






由于研究需要获取全国范围的火车站,因此想记录一下获取数据的过程。
获取思路
一开始我的想法是直接从高德地图poi搜索直接获取到经纬度然后将其转化坐标即可,但这里有几个不太现实的地方
- 高德对于poi查询有限额,每天仅提供100次服务
- 关键字查询会把返回过于冗余的结果,给后期清理数据带来很大麻烦,比如查询北京站,会返回有北京站出站口,进站口,停车场等等这些其他交通设施的信息、
- 把一些废弃或者停运车站也作为结果返回。以桂林市为例,桂林南站,桂林东站
因此,最后想要获取可靠信源的车站只能从12306获取,并且最后对车站名进行地理编码获取经纬度
过程与代码
12306的有关API接口虽然官方没给出,但在网上相关资料都给出了参考,都很容易获取。甚至在你可以在官网按下F12直接获取这些信息


这里格式都很标准我们直接爬取下来即可
import requests
import re
import csv
url = "https://www.12306.cn/index/script/core/common/station_name_new_v10079.js"
response = requests.get(url)
content = response.text
match = re.search(r"var station_names ='(.*?)';", content, re.DOTALL)
if match:
station_data = match.group(1)
stations = station_data.split('@')[1:]
csv_data = []
for station in stations:
parts = station.strip().split('|')
if len(parts) >= 8:
zh_name = parts[1] + "站"
pinyin = parts[4]
tele_code = parts[2]
station_code = parts[6]
bureau = parts[7]
city = parts[3]
csv_data.append([zh_name, pinyin, tele_code, station_code, bureau, city])
with open('china_railway_stations.csv', 'w', encoding='utf-8-sig', newline='') as f:
writer = csv.writer(f)
writer.writerow(['车站名', '拼音', '电报码', '车站代码', '所属铁路局', '所在城市'])
writer.writerows(csv_data)
print("已成功导出为 china_railway_stations.csv")
else:
print("无法找到车站数据")
接着我们需要对数据进行地理编码服务
import requests
import pandas as pd
from tqdm import tqdm
import os
import time
from urllib.parse import quote
API_KEY = ''
QPS = 3
SLEEP_TIME = 1 / QPS
def geocode_station(station_name):
"""
对车站名进行地理编码
:param station_name: 车站名称
:return: 经度,纬度 或 None,None
"""
# 对站名进行URL编码
encoded_station = quote(station_name)
url = f'https://restapi.amap.com/v3/geocode/geo?key={API_KEY}&address={encoded_station}'
try:
response = requests.get(url, timeout=10) # 添加超时设置
response.raise_for_status() # 检查请求是否成功
data = response.json()
if data['status'] == '1' and int(data['count']) > 0:
location = data['geocodes'][0]['location']
return location.split(',')
else:
print(f"未找到站点 {station_name} 的位置信息")
return None, None
except requests.exceptions.RequestException as e:
print(f"请求失败: {station_name}, 错误: {e}")
return None, None
except (KeyError, ValueError, IndexError) as e:
print(f"解析数据失败: {station_name}, 错误: {e}")
return None, None
def main():
stations = pd.read_csv('china_railway_stations.csv')
# 添加经纬度列(如果不存在)
if 'lon' not in stations.columns:
stations['lon'] = None
if 'lat' not in stations.columns:
stations['lat'] = None
output_file = 'stations_with_coord.csv'
start_index = 0
if os.path.exists(output_file):
processed_data = pd.read_csv(output_file)
start_index = len(processed_data[processed_data['lon'].notna()])
if start_index > 0:
stations.iloc[:start_index, stations.columns.get_loc('lon')] = processed_data['lon'][:start_index]
stations.iloc[:start_index, stations.columns.get_loc('lat')] = processed_data['lat'][:start_index]
last_time = time.time()
for i, row in tqdm(stations.iterrows(), total=len(stations), initial=start_index, desc="地理编码中"):
if i < start_index:
continue
current_time = time.time()
elapsed = current_time - last_time
if elapsed < SLEEP_TIME:
time.sleep(SLEEP_TIME - elapsed)
last_time = time.time()
# 使用带“站”字的车站名调用高德API
lon, lat = geocode_station(row['车站名'])
stations.at[i, 'lon'] = lon
stations.at[i, 'lat'] = lat
stations.to_csv(output_file, index=False)
print("地理编码已完成,并已保存至 stations_with_coord.csv")
def retry_failed_stations():
"""
重试处理未成功编码的站点
"""
output_file = 'stations_with_coord.csv'
# 读取现有数据
if not os.path.exists(output_file):
print("找不到已处理的数据文件")
return
stations = pd.read_csv(output_file)
# 找出经纬度为空的站点
failed_stations = stations[stations['lon'].isna() | stations['lat'].isna()]
if len(failed_stations) == 0:
print("没有发现编码失败的站点")
return
print(f"发现 {len(failed_stations)} 个编码失败的站点,开始重试...")
# 记录开始时间
last_time = time.time()
# 对失败的站点进行重试
for i, row in tqdm(failed_stations.iterrows(), total=len(failed_stations), desc="重试编码中"):
# 控制 QPS
current_time = time.time()
elapsed = current_time - last_time
if elapsed < SLEEP_TIME:
time.sleep(SLEEP_TIME - elapsed)
last_time = time.time()
# 尝试重新编码
lon, lat = geocode_station(row['车站名'])
if lon is not None and lat is not None:
stations.at[i, 'lon'] = lon
stations.at[i, 'lat'] = lat
# 每成功处理一个站点就保存一次
stations.to_csv(output_file, index=False)
# 统计处理结果
remaining_failed = stations[stations['lon'].isna() | stations['lat'].isna()]
print(f"重试完成!")
print(f"成功补充编码: {len(failed_stations) - len(remaining_failed)} 个站点")
if len(remaining_failed) > 0:
print(f"仍有 {len(remaining_failed)} 个站点未能成功编码:")
for _, row in remaining_failed.iterrows():
print(f"- {row['车站名']}")
if __name__ == '__main__':
# 如果是第一次运行,执行完整的编码过程
if not os.path.exists('stations_with_coord.csv'):
main()
# 否则只重试失败的站点
retry_failed_stations()
至此成功获取获取到全国范围内车站经纬度信息。根据自己需要进一步转化为84坐标系,但在这里就不再过多赘述。
后续
尽管已经成功获取到全国车站的信息了,但是这里的结果没有办法区分到这些车站是否还能在运营。
因此我想到是不是通过查询车站大屏是否为空判断是否还在运营,但是显然没有这个接口的信息。经过一番查找,我发现可以使用车站的车票开售时间来判断,刚好很容易获取
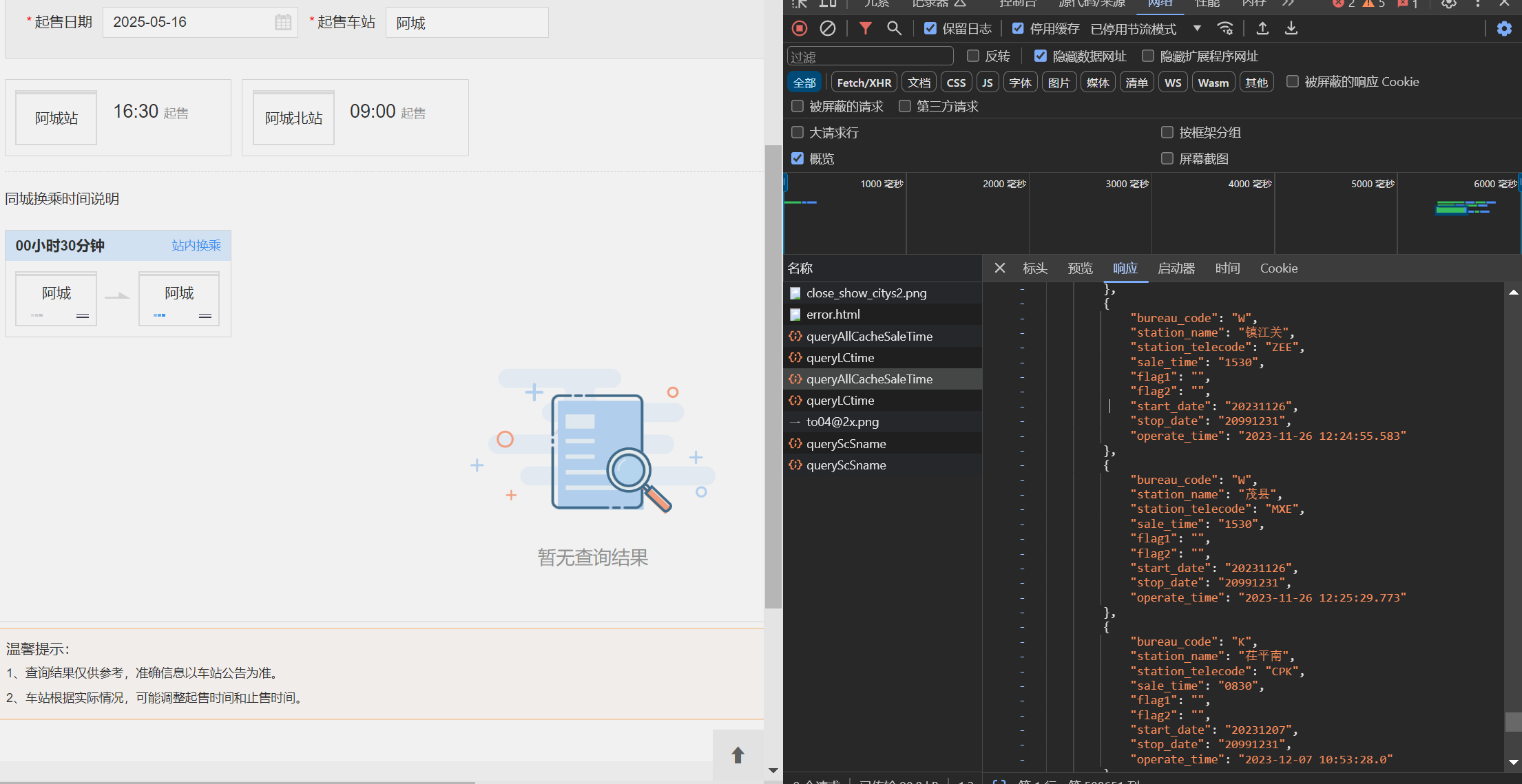
其中这里"sale_time": "1630"便是开售时间。
当然这里作为辅助判断,也只能判断是客运的火车站,对于货运,和客货混用的也无法判断。
示例代码如下
import json
import csv
from tqdm import tqdm
import os
def merge_sale_time(json_path, csv_path, output_path, checkpoint_file='checkpoint.txt'):
"""
将JSON文件中的sale_time字段合并到CSV文件中
参数:
json_path: JSON文件路径
csv_path: 原始CSV文件路径
output_path: 输出CSV文件路径
checkpoint_file: 检查点文件路径
"""
# 读取检查点
last_processed = 0
if os.path.exists(checkpoint_file):
with open(checkpoint_file, 'r') as f:
last_processed = int(f.read().strip())
# 读取JSON数据
with open(json_path, 'r', encoding='utf-8') as f:
json_data = json.load(f)
# 创建车站名到sale_time的映射
station_sale_time = {}
for item in json_data.get('data', []):
station_name = item.get('station_name', '') + '站'
sale_time = item.get('sale_time', '')
station_sale_time[station_name] = sale_time
# 处理CSV文件
with open(csv_path, 'r', encoding='utf-8') as infile, \
open(output_path, 'w', encoding='utf-8', newline='') as outfile:
reader = csv.reader(infile)
writer = csv.writer(outfile)
# 读取并写入表头
headers = next(reader)
headers.append('起售时间') # 添加新字段
writer.writerow(headers)
# 处理数据行
rows = list(reader)
for i in tqdm(range(len(rows)), desc='处理进度'):
if i < last_processed:
continue
row = rows[i]
station_name = row[0] # 假设车站名在第一列
sale_time = station_sale_time.get(station_name, '')
row.append(sale_time)
writer.writerow(row)
# 更新检查点
with open(checkpoint_file, 'w') as f:
f.write(str(i))
print(f"处理完成,结果已保存到: {output_path}")
if __name__ == '__main__':
# 文件路径
json_file = 'information.json'
csv_file = 'china_railway_stations.csv'
output_file = 'china_railway_stations_with_saletime.csv'
merge_sale_time(json_file, csv_file, output_file)
总结
磕磕绊绊终于搞完了,但是这里还是没有办法区分车站等级以及更多信息。欢迎大家讨论交流。

















 6万+
6万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









