
html_text : str
可阅读的html文本
'''
response = requests.get(url)
response.encoding = response.apparent_encoding
return response.text
def parse_page(html_text):
'''
解析HTML代码,提取学术报告的标题
Parameters
----------
html_text : str
中文无乱码的HTML代码
Returns
-------
df : str
返回数据框包含学术报告的标题和日期
'''
selector = etree.HTML(html_text)
titles = selector.xpath("//div[@class='news-item-title']/a/text()")
dates = selector.xpath("//div[@class='news-item-date']/text()")
data = []
for title, date in zip(titles, dates):
data.append({"标题": title, "日期": date})
return data
# 初始URL
base_url = "https://zs.xmu.edu.cn/sss.htm"
# 存储所有数据的列表
all_data = []
# 获取总页数
html_text = download(base_url)
selector = etree.HTML(html_text)
element_list=selector.xpath("//span[@class='p_pages']/span/a/text()")
page_numbers=int(element_list[-3])
# 爬取首页,并存入数据
first_page_data = parse_page(html_text)
all_data.extend(first_page_data)
for page in range(page_numbers, 0, -1): # 逆序循环
url = f"https://zs.xmu.edu.cn/sss/{page}.htm" # 更新URL构造方式
html_text = download(url)
page_data = parse_page(html_text)
print(f"已爬取第 {page} 页")
all_data.extend(page_data)
# 将数据存储为DataFrame
df = pd.DataFrame(all_data)
# 存储为Excel文件
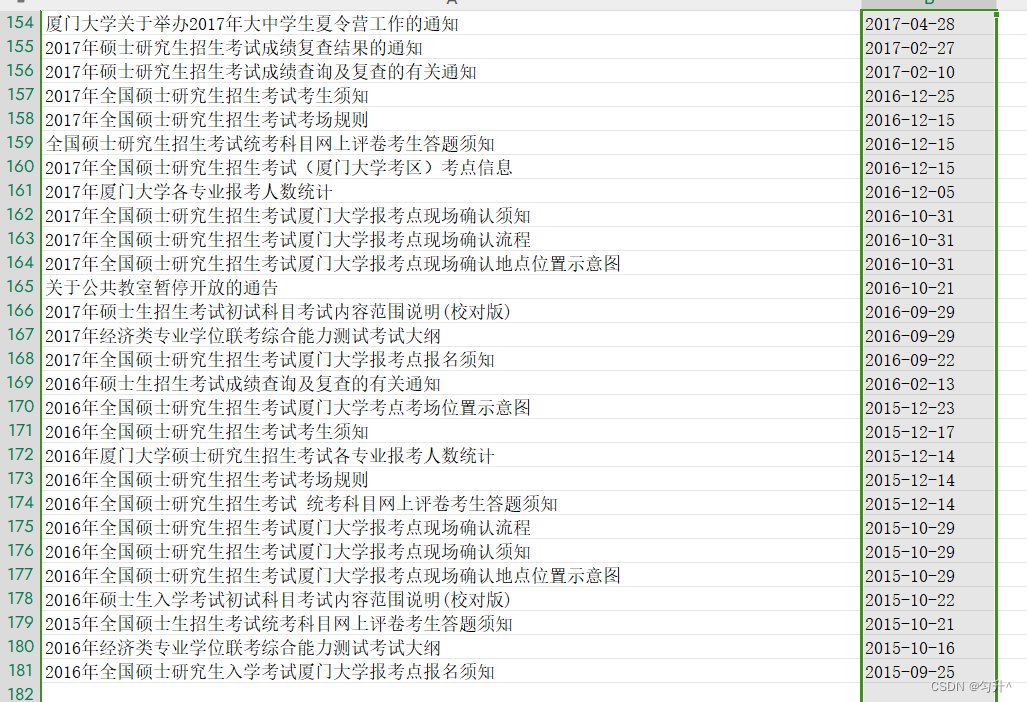
df.to_excel('爬取厦大研究生的页面.xlsx', index=False)爬取时注意观察不同页码的url所对应的page值,最终结果如图所示(第一页和最后一页)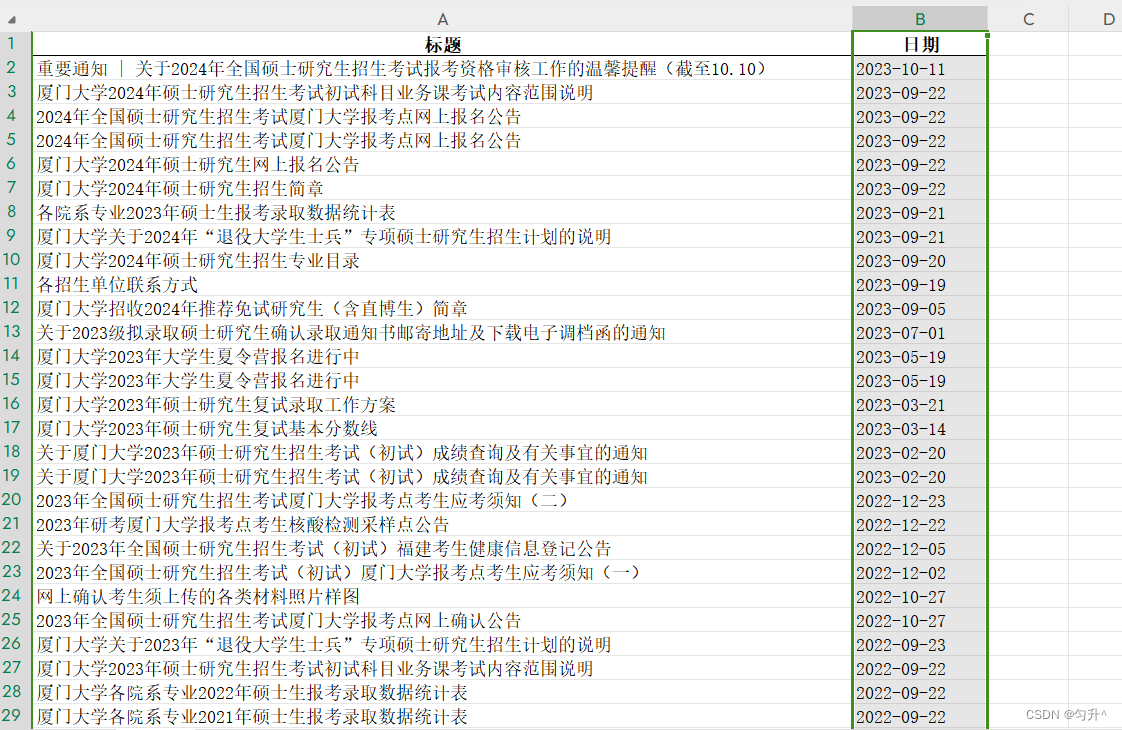


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









