






MySQL查询截取分析步骤:
一、开启慢查询日志,捕获慢SQL
二、explain+慢SQL分析
三、show profile查询SQL语句在服务器中的执行细节和生命周期
四、SQL数据库服务器参数调优
一、开启慢查询日志,捕获慢SQL
1、查看慢查询日志是否开启
SHOW VARIABLES LIKE '%slow_query_log%';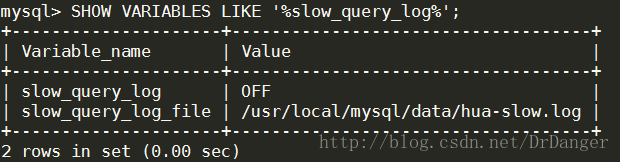
2、开启慢查询日志
SET GLOBAL slow_query_log=1;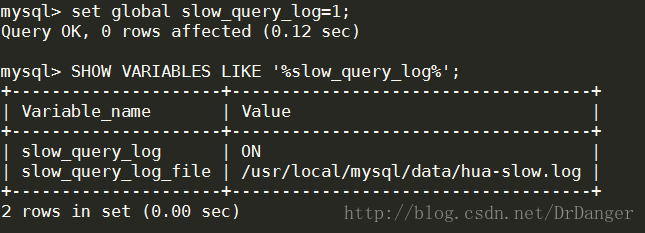
3、查看慢查询日志阙值
SHOW [GLOBAL] VARIABLES LIKE '%long_query_time%';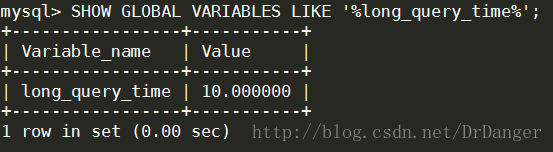
这个值表示超过多长时间的SQL语句会被记录到慢查询日志中
4、设置慢查询日志阙值
SET GLOBAL long_query_time=3;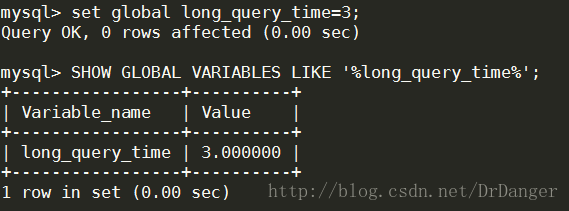
5、查看多少SQL语句超过了阙值
SHOW GLOBAL STATUS LIKE '%Slow_queries%';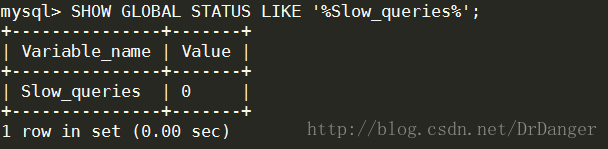
6、MySQL提供的日志分析工具mysqldumpslow
进入MySQL的安装目录中的bin目录下
执行 ./mysqldumpslow --help 查看帮助命令
常用参考:
得到返回记录集最多的10个SQL
mysqldumpslow -s r -t 10 slow.log
得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 slow.log
得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" slow.log
使用这些语句时结合| more使用
mysqldumpslow -s r -t 10 slow.log
得到访问次数最多的10个SQL
mysqldumpslow -s c -t 10 slow.log
得到按照时间排序的前10条里面含有左连接的查询语句
mysqldumpslow -s t -t 10 -g "left join" slow.log
使用这些语句时结合| more使用
二、explain+慢SQL分析
使用EXPLAIN关键字可以模拟优化器执行SQL查询语句,从而知道MySQL是 如何处理你的SQL语句的。分析你的查询语句或是表结构的性能瓶颈。
使用方式:Explain+SQL语句
执行计划包含的信息:
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+------+-------+
1、id
SELECT查询的序列号,包含一组数字,表示查询中执行SELECT语句或操作表的顺序
包含三种情况:
1.id相同,执行顺序由上至下
2.id不同,如果是子查询,id序号会递增,id值越大优先级越高,越先被执行
3.id既有相同的,又有不同的。id如果相同认为是一组,执行顺序由上至下; 在所有组中,id值越大优先级越高,越先执
行。
2、select_type
SIMPLE:简单SELECT查询,查询中不包含子查询或者UNION
PRIMARY:查询中包含任何复杂的子部分,最外层的查询
SUBQUERY:SELECT或WHERE中包含的子查询部分
DERIVED:在FROM中包含的子查询被标记为DERIVER(衍生), MySQL会递归执行这些子查询,把结果放到临时表中
UNION:若第二个SELECT出现UNION,则被标记为UNION, 若UNION包含在FROM子句的子查询中,外层子查询将被标记为DERIVED
UNION RESULT:从UNION表获取结果的SELECT
PRIMARY:查询中包含任何复杂的子部分,最外层的查询
SUBQUERY:SELECT或WHERE中包含的子查询部分
DERIVED:在FROM中包含的子查询被标记为DERIVER(衍生), MySQL会递归执行这些子查询,把结果放到临时表中
UNION:若第二个SELECT出现UNION,则被标记为UNION, 若UNION包含在FROM子句的子查询中,外层子查询将被标记为DERIVED
UNION RESULT:从UNION表获取结果的SELECT
3、table
显示这一行数据是关于哪张表的
4、type
type显示的是访问类型,是较为重要的一个指标,结果值从最好到最坏依次是:
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
system>const>eq_ref>ref>fulltext>ref_or_null>index_merge>unique_subquery>index_subquery>range>index>ALL
一般来说,得保证查询至少达到range级别,最好能达到ref。
system:表只有一行记录(等于系统表),这是const类型的特例,平时不会出现
const:如果通过索引依次就找到了,const用于比较主键索引或者unique索引。 因为只能匹配一行数据,所以很快。如果将主键置于where列表中,MySQL就能将该查询转换为一个常量
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回所有匹配 某个单独值的行,然而它可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where语句中出现between、<、>、in等的查询,这种范围扫描索引比全表扫描要好,因为只需要开始于缩印的某一点,而结束于另一点,不用扫描全部索引
index:Full Index Scan ,index与ALL的区别为index类型只遍历索引树,这通常比ALL快,因为索引文件通常比数据文件小。 (也就是说虽然ALL和index都是读全表, 但index是从索引中读取的,而ALL是从硬盘读取的)
all:Full Table Scan,遍历全表获得匹配的行
eq_ref:唯一性索引扫描,对于每个索引键,表中只有一条记录与之匹配。常见于主键或唯一索引扫描
ref:非唯一性索引扫描,返回匹配某个单独值的所有行。本质上也是一种索引访问,它返回所有匹配 某个单独值的行,然而它可能会找到多个符合条件的行,所以它应该属于查找和扫描的混合体
range:只检索给定范围的行,使用一个索引来选择行。key列显示使用了哪个索引,一般就是在你的where语句中出现between、<、>、in等的查询,这种范围扫描索引比全表扫描要好,因为只需要开始于缩印的某一点,而结束于另一点,不用扫描全部索引
index:Full Index Scan ,index与ALL的区别为index类型只遍历索引树,这通常比ALL快,因为索引文件通常比数据文件小。 (也就是说虽然ALL和index都是读全表, 但index是从索引中读取的,而ALL是从硬盘读取的)
all:Full Table Scan,遍历全表获得匹配的行
5、possible_keys
显示可能应用在这张表中的索引,一个或多个。 查询涉及到的字段上若存在索引,则该索引将被列出,但不一定被查询实际使用
6、key
实际使用的索引。如果为NULL,则没有使用索引。
查询中若出现了覆盖索引,则该索引仅出现在key列表中。
7、key_len
表示索引中使用的字节数,可通过该列计算查询中使用的索引的长度。在不损失精度的情况下,长度越短越好。
key_len显示的值为索引字段的最大可能长度,并非实际使用长度,即key_len是根据表定义计算而得,不是通过表内检索出的。
8、ref
显示索引的哪一列被使用了,哪些列或常量被用于查找索引列上的值。
9、rows
根据表统计信息及索引选用情况,大致估算出找到所需记录多需要读取的行数。
10、Extra
包含不适合在其他列中显示但十分重要的额外信息:
1、Using filesort: 说明MySQL会对数据使用一个外部的索引排序,而不是按照表内的索引顺序进行读取。MySQL中无法利用索引完成的排序操作称为“文件排序”
2、Using temporary: 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by
3、Using index: 表示相应的SELECT操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错。 如果同时出现using where,表明索引被用来执行索引键值的查找; 如果没有同时出现using where,表明索引用来读取数据而非执行查找动作 覆盖索引(Covering Index): 理解方式1:SELECT的数据列只需要从索引中就能读取到,不需要读取数据行,MySQL可以利用索引返回SELECT列表中 的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖 理解方式2:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此他不必读取整个行。 毕竟索引叶子节点存储了他们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了,一个索引 包含了(覆盖)满足查询结果的数据就叫做覆盖索引 注意: 如果要使用覆盖索引,一定要注意SELECT列表中只取出需要的列,不可SELECT *, 因为如果所有字段一起做索引会导致索引文件过大查询性能下降
6、impossible where: WHERE子句的值总是false,不能用来获取任何元组
7、select tables optimized away: 在没有GROUP BY子句的情况下基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作, 不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化
8、distinct: 优化distinct操作,在找到第一匹配的元祖后即停止找同样值的操作
2、Using temporary: 使用了临时表保存中间结果,MySQL在对查询结果排序时使用临时表。常见于排序order by和分组查询group by
3、Using index: 表示相应的SELECT操作中使用了覆盖索引(Covering Index),避免访问了表的数据行,效率不错。 如果同时出现using where,表明索引被用来执行索引键值的查找; 如果没有同时出现using where,表明索引用来读取数据而非执行查找动作 覆盖索引(Covering Index): 理解方式1:SELECT的数据列只需要从索引中就能读取到,不需要读取数据行,MySQL可以利用索引返回SELECT列表中 的字段,而不必根据索引再次读取数据文件,换句话说查询列要被所建的索引覆盖 理解方式2:索引是高效找到行的一个方法,但是一般数据库也能使用索引找到一个列的数据,因此他不必读取整个行。 毕竟索引叶子节点存储了他们索引的数据;当能通过读取索引就可以得到想要的数据,那就不需要读取行了,一个索引 包含了(覆盖)满足查询结果的数据就叫做覆盖索引 注意: 如果要使用覆盖索引,一定要注意SELECT列表中只取出需要的列,不可SELECT *, 因为如果所有字段一起做索引会导致索引文件过大查询性能下降
6、impossible where: WHERE子句的值总是false,不能用来获取任何元组
7、select tables optimized away: 在没有GROUP BY子句的情况下基于索引优化MIN/MAX操作或者对于MyISAM存储引擎优化COUNT(*)操作, 不必等到执行阶段再进行计算,查询执行计划生成的阶段即完成优化
8、distinct: 优化distinct操作,在找到第一匹配的元祖后即停止找同样值的操作
三、show profile查询SQL语句在服务器中的执行细节和生命周期
Show Profile是MySQL提供可以用来分析当前会话中语句执行的资源消耗情况,可以用于SQL的调优测量
默认关闭,并保存最近15次的运行结果
分析步骤
1、查看状态:SHOW VARIABLES LIKE 'profiling';
2、开启:set profiling=on;
3、查看结果:show profiles;
4、诊断SQL:show profile cpu,block io for query 上一步SQL数字号码;
ALL:显示所有开销信息
BLOCK IO:显示IO相关开销
CONTEXT SWITCHES:显示上下文切换相关开销
CPU:显示CPU相关开销
IPC:显示发送接收相关开销
MEMORY:显示内存相关开销
PAGE FAULTS:显示页面错误相关开销
SOURCE:显示和Source_function,Source_file,Source_line相关开销
SWAPS:显示交换次数相关开销
注意(遇到这几种情况要优化)
converting HEAP to MyISAM: 查询结果太大,内存不够用往磁盘上搬
Creating tmp table:创建临时表
Copying to tmp table on disk:把内存中的临时表复制到磁盘
locked
默认关闭,并保存最近15次的运行结果
分析步骤
1、查看状态:SHOW VARIABLES LIKE 'profiling';
2、开启:set profiling=on;
3、查看结果:show profiles;
4、诊断SQL:show profile cpu,block io for query 上一步SQL数字号码;
ALL:显示所有开销信息
BLOCK IO:显示IO相关开销
CONTEXT SWITCHES:显示上下文切换相关开销
CPU:显示CPU相关开销
IPC:显示发送接收相关开销
MEMORY:显示内存相关开销
PAGE FAULTS:显示页面错误相关开销
SOURCE:显示和Source_function,Source_file,Source_line相关开销
SWAPS:显示交换次数相关开销
注意(遇到这几种情况要优化)
converting HEAP to MyISAM: 查询结果太大,内存不够用往磁盘上搬
Creating tmp table:创建临时表
Copying to tmp table on disk:把内存中的临时表复制到磁盘
locked
四、SQL数据库服务器参数调优
当order by 和 group by无法使用索引时,增大max_length_for_sort_data参数设置和增大sort_buffer_size参数的设置

















 7124
7124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









