







 本文详述了一次爬取并分析亚马逊自营广告的实践,涵盖了搜索结果页面和产品页面的爬虫实现,以及对广告出现频率、位置和质量的分析。爬虫涉及了多种模块和推荐算法,分析结果显示,自营广告在搜索结果页面上的出现概率高,且网格型页面广告更多。同时,推荐产品在价格和会员产品占比上优于主产品。
本文详述了一次爬取并分析亚马逊自营广告的实践,涵盖了搜索结果页面和产品页面的爬虫实现,以及对广告出现频率、位置和质量的分析。爬虫涉及了多种模块和推荐算法,分析结果显示,自营广告在搜索结果页面上的出现概率高,且网格型页面广告更多。同时,推荐产品在价格和会员产品占比上优于主产品。
写在前面
因为包含了完整的代码,不小心变成了超级长文。主要目的是整理一下自己的工作,大家如果有缘看到且尚有兴趣,请根据目录各取所需。未经允许,请勿转载。
背景
自营广告 (first party advertising / promoted listing / sponsored listing)是电商平台最常见的盈利方式之一。电商平台上的卖家通过参加自营广告,支付一定的广告费用,可以使他们的产品获得更多流量,更好的曝光位置,从而获得更高的转化率。
根据法务要求,自营广告会伴随着很明显的Sponsored/ Ads 等广告字样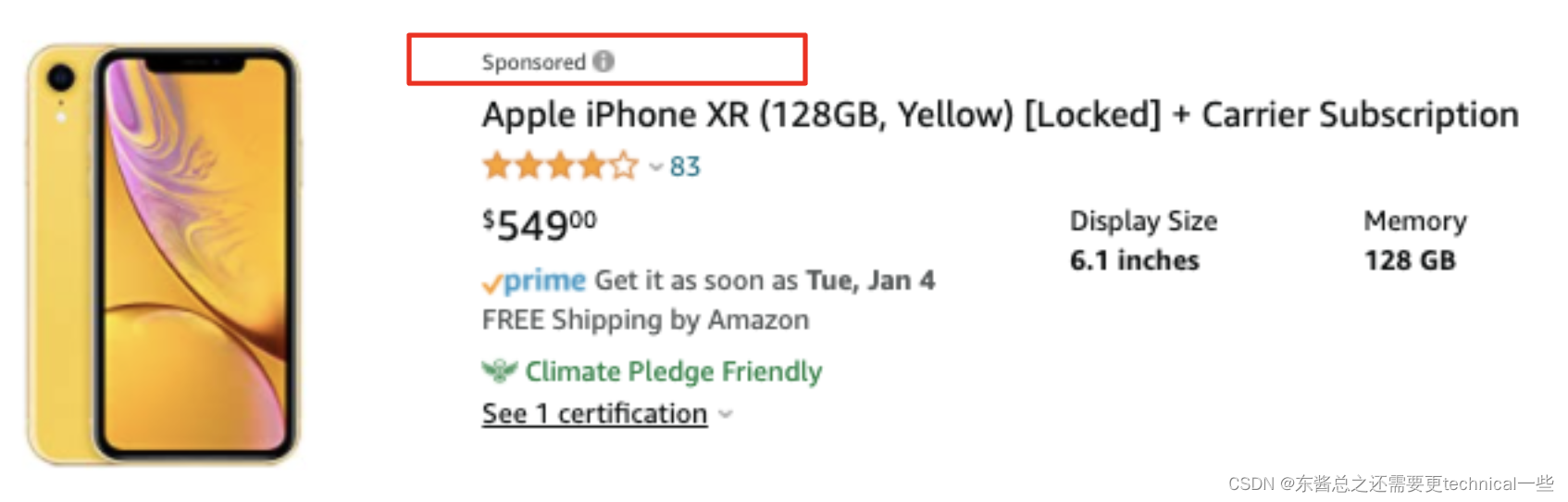
自营广告可以显著提升电商平台的利润,但过多的自营广告又会导致用户体验和转换率的下降。通过调整广告的呈现形式/位置(UI design/position),密度(density)和质量(quality)来达到一个最佳的平衡点是所有电商平台都在不停测试和追求的。
自营广告最常出现的位置有两个:搜索结果页面(SRP: Search Result Page)和产品页面(VIP: View Item Page)。在本次分析中,我们通过爬取亚马逊在这两个页面上所有的广告模块,可以了解到作为在北美拥有绝对主导地位的电商平台,亚马逊现在的自营广告密度,质量以及表现形式。他山之石,可以攻玉。
爬虫介绍及代码
爬虫环境:PC端,Chrome浏览器,隐身模式(Incognito Mode)
爬取内容:
- 搜索结果页面 (1k):十个不同品类,每个品类前一百热门搜索关键词
- 产品页面 (1k):来自上述一千个搜索结果页面,每个页面上排序第一的产品
搜索结果页面 (Search Result Page) 爬取
简介
爬虫的第一步是选取几个样本,直观的了解亚马逊网站的基本格式与对应html code之间的关系。亚马逊的搜索结果页面包含了两部分内容:主搜索结果和与搜索相关的定制化模块。
主搜索结果
主搜索结果每次都会出现(Surface Rate = 100%),分为两种主要类型:列表型(List View,每行一个产品,22个每页)和网格型(Grid View,每行四个产品,60个/15行每页)。因为这两种对应了完全不同的界面(UI),在爬虫过程中,我们可以通过每页的产品个数将这两种类型区分开,以便于后续分析。
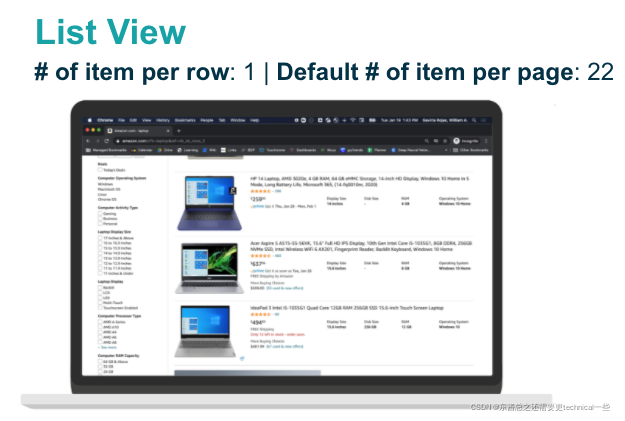
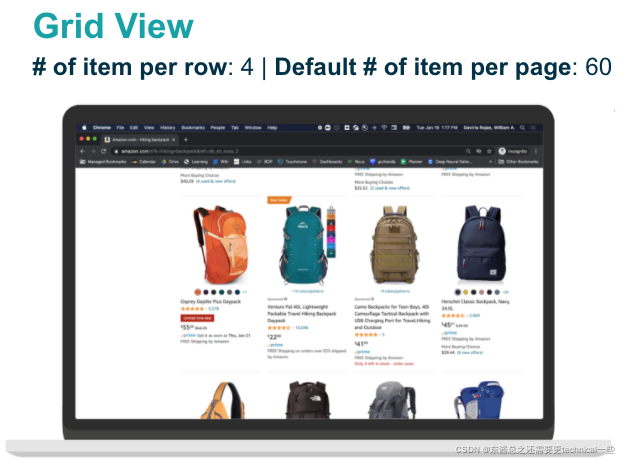
与搜索相关的定制化模块
在100%出现的主搜索结果之外,亚马逊还会基于不同的关键词类型、品类、产品特性,显示不同的定制化模块。这些模块不是每次都会出现,所以需要多看一些样本。基于样本分析,最常出现的模块有以下几种:
- 品牌推广(Sponsored Brand, widget_name: CARDS)
- 产品光谱(Spectrum of Value, widget_name: VISUAL_NAVIGATION)
- 特色产品(Featured Listings, widget_name: FEATURED_ASIN_LIST)
- 视频推广(Sponsored Video, widget_name: VIDEO_SINGLE_PRODUCT)
- 亚马逊之选(Amazon’s Choice, widget_name: TAB_NAVIGATION)
- 主编推荐(Editorial Recommendation, widget_name: SHOPPING_ADVISER)
在后台html code中,每一个模块都对应着一个Widget(窗口小模块),所以我们可以通过Widget_name清楚的区分这些模块。但由于每个模块呈现的产品的个数/格式略有不同,我们需要为它们创建不同的爬虫模版(template),才能顺利爬取所有需要的信息。
爬虫公式 (scraping_functions)
- Import necessary modules
import time
import regex as re
import json
from bs4 import BeautifulSoup
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
- Driver configuration. 需要先下载Chrome Driver: https://chromedriver.chromium.org/downloads
def configure_driver():
# Add additional Options to the webdriver
chrome_options = Options()
# add the argument and make the browser Headless.
chrome_options.add_argument("--headless")
chrome_options.add_argument("--incognito")
# Instantiate the Webdriver: Mention the executable path of the webdriver you have downloaded
# For linux/Mac
driver = webdriver.Chrome(
'/Users/xxx/Downloads/chromedriver', options=chrome_options)
return driver
- 基于不同的关键词(search_keyword),生成对应的亚马逊搜索结果页面(“https://www.amazon.com/s?k=" + search_keyword),利用
BeautifulSoup爬取backend html code。
def getCourses(driver, search_keyword):
driver.get("https://www.amazon.com/s?k=" + search_keyword)
# wait for the element to load
try:
time.sleep(2)
except TimeoutException:
print("TimeoutException: Element not found")
return None
with open("/Users/xxx/work/Search/" + search_keyword + ".html", "w") as f:
f.write(driver.page_source)
# Step 2: Create a parse tree of page sources after searching
soup = BeautifulSoup(driver.page_source, "html.parser")
return soup
- 爬取每个Item Card上所有的产品信息:Item_ID, Component_Type, Title, Star_Rating, Rating_Size, Price, Prime_Label, etc.
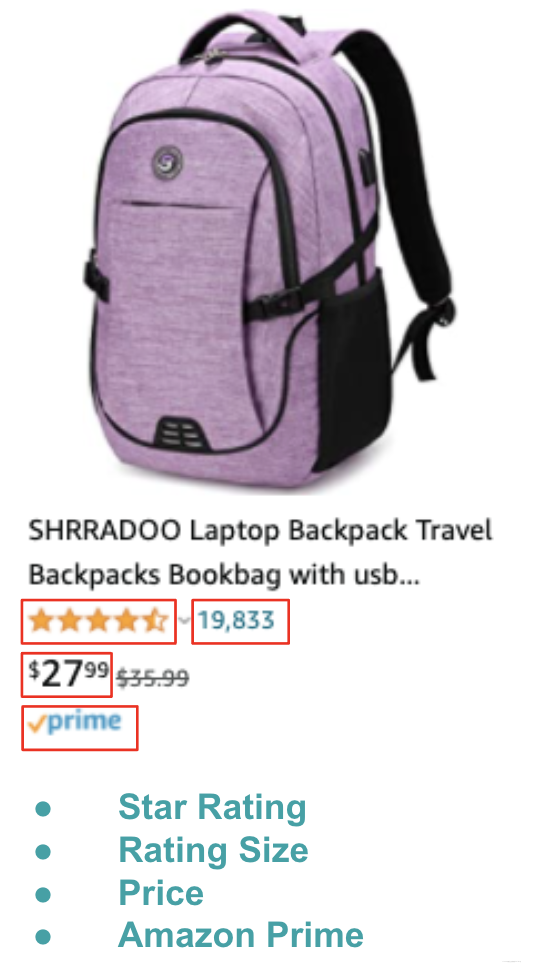
# parsing search results template
def parse_search_results(vn_tag):
try:
item_id_pattern=re.compile('data-asin=(\".*?\")')
item_id=re.findall(item_id_pattern, str(vn_tag))[0]
except (TypeError, AttributeError, IndexError):
item_id = ""
try:
component_type = vn_tag.find_all(
"span", {"class": "s-label-popover-hover"})[0].text.strip()
except IndexError:
component_type = ""
try:
title = vn_tag.find_all('h2')[0].text.strip()
except IndexError:
title = ""
try:
star_rating = vn_tag.find_all('span', {'class': 'a-icon-alt'
})[0].text.strip()
except IndexError:
star_rating = ""
try:
rating_size = vn_tag.find_all(
"div", {"class": "a-row a-size-small"})[0].text.split()[-1]
except IndexError:
rating_size = ""
try:
price = "".join(("$", vn_tag.find_all(
'span', {'class': 'a-price'})[0].text.strip().split("$")[-1]))
except IndexError:
price = ""
try:
prime_label = vn_tag.find_all(
"i", {"class": "a-icon-prime"})[0]['aria-label']
except IndexError:
prime_label = ""
try:
badge = vn_tag.find_all('span', {'class': 'a-size-base s-cpf-badge'
})[0].text.strip()
except IndexError:
badge = ""
try:
product_specs = vn_tag.find_all('div',
{'class': 'sg-row s-product-specs-view'
})[0].text.strip()
except IndexError:
product_specs = ""
try:
more_buying_choice = vn_tag.find_all(
"div", {"class": "a-section a-spacing-none a-spacing-top-mini"})[0].text.strip()
except IndexError:
more_buying_choice = ""
vals = [{
'item_id': item_id,
'component_type': component_type,
'title': title,
'price': price,
'star_rating': star_rating,
'prime_label': prime_label,
'rating_size': rating_size,
'badge': badge,
'more_buying_choice': more_buying_choice,
'product_specs': product_specs,
}]
return vals
- 为品牌推广(Sponsored Brand, widget_name: CARDS),产品光谱(Spectrum of Value, widget_name: VISUAL_NAVIGATION),特色产品(Featured Listings, widget_name: FEATURED_ASIN_LIST),视频推广(Sponsored Video, widget_name: VIDEO_SINGLE_PRODUCT),亚马逊之选(Amazon’s Choice, widget_name: TAB_NAVIGATION),主编推荐(Editorial Recommendation, widget_name: SHOPPING_ADVISER)创建不同的爬虫模版。
# parsing visual navigation template
def parse_visual_navigation(vn_tag):
# aria_label = row.find_all("div",{"class":"s-visual-card-navigation-carousel-title-wrapper"})[0].text.strip()
aria_label = vn_tag.find_all(
"div", {"class": "s-visual-card-navigation-desktop"})[0].findChild("div").text.strip()
corosel_pattern = re.compile('data-a-carousel-options=\'({.*})\'')
carousel_options = re.findall(corosel_pattern, str(vn_tag))[0]
carousel_product_names = ','.join([x for x in [x.text.strip()
for x in vn_tag.find_all('a')] if x])
vals = [{'aria_label': aria_label,
'carousel_options': carousel_options,
'carousel_product_names': carousel_product_names}]
return vals
# parsing cards template
def cards(vn_tag):
carousel_options = {}
try:
aria_label = vn_tag.find_all(
"a", {"aria-hidden": "false"})[0]['aria-label']
except IndexError:
aria_label = ""
try:
carousel_details = []
container = vn_tag.find_all("div", {"data-avar": "desc"})
for i in container:
carousel_details.append(i.text.strip())
except IndexError:
carousel_details = []
vals = [{'aria_label': aria_label,
'carousel_options': carousel_options,
'carousel_product_names': carousel_details}]
return vals
# parsing featured list template
def featured_asins_list(vn_tag):
aria_label = vn_tag.find_all("div", {"class": "a-section"})[0].text.strip()
corosel_pattern = re.compile('data-a-carousel-options=\'({.*})\'')
carousel_options = re.findall(corosel_pattern, str(vn_tag))[0]
carousel_details = []
container = vn_tag.find("ol", {"class": "a-carousel"})
for li in container.find 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2863
2863

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









