








 超级会员免费看
超级会员免费看


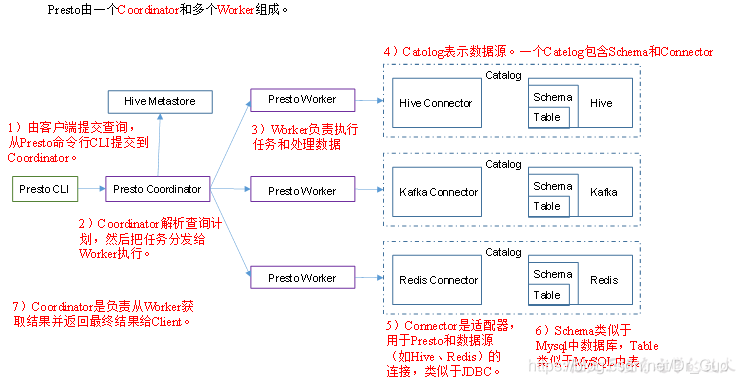
Presto和Impala、Spark SQL都是SQL查询引擎,也都是基于内存运算。但是Presto支持多种数据源,比如Hive、TiDB、Redis、Kafka、ES、Oracle等等,可以跨数据源连表查,既快又方便。
不过多介绍了,下面进入正题。
Hive 动态分区使用方法见下:
set hive.exec.dynamic.partition=true; #开启动态分区,默认是false
set hivePresto和Impala、Spark SQL都是SQL查询引擎,也都是基于内存运算。但是Presto支持多种数据源,比如Hive、TiDB、Redis、Kafka、ES、Oracle等等,可以跨数据源连表查,既快又方便。
不过多介绍了,下面进入正题。
Hive 动态分区使用方法见下:
set hive.exec.dynamic.partition=true; #开启动态分区,默认是false
set hive 4321
2万+
4321
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言





 订阅专栏 解锁全文
订阅专栏 解锁全文























