







一、sql语句执行的过程示意图
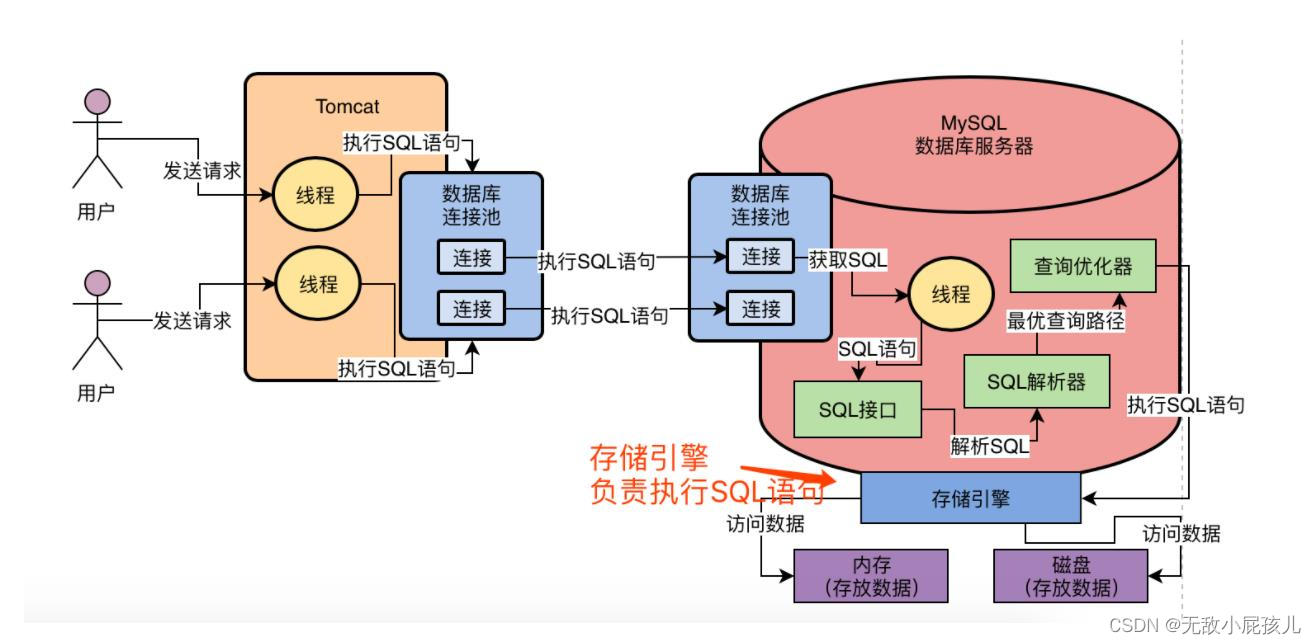
二、sql语句执行的过程详解
1、连接器
MySQL内部首先提供了一个组件,就是SQL接口(SQL Interface),他是一套执行SQL语句的接口,专门用于执行我们发送给MySQL的那些增删改查的SQL语句,因此MySQL的工作线程接收到SQL语句之后,就会转交给SQL接口去执行。当sql接口接收到sql语句之后,接下来交给连接器进行处理,连接器的主要作用如下:
1.1、负责与客户端的通信,是半双工模式,这就意味着某一固定时刻只能由客户端向服务器请求或者服务器向客户端发送数 据,而不能同时进行,其中MySQL在与客户端连接TCP/IP的。
1.2、MySQL自带的权限表会校验当前用户的权限。
2、分析器
上一步的连接器的权限校验ton过后,接下来的分析器是将客户端发过来的SQL语句进行分析,这将包括预处理与解析过程,在这个阶段会解析SQL语句的语义,并进行关键词和非关键词进行提取、解析,并组成一个解析树。具体的关键词包括不限定于以下:select/update/delete/or/in/where/group by/having/count/limit等。
select * from user where userId = 1 ;如上面的sql语句,在分析器中就通过语义规则器将select from where这些关键词提取和匹配出来,MySQL会自动判断关键词和非关键词,将用户的匹配字段和自定义语句识别出来。这个阶段也会做一些校验:比如校验当前数据库是否存在user表,同时假如user表中不存在userId这个字段同样会报错:unknown column in field list.
3、优化器
上一步的分析器对sql语句进行分析后得到一个:解析树,优化器根据解析树来进行SQL语句的优化,会根据执行计划进行最优的选择,匹配合适的索引,选择最佳的执行方案。
select * from user where id = 1 and age > 30 ;1.1、根据搜索条件,找出所有可能使用的索引
id = 1 , 这个搜索条件可以使用主键索引PRIMARY。
age > 30 ,这个搜索条件可以使用二级索引(非聚簇索引)。
1.2、计算全表扫描的代价
对于InnoDB存储引擎来说,全表扫描的意思就是把聚簇索引中的记录都依次和给定的搜索条件做一下比较,把符合搜索条件的记录加入到结果集,所以需要将聚簇索引对应的页面加载到内存中,然后再检测记录是否符合搜索条件。由于查询成本=I/O成本+CPU成本。
(补充)我们前边说过表中的记录其实都存储在聚簇索引对应B+树的叶子节点中,所以只要我们通过根节点获得了最左边的叶子节点,就可以沿着叶子节点组成的双向链表把所有记录都查看一遍。也就是说全表扫描这个过程其实有的B+树内节点是不需要访问的,但是MySQL在计算全表扫描成本时直接使用聚簇索引占用的页面数作为计算I/O成本的依据,是不区分内节点和叶子节点的。
1.3、计算PRIMARY需要成本
计算PRIMARY需要多少成本的关键问题是:需要预估出根据对应的where条件在主键索引B+树中存在多少条符合条件的记录。
1.4、计算二级索引需要成本
因为通过二级索引查询会遇到回表,索引覆盖,索引下推等不同情况,所以在计算二级索引需要成本时还要加上以上不同情况的成本:
1.5、比较各成本选出最优者
选择成本最小的索引
1.6、生成执行计划
根据上面的计算,最后得出一个执行计划。
4、执行器
执行器就会根据优化器生成的一套执行计划 ,然后调用myisam或者innodb(以innodb为主)存储引擎去执行我们的sql,之后的步骤会涉及:buffer pool、change buffer、redo log buffer、undoLog、redoLog、binLog等组件,这些后续篇章进行补充。
借道友法力一用:

========================== stay hungry stay foolish ==========================














 1131
1131











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









